Go有哪些特殊的語言特性?
摘要:本文由葡萄城技術團隊於部落格園原創並首發。轉載請註明出處:葡萄城官網,葡萄城為開發者提供專業的開發工具、解決方案和服務,賦能開發者。
前言
本文主要通過值傳遞和指標、字串、陣列、切片、集合、物件導向(封裝、繼承、抽象)和設計哲學7個方面來介紹GO語言的特性。
文章目錄:
1.Go的前世今生
1.1Go語言誕生的過程
話說早在 2007 年 9 月的一天,Google 工程師 Rob Pike 和往常一樣啟動了一個 C++專案的構建,按照他之前的經驗,這個構建應該需要持續 1 個小時左右。這時他就和 Google公司的另外兩個同事 Ken Thompson 以及 Robert Griesemer 開始吐槽並且說出了自己想搞一個新語言的想法。當時 Google 內部主要使用 C++構建各種系統,但 C++複雜性巨大並且原生缺少對並行的支援,使得這三位大佬苦惱不已。

第一天的閒聊初有成效,他們迅速構想了一門新語言:能夠給程式設計師帶來快樂,能夠匹配未來的硬體發展趨勢以及滿足 Google 內部的大規模網路服務。並且在第二天,他們又碰頭開始認真構思這門新語言。第二天會後,Robert Griesemer 發出瞭如下的一封郵件:
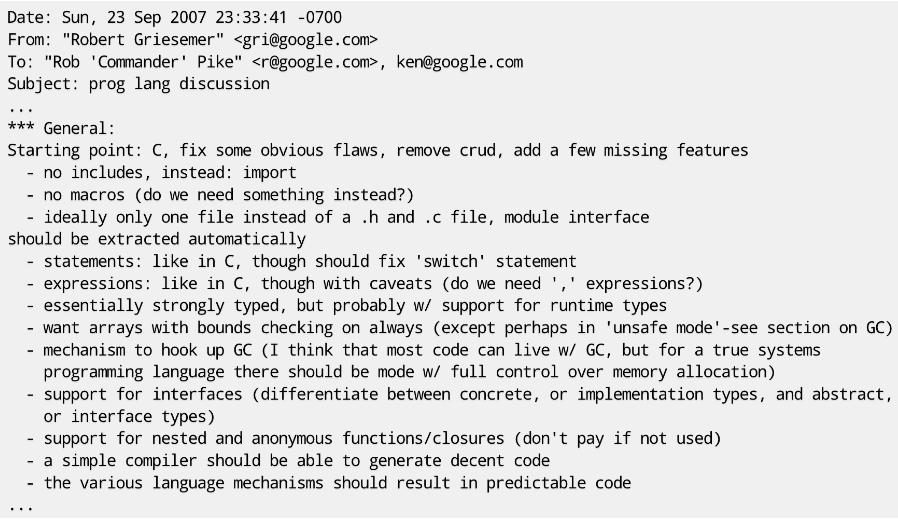
可以從郵件中看到,他們對這個新語言的期望是:在 C 語言的基礎上,修改一些錯誤,刪除一些詬病的特性,增加一些缺失的功能。比如修復 Switch 語句,加入 import 語句,增加垃圾回收,支援介面等。而這封郵件,也成了 Go 的第一版設計初稿。
在這之後的幾天,Rob Pike 在一次開車回家的路上,為這門新語言想好了名字Go。在他心中,」Go」這個單詞短小,容易輸入並且可以很輕易地在其後組合其他字母,比如 Go 的工具鏈:goc 編譯器、goa 組合器、gol 聯結器等,並且這個單詞也正好符合他們對這門語言的設計初衷:簡單。
1.2逐步成型
在統一了 Go 的設計思路之後,Go 語言就正式開啟了語言的設計迭代和實現。2008 年,C語言之父,大佬肯·湯普森實現了第一版的 Go 編譯器,這個版本的 Go 編譯器還是使用C語言開發的,其主要的工作原理是將Go編譯成C,之後再把C編譯成二進位制檔案。到2008年中,Go的第一版設計就基本結束了。這時,同樣在谷歌工作的伊恩·泰勒(Ian Lance Taylor)為Go語言實現了一個gcc的前端,這也是 Go 語言的第二個編譯器。伊恩·泰勒的這一成果不僅僅是一種鼓勵,也證明了 Go 這一新語言的可行性 。有了語言的第二個實現,對Go的語言規範和標準庫的建立也是很重要的。隨後,伊恩·泰勒以團隊的第四位成員的身份正式加入 Go 語言開發團隊,後面也成為了 Go 語言設計和實現的核心人物之一。羅斯·考克斯(Russ Cox)是Go核心開發團隊的第五位成員,也是在2008年加入的。進入團隊後,羅斯·考克斯利用函數型別是「一等公民」,而且它也可以擁有自己的方法這個特性巧妙設計出了 http 包的 HandlerFunc 型別。這樣,我們通過顯式轉型就可以讓一個普通函數成為滿足 http.Handler 介面的型別了。不僅如此,羅斯·考克斯還在當時設計的基礎上提出了一些更泛化的想法,比如 io.Reader 和 io.Writer 介面,這就奠定了 Go 語言的 I/O 結構模型。後來,羅斯·考克斯成為 Go 核心技術團隊的負責人,推動 Go 語言的持續演化。到這裡,Go 語言最初的核心團隊形成,Go 語言邁上了穩定演化的道路。
1.3正式釋出
2009年10月30日,羅伯·派克在Google Techtalk上做了一次有關 Go語言的演講,這也是Go語言第一次公之於眾。十天後,也就是 2009 年 11 月 10 日,谷歌官方宣佈 Go 語言專案開源,之後這一天也被 Go 官方確定為 Go 語言的誕生日。

(Go語言吉祥物Gopher)
1.4.Go安裝指導
1.Go語言安裝包下載
Go 官網:https://golang.google.cn/
選擇對應的安裝版本即可(建議選擇.msi檔案)。
2.檢視是否安裝成功 + 環境是否設定成功
開啟命令列:win + R 開啟執行框,輸入 cmd 命令,開啟命令列視窗。
命令列輸入 go version 檢視安裝版本,顯示下方內容即為安裝成功。

2.Go語言特殊的語言特性
2.1值傳遞和指標
Go中的函數引數和返回值全都是按值傳遞的。什麼意思呢?比如下述的程式碼:
type People struct {
name string
}
func ensureName(p People) {
p.name = "jeffery"
}
func main() {
p := People{
name: ""
}
ensurePeople(p)
fmt.Println(p.name) // 輸出:""
}
為啥上面這段程式碼沒有把 p 的內容改成「jeffery」呢?因為 Go 語言的值傳遞特性,ensureName函數內收到的 p 已經是 main 函數中 p 的一個副本了。這就和 C#中把 p 改為一個 int 型別得到的結果一樣。
那怎麼解決呢?用指標。
不知道其他人怎麼樣,當我最開始學習 Go 的時候發現需要學指標的時候瞬間回想起了大學時期被 C 和 C++指標折磨的那段痛苦回憶,所以我本能的對指標就有一種排斥感,雖然 C#中也可以用指標,但是如果不寫底層程式碼,可能寫 10 年程式碼都用不到一次。
不過還好,Go 中對指標的使用進行了簡化,沒有複雜的指標計算邏輯,僅知道兩個操作就可以很輕鬆的用好指標:
- 「*「: 取地址中的內容
- 「&」: 取變數的地址
var p \*People = \&People{
name: "jeffery",
}
上述程式碼中,我建立了一個新的 People 範例,並且通過」&」操作獲取了它的地址,把它的地址賦值給了一個*People的指標型別變數 p。此時,p 就是一個指標型別,如果按照 C 或者 C++,我是無法直接操作 People 中的欄位 name 的,但是 Go 對指標操作進行了簡化,我可以對一個指標型別變數直接操作其內的欄位,比如:
func main() {
fmt.Println(p.name) // 輸出:jeffery
fmt.Println(\*(p).name) // 輸出:jeffery
}
上述的兩個操作是等價的。
有了指標,我們就可以很輕鬆的模擬出 C#那種按參照傳遞引數的程式碼了:
type People struct {
name string
}
func ensureName(p \*People) {
p.name = "jeffery"
}
func main() {
p := \&People{
name: ""
}
ensurePeople(p)
fmt.Println(p.name) // 輸出:jeffery
}
2.2字串
在 C#中字串其實是 char 型別的陣列,是一個特殊的分配在棧空間的參照型別。
而在 Go 語言中,字串是值型別,並且字串是一個整體。也就是說我們不能修改字串的內容,從下面的例子可以很清楚的看出這一概念:
var str = "jeffery";
str[0] = 'J';
Console.WriteLine(str); // 輸出:Jeffery
上述的語法在 C#中是成立的,因為我們修改的其實是字串中的一個 char 型別,而 Go 中這樣的語法是會被編譯器報錯的:
str := "jeffery"
str[0] = 'J' // 編譯錯誤:Cannot assign to str[0]
但是我們可以用陣列 index 讀取對應字串的值:
s := str[0]
fmt.Printf("%T", s) // uint8
可以看到這個返回值是uint8,這是為啥呢?其實,在 Go 中,string 型別是由一個名為rune的型別組成的,進入 Go 原始碼看到rune的定義就是一個 int64 型別。這是因為 Go 中把 string 編譯成了一個一個的 UTF8 編碼,每一個 rune 其實就是對應 UTF8 編碼的值。
此外,string 型別還有一個坑:
str := "李正龍"
fmt.Printf("%d", len(str))
len()函數同樣也是 go 的內建函數,是用來求集合的長度的。
上面這個例子會返回9,這是因為中文在 Go 中會編譯為 UTF-8 編碼,一個漢字的編碼長度就 3,所以三個漢字就成了 9,但是也不一定,因為一些特殊的漢字可能佔 4 個長度,所以不能簡單用 len() / 3 來獲取文字長度。
因此,漢字求長度的方法應該這樣做:
fmt.Println(utf8.RuneCountInString("李正龍"))
2.3陣列
Go 中的陣列也是一個我覺得設計的有點過於底層的概念了。基礎的用法和 C#是相同的,但是細節區別還是很大的。
首先,Go 的陣列也是一個值型別,除此之外,由於」嚴格地「遵循了陣列是一段連續的記憶體的結合這個概念,陣列的長度是陣列的一部分。這個概念也很重要,因為這是直接區別於切片的一個特徵。而且,Go 中的陣列的長度只能是一個常數。
a := [5]int{1,2,3,4,5}
b := [...]{1,2,3,4,5}
lena := len(a)
lenb := len(b)
上述是 Go 中陣列的兩個比較常規的初始化語法,陣列的長度和字串一樣,都是通過len()內建函數獲取的。其餘的使用和 C#基本相同,比如可以通過索引取值賦值,可以遍歷,不可以插入值等。
2.4切片
與陣列對應的一個概念,就是 Go 中獨有的切片Slice型別。在日常的開發中幾乎很少能用得到陣列,因為陣列沒有擴充套件能力,比如 C#中我們也幾乎用不到陣列,能用陣列的地方基本都用List<T>。Slice 就是 List 的一種 Go 語言實現,它是一個參照型別,主要的目的是為了解決陣列無法插入資料的問題。其底層也是一個陣列,只不過它對陣列進行了一些封裝,加入了兩個指標分別指向陣列的左右邊界,就使得 Slice 有了可以增加資料的功能。
s1 := []int{1,2,3,4,5}
s2 := s1[1:3]
s3 := make([]int, 0, 5)
上面是 Slice 的三種常用的初始化方式。
- 可以看到切片和陣列的唯一區別就是沒有了陣列定義中的數量
- 可以基於一個去切片去建立另一個切片,其後面的數位的含義就是目前業界通用的左包含右封閉
- 可以通過**make()**函數建立一個切片
make()函數感覺可以伴隨 Go 開發者的一生,Go 的三個參照型別都是通過 make 函數進行初始化建立的。對切片來說,第一個參數列示切片型別,比如上慄就是初始化一個 int 型別的切片,第二個參數列示切片的長度,第三個參數列示切片的容量。
想切片中插入資料需要使用到 append()函數,並且語法十分詭異,可以說是離譜到家了:
s := make([]int)
s = append(s, 12345) // 這種追加值還需要返回給原集合的語法真不知道是哪個小天才想到的
這裡出現了一個新的概念,切片的容量。我們知道陣列是沒有容量這個概念的(其實是有的,只不過容量就是長度),而切片的容量其實就類似於 C#中List<T>的容量(我知道大部分 C#er 在使用 List 的時候根本不會去關心 Capacity 這個引數),容量表示的是底層陣列的長度。
容量可以通過 cap()函數獲取
在 C#中,如果 List 的資料寫滿了底層陣列,那會發生擴容操作,需要新開闢一個陣列將原來的資料複製到新的陣列中,這是很耗費效能的一個操作,Go 中也是一樣的。因此在日常開發使用 List 或者切片的時候,如果能提前確定容量,最好就是初始化的時候就定義好,避免擴充套件導致的效能損耗。
2.5集合
Go 中除了把 List 內建為切片,同樣也把 Dictionary<TKey, TValue>內建為了 map 型別。map 是 Go 中三個參照型別的第二個,其建立的方式和切片相同,也需要通過 make 函數:
m := make(map[int]string, 10)
從字面意思我們就可以知道,這句話是建立了一個 key 為 int,value 為 string,初始容量是 10 的 map 型別。
對 map 的操作沒有像 C#那麼複雜,get,set 和 contains 操作都是通過[]來實現的:
m := make(map[string]string, 5)
// 判斷是否存在
v, ok := m["aab"]
if !ok {
//說明map中沒有對應的key
}
// set值,如果存在重複key則會直接替換
m["aab"] = "hello"
// 刪除值
delete(m, "aab")
這裡要說個坑,雖然 Go 中的 map 也是可以遍歷的,但是 Go 強制將結果亂序了,所以每次遍歷不一定拿到的是相同順序的結果。
2.6物件導向
2.6.1封裝
終於說到物件導向了。細心的同學肯定已經看到了,Go裡面竟然沒有封裝控制關鍵字public,protected和private!那我這物件導向第一準則的封裝性怎麼搞啊?
Go 語言的封裝性是通過變數首字母大小寫控制的(對重度程式碼潔癖患者的我來說,這簡直是天大的福音,我再也不用看到那些首字母小寫的屬性了)。
// struct型別的首字母大寫了,說明可以在包外存取
type People struct {
// Name欄位首字母也大寫了,同理包外可存取
Name string
// age首字母小寫了,就是一個包內欄位
age int
}
// New函數大寫了,包外可以調到
func NewPeople() People {
return People{
Name: "jeffery",
age: 28
}
}
2.6.2繼承
封裝搞定了,繼承怎麼搞呢?Go 裡好像也沒有繼承的關鍵字extends啊?Go 完全以設計模式中的優先組合而非繼承的設計思想設計了複用的邏輯,在 Go 中沒有繼承,只有組合。
type Animal struct {
Age int
Name string
}
type Human struct {
Animal // 如果預設不定義欄位的欄位名,那Go會預設把組合的型別名定義為欄位名
// 這樣寫等同於: Animal Animal
Name string
}
func do() {
h := \&Human{
Animal: Animal{Age: 19, Name: "dog"},
Name: "jeffery",
}
h.Age = 20
fmt.Println(h.Age) // 輸出:20,可以看到如果自身沒有組合結構體相同的欄位,那可以省略子結構體的呼叫直接獲取屬性
fmt.Println(h.Name) // 輸出:jeffery,對於有相同的屬性,優先輸出自身的,這也是多型的一種體現
fmt.Println(h.Animal.Name)// 輸出:dog,同時,所組合的結構體的屬性也不會被改變
}
這種組合的設計模式極大的降低了繼承帶來的耦合,單就這一點來說,我認為是完美的銀彈。
2.6.3抽象
在講解關鍵字的部分我們就已經看到了,Go 是有介面的,但是同樣沒有實現介面的implemented關鍵字,那是因為 Go 中的介面全部都是隱式實現的。
type IHello interface {
sayHello()
}
type People struct {}
func (p \*People) sayHello() {
fmt.Println("hello")
}
func doSayHello(h IHello) {
h.sayHello()
}
func main() {
p := \&People{}
doSayHello(p) // 輸出:hello
}
可以看到,上例中的結構體 p 並沒有和介面有任何關係,但是卻可以正常被doSayHello這個函數參照,主要就是因為 Go 中的所有介面都是隱式實現的。(所以我覺得真的有可能出現你寫著寫著突然就實現了某個依賴包的某個介面的情況)
此外,這裡看到了一個不一樣的語法,函數關鍵字 func 之後沒有直接定義函數名稱,而是加入了一個結構體 p 的一個指標。這樣的函數就是結構體的函數,或者更直白一點就是 C#中的方法。
在預設情況下,我們都是使用指標型別為結構體定義函數,當然也可以不用指標,但是在那種情況下,函數所更改的內容就和原結構體完全不相關了。所以一般也遵循一個無腦用指標的原則。
好了,封裝、繼承和抽象都有了,至於多型,在繼承那裡已經看到了,Go 也是優先匹配自身的相同函數,如果沒有才回去呼叫父結構體的函數,因此預設情況下的函數都是被重寫之後的函數。
2.7設計哲學
Go 語言的設計哲學是less is more。這句話的意思是 Go 需要簡單的語法,其中簡單的語法也包括顯式大於隱式(介面型別真是滿頭問號)。這是什麼意思呢?
2.7.1. Go 沒有預設的型別轉換
var i int8 = 1
var j int
j = i // 編譯報錯:Cannot use 'i' (type int8) as the type int
還有一個例子就是 string 型別不能預設和 int 等其他型別拼接,比如輸入"n你好" + 1在 Go 中同樣會報編譯錯誤。原因就是 Go 的設計者覺得這種都是隱式的轉換,Go 需要簡單,不應該有這些。
2.7.2. Go 沒有預設引數,同樣也沒有方法過載
這也是一個很讓人惱火語言特性。因為不支援過載,寫程式碼時就不得不寫大量可能重複但是名字不相同的函數。這個特性也是有開發者專門問過 Go 設計師的, 給出的回覆就是 Go 的設計目標就是簡單,在簡單的大前提下,部分冗餘的程式碼是可以接受的。
2.7.3.Go 不支援 Attribute
和目前沒有泛型不同,Go 的泛型是一個正在開發的功能,是還沒來得及做的。而特性 Attribute 也就是 Java 中的註解,在 Go 中是被明確說明不會支援的語言特性。
註解能在 Java 中帶來怎樣強大的功能呢?舉一個例子:
在大型網際網路都轉向微服務架構的時代,分散式的多段提交,分散式事務就是一個比較大的技術壁壘。以分散式事務為例,多個微服務很可能都不是一個團隊開發的,也可能部署在世界各地,而如果一個操作需要回滾,其他所有的微服務都需要實現回滾的機制。這裡不光涉及複雜的業務模型,還有更復雜的資料庫回滾策略(什麼 2PC 啊,TCC 啊每一個策略都可以當一門單獨的課來講)。
這種東西如果要從頭開發那幾乎是很難考慮全面的。更別提這樣的複雜程式碼再耦合到業務程式碼中,那程式碼會變得非常難看。都不說分散式事務了,簡單的一個記憶體快取,我們用的都很混亂,在程式碼中會經常看到先讀取快取在讀取資料庫的程式碼,和業務完全耦合在一起,完全無法維護。
而 Spring Cloud 中,程式碼的使用者可以通過一個簡單的註解(也就是 C#的特性)@Transactional,那這個方法就是支援事務的,使這種複雜的技術級程式碼完全和業務程式碼解耦,開發者完全按照正常的業務邏輯寫業務程式碼即可,完全不用管事務的一些問題。
然而, Go 的設計者同樣認為註解會嚴重影響程式碼使用者對一個呼叫的使用心智,因為加了一個註解,就可以導致一個函數的功能完全不一樣,這與 Go 顯式大於隱式的設計理念相違背,會嚴重增加使用者的心智負擔,不符合 Go 的設計哲學(哎,就離譜…)
2.7.4. Go 沒有 Exception
在 Go 中沒有異常的概念,相反地提供了一個 error 的機制。對 C#來說,如果一段程式碼執行存在問題,那我們可以手動丟擲一個 Exception,在呼叫方可以捕獲對應的異常進行之後的處理。而 Go 中沒有異常,替代的方案是 error 機制。什麼是 error 機制呢?還記得之前講過的 Go 的幾乎所有的函數都有多個返回值嗎?為啥要那麼多的返回值呢?對,就是為了接收 error 的。比如下述程式碼:
func sayHello(name string) error {
if name == "" {
return errors.New("name can not be empty")
}
fmt.Printf("hello, %s\\n", name)
return nil
}
// invoker
func main() {
if err := sayHello("jeffery"); err != nil {
// handle error
}
}
這樣的 error 機制需要保證所有的程式碼執行過程中都不會異常崩潰,每個函數到底執行成功了沒有,需要通過函數的返回錯誤資訊來判斷,如果一個函數呼叫的返回結果的 error == nil,說明這段程式碼沒問題。否則,就要手動處理這個 error。
這樣就有可能導致一個嚴重的後果:所有的函數呼叫都需要寫成
if err := function(); err != nil
這樣的結構。這樣的後果幾乎是災難性的(這也是為啥 VS2022 支援了程式碼 AI 補全功能後,網上的熱評都是利好 Gopher)這種 error 的機制也是 Go 被黑的最慘的地方。
那這時候肯定有小夥伴說了,那我就是不處理搞一個類似於1/0這樣的程式碼會怎麼樣呢?
如果寫了類似於上述的程式碼,那最終會引發一個 Go 的panic。在我目前淺顯的理解中,panic其實才是 C#中 Exception 的概念,因為程式執行遇到 panic 後就會徹底崩潰了,Go 的設計者在最開始的設計中估計是認為所有的錯誤都應該用 error 處理,如果引發了 panic 那說明這個程式無法使用了。因此 panic 其實是一個無法挽回的錯誤的概念。
然而,大型的專案中,並不是自己的程式碼寫的萬無一失就沒有 panic 了,很可能我們參照的其他包乾了個什麼我們不知道的事就 panic 了,比如最典型的一個例子:Go 的 httpRequest 中的 Body 只能讀取一次,讀完就沒有了。如果我們使用的 web 框架在處理請求時把 Body 讀了,我們再去讀取結果很有可能 panic。
因此,為了解決 panic,Go 還有一個 recover()的函數,一般的用法是:
func main() {
panic(1)
defer func() {
if err := recover(); err != nil {
fmt.Println("boom")
}
}
}
其實 Go 有一個強大的競爭者——Rust,Rust 是 Mozilla 基金會在 2010 年研發的語言,和 Go 是以 C 語言為基礎開發的類似,Rust 是以 C++為基準進行開發的。所以現在社群中就有 Go 和 Rust 兩撥陣營在相互爭論,吵得喋喋不休。當然,萬物沒有銀彈,一切的事物都應該以辯證的思維去學習理解。
好了,看完了上面那些 Go 的語法之後,肯定也會手癢寫一點 Go 的程式碼練習練習,加深記憶。正好,那就來實現一個 Go 官網中的一個小例子,自己動手實現一下這個計算 Fibonacci 數列第 N 個數的介面吧。
type Fib interface {
// CalculateFibN 計算斐波那契數列中第N個數的值
// 斐波那契數列為:前兩項都是1,從第三項開始,每一項的值都是前兩項的和
// 例如:1 1 2 3 5 8 13 ...
CalculateFibN(n int) int
}
由於篇幅所限,這個小練習的答案我放在了自己的 gitee中,歡迎大家存取。