【Python】Locust持續優化:InfluxDB與Grafana實現資料持久化與視覺化分析
前言
在進行效能測試時,我們需要對測試結果進行監控和分析,以便於及時發現問題並進行優化。
Locust在記憶體中維護了一個時間序列資料結構,用於儲存每個事件的統計資訊。 這個資料結構允許我們在Charts分頁中檢視不同時間點的效能指標,但是正因為Locust WebUI上展示的資料實際上是儲存在記憶體中的。所以在Locust測試結束後,這些資料將不再可用。 如果我們需要長期儲存以便後續分析測試資料,可以考慮將Locust的測試資料上報到外部的資料儲存系統,如InfluxDB,並使用Grafana等視覺化工具進行展示和分析。
本文將介紹如何使用Locust進行負載測試,並將測試資料上報到InfluxDB。同時,我們將使用Grafana對測試資料進行展示和分析。
最終效果:

influxDB
InfluxDB是一款開源的時間序列資料庫,專為處理大量的時間序列資料而設計。時間序列資料通常是按照時間順序儲存的資料點,每個資料點都包含一個時間戳和一個或多個與之相關的值。這種資料型別在許多場景下都非常常見,如監控系統、物聯網裝置、金融市場資料等。在這些場景下,資料上報是一種關鍵的需求,因為它可以幫助我們實時瞭解系統的狀態和效能。
注: InfluxDB 開源的時單機版本,叢集版本並未開元,但是對於普通使用者的日常場景已經完全夠用。
以下是關於InfluxDB的關鍵特性和優勢的表格:
| 特性 | 優勢 |
|---|---|
| 高效能 | 針對時間序列資料進行了優化,可以快速地寫入和查詢大量資料。 |
| 資料壓縮 | 使用了高效的資料壓縮演演算法,在磁碟上節省大量空間。 |
| 自帶查詢語言 | 具有一種名為InfluxQL的查詢語言,類似於SQL,便於查詢和分析資料。 |
| 資料保留策略 | 支援設定資料保留策略,可以自動清除過期的資料。 |
| 易於整合 | 具有豐富的API和使用者端庫,可以輕鬆地與其他系統和工具整合。 |
安裝執行InfluxDB
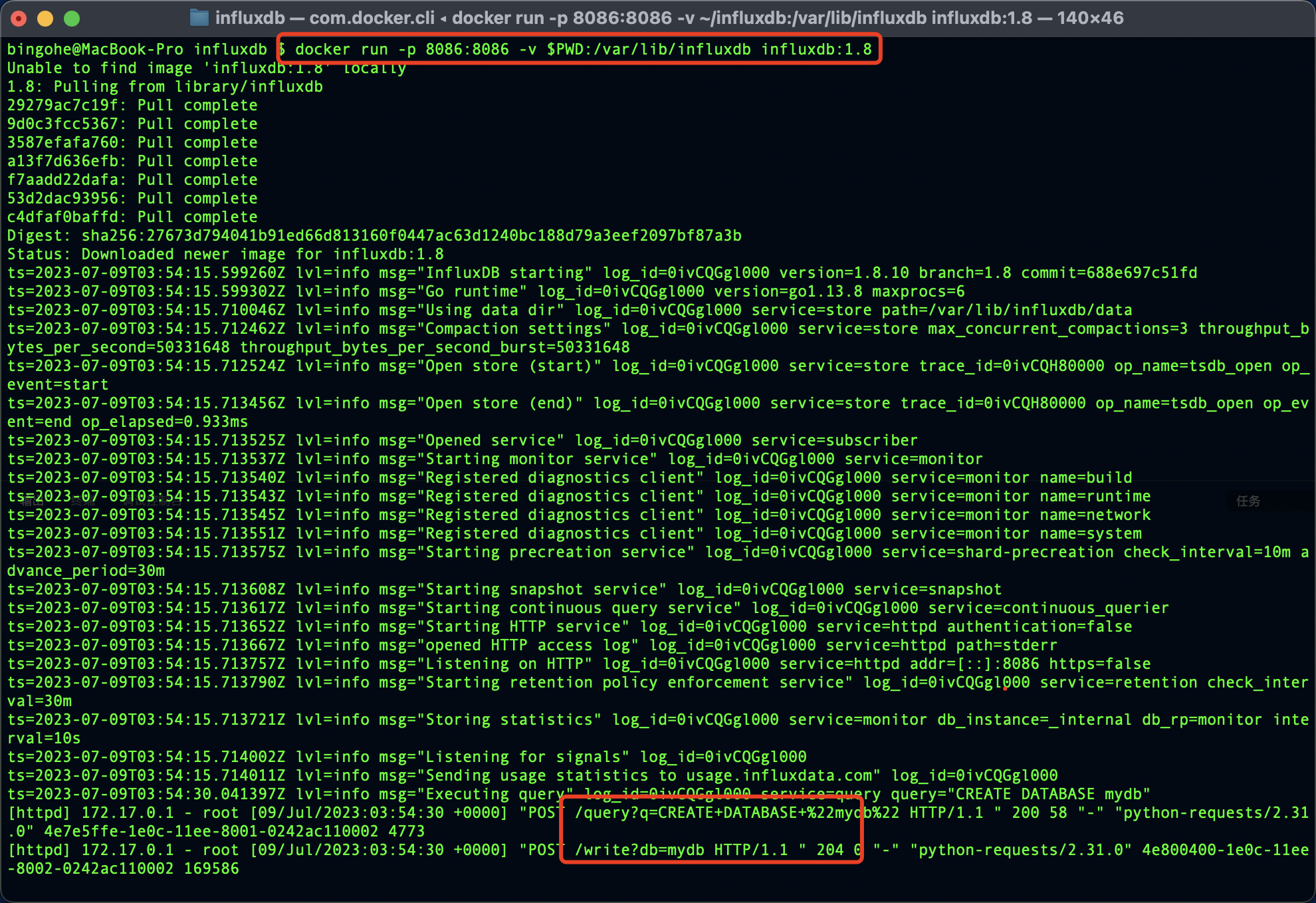
如果你已經安裝了Docker,可以直接使用官方的InfluxDB映象來執行InfluxDB:
docker run -p 8086:8086 -v $PWD:/var/lib/influxdb influxdb:1.8
此命令將在Docker容器中啟動InfluxDB,並將主機上的8086埠對映到容器的8086埠。
點選檢視在如何在不同作業系統中如何安裝 InfluxDB
InfluxDB的安裝方法因作業系統而異。以下是針對不同作業系統的InfluxDB安裝指南:
在Ubuntu上安裝InfluxDB
- 匯入InfluxDB的GPG key並新增倉庫:
wget -qO- https://repos.influxdata.com/influxdb.key | sudo gpg --dearmor -o /usr/share/keyrings/influxdb-archive-keyring.gpg
echo "deb [signed-by=/usr/share/keyrings/influxdb-archive-keyring.gpg] https://repos.influxdata.com/debian $(lsb_release -cs) stable" | sudo tee /etc/apt/sources.list.d/influxdb.list
- 更新倉庫並安裝InfluxDB:
sudo apt-get update
sudo apt-get install influxdb
- 啟動InfluxDB服務:
sudo systemctl unmask influxdb.service
sudo systemctl start influxdb
- 設定開機啟動:
sudo systemctl enable influxdb
在CentOS/RHEL上安裝InfluxDB
- 建立InfluxDB倉庫檔案:
sudo vi /etc/yum.repos.d/influxdb.repo
- 將以下內容新增到倉庫檔案中:
[influxdb]
name = InfluxDB Repository - RHEL \$releasever
baseurl = https://repos.influxdata.com/rhel/\$releasever/\$basearch/stable
enabled = 1
gpgcheck = 1
gpgkey = https://repos.influxdata.com/influxdb.key
- 安裝InfluxDB:
sudo yum install influxdb
- 啟動InfluxDB服務:
sudo systemctl start influxdb
- 設定開機啟動:
sudo systemctl enable influxdb
在macOS上安裝InfluxDB
使用Homebrew安裝InfluxDB:
brew install influxdb
啟動InfluxDB服務:
brew services start influxdb
更多關於InfluxDB安裝的詳細資訊,請參考官方檔案:https://docs.influxdata.com/influxdb/v2.1/install/
使用Python 上報資料到influxdb
首先,確保已經安裝了influxdb庫:
pip install influxdb
然後,使用以下程式碼上報資料到InfluxDB:
以下是一個使用Python操作InfluxDB上報資料的範例,對照MySQL進行註釋:
import time
from influxdb import InfluxDBClient
# 連線到InfluxDB(類似於連線到MySQL資料庫)
client = InfluxDBClient(host='localhost', port=8086)
# 建立資料庫(類似於在MySQL中建立一個新的資料庫)
client.create_database('mydb')
# 切換到建立的資料庫(類似於在MySQL中選擇一個資料庫)
client.switch_database('mydb')
# 上報資料(類似於在MySQL中插入一條記錄)
data = [
{
# 在InfluxDB中,measurement相當於MySQL中的表名
"measurement": "cpu_load",
# tags相當於MySQL中的索引列,用於快速查詢
"tags": {
"host": "server01",
"region": "us-west"
},
# time為時間戳,是InfluxDB中的關鍵欄位
"time": int(time.time_ns()),
# fields相當於MySQL中的資料列,用於儲存實際的資料值
"fields": {
"value": 0.64
}
}
]
# 寫入資料(類似於在MySQL中執行INSERT語句)
client.write_points(data)
在這個範例中,我們首先連線到InfluxDB(類似於連線到MySQL資料庫),然後建立一個名為mydb的資料庫(類似於在MySQL中建立一個新的資料庫),並切換到建立的資料庫(類似於在MySQL中選擇一個資料庫)。接著,我們準備了一條名為cpu_load的資料(在InfluxDB中,measurement相當於MySQL中的表名),併為資料新增了host和region標籤(類似於MySQL中的索引列)。最後,我們將資料寫入到InfluxDB中(類似於在MySQL中執行INSERT語句)。
執行上面的程式碼後我們可以看到我們的操作成功了:
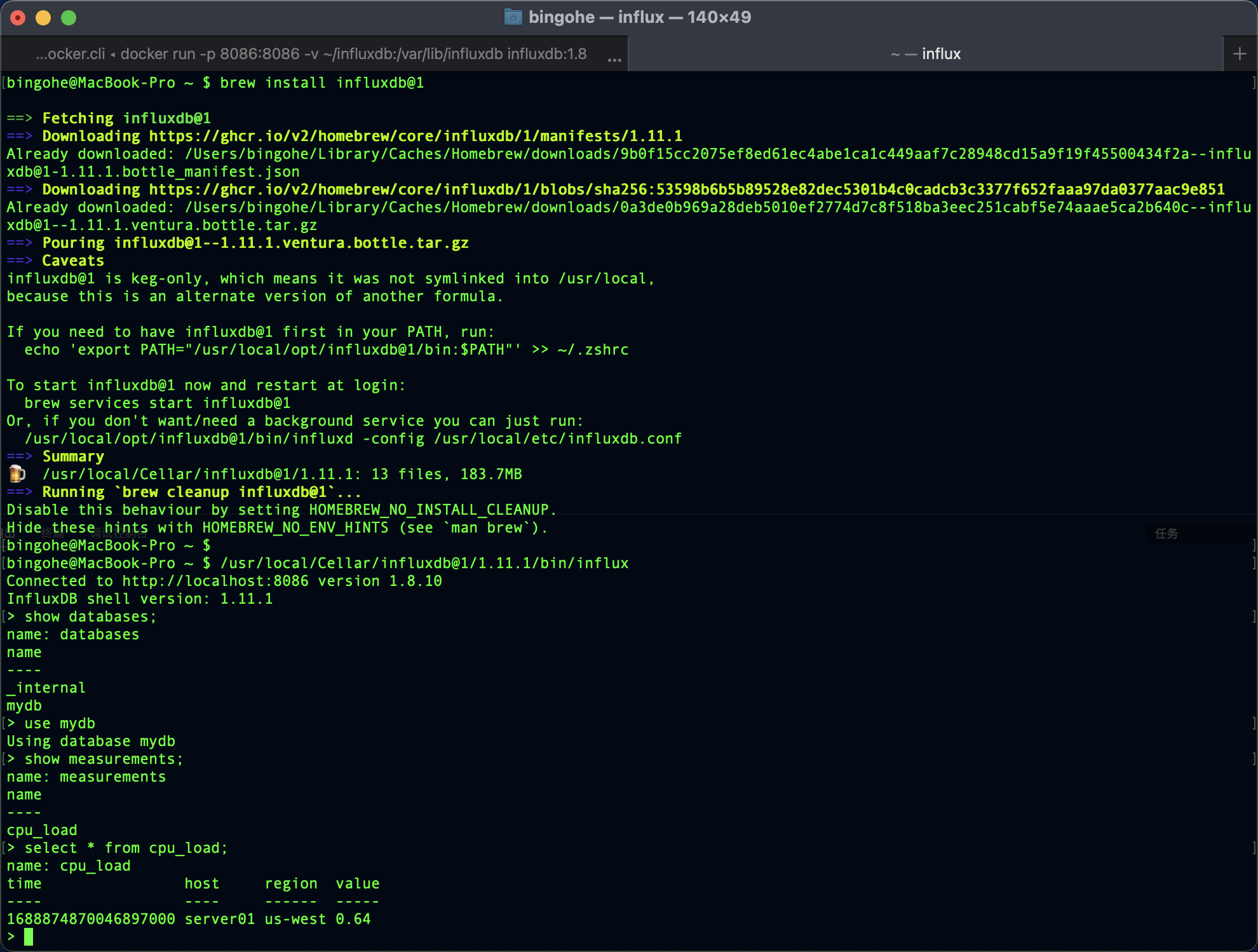
如果我們安裝了influx-cli就可以在命令列中直接查詢剛才寫入的資料:
bingohe@MacBook-Pro ~ $ /usr/local/Cellar/influxdb@1/1.11.1/bin/influx
Connected to http://localhost:8086 version 1.8.10
InfluxDB shell version: 1.11.1
> show databases;
name: databases
name
----
_internal
mydb
> use mydb
Using database mydb
> show measurements;
name: measurements
name
----
cpu_load
> select * from cpu_load;
name: cpu_load
time host region value
---- ---- ------ -----
1688874870046897000 server01 us-west 0.64
點選檢視如何使用命令列存取InfluxDB
要通過命令列存取InfluxDB,你可以使用InfluxDB的命令列使用者端工具influx。以下是安裝influx使用者端並通過命令列存取InfluxDB的步驟:
對於InfluxDB 1.x
- 安裝
influx使用者端:
- 在Ubuntu上:
sudo apt-get install influxdb-client
- 在CentOS/RHEL上:
sudo yum install influxdb
- 在macOS上:
brew install influxdb@1
- 使用
influx使用者端連線到InfluxDB:
influx -host localhost -port 8086
這將連線到執行在localhost上的InfluxDB範例,埠為8086。你現在應該進入了InfluxDB的命令列介面,可以執行InfluxQL查詢和管理操作。
對於InfluxDB 2.x
- 安裝
influx使用者端:
- 在Ubuntu上:
wget https://dl.influxdata.com/influxdb/releases/influxdb2-client-2.3.0-linux-amd64.tar.gz
tar xvfz influxdb2-client-2.3.0-linux-amd64.tar.gz
sudo cp influxdb2-client-2.3.0-linux-amd64/influx /usr/local/bin/
- 在CentOS/RHEL上:
wget https://dl.influxdata.com/influxdb/releases/influxdb2-client-2.3.0-linux-amd64.tar.gz
tar xvfz influxdb2-client-2.3.0-linux-amd64.tar.gz
sudo cp influxdb2-client-2.3.0-linux-amd64/influx /usr/local/bin/
- 在macOS上:
brew install influxdb@2
- 使用
influx使用者端連線到InfluxDB:
influx -host localhost -port 8086 -t your_token -o your_organization
這將連線到執行在localhost上的InfluxDB範例,埠為8086。同時,你需要提供你的令牌(token)和組織(organization)以進行身份驗證和授權。你現在應該進入了InfluxDB的命令列介面,可以執行InfluxQL查詢和管理操作。
命令列連線 influxdb
inlfux 預設執行的時,在macOS上,你可以通過以下命令找到InfluxDB 1.x的命令列工具:
brew list influxdb@1
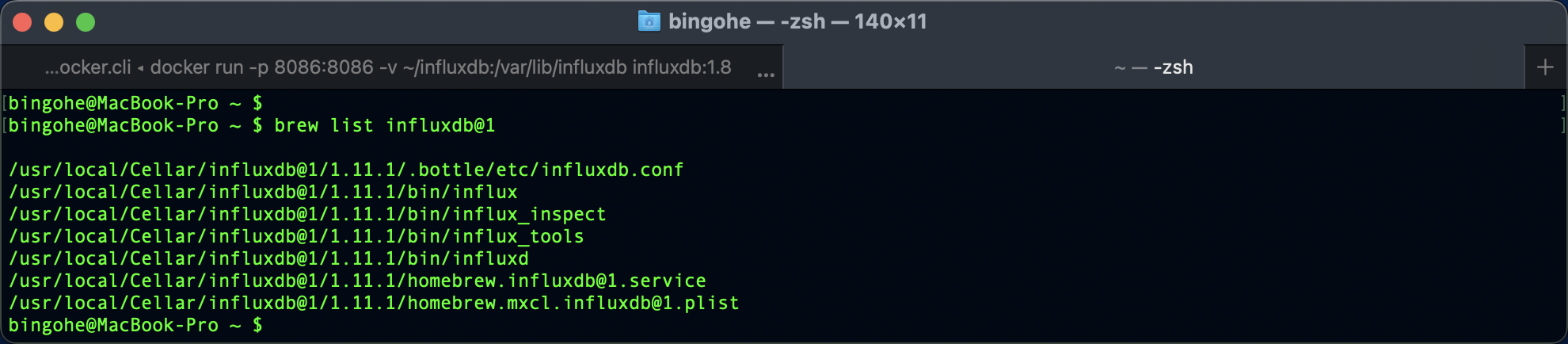
在輸出中,找到名為influx的可執行檔案,它應該位於bin目錄下。然後,使用完整路徑來執行influx命令列工具,例如:
/usr/local/Cellar/influxdb@1/1.8.10/bin/influx -host localhost -port 8086
請注意,上述路徑可能因InfluxDB版本和安裝位置的不同而有所不同。請根據實際情況進行調整。
Locust 資料寫入到 influx
在 【Python】萬字長文,Locust 效能測試指北(上) 中我們提到過Locust的生命週期,我們也通過Locust生命週期實現了集合點的功能。現在我們一起來通過它實現測試資料的實時展示。
Locust的生命週期
點選檢視Locust的生命週期
test_start:測試開始時觸發。spawning_start:生成使用者時觸發。user_add:每個使用者被新增時觸發。spawning_complete:所有使用者生成完成時觸發。request:每個請求發生時觸發。test_stop:測試停止時觸發。
上報資料
我們先來看看常用的事件裡面可以獲取到的資料:
import time
from locust import HttpUser, task, between, events
@events.request.add_listener
def request_handler(*args, **kwargs):
print(f"request args: {args}")
print(f"request kwargs: {kwargs}")
@events.worker_report.add_listener
def worker_report_handlers(*args, **kwargs):
print(f"worker_report args: {args}")
print(f"worker_report kwargs: {kwargs}")
@events.test_start.add_listener
def test_start_handlers(*args, **kwargs):
print(f"test_start args: {args}")
print(f"test_start kwargs: {kwargs}")
@events.test_stop.add_listener
def test_stop_handlers(*args, **kwargs):
print(f"test_stop args: {args}")
print(f"test_stop kwargs: {kwargs}")
class QuickstartUser(HttpUser):
wait_time = between(1, 2)
@task
def root(self):
with self.client.get("/", json={"time": time.time()}, catch_response=True) as rsp:
rsp_json = rsp.json()
if rsp_json["id"] != 5:
# 失敗時上報返回的資料
rsp.failure(f"{rsp_json}")
執行一次測試時能看到這些生命週期內的Locust 對外暴露的資料:
test_start args: ()
test_start kwargs: {'environment': <locust.env.Environment object at 0x10c426c70>}
request args: ()
request kwargs: {'request_type': 'GET', 'response_time': 2.6886250000011103, 'name': '/', 'context': {}, 'response': <Response [200]>, 'exception': None, 'start_time': 1688888321.896039, 'url': 'http://0.0.0.0:10000/', 'response_length': 8}
request args: ()
request kwargs: {'request_type': 'GET', 'response_time': 2.735957999998817, 'name': '/', 'context': {}, 'response': <Response [200]>, 'exception': CatchResponseError("{'id': 6}"), 'start_time': 1688888323.421389, 'url': 'http://0.0.0.0:10000/', 'response_length': 8}
test_stopping args: ()
test_stopping kwargs: {'environment': <locust.env.Environment object at 0x10c426c70>}
test_stop args: ()
test_stop kwargs: {'environment': <locust.env.Environment object at 0x10c426c70>}
從上面的監控我們可以看到,每次任務啟動和停止的時候會分別呼叫@events.test_start.add_listener和@events.test_stop.add_listener裝飾的函數,每次請求發生的的時候都會呼叫@events.request.add_listener 監聽器裝飾的函數,我們就是要利用這一點來進行資料的上報。
通過檢視 Locust 的 EventHook 原始碼註釋我們可以看到標準的使用方法:
#.../site-packages/locust/event.py
...
class EventHook:
"""
Simple event class used to provide hooks for different types of events in Locust.
Here's how to use the EventHook class::
my_event = EventHook()
def on_my_event(a, b, **kw):
print("Event was fired with arguments: %s, %s" % (a, b))
my_event.add_listener(on_my_event)
my_event.fire(a="foo", b="bar")
If reverse is True, then the handlers will run in the reverse order
that they were inserted
"""
...
結合前面的寫資料到 influxDB的實現,上報資料這一項一下子就變簡單了:
簡單實現每次請求資料上報 到 influxDB
下面的程式碼執行Locust測試後會自動建立一個locust_requests的 measurement,然後將每次請求的資料上報。
執行方法可以參考:【Python】萬字長文,Locust 效能測試指北(上)
import time
from datetime import datetime
from influxdb import InfluxDBClient
from locust import HttpUser, task, between, events
client = InfluxDBClient(host='localhost', port=8086, database="mydb")
def request(request_type, name, response_time, response_length, response, context, exception, url, start_time):
_time = datetime.utcnow()
was_successful = True
if response:
was_successful = 199 < response.status_code < 400
tags = {
'request_type': request_type,
'name': name,
'success': was_successful,
'exception': str(exception),
}
fields = {
'response_time': response_time,
'response_length': response_length,
}
data = {"measurement": 'locust_requests', "tags": tags, "time": _time, "fields": fields}
client.write_points([data])
# 在每次請求的時候通過前面定義的request函數寫資料到 DB
events.request.add_listener(request)
class QuickstartUser(HttpUser):
wait_time = between(1, 2)
@task
def root(self):
with self.client.get("/", json={"time": time.time()}, catch_response=True) as rsp:
rsp_json = rsp.json()
if rsp_json["id"] != 5:
rsp.failure(f"{rsp_json}")
上報的資料 influxDB 中查詢到:
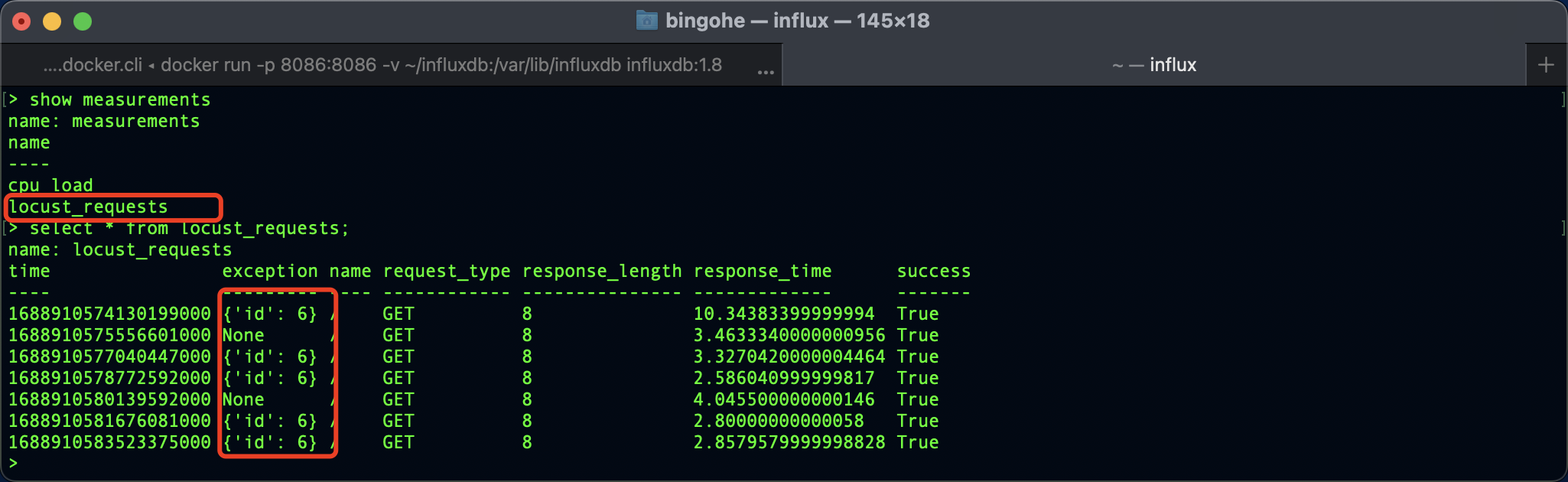
優化升級
上面的這個上報很粗糙,每次請求會上報一次資料,會影響實際的壓測,如果我們將要上報的資料放在一個資料結構中中,非同步的上報這個資料將極大的提升效能
# 將 __flush_points 方法中的寫入操作放到一個單獨的執行緒中,避免阻塞主執行緒,提高效能。
self.write_thread = threading.Thread(target=self.__write_points_worker)
# 批次寫入
if len(self.write_batch) >= self.batch_size or time.time() - self.last_flush_time >= self.interval_ms / 1000:
# 使用 gzip 壓縮上報的資料
influxdb_writer = InfluxDBWriter('localhost', 8086, 'mydb', batch_size=1000, gzip_enabled=True)
...
設定Grafana
在測試資料被上報到InfluxDB之後,可以通過Grafana進行資料展示和分析。需要先在Grafana中設定InfluxDB資料來源,然後建立相應的圖表和儀表盤。
在建立圖表和儀表盤時,可以選擇InfluxDB作為資料來源,並使用InfluxQL查詢語言進行資料查詢和過濾。可以根據需要選擇不同的圖表型別和顯示方式,以展示測試結果資料的趨勢和變化。
設定過程可以參考這篇部落格【Docker】效能測試監控平臺搭建:InfluxDB+Grafana+Jmeter+cAdvisor
總結
本文介紹瞭如何將Locust測試資料上報到InfluxDB,並通過Grafana進行展示和分析。通過將測試資料與監控工具相結合,可以更好地瞭解系統的效能和穩定性,及時發現問題並進行優化,也可以方便後續進行測試資料分析。希望本文能對大家有所幫助。
合抱之木,生於毫末;九層之臺,起於累土;千里之行,始於足下。