Delta Lake_ High-Performance ACID Table Storage over Cloud Object Stores
論文發表於 2020年, 研究資料湖產品的很好的學習資料.
概要
開篇很明確的表明了為什麼要做Delta lake這樣一個產品. Databricks嘗試將資料倉儲直接架在雲上物件儲存之上, 這種嘗試的過程中遇到了物件儲存的一些問題, 為了解決這些問題, 提出了Delta lake這套技術方案.
物件儲存的優勢
- 價效比高, pay-as-you-go 用多少付多少
- 能快速擴縮容
- 存算分離, 使得使用者可以單獨去調整儲存或計算資源
物件儲存的問題
- 物件儲存只提供了類似 kv 的api , 每一個路徑就是一個key , 很難做到跨key 物件之間的事務保障. 在更新某張表的時候, 可能會導致其他使用者端讀取到中間資料. 甚至在更新過程中的意外退出可能會導致損壞的資料
- 後設資料操作效能特別差, 特別是list 操作, 例如S3 每次只能返回1000個物件, 每次執行需要花費上百ms.
- 由於雲上讀取資料會有初始的latency(慢啟動), 所以要想利用在parquet檔案的footer中儲存的min/max的statistics資訊, 就需要頻繁去讀取每個檔案的footer, 來進行謂詞下推, 這個過程反而可能會因為"慢啟動" 的問題導致這種 "skipping check" 反而比原始query 還要慢.
Delta Lake設計思路
因此, 為了解決這些物件儲存的問題提出了Delta Lake, an ACID table storage layer over cloud object stores的架構設計.
他這裡也對比了其他幾種解決的思路
比如通過資料分割區, 或者像snowflake那樣通過一個集中式的後設資料服務, 這個劣勢就是需要單獨維護一個後設資料服務, 並且這個服務很容易成為瓶頸, 因為所有的操作都需要經過這個服務.
Delta lake的思路就是直接將後設資料儲存在object store之上, 並通過WAL紀錄檔實現事務保障.

可以看到分割區目錄下是資料檔案, _dalta_log 目錄中就記錄的是transaction log.
這些紀錄檔中記錄了, 哪些檔案被新增了, 哪些檔案被刪除了, 後設資料的操作, schema變更, statistics資訊.
這樣讀取的時候需要遍歷delta log 來確定所需要讀取的檔案列表, 那麼為了避免每次讀取需要查所有的json檔案, 會定期的checkpoint, 將多個json檔案合併成一個.parquet檔案, 並在_last_checkpoint中記錄最新的checkpoint id.
這樣讀取資料的流程就是查詢checkpoint檔案找到這些檔案的列表, 然後可以根據後設資料中的statistics 過濾掉不相關的檔案, 然後直接讀取這些datafile, 相比原來的操作list + 讀取檔案的 footer 要快很多.
讀取協定
- 讀取last_checkpoint id
- 使用list操作 找到 checkpoint 及他之後的json列表. 這樣就可以構建出某個時間點表的檢視. 這裡有個點需要注意 設計中還存在對雲端儲存最終一致性的相容

- 根據這個後設資料的檔案列表進行資料讀取
寫入協定
- 在寫完一個data object後, 需要更新後設資料到delta_log目錄中
- 找到要新寫入的檔案序列id r, 將新的record 寫入
r + 1.json

(這樣豈不是每個json檔案只記錄一個檔案?) 按照論文裡描述的, 一個log 檔案應該是包含多個操作的, 有可能spark是微批寫入, 每次寫入的時候可能會涉及多個data file的變動
- 寫入
r+1.json的操作需要是原子的. 這依賴於不同的雲廠商所提供的原子性的api.- 例如 Google Cloud Storage 有 atomic put-if-absent的介面
- HDFS 使用原子的rename api
- 而S3是沒有的, 所以他還是額外提供了一個coordination的服務來實現
- 如果寫入失敗, 會重新執行前面的一步, 重新執行commit
事務保障
ACID 分別對應 原子性(要麼成功要麼失敗),一致性(資料永遠符合完整性約束,且對資料的修改在事務完成後立刻對使用者可見),隔離性(並行操作互不影響),永續性(資料不易失)。
原子性: 對log檔案的操作是原子的, 對這個檔案的修改實際上就是事務提交的過程, 要麼成功要麼失敗, 保障了原子性
一致性: 一致性是指,一個事務必須使資料庫從一個一致性狀態變換到另一個一致性狀態(執行成功),或回滾到原始的一致性狀態(執行失敗)。這意味著必須維護完整性約束,以使在事務之前和之後資料庫保持一致性和正確性。從這個意義上來說, 目前Delta lake說的是保障的是單表上的事務能力, 所以一致性也是能滿足的. 原子性滿足, 一致性就可以滿足.
隔離性: 隔離性是指,並行執行的各個事務之間不能互相干擾,即一個事務內部的操作及使用的資料,對並行的其他事務是隔離的。此屬性確保並行執行一系列事務的效果等同於以某種順序序列地執行它們,也就是要達到這麼一種效果:對於任意兩個並行的事務T1和T2,在事務T1看來,T2要麼在T1開始之前就已經結束,要麼在T1結束之後才開始,這樣每個事務都感覺不到有其他事務在並行地執行。這要求兩件事:
- 在一個事務執行過程中,資料的中間的(可能不一致)狀態不應該被暴露給所有的其他事務。
- 兩個並行的事務應該不能操作同一項資料。資料庫管理系統通常使用鎖來實現這個特徵。
拿轉賬來說,在A向B轉賬的整個過程中,只要事務還沒有提交(commit),查詢A賬戶和B賬戶的時候,兩個賬戶裡面的錢的數量都不會有變化。如果在A給B轉賬的同時,有另外一個事務執行了C給B轉賬的操作,那麼當兩個事務都結束的時候,B賬戶裡面的錢必定是A轉給B的錢加上C轉給B的錢再加上自己原有的錢。
如此,隔離性防止了多個事務並行執行時由於交叉執行而導致資料的不一致。事務隔離分為不同級別,包括未提交讀(Read uncommitted)、提交讀(read committed)、可重複讀(repeatable read)和序列化(Serializable)。以上4個級別的隔離性依次增強,分別解決不同的問題。事務隔離級別越高,就越能保證資料的完整性和一致性,但同時對並行效能的影響也越大。
**永續性: **資料都是寫到持久化儲存上, 在commit階段發生的失敗會進行重寫, 可以保障永續性
隔離性中常見的問題是
- 髒讀: 髒讀指的是讀到了其他事務未提交的資料,未提交意味著這些資料可能會回滾,也就是可能最終不會存到資料庫中,也就是不存在的資料。讀到了並一定最終存在的資料,這就是髒讀。
- 不可重複讀: 不可重複讀指的是在同一事務內,不同的時刻讀到的同一批資料可能是不一樣的,可能會受到其他事務的影響,比如其他事務改了這批資料並提交了
- 幻讀: 幻讀是針對資料插入(INSERT)操作來說的。假設事務A對某些行的內容作了更改,但是還未提交,此時事務B插入了與事務A更改前的記錄相同的記錄行,並且在事務A提交之前先提交了,而這時,在事務A中查詢,會發現好像剛剛的更改對於某些資料未起作用,但其實是事務B剛插入進來的,讓使用者感覺很魔幻,感覺出現了幻覺,這就叫幻讀。
在Delta Lake中commit的過程可能多個client並行的, 但同一時刻只會有一個client commit成功, 失敗的使用者端會重試寫入到下一個檔案, 這個時候應該會有一些衝突檢測的邏輯. 這是一種樂觀並行控制機制

並且通過delta log維護每次提交的版本檔案列表, 可以實現MVCC語意. 讀取的時候只會讀取到某一個提交成功的版本. 所以Delta Lake是通過樂觀並行控制 + MVCC, 以上的隔離性的幾個問題都不會存在, 達到了Serializable隔離級別
因此可以說保障了ACID語意
Higher Level Features
Time Travel and Rollbacks
在checkpoint中記錄的每個版本中的快照, 所以時間旅行非常的簡單, Spark SQL支援通過
AS OF timestamp和VERSION AS OF commit_id來讀取某個版本的資料. 當然為了讀取歷史版本的資料, 需要去設定資料儲存的時長, 防止讀取的時候資料已經被物理刪除了.
同時也可以通過MERGE INTO的語法來回滾/修復資料

Efficient UPSERT, DELETE and MERGE
由於支援了事務, 所以可以很安全的更新資料. 而不會影響當前的reader. 他這裡面沒有提到具體是怎麼實現更新的, 但是感覺應該是類似於hudi, 先定位到檔案, 然後在重寫這部分檔案.
Streaming Ingest and Consumption
可以承擔一部分訊息佇列的能力. delta_log的資料可以用作讀取某個cp點之後的資料的變化. 可以在後臺執行compaction任務將小檔案合併成大檔案, 優化讀取的效能.
Data Layout Optimization
也是由於事務的支援, 因此可以通過一些後臺的layout optimization來優化讀取, 常見的優化手段: compact, 更新 statistics, 索引, Z-Ordering
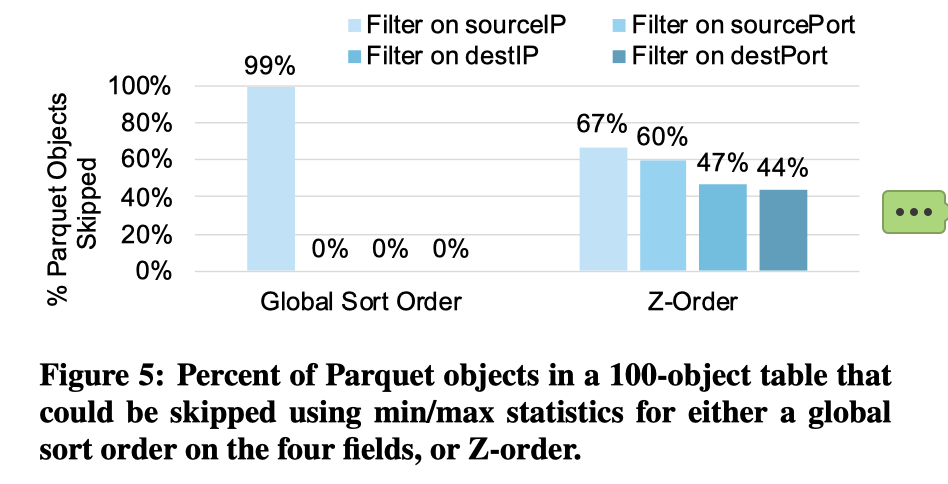
Z-Order 能使得表在多維度的場景中都能取得比較不錯的data skipping效果. 效能測試中也展示了zorder在多維場景下的資料過濾的效果.
Caching
這裡是指可以在計算端的本地磁碟快取遠端的資料, 由於一個資料檔案寫入後即不再變化了, 所以快取是比較安全的, 而且可以很好的加速查詢
Audit Logging
通過後設資料管理可以將資料的操作紀錄檔都記錄在後設資料中, 可以表檔案的歷史變更, paimon裡面也有類似的audit log的表

Schema Evolution
通過後設資料管理, 表其實具備了多版本的能力, 可以通過不同版本的schema去讀取底層的資料. 這也是天然就能實現的
Connectors to Query and ETL Engines
這一點比較有意思, 這個是指他提供了和其他系統整合的connector, 但是利用了一種機制

通過提供 _symlink_format_manifest 檔案, 這樣就可以暴露一個當前系統的快照給那些批式處理和olap系統, 而這些系統只要能讀取parquet檔案就可以了.
使用者只需要跑一個sql, 就可以生成這樣一個manifest檔案, 就可以作為Presto, Arthena, RedShift, SnowFlake的外表了. 也不需要額外外掛開發的負擔
常見使用場景
-
基於雲端儲存的傳統ETL, 利用上雲上物件儲存的優勢
-
BI分析. 直接基於物件儲存的Olap查詢. 而spark為了加速這種查詢專門開發了Photon runtime, 極大提升即席查詢的能力, 好處是不需要單獨把資料匯入到一個專門的系統中

最後Delta lake在業務上的集大成者應該就是Lakehouse, Databricks應該在隨後就發表了一篇相關論文. Lakehouse 直接基於物件儲存的統一儲存來實現 批式ETL, 流式計算, Olap分析, Machine learning
效能
最後在效能上主要有幾個大的提升點:
- 通過log檔案管理後設資料, 減少了傳統架構中的list等後設資料操作
- Z-Ordering 等layout 優化的效果
- 寫入效能保持和之前接近
Related Work
Hudi/Iceberg: 很類似, 也是在儲存上定義了儲存格式和協定. 能力上其實也差不多.
Hive: 當前hive也具備了ACID的能力, 藉助於metastore. 但是可能缺少一些time travel能力, 資料新鮮度不夠, 分割區資料大的時候後設資料操作仍然會是瓶頸
HBase/kudu: 這些系統也是能在HDFS之上提供更低延遲的寫入和讀取能力, 可以將small write合併後寫入, 但是需要執行一個單獨的分散式系統, 成本完全不是一回事
Cstore: 最後這個是Cstore, 長期來看這些系統都是在嘗試提供高效能的事務能力, 以及分析能力. 而Cstore就是嘗試這樣融合的HTAP的系統. 這些系統都是提供了常駐的服務來優化OLTP或者analysis.
而Delta lake呢 則是裸跑在object store之上, 提供了相對夠用的事務層. 免去了獨立儲存服務的開銷.
總結
Delta Lake 在雲上物件儲存之上封裝了一層基於樂觀並行控制 + MVCC的寫入讀取協定, 提供了ACID語意, 在這基礎上實現了諸如Time Travel, Update/Delete, Data Layout, Schema Evolution, Streaming Read等一系列high level的能力.
雖然市場上資料湖有三大主要的產品, Delta lake, Hudi, Iceberg. 但是這三者的建立之初的初衷都還是各有側重點的. 這篇文章中主要介紹了Delta lake主要還是想盡可能的利用雲上物件儲存廉價和pay-as-you-go的特性, 但是又不得不解決一系列物件儲存的問題所引入的技術.
而Hudi最早應該是Uber為了解決其內部離線數倉增量更新的問題. 但是隨著開源社群和市場的打磨, 這些產品的功能也逐漸趨同, 都基本具備了 Update/Delete, ACID, Time Travel, Data layout optimization, 流讀等功能.
此外也可以看到的技術大趨勢
- 存算分離
- 基於同一儲存的Lakehouse架構
參考
https://developer.aliyun.com/article/874742 雲數倉與資料湖後設資料 ACID 介紹與對比
https://www.cnblogs.com/cciejh/p/acid.html 深入理解巨量資料架構之——事務及其ACID特性
https://zhuanlan.zhihu.com/p/117476959 MySQL事務隔離級別和實現原理
https://draveness.me/database-concurrency-control/
https://docs.delta.io/latest/concurrency-control.html
本文來自部落格園,作者:Aitozi,轉載請註明原文連結:https://www.cnblogs.com/Aitozi/p/17552466.html