基於 NNCF 和 🤗 Optimum 面向 Intel CPU 對 Stable Diffusion 優化
基於隱空間的擴散模型 (Latent Diffusion Model),是解決文字到圖片生成問題上的顛覆者。Stable Diffusion 是最著名的一例,廣泛應用在商業和工業。Stable Diffusion 的想法簡單且有效: 從噪聲向量開始,多次去噪,以使之在隱空間裡逼近圖片的表示。
但是,這樣的方法不可避免地增加了推理時長,使使用者端的體驗大打折扣。眾所周知,一個好的 GPU 總能有幫助,確實如此,但其損耗大大增加了。就推理而言,在 2023 年上半年 (H1’23),一個好 CPU 範例 (r6i.2xlarge,8 vCPUs ,64 GB 記憶體) 價格是 0.504 $/h,同時,類似地,一個好 GPU 範例 (g4dn.2xlarge,NVIDIA T4,16 GB 記憶體) 價格是 0.75 $/h ,是前者的近 1.5 倍。
這就使影象生成的服務變得昂貴,無論持有者還是使用者。該問題在面向使用者端部署就更突出了: 可能沒有 GPU 能用!這讓 Stable Diffusion 的部署變成了棘手的問題。
在過去五年中,OpenVINO 整合了許多高效能推理的特性。 其一開始為計算機視覺模型設計,現今仍在許多模型的推理效能上取得最佳表現,包括 Stable Diffusion。然而,對資源有限型的應用,優化 Stable Diffusion 遠不止執行時的。這也是 OpenVINO NNCF(Neural Network Compression Framework) 發揮作用的地方。
在本部落格中,我們將理清優化 Stable Diffusion 模型的問題,並提出對資源有限的硬體 (比如 CPU) 減負的流程。尤其是和 PyTorch 相比,我們速度提高了 5.1 倍,記憶體減少了 4 倍。
Stable Diffusion 的優化
在 Stable Diffusion 的 管線 中,UNet 的執行是最計算昂貴的。因此,對模型的推理速度,針對 UNet 的優化能帶來足夠的效益。
然而事實表明,傳統的模型優化方法如 8-bit 的後訓練量化,對此不奏效。主要原因有兩點: 其一,面向畫素預測的模型,比如語意分割、超解析度等,是模型優化上最複雜的,因為任務複雜,引數和結構的改變會導致無數種變數; 其二,模型的引數不是很冗餘,因為其壓縮了其數以千萬計的 資料集 中的資訊。這也是研究者不得不用更復雜的量化方法來保證模型優化後的精度。舉例而言,高通 (Qualcomm) 用分層知識蒸餾 (layer-wise Knowledge Distillation) 方法 (AdaRound) 來 量化 Stable Diffusion。這意味著,無論如何,模型量化後的微調是必要的。既然如此,為何不用 量化感知的訓練 (Quantization-Aware Trainning, QAT),其對原模型的微調和引數量化是同時進行的?因此,我們在本工作中,用 token 合併 (Token Merging) 方法結合 NNCF, OpenVINO 和 Diffusers 實踐了該想法。
優化流程
我們通常從訓練後的模型開始優化。在此,我們從寶可夢資料集 (Pokemons dataset,包含圖片和對應的文字描述) 上微調的 模型。
我們對 Stable Diffusion 用 Diffusers 中的 圖片 - 文字微調之例,結合 NNCF 中的 QAT (參見訓練的 指令碼)。我們同時改變了損失函數,以同時實現從源模型到部署模型的知識蒸餾。該方法與通常的知識蒸餾不同,後者是把源模型蒸餾到小些的模型。我們的方法主要將知識整理作為附加的方法,幫助提高最後優化的模型的精度。我們也用指數移動平均方法 (Exponential Moving Average, EMA) 讓我們訓練過程更穩定。我們僅對模型做 4096 次迭代。
基於一些技巧,比如梯度檢查 (gradient checkpointing) 和 保持 EMA 模型 在記憶體 (RAM) 而不是虛擬記憶體 (VRAM) 中。整個優化過程能用一張 GPU 在一天內完成。
量化感知的訓練之外呢 ?
量化模型本身就能帶來模型消耗、載入、記憶體、推理速度上的顯著提高。但量化模型蠻大的優勢在能和其他模型優化方法一起,達到加速的增益效果。
最近,Facebook Research 針對視覺 Transformer 模型,提出了一個 Token Merging 方法。該方法的本質是用現有的方法 (取平均、取最大值等) 把冗餘的 token 和重要的 token 融合。這在 self-attention 塊之前完成,後者是 Transformer 模型最消耗算力的部分。因此,減小 token 的跨度能減少 self-attention 塊消耗的時間。該方法也已被 Stable Diffusion 模型 採用,並在面向 GPU 的高解析度優化上有可觀的表現。
我們改進了 Token Merging 方法,以便用 OpenVINO,並在注意力 UNet 模型上採用 8-bit 量化。這包含了上述含知識蒸餾等的所有技術。對量化而言,其需要微調,以保證數值精度。我們也從 寶可夢資料集 上訓練的 模型 開始優化和微調。下圖體現了總體的優化工作流程。
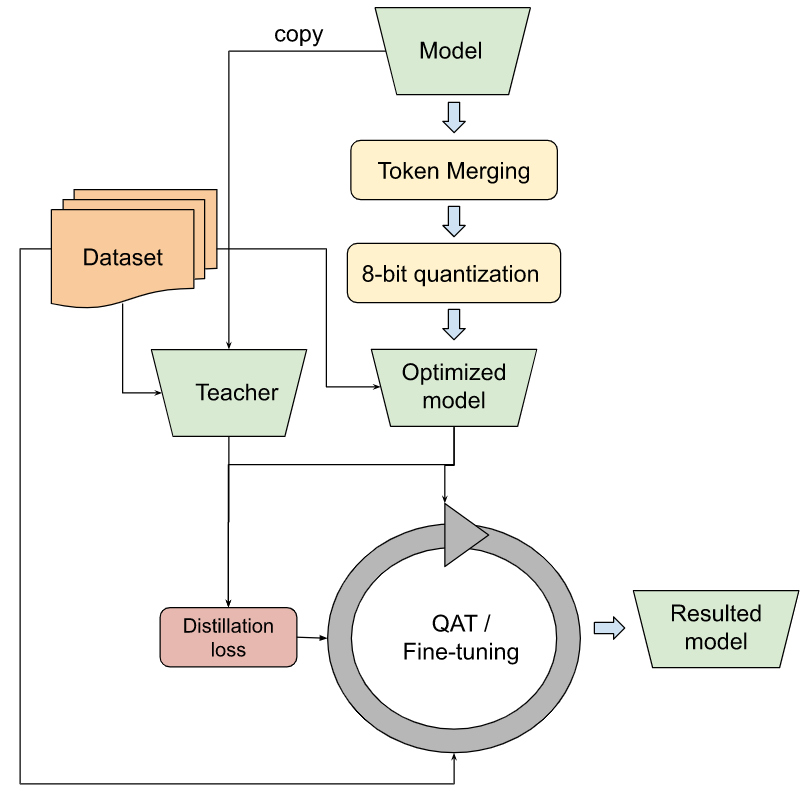
結果的模型在有限資源的硬體上是高度有效的,如客戶機或邊緣 CPU。如上文所述,把 Token Merging 方法和量化方法疊加能帶來額外的推理增益。




用不同模型優化方法的圖片生成的結果 展示。輸入提示詞為 「cartoon bird」,隨機種子為 42。模型用 OpenVINO 2022.3,來自 Hugging Face Space,用「CPU 升級」的範例: 第三代 Intel® Xeon® Scalable Processors,和 Intel® 深度學習加速技術。
結果
我們用優化模型不完整的流程以得到兩種模型: 基於 8-bit 量化的和基於 Token Merging 量化的,並和 PyTorch 作為基準比較。我們也把基準先轉化成 vanilla OpenVINO (FP32) 的模型,以用以分析性比較。
上面的結果圖展示了影象生成和部分模型的特性。如你所見,僅轉化成 OpenVINO 就帶來大的推理速度提高 ( 1.9 倍)。用基於 8-bit 的量化加速和 PyTorch 相比帶來了 3.9 倍的推理速度。量化的另外一個重要提高在於記憶體消耗減少,0.25 倍之於 PyTorch,同時也提高了載入速度。在量化之上應用 Token Merging (ToME) (融合比為 0.4) 帶來了 5.1 倍 的提速,同時把模型記憶體消耗保持在原水平上。我們不提供輸出結果上的質量改變,但如你所見,結果還是有質量的。
下面我們展示將最終優化結果部署在 Intel CPU 上程式碼。
from optimum.intel.openvino import OVStableDiffusionPipeline
# Load and compile the pipeline for performance.
name = "OpenVINO/stable-diffusion-pokemons-tome-quantized-aggressive"
pipe = OVStableDiffusionPipeline.from_pretrained(name, compile=False)
pipe.reshape(batch_size=1, height=512, width=512, num_images_per_prompt=1)
pipe.compile()
# Generate an image.
prompt = "a drawing of a green pokemon with red eyes"
output = pipe(prompt, num_inference_steps=50, output_type="pil").images[0]
output.save("image.png")
在 Hugging Face Optimum Intel 庫中你可以找到訓練和量化 程式碼。比較優化過的和原模型的 notebook 程式碼在 這裡。你可以在 Hugging Face Hub 上找到 OpenVINO 下的 許多模型。另外,我們在 Hugging Face Spaces 上建了一個 demo,以執行 [帶第三代 Intel Xeon Scalable 的 r6id.2xlarge 範例]。
一般的 Stable Diffusion 模型呢?
正如我們在寶可夢影象生成任務中展現的一樣,僅用小量的訓練資源,對 Stable Diffusion 管線實現高層次的優化是可能的。同時,眾所周知,訓練一般的 Stable Diffusion 模型是一個 昂貴的任務。但是,有充足的資金和硬體資源,用上述方法優化一般的模型生成高解析度的模型是可能的。我們唯一的警告是關於 Token Merging 方法,其會減弱模型容忍性。這裡衡量標準是,訓練資料越複雜,優化模型時的融合比就該越小。
如果你樂於讀本部落格,那你可能對另外一篇 部落格 感興趣,它討論了在第四代 Intel Xeon CPU 上其他互補的 Stable Diffusion 模型優化方法。
英文原文: https://hf.co/blog/train-optimize-sd-intel
作者: Alexander, Yury Gorbachev, Helena, Sayak Paul, Ella Charlaix
譯者: Vermillion
審校/排版: zhongdongy (阿東)