終於可以徹底告別手寫正規表示式了
可以徹底告別手寫正規表示式了
這篇文章的目的是讓你能得到完美的正規表示式,而且還不用自己拼。
說到正規表示式,一直是令我頭疼的問題,這傢伙一般時候用不到,等用到的時候發現它的規則是一點兒也記不住,\d表示一個數位,\s表示包括下劃線在內的任意單詞字元,也就是 [A-Za-z0-9_],還有[\s\S]*可以匹配包括換行在內的任意字串。

這你都能記住嗎,如果能的話,那真的佩服,反正我是記不住,之前每次手寫的時候都得跟查字典似的一個個的查,簡單的還好,複雜的就很痛苦了。

過程往往是這個樣子的:
1、 先開啟 Google,搜尋一篇正規表示式,找到一份像上圖那樣的字典教學,先看個幾分鐘,回憶回憶,還有可能回憶不起來。
2、然後就開始根據需求寫一個正規表示式。
3、放到程式中執行一下。
4、誒,怎麼不好用,匹配不上啊,接著修改正則。
5、繼續從 3 - 4 的迴圈,直到運氣來了,正常出結果了。
這是最早的時候,真的是全靠那點僅有的實力和運氣了。
記得剛畢業不久的時候,有一次領導給安排一個任務,要在一堆 PDF 檔案裡把我們需要的資料摘出來。PDF 這玩意兒吧,你把它的內容讀出來,它就是一大段文字,要在這一堆內容不一致的檔案中準確的拿到資料,第一反應就是用正則。
當時的做法就是上面的 1-5這幾步來的,加上當時候剛畢業比較菜,跌跌撞撞才把程式寫好,中間有幾次偵錯的時候,程式一跑起來,VS(Visual Studio)就特別卡。對的,就是宇宙第一強大的 IDE ,當時我還在寫 C#,縱然是宇宙第一強大,也被我弄的特別卡。
當時只道是正則寫的有問題,然後就一直改。
後來才知道,那是因為正則寫的不合理,發生了回溯現象,越不合理,回溯越嚴重,加上當時的 PDF 內容很多,所以導致開發工具都卡了,這要是整到線上,那怕是混不下去了。
關於回溯的問題,可以參考下面這篇文章《失控的正規表示式:災難性的回溯》
https://www.regular-expressions.info/catastrophic.html
後來就不至於那麼菜了,知道了一些關於正規表示式的線上網站,上面有一些常用的正規表示式,不用自己搗鼓了,能偷懶當然要偷懶了。可以在 Goolge 上搜尋關鍵詞「正規表示式 線上」,然後就會出來一大堆,直接在上面用那些常用的正則,例如手機號、郵箱、網址啊,基本上能解決90%的需求場景。
另外的10%呢,以前可能只能自己琢磨了,現在都2023年了,基本上99%的概率都不用親自動手了,當然了,如果是大佬呢,就想自己寫,那完全沒問題。
ChatGPT 完美解決
ChatGPT 是LLM(大語言模型)的產品,最最擅長的事情就是分析語言,而正規表示式的應用場景是什麼呢,其實就是在一大堆文字語言中按照我們的規則,找到我們需要的內容,總的來說,也是對於文字語言的處理,所以用 ChatGPT 解決正規表示式的問題簡直太合適不過了。
比如最簡單的,匹配中國的手機號,直接讓 ChatGPT 把正則寫出來,而且連程式碼都給你寫好了。
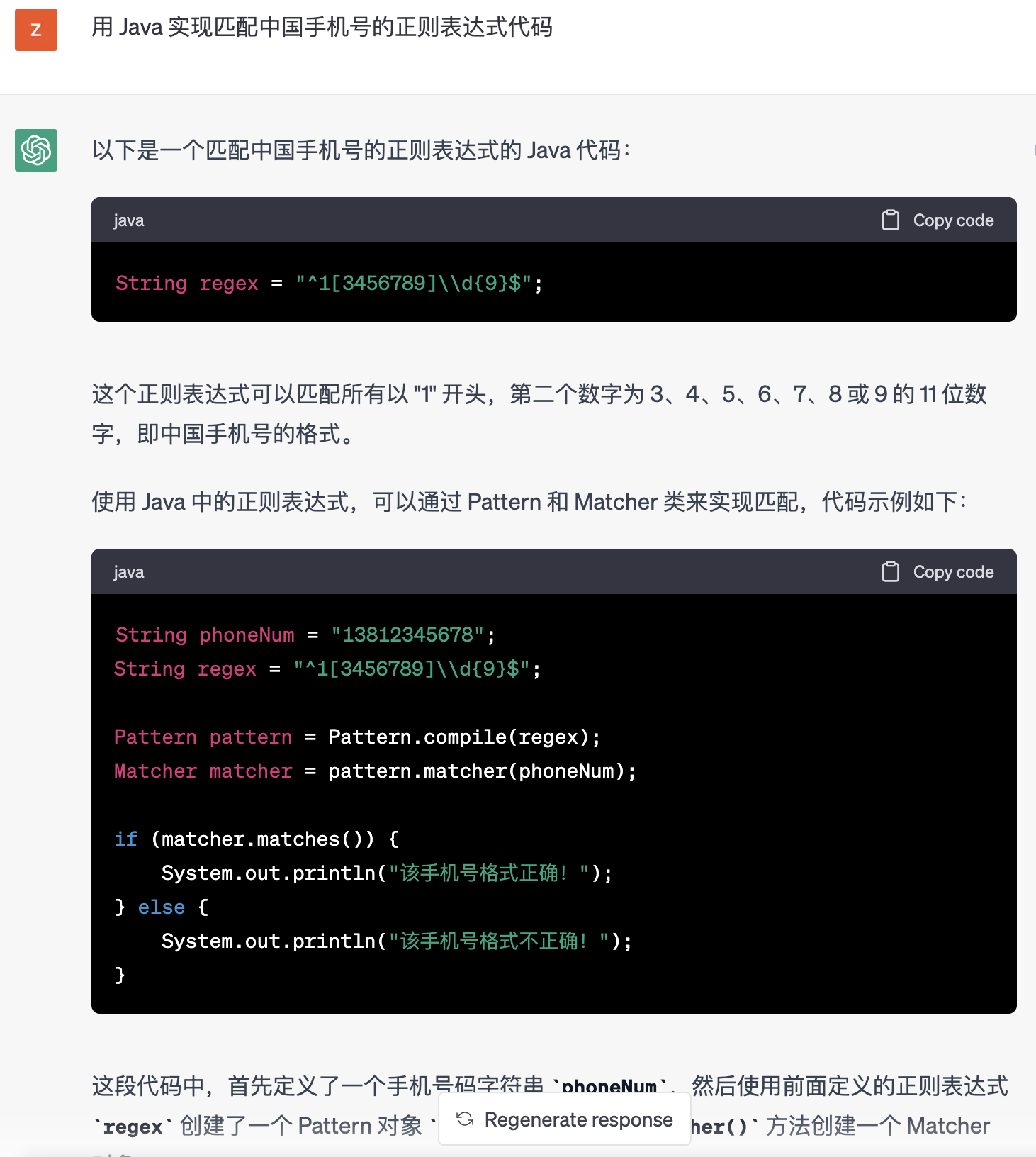
至於網址、郵箱等等也不在話下了。
不僅ChatGPT 可以,連百度文心一言也可以。百度文心一言雖然這樣可以,但是如果你反過來問它,它就蒙圈了。
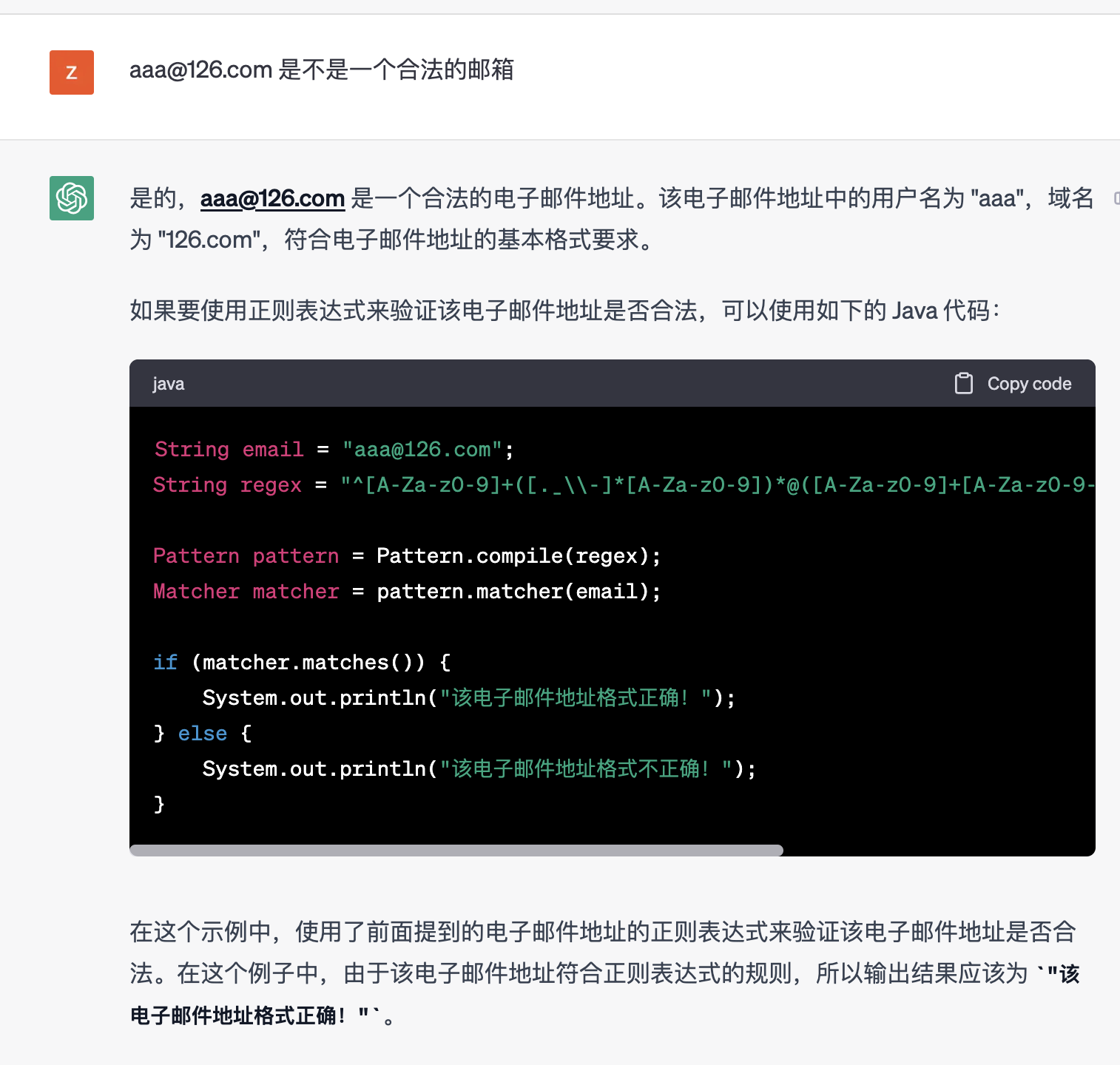
比如我問 [email protected] 是不是一個合法的郵箱,ChatGPT 會告訴你這個郵箱是合法的,但是百度文心一言就不行了。
下面這個是 ChatGPT 的回答:
下面這個是百度文心一言的回答:

不僅郵箱不行,你問它一個手機號是否合法,百度文心一言也不行,還會告訴你這個號碼的歸屬地,但是這個歸屬地也是錯誤的。
這樣就看出來什麼是智慧,什麼是巨量資料了,明顯 ChatGPT 更智慧一點,希望國產的大模型能在這兩年追上吧。
再舉一個例子
匹配一段 HTML 中的某個部分也是正則的常用場景,做過爬蟲的或多或少都用過正則吧。
比如我在一大段 HTML 中有這麼一部分
<div class="time">這是一個,this is some</div>
現在要拿到這個 div 中的內容部分,當然有很多其他的方式了,比如 Java 版的 jsoup,使用 xpath、css selector 等都可以,但是如果就要用正則呢,是不是自己寫的話,一般菜鳥就感覺很麻煩了。
這時候我們問問 ChatGTP ,看看它怎麼搞的。
直接就這麼問了:
<div> <div class="outer"> <div class="time">這是一個,this is some</div> <div class="button">button</div> </div> </div>, 用 Java 正規表示式匹配這段 HTML 中 class="time" 的這個標籤的 Text 部分
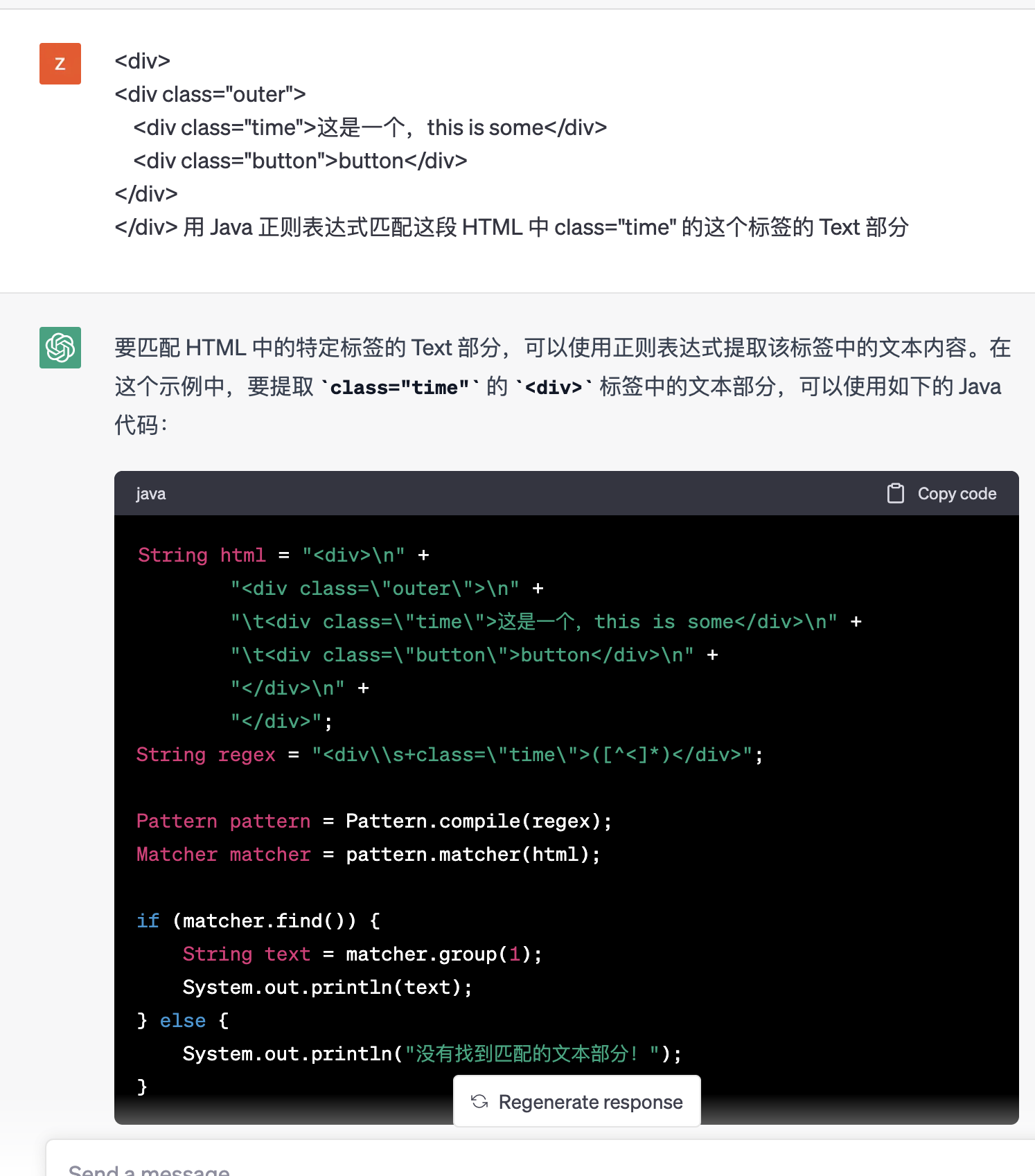
直接拿過程式碼跑一下,沒有任何問題。
有同學說了,這麼明顯的標籤,還用的著 ChatGPT ,直接拿過來就寫了。
這裡只是舉個例子,如果哪位有比較複雜的匹配邏輯,也可以用ChatGPT 來試試,基本上99%都能直接解決。
還有一個網站很厲害
如果你沒有辦法或者不想用 ChatGPT ,也不想用百度文心一言這些,我還發現一個網站,這個網站我嚴重懷疑它已經接入了 ChatGPT ,它也支援通過自然語言描述,就能給出相應的正規表示式。
網站地址:https://wangwl.net/static/projects/visualRegex
比如我跟他說:提取一段字串中的中國手機號碼部分,而且還有正則視覺化。

上面的那個匹配 HTML 的例子,我也在這個網站上試過,結果也是可以的。
純粹的好東西分享,我跟這個網站沒有任何關係。
一個幫你分析正則的網站
接下來這個網站呢,如果你想對正則有比較深入的理解,或者想看看自己寫好的正則或ChatGPT 幫你生成的正規表示式效果怎麼樣,效能好不好,都可以在這個網站進行。

網站左側可以選擇你的目標語言,也就是你的程式碼實現是哪種語言 Java 還是 JavaScript 等。
中間上方是正規表示式,中間下方是待匹配的內容。
右側上方是你寫的正則對待匹配內容完整的匹配分析過程,非常詳細,可以通過這裡清楚的看出這個正則匹配的時候經過了哪些路徑。
右側下方是最終的匹配結果。
如果你寫的正則在工作的時候發生了明顯的回溯,這裡也會給出提示,告訴你問題,讓你去優化。
總結
君子善假於物也,雖然我很菜,但是工具好用啊,我+好用的工具,等於我也很厲害了。
歡迎捧場,趕緊用一用吧,覺得好用的話,可以推薦給身邊的小夥伴也用一下。
