安裝Hadoop單節點偽分散式叢集
安裝Hadoop單節點偽分散式叢集
作業系統:Ubuntu server 20.04
參考檔案:http://apache.github.io/hadoop/hadoop-project-dist/hadoop-common/SingleCluster.html
系統準備
開啟SSH
系統支援SSH遠端登陸.
如未安裝可使用下面命令安裝:
sudo apt-get install ssh
安裝JDK
參考網址:https://cwiki.apache.org/confluence/display/HADOOP/Hadoop+Java+Versions
官方檔案:
- Apache Hadoop 3.3 and upper supports Java 8 and Java 11 (runtime only)
- Please compile Hadoop with Java 8. Compiling Hadoop with Java 11 is not supported: HADOOP-16795 - Java 11 compile support OPEN
- Apache Hadoop from 3.0.x to 3.2.x now supports only Java 8
- Apache Hadoop from 2.7.x to 2.10.x support both Java 7 and 8
根據官方檔案,目前支援JDK8和JDK11,我們安裝JDK8即可
操作步驟如下:
# 更新軟體包
sudo apt-get update
sudo apt-get upgrade
# 安裝JDK8
sudo apt install openjdk-8-jdk
# 驗證是否安裝成功
java -version
# 輸出
openjdk version "1.8.0_362"
OpenJDK Runtime Environment (build 1.8.0_362-8u372-ga~us1-0ubuntu1~22.04-b09)
OpenJDK 64-Bit Server VM (build 25.362-b09, mixed mode)
檢視JAVA安裝資訊
# 檢視安裝目錄
which java
# 輸出:/usr/bin/java
# 檢視具體路徑
ll /usr/bin/java
# 輸出:... /usr/bin/java -> /etc/alternatives/java*
設定JAVA_HOME
# 查詢系統中可用的JAVA版本
update-alternatives --config java
# 輸出:
# There is only one alternative in link group java (providing /usr/bin/java): /usr/lib/jvm/java-8-openjdk-amd64/jre/bin/java
# Nothing to configure.
# 通過上面輸出資訊安裝路徑為:/usr/lib/jvm/java-8-openjdk-amd64/jre/bin/java
# 編輯profile檔案
vim /etc/profile
# 在檔案中新增下面程式碼
export JAVA_HOME=/usr/lib/jvm/java-8-openjdk-amd64
export JRE_HOME=$JAVA_HOME/jre
export CLASSPATH=$JAVA_HOME/lib:$JRE_HOME/lib:$CLASSPATH
export PATH=$JAVA_HOME/bin:$JRE_HOME/bin:$PATH
# 生效環境變數
source /etc/profile
# 驗證是否設定成功
echo $JAVA_HOME
# 到這裡如果停的話,就會出現一種情況,每次開啟終端,就需要source /etc/profile一下才能使用java環境,所以參考部落格https://blog.csdn.net/RABCDXB/article/details/123243868 做法如下:
# 輸入vim ~/.bashrc,在對應檔案中輸入上面相同的設定資料。
安裝Hadoop
下載
目前最新版本為:3.3.6,安裝最新版本,可從官網下載。
下載地址:https://dlcdn.apache.org/hadoop/common/hadoop-3.3.6/hadoop-3.3.6.tar.gz
# 進入軟體下載目錄,如果該目錄不存在則可建立此目錄
cd /root/software
# 下載安裝包
wget https://dlcdn.apache.org/hadoop/common/hadoop-3.3.6/hadoop-3.3.6.tar.gz
準備啟動
# 將軟體複製到安裝目錄,如果該目錄不存在可建立
cd /root/program
# 複製安裝包
cp /root/software/hadoop-3.3.6.tar.gz .
# 解壓
tar -zxvf hadoop-3.3.6.tar.gz
# 設定JavaHome
vim /root/program/hadoop-3.3.6/etc/hadoop/hadoop-env.sh
# 修改JAVA_HOME變數,大約在54行
export JAVA_HOME=/usr/lib/jvm/java-8-openjdk-amd64
# 儲存後測試啟動
cd /root/program/hadoop-3.3.6
bin/hadoop
# 此命令輸出相關操作說明
接下來,將有三種啟動模式部署:
-
Local (Standalone) Mode:單機模式
-
Pseudo-Distributed Mode:偽分散式
-
Fully-Distributed Mode:分散式
下面以偽分散式模式進行說明,其他模式部署方式請參考官方檔案。
偽分散式模式安裝
Hadoop可以以偽分散式的方式部署在一臺機器上。
設定
設定core-site.xml檔案.
# 進入Hadoop軟體目錄
cd /root/program/hadoop-3.3.6
# 編輯組態檔
vim etc/hadoop/core-site.xml
# 在檔案的configuration節點新增下面組態檔(第19行):
<configuration>
<property>
<name>fs.defaultFS</name>
<value>hdfs://localhost:9000</value>
</property>
</configuration>
設定etc/hadoop/hdfs-site.xml檔案.
# 進入Hadoop軟體目錄
cd /root/program/hadoop-3.3.6
# 編輯組態檔
vim etc/hadoop/hdfs-site.xml
# 在檔案的configuration節點新增下面組態檔(第19行):
<configuration>
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
</configuration>
設定sbin/start-dfs.sh檔案中啟動使用者為root.
# 進入Hadoop軟體目錄
cd /root/program/hadoop-3.3.6
# 編輯組態檔
vim sbin/start-dfs.sh
# 檔案頂部新增以下引數
#!/usr/bin/env bash
HDFS_DATANODE_USER=root
HADOOP_SECURE_DN_USER=hdfs
HDFS_NAMENODE_USER=root
HDFS_SECONDARYNAMENODE_USER=root
設定sbin/stop-dfs.sh檔案中啟動使用者為root.
# 進入Hadoop軟體目錄
cd /root/program/hadoop-3.3.6
# 編輯組態檔
vim sbin/stop-dfs.sh
# 檔案頂部新增以下引數
#!/usr/bin/env bash
HDFS_DATANODE_USER=root
HADOOP_SECURE_DN_USER=hdfs
HDFS_NAMENODE_USER=root
HDFS_SECONDARYNAMENODE_USER=root
設定sbin/start-yarn.sh檔案中啟動使用者為root.
# 進入Hadoop軟體目錄
cd /root/program/hadoop-3.3.6
# 編輯組態檔
vim sbin/start-yarn.sh
# 檔案頂部新增以下引數
#!/usr/bin/env bash
YARN_RESOURCEMANAGER_USER=root
HADOOP_SECURE_DN_USER=yarn
YARN_NODEMANAGER_USER=root
設定sbin/stop-yarn.sh檔案中啟動使用者為root.
# 進入Hadoop軟體目錄
cd /root/program/hadoop-3.3.6
# 編輯組態檔
vim sbin/stop-yarn.sh
# 檔案頂部新增以下引數
#!/usr/bin/env bash
YARN_RESOURCEMANAGER_USER=root
HADOOP_SECURE_DN_USER=yarn
YARN_NODEMANAGER_USER=root
配飾SSH免密登入本機
# 檢查是否已支援免密登入
ssh localhost
# 如果未設定,可使用下面命令設定,注意當前登入使用者為root
ssh-keygen -t rsa -P '' -f ~/.ssh/id_rsa
cat ~/.ssh/id_rsa.pub >> ~/.ssh/authorized_keys
chmod 0600 ~/.ssh/authorized_keys
測試啟動
截至到目前設定,可以測試啟動Hadoop,此種方式可手動執行MapReduce任務,該部分僅驗證是否可正常啟動。
後面將會介紹Yarn設定,並使用Yarn執行任務。
# 進入應用安裝目錄
cd /root/program/hadoop-3.3.6
# 檔案系統格式化
bin/hdfs namenode -format
# 啟動NameNode和DataNode
sbin/start-dfs.sh
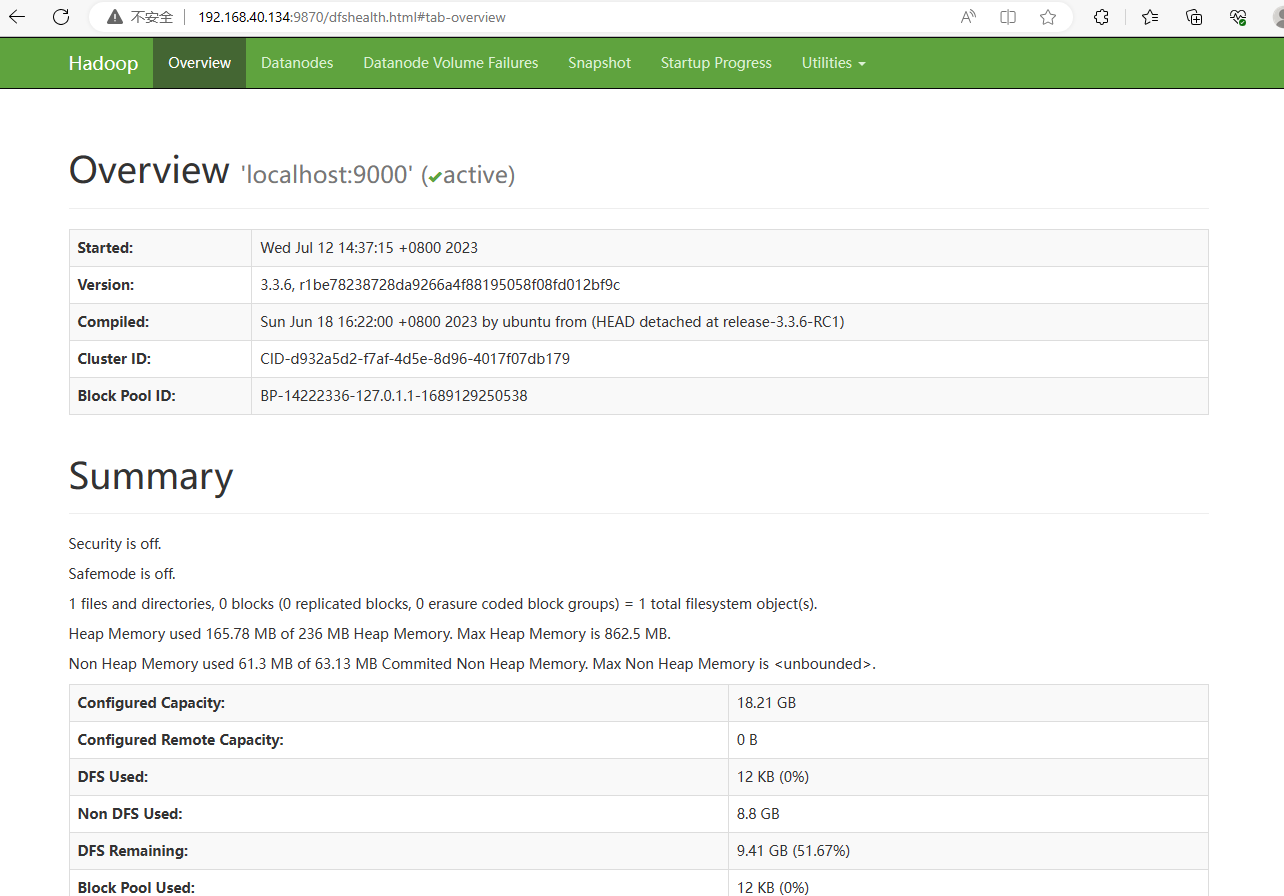
# 瀏覽器開啟終端進行檢視執行狀態,注意防火牆埠是否開啟,NameNode網址如下:
http://192.168.40.134:9870/
# 現狀狀態 Active 即為執行成功
# 停止NameNode和DataNode
sbin/stop-dfs.sh
單節點安裝YARN
在保證上面測試啟動執行正常情況下,可以按照下面步驟設定啟動YARN.
設定etc/hadoop/mapred-site.xml檔案.
# 進入Hadoop軟體目錄
cd /root/program/hadoop-3.3.6
# 編輯組態檔
vim etc/hadoop/mapred-site.xml
# 在檔案的configuration節點新增下面組態檔(第19行):
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
<property>
<name>mapreduce.application.classpath</name>
<value>$HADOOP_MAPRED_HOME/share/hadoop/mapreduce/*:$HADOOP_MAPRED_HOME/share/hadoop/mapreduce/lib/*</value>
</property>
</configuration>
設定etc/hadoop/yarn-site.xml檔案.
# 進入Hadoop軟體目錄
cd /root/program/hadoop-3.3.6
# 編輯組態檔
vim etc/hadoop/yarn-site.xml
# 在檔案的configuration節點新增下面組態檔(第16行):
<configuration>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<property>
<name>yarn.nodemanager.env-whitelist</name>
<value>JAVA_HOME,HADOOP_COMMON_HOME,HADOOP_HDFS_HOME,HADOOP_CONF_DIR,CLASSPATH_PREPEND_DISTCACHE,HADOOP_YARN_HOME,HADOOP_HOME,PATH,LANG,TZ,HADOOP_MAPRED_HOME</value>
</property>
</configuration>
服務啟動與停止:
# 進入Hadoop軟體目錄
cd /root/program/hadoop-3.3.6
# 服務啟動
sbin/start-yarn.sh
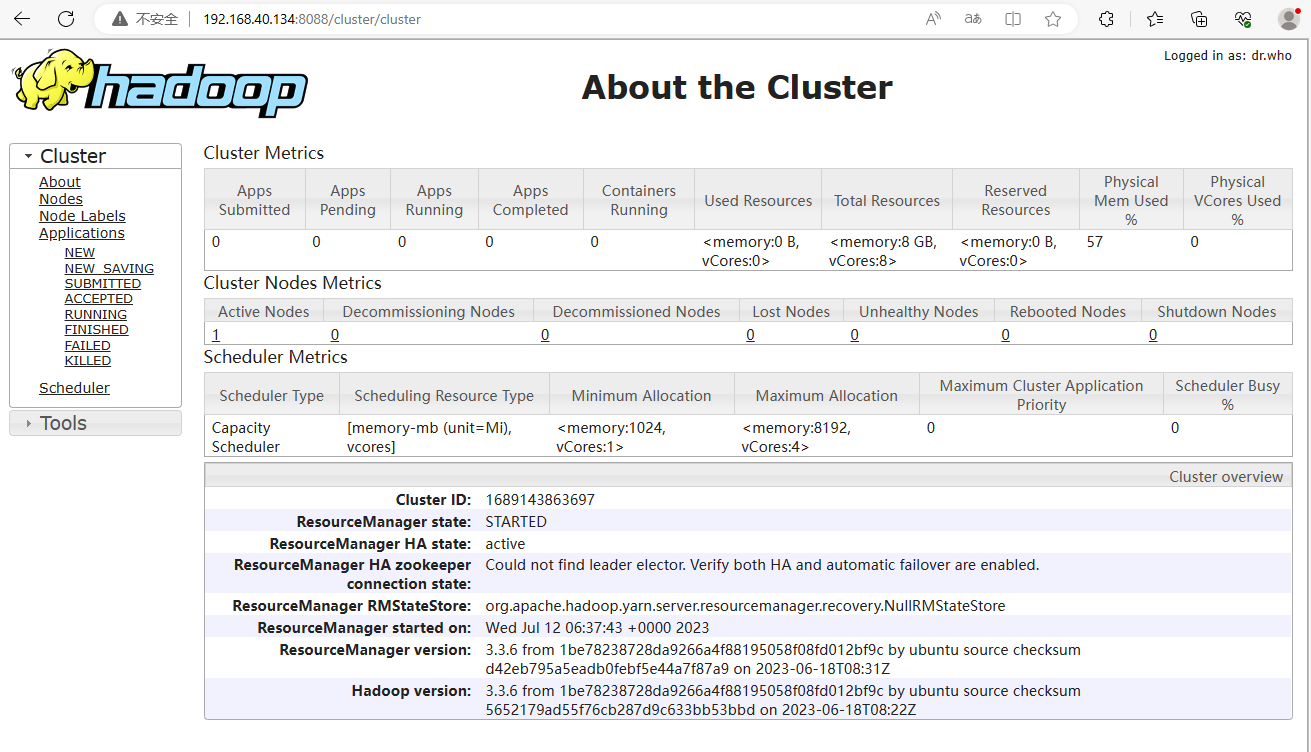
# 瀏覽器開啟終端進行檢視執行狀態,注意防火牆埠是否開啟,資源管理網址如下:
http://192.168.40.134:8088/
# 服務停止
sbin/stop-yarn.sh
偽分散式叢集啟動與停止
# 進入Hadoop軟體目錄
cd /root/program/hadoop-3.3.6
# 啟動,注意順序
sbin/start-dfs.sh
sbin/start-yarn.sh
# 停止,注意順序
sbin/stop-yarn.sh
sbin/stop-dfs.sh