《最新出爐》系列初窺篇-Python+Playwright自動化測試-6-元素定位大法-下篇
1.簡介
上一篇主要是講解我們日常工作中在使用Playwright進行元素定位的一些比較常用的定位方法的理論基礎知識以及在什麼情況下推薦使用。今天這一篇講解和分享一下,在日常中很少用到或者很少見的定位,但是遇到了我們也要會,俗話說:手裡有糧心裡不慌。
2.陰影定位-Shadow DOM
在做web自動化的時候,一些元素在shadow-root的節點下,使得playwright中無法通過xpath來定位

上面所看到的shadow-root標籤其實就是一個shadowDOM,那麼什麼是shadowDOM呢?
他是前端的一種頁面封裝技術,可以將shadowDOM視為「DOM中的DOM」(可以看成一個隱藏的DOM)
他是一個獨立的DOM樹,具有自己的元素和樣式,與原始檔案DOM完全隔離。
shadowDOM必須附在一個HTML元素中,存放shadowDOM的元素,我們可以把它稱為宿主元素。在HTML5中有很多的標籤樣式都是通過shadowDOM來實現的。
比如:日期選擇框,音訊播放標籤,視訊播放標籤都自帶了樣式;(這種封裝對於前端開發來說雖好,但是我們測試人員在做web自動給的時候就會遇到一些問題,shadowDOM中的標籤無法定位。)
預設情況下,Playwright 中的所有定位器都使用 Shadow DOM 中的元素。例外情況是:
- 通過 XPath 定位不會刺穿陰影根部。
- 不支援閉合模式影子根。
例如:以下範例和自定義 Web 元件:
<x-details role=button aria-expanded=true aria-controls=inner-details> <div>Title</div> #shadow-root <div id=inner-details>Details</div> </x-details>
您可以採用與影子根根本不存在相同的方式進行定位。
要單擊 :<div>Details</div>
page.get_by_text("Details").click()
要單擊 :<x-details>
page.locator("x-details", has_text="Details" ).click()
要確保包含文字「詳細資訊」,請執行以下操作:<x-details>
expect(page.locator("x-details")).to_contain_text("Details")
3.過濾器定位-Filtering
例如以下 DOM 結構,我們要在其中單擊第二個產品卡的購買按鈕。我們有幾個選項來過濾定位器以獲得正確的定位器。
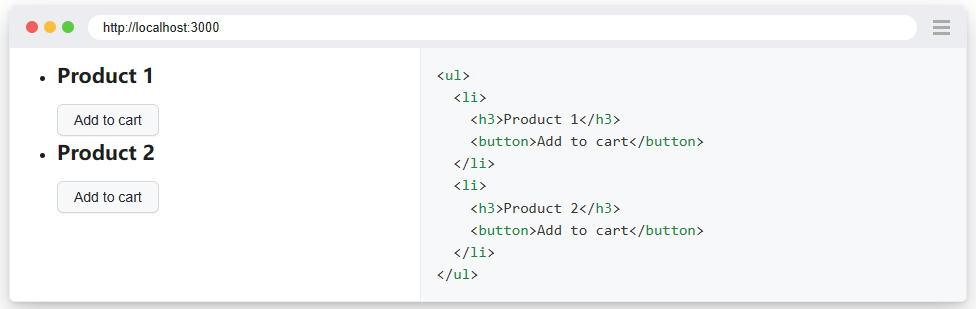
3.1文字過濾
定位器可以使用 locator.filter()方法按文字進行過濾。它將搜尋元素內某處的特定字串,可能在後代元素中,不區分大小寫。您還可以傳遞正規表示式。
1.使用文字
page.get_by_role("listitem").filter(has_text="Product 2").get_by_role( "button", name="Add to cart" ).click()
2.使用正規表示式
page.get_by_role("listitem").filter(has_text=re.compile("Product 2")).get_by_role( "button", name="Add to cart" ).click()
3.通過沒有文字進行篩選
# 5 in-stock items expect(page.get_by_role("listitem").filter(has_not_text="Out of stock")).to_have_count(5)
3.2子項/後代過濾
定位器支援僅選擇具有或沒有與其他定位器匹配的後代的元素的選項。因此,您可以按任何其他定位器進行過濾,例如 locator.get_by_role()、locator.get_by_test_id()、locator.get_by_text() 等。
1.使用子項
page.get_by_role("listitem").filter( has=page.get_by_role("heading", name="Product 2") ).get_by_role("button", name="Add to cart").click()
2.使用產品卡斷言,確保只有一個
expect( page.get_by_role("listitem").filter( has=page.get_by_role("heading", name="Product 2") ) ).to_have_count(1)
3.通過內部沒有匹配的元素進行過濾
expect( page.get_by_role("listitem").filter( has_not=page.get_by_role("heading", name="Product 2") ) ).to_have_count(1)
敲黑板!!!!注意:內部定位器從外部定位器開始匹配,而不是從檔案根目錄匹配。
3.3匹配其他定位進行過濾
方法 locator.and_() 通過匹配其他定位器來縮小現有定位器的範圍。例如,您可以組合 page.get_by_role() 和 page.get_by_title() 以按角色和頭銜進行匹配。
button = page.get_by_role("button").and_(page.getByTitle("Subscribe"))
4.連結定位器
您可以連結建立定位器的方法(如 page.get_by_text() 或 locator.get_by_role()),以將搜尋範圍縮小到頁面的特定部分。
在此範例中,我們首先通過定位其角色:listitem 來建立一個名為 product 的定位器。然後我們按文字過濾。我們可以再次使用產品定位器按按鈕的角色獲取並單擊它,然後使用斷言來確保只有一個帶有文字「產品 2」的產品。
product = page.get_by_role("listitem").filter(has_text="Product 2") product.get_by_role("button", name="Add to cart").click()
您還可以將兩個定位器連結在一起,例如在特定對話方塊中查詢「儲存」按鈕:
save_button = page.get_by_role("button", name="Save") # ... dialog = page.get_by_test_id("settings-dialog") dialog.locator(save_button).click()
5.列表
5.1對列表中的專案進行計數
可以斷言定位器以對列表中的專案進行計數。例如:一下DOM結構
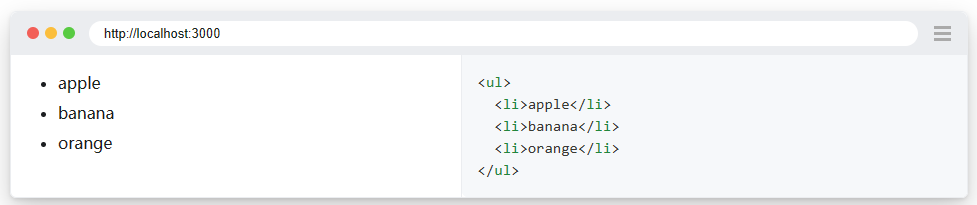
使用計數斷言確保列表包含 3 個專案。
expect(page.get_by_role("listitem")).to_have_count(3)
5.2斷言列表中所有文字
可以斷言定位器以查詢列表中的所有文字。使用 expect(定位器).to_have_text() 確保列表包含文字「蘋果」、「香蕉」和「橙色」。
expect(page.get_by_role("listitem")).to_have_text(["apple", "banana", "orange"])
5.3定位特定專案
有許多方法可以在列表中定位特定專案。
5.3.1通過文字定位
使用 page.get_by_text() 方法通過文字內容在列表中查詢元素,然後單擊它。
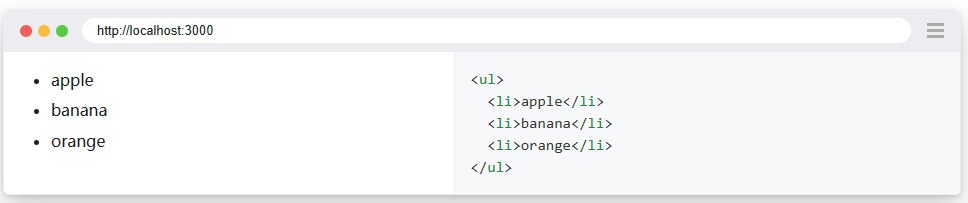
通過文字內容找到專案並單擊它。
page.get_by_text("orange").click()
5.3.2通過文字過濾定位
使用 locator.filter() 在列表中查詢特定專案。按「列表項」的角色找到一個專案,然後按「橙色」的文字進行篩選,然後單擊它。
page.get_by_role("listitem").filter(has_text="orange").click()
5.3.3通過測試id定位
使用 page.get_by_test_id() 方法在列表中查詢元素。如果您還沒有測試 ID,則可能需要修改 html 並新增測試 ID。
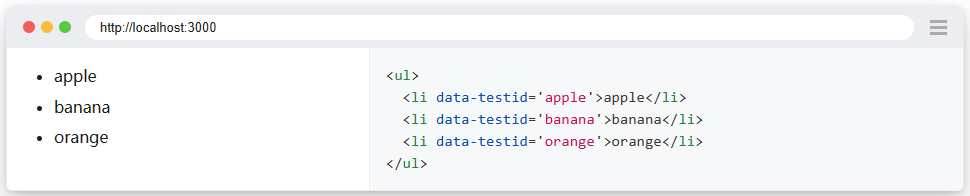
通過測試ID「橙色」找到專案,然後單擊它。
page.get_by_test_id("orange").click()
5.3.4通過第n項定位
如果你有一個相同元素的列表,並且區分它們的唯一方法是順序,你可以從帶有 locator.first、locator.last 或 locator.nth() 的列表中選擇一個特定的元素。
banana = page.get_by_role("listitem").nth(1)
但是,請謹慎使用此方法。通常,頁面可能會更改,並且定位器將指向與預期完全不同的元素。相反,嘗試提出一個通過嚴格標準的獨特定位器。
5.4連結過濾器
當您有各種相似性的元素時,可以使用 locator.filter()方法選擇正確的元素。您還可以連結多個篩選器以縮小選擇範圍。
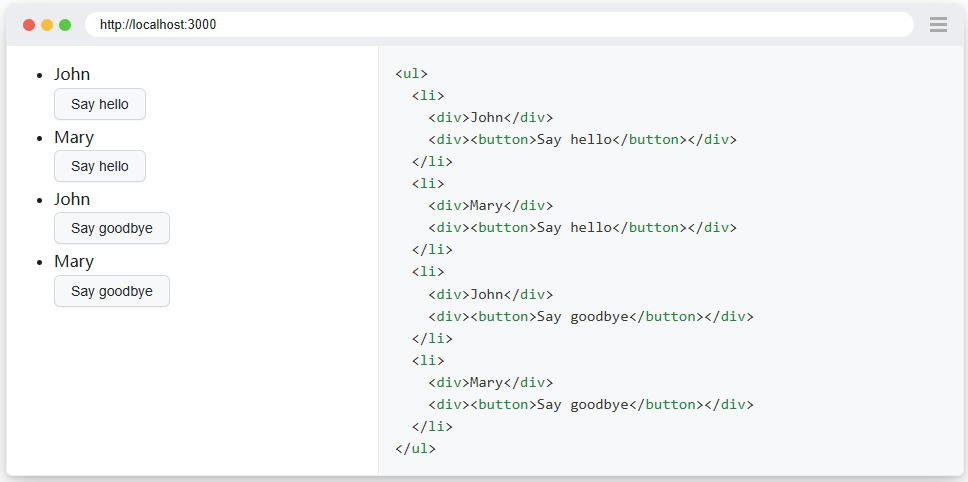
要擷取帶有「Mary」和「Say goodbye」的行的螢幕截圖:
row_locator = page.get_by_role("listitem") row_locator .filter(has_text="Mary") .filter(has=page.get_by_role("button", name="Say goodbye")) .screenshot(path="screenshot.png")
5.5罕見例子
5.5.1對列表中每個元素執行操作
迭代元素
for row in page.get_by_role("listitem").all(): print(row.text_content())
使用常規 for 迴圈進行迭代:
rows = page.get_by_role("listitem") count = rows.count() for i in range(count): print(rows.nth(i).text_content())
5.5.2在頁面中評估
locator.evaluate_all()中的程式碼在頁面中執行,您可以在那裡呼叫任何 DOM API。
rows = page.get_by_role("listitem") texts = rows.evaluate_all("list => list.map(element => element.textContent)")
6.小結
定位器是非常嚴格。這意味著,如果多個元素匹配,則對定位器執行暗示某些目標 DOM 元素的所有操作都將引發異常。例如,如果 DOM 中有多個按鈕,則會引發以下呼叫:
如果有多個button,則引發錯誤
page.get_by_role("button").click()
另一方面,Playwright 瞭解何時執行多元素操作,因此當定位器解析為多個元素時,以下呼叫工作正常。
適用於多個元素
page.get_by_role("button").count()
您可以通過 locator.first、locator.last 和 locator.nth() 告訴 Playwright 在多個元素匹配時使用哪個元素來明確選擇退出嚴格性檢查。不建議使用這些方法,因為當您的頁面更改時,Playwright 可能會單擊您不想要的元素。相反,請按照上述最佳實踐建立唯一標識目標元素的定位器。
6.1其他定位器
對於不太常用的定位器,請檢視官網的其他定位器指南。由於時間關係,宏哥就不在這裡對其進行展開介紹和講解了。好了時間不早了,關於元素定位大法今天就分享到這裡!!!僅供大家學習參考,感謝您耐心的閱讀。
感謝您花時間閱讀此篇文章,如果您覺得這篇文章你學到了東西也是為了犒勞下博主的碼字不易不妨打賞一下吧,讓博主能喝上一杯咖啡,在此謝過了!
如果您覺得閱讀本文對您有幫助,請點一下左下角「推薦」按鈕,您的將是我最大的寫作動力!另外您也可以選擇【關注我】,可以很方便找到我!
本文版權歸作者和部落格園共有,來源網址:https://www.cnblogs.com/du-hong 歡迎各位轉載,但是未經作者本人同意,轉載文章之後必須在文章頁面明顯位置給出作者和原文連線,否則保留追究法律責任的權利!

