TiDB簡述及TiKV的資料結構與儲存
1 概述
TiDB 是 PingCAP 公司自主設計、研發的開源分散式關係型資料庫,是一款同時支援線上事務處理與線上分析處理 (Hybrid Transactional and Analytical Processing, HTAP) 的融合型分散式資料庫產品,具備水平擴容或者縮容、金融級高可用、實時 HTAP、雲原生的分散式資料庫、相容 MySQL 5.7 協定和 MySQL 生態等重要特性。目標是為使用者提供一站式 OLTP (Online Transactional Processing)、OLAP (Online Analytical Processing)、HTAP 解決方案。TiDB 適合高可用、強一致要求較高、資料規模較大等各種應用場景。
總結一下,Tidb是個高度相容MySQL的分散式資料庫,並擁有以下幾個特性:
- 高度相容 MySQL:掌握MySQL,就可以零基礎使用TIDB
- 水平彈性擴充套件:自適應擴充套件,基於Raft協定
- 分散式事務:悲觀鎖、樂觀鎖、因果一致性
- 真正金融級高可用:基於Raft協定
- 一站式 HTAP 解決方案:單個資料庫同時支援 OLTP 和 OLAP,進行實時智慧處理的能力
其中TiDB的核心特性是:水平擴充套件、高可用。
本文主要從TiDB的各類元件為起點,瞭解它的基礎架構,並重點分析它在儲存架構方面的設計,探究其如何組織資料,Table中的每行記錄是如何在記憶體和磁碟中進行儲存的。
2 元件
先看一張Tidb的架構圖,裡面包含 TiDB、Storage(TiKV、TiFlash)、TiSpark、PD。其中的TiDB、TiKV、PD是核心元件;TIFlash、TiSpark是為了解決複雜OLAP的元件。
TiDB是Mysql語法的互動入口,TiSpark是sparkSAL的互動入口。
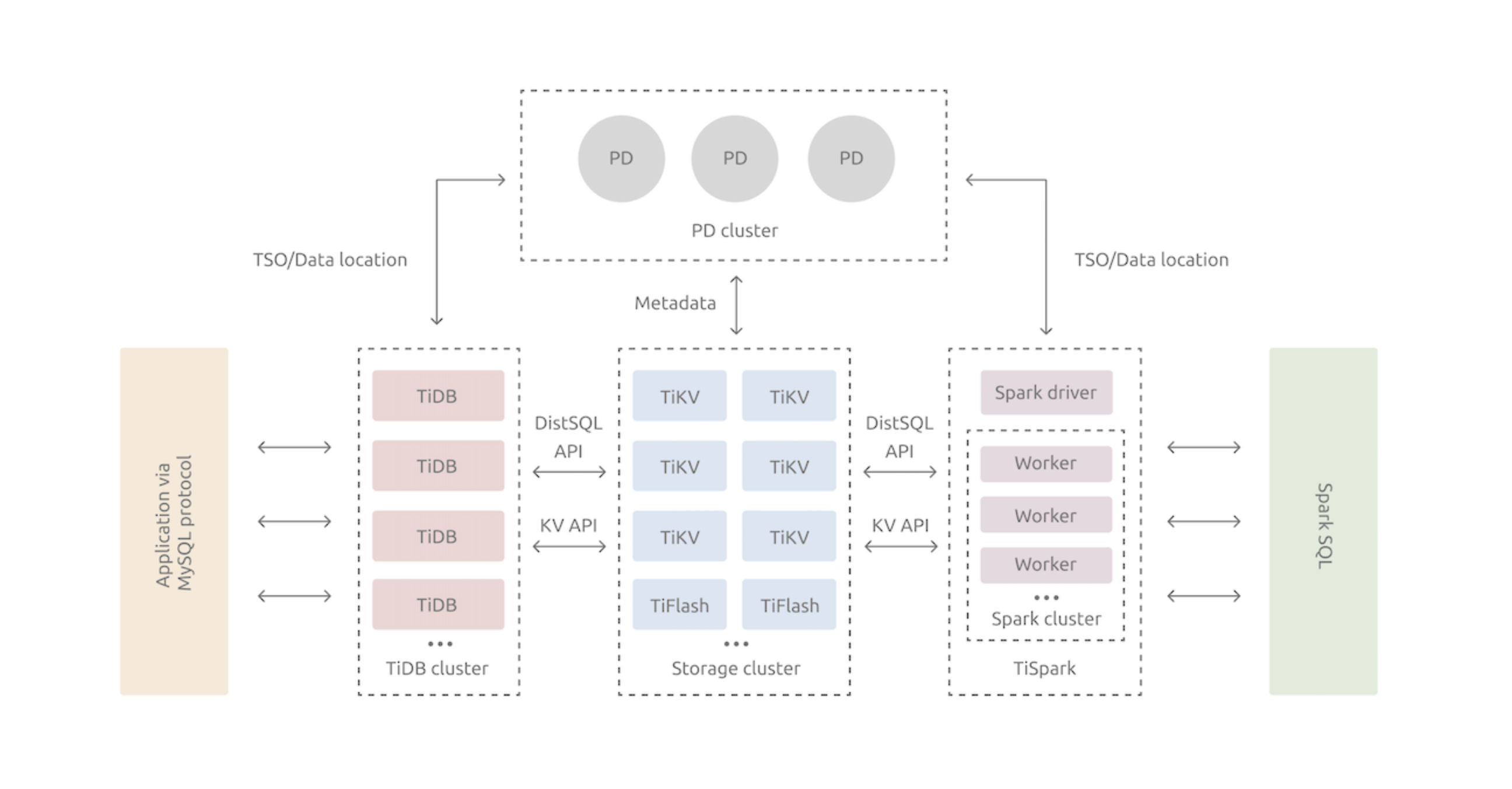
2.1 TiDB Server
SQL 層,對外暴露 MySQL 協定的連線 endpoint,負責接受使用者端的連線,執行 SQL 解析和優化,最終生成分散式執行計劃。
TiDB 層本身是無狀態的,實踐中可以啟動多個 TiDB 範例,通過負載均衡元件(如 LVS、HAProxy 或 F5)對外提供統一的接入地址,使用者端的連線可以均勻地分攤在多個 TiDB 範例上以達到負載均衡的效果。TiDB Server 本身並不儲存資料,只是解析 SQL,將實際的資料讀取請求轉發給底層的儲存節點 TiKV(或 TiFlash)。
2.2 PD (Placement Driver) Server
整個 TiDB 叢集的元資訊管理模組,負責儲存每個 TiKV 節點實時的資料分佈情況和叢集的整體拓撲結構,提供 TiDB Dashboard 管控介面,併為分散式事務分配事務 ID。
PD 不僅儲存元資訊,同時還會根據 TiKV 節點實時上報的資料分佈狀態,下發資料排程命令給具體的 TiKV 節點,可以說是整個叢集的「大腦」。此外,PD 本身也是由至少 3 個節點構成,擁有高可用的能力。建議部署奇數個 PD 節點。
2.3 儲存節點
2.3.1 TiKV Server
負責儲存資料,從外部看 TiKV 是一個分散式的提供事務的 Key-Value 儲存引擎。
儲存資料的基本單位是 Region,每個 Region 負責儲存一個 Key Range(從 StartKey 到 EndKey 的左閉右開區間)的資料,每個 TiKV 節點會負責多個 Region。
TiKV 的 API 在 KV 鍵值對層面提供對分散式事務的原生支援,預設提供了 SI (Snapshot Isolation) 的隔離級別,這也是 TiDB 在 SQL 層面支援分散式事務的核心。
TiDB 的 SQL 層做完 SQL 解析後,會將 SQL 的執行計劃轉換為對 TiKV API 的實際呼叫。所以,資料都儲存在 TiKV 中。另外,TiKV 中的資料都會自動維護多副本(預設為三副本),天然支援高可用和自動故障轉移。
2.3.2 TiFlash
TiFlash 是一類特殊的儲存節點。和普通 TiKV 節點不一樣的是,在 TiFlash 內部,資料是以列式的形式進行儲存,主要的功能是為分析型的場景加速。假如使用場景為海量資料,且需要進行統計分析,可以在資料表基礎上建立TiFlash儲存結構的對映表,以提高查詢速度。
以上元件互相配合,支撐著Tidb完成海量資料儲存、同時兼顧高可用、事務、優秀的讀寫效能。
3 儲存架構
3.1 TiKV的模型
前文所描述的Tidb架構中,其作為儲存節點的有兩個服務,TiKV和TiFlash。其中TiFlash為列式儲存的形式實現的,可以參考ClickHouse的架構思路,二者具有相似性。本章節主要討論TiKV的實現。
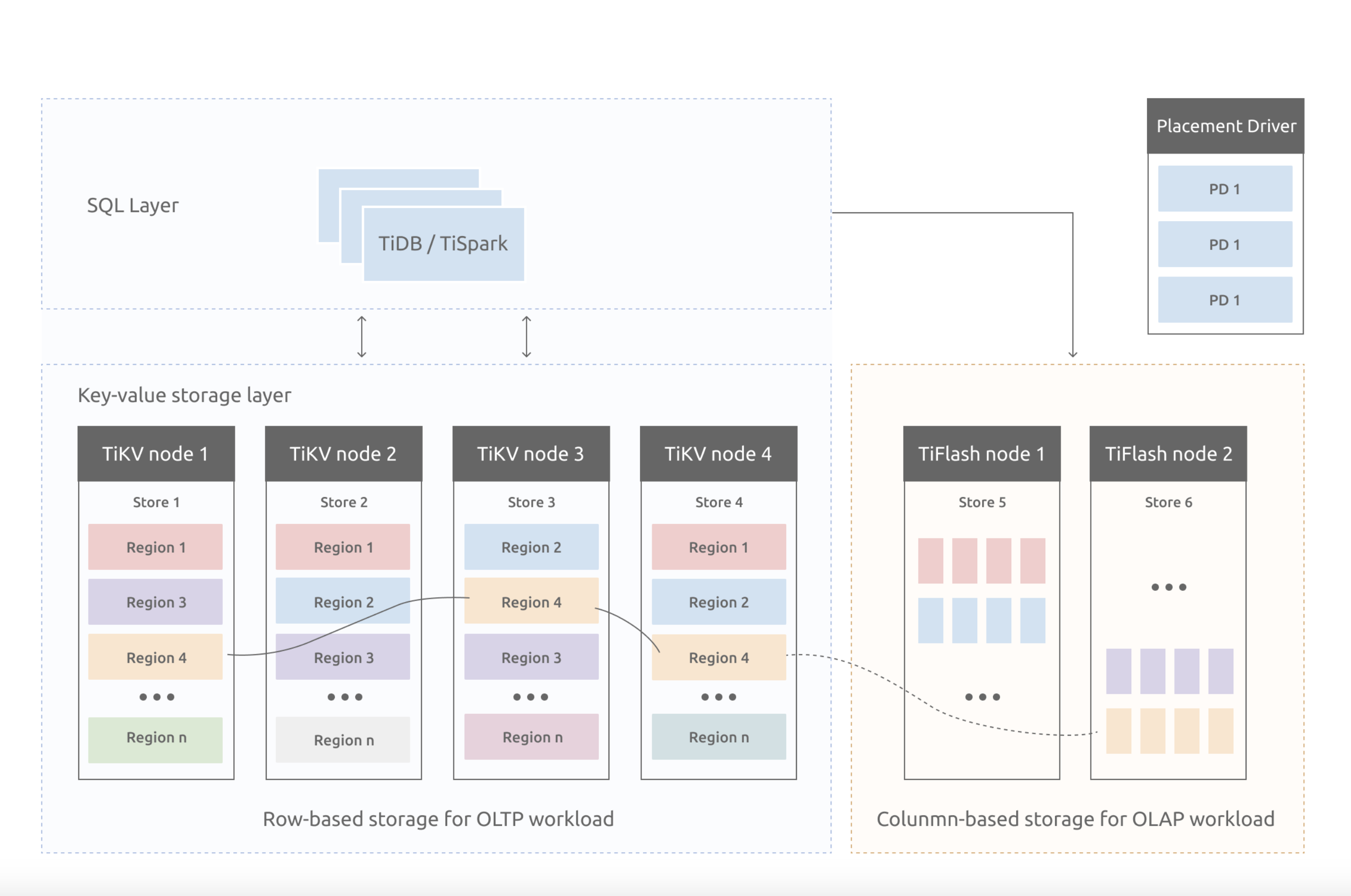
在上圖中,TiKV node所描述的就是OLTP場景下Tidb的儲存元件,而TiFlash則是應對的LOAP場景。TiKV選擇的是Key-Value模型,作為資料的儲存模型,並提供有序遍歷方法進行讀取。
TiKV資料儲存有兩個關鍵點:
- 是一個巨大的Map(可以參考HashMap),也就是儲存的是Key-Value Pairs(鍵值對)。
- 這個Map中的Key-Value pair按照Key的二進位制順序有序,也就是可以Seek到某一個Key的位置,然後不斷地呼叫Next方法,以遞增的順序獲取比這個Key大的Key-Value。
需要注意的是,這裡描述的TiKV的KV儲存模型,與SQL中的Table無關,不要有任何代入。
在圖中TiKV node內部,有store、Region的概念,這是高可用的解決方案,TiDB採用了Raft演演算法實現,這裡細分析。
3.2 TiKV的行儲存結構
在使用Tidb時,依然以傳統「表」的概念進行讀寫,在關係型資料庫中,一個表可能有很多列。而Tidb是以Key-Value形式構造資料的,因此需要考慮,將一行記錄中,各列資料對映成一個key-value鍵值對。
首先,在OLTP場景,有大量針對單行或者多行的增、刪、改、查操作,要求資料庫具備快速讀取一行資料的能力。因此,對應的 Key 最好有一個唯一 ID(顯示或隱式的 ID),以方便快速定位。
其次,很多 OLAP 型查詢需要進行全表掃描。如果能夠將一個表中所有行的 Key 編碼到一個區間內,就可以通過範圍查詢高效完成全表掃描的任務。
3.2.1 表資料的KV對映
Tidb中表資料與Key-Value的對映關係,設計如下:
- 為了保證同一個表的資料會放在一起,方便查詢,TiDB會為每個表分配一個表ID,用TableID表示,整數、全域性唯一。
- TiDB會為每行資料分配一個行ID,用RowID表示,整數、表內唯一。如果表有主鍵,則行ID等於主鍵。
基於以上規則,生成的Key-Value鍵值對為:
Key: tablePrefix{TableID}_recordPrefixSep{RowID}
Value: [col1,col2,col3,col4]
其中 tablePrefix 和 recordPrefixSep 都是特定的字串常數,用於在 Key 空間內區分其他資料。
這個例子中,是完全基於RowID形成的Key,可以類比MySQL的聚集索引。
3.2.2 索引資料的KV對映
對於普通索引,在MySQL中是有非聚集索引概念的,尤其innodb中,通過B+Tree形式,子節點記錄主鍵資訊,再通過回表方式得到結果資料。
在Tidb中是支援建立索引的,那麼索引資訊如何儲存? 它同時支援主鍵和二級索引(包括唯一索引和非唯一索引),且與表資料對映方式類似。
設計如下:
- Tidb為表中每個索引,分配了一個索引ID,用IndexID表示。
- 對於主鍵和唯一索引,需要根據鍵值快速定位到RowID,這個會儲存到value中
因此生成的key-value鍵值對為:
Key:tablePrefix{TableID}_indexPrefixSep{IndexID}_indexedColumnsValue
Value: RowID
由於設計的key中存在indexedColumnsValue,也就是查詢的欄位值,因此可以直接命中或模糊檢索到。再通過value中的RowID,去表資料對映中,檢索到RowID對應的行記錄。
對於普通索引,一個鍵值可能對應多行,需要根據鍵值範圍查詢對應的RowID。
Key: tablePrefix{TableID}_indexPrefixSep{IndexID}_indexedColumnsValue_{RowID}
Value: null
根據欄位值,可以檢索到具有相關性的key的列表,在根據key中包含的RowID,再拿到行記錄。
3.2.3 對映中的常數字串
上述所有編碼規則中的 tablePrefix、recordPrefixSep 和 indexPrefixSep 都是字串常數,用於在 Key 空間內區分其他資料,定義如下:
tablePrefix = []byte{'t'}
recordPrefixSep = []byte{'r'}
indexPrefixSep = []byte{'i'}
在上述對映關係中,一個表內所有的行都有相同的 Key 字首,一個索引的所有資料也都有相同的字首。這樣具有相同的字首的資料,在 TiKV 的 Key 空間內,是排列在一起的。
因此,只需要設計出穩定的字尾,則可以保證表資料或索引資料,有序的儲存在TiKV中。而有序帶來的價值就是能夠高效的讀取。
3.2.4 舉例
假設資料庫的一張表,如下:
CREATE TABLE User (
ID int,
Name varchar(20),
Role varchar(20),
Age int,
PRIMARY KEY (ID),
KEY idxAge (Age)
);
表中有3行記錄:
1, "TiDB", "SQL Layer", 10
2, "TiKV", "KV Engine", 20
3, "PD", "Manager", 30
4, "TiFlash", "OLAP", 30
這張表中有一個主鍵ID、一個普通索引idxAge,對應的是列Age.
假設該表的TableID=10,則其表資料的儲存如下:
t10_r1 --> ["TiDB", "SQL Layer", 10]
t10_r2 --> ["TiKV", "KV Engine", 20]
t10_r3 --> ["PD", "Manager", 30]
t10_r4 --> ["TiFlash", "OLAP", 30]
其普通索引idxAge的儲存如下:
t10_i1_10_1 --> null
t10_i1_20_2 --> null
t10_i1_30_3 --> null
t10_i1_30_4 --> null
3.3 SQL與KV對映
TiDB 的 SQL 層,即 TiDB Server,負責將 SQL 翻譯成 Key-Value 操作,將其轉發給共用的分散式 Key-Value 儲存層 TiKV,然後組裝 TiKV 返回的結果,最終將查詢結果返回給使用者端。
舉例,「select count(*) from user where name=’tidb’;」這樣的SQL語句,在Tidb中進行檢索,流程如下:
- 根據表名、所有的RowID,結合表資料的Key編碼規則,構造出一個[StartKey,endKey)的左閉右開區間。
- 根據[StartKey,endKey)這個區間內的值,到TiKV中讀取資料
- 得到每一行記錄後,過濾出name=’tidb’的資料
- 將結果進行統計,計算出count(*)的結果,進行返回。
在分散式環境下,為了提高檢索效率,實際執行過程中,上述流程是會將name=’tidb’和count( *)下推到叢集的每個節點中,減少無異議的網路傳輸,每個節點最終將count( *)的結果,再由SQL層將結果累加求和。
4 RockDB 持久化
4.1 概述
前文所描述的Key-Value Pairs只是儲存模型,是存在於記憶體中的,任何持久化的儲存引擎,資料終歸要儲存在磁碟上。TiKV 沒有選擇直接向磁碟上寫資料,而是把資料儲存在 RocksDB 中,具體的資料落地由 RocksDB 負責。
這個選擇的原因是開發一個單機儲存引擎工作量很大,特別是要做一個高效能的單機引擎,需要做各種細緻的優化,而 RocksDB 是由 Facebook 開源的一個非常優秀的單機 KV 儲存引擎,可以滿足 TiKV 對單機引擎的各種要求。這裡可以簡單的認為 RocksDB 是一個單機的持久化 Key-Value Map。
4.2 RocksDB
TiKV Node的內部被劃分成多個Region,這些Region作為資料切片,是資料一致性的基礎,而TiKV的持久化單元則是Region,也就是每個Region都會被儲存在RocksDB範例中。
以Region為單元,是基於順序I/O的效能考慮的。而TiKV是如何有效的組織Region內的資料,保證分片均勻、有序,這裡面用到了LSM-Tree,如果有HBase經驗一定不模式。
4.2.1 LSM-Tree結構
LSM-Tree(log structured merge-tree)字面意思是「紀錄檔結構的合併樹」,LSM-Tree的結構是橫跨磁碟和記憶體的。它將儲存媒介根據功能,劃分磁碟的WAL(write ahead log)、記憶體的MemTable、磁碟的SST檔案;其中SST檔案又分為多層,每一層資料達到閾值後,會挑選一部分SST合併到下一層,每一層的資料是上一層的10倍,因此90%的資料會儲存在最後一層。
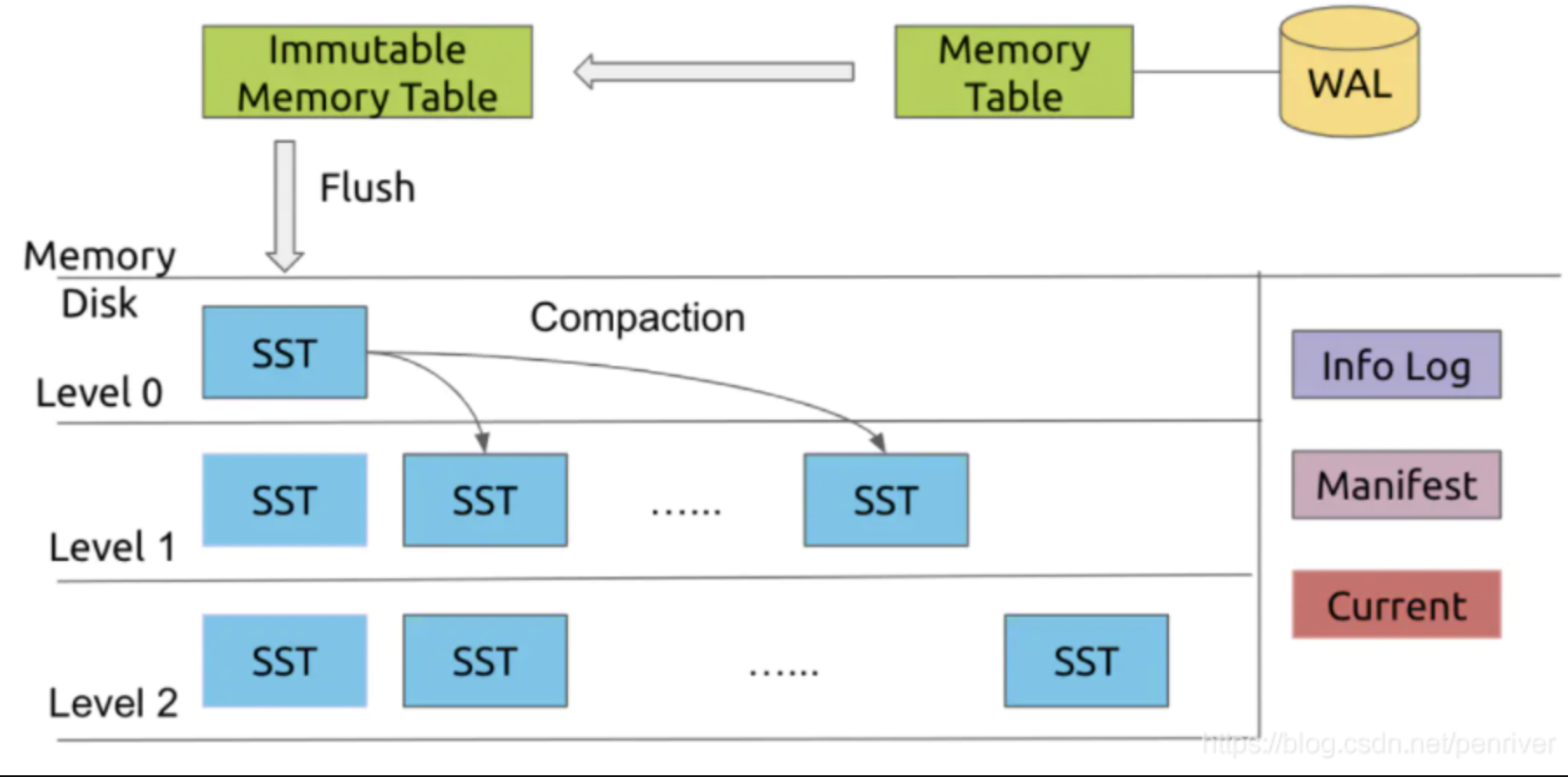
WAL:是預寫Log的實現,當進行寫操作時,會將資料通過WAL方式備份到磁碟中,防止記憶體斷電而丟失。
Memory-Table:是在記憶體中的資料結構,用以儲存最近的一些更新操作;memory-table可以使用跳躍表或者搜尋樹等資料結構來組織資料,以保持資料的有序性。當memory-table達到一定的資料量後,memory-table會轉化成為immutable memory-table,同時會建立一個新的memory-table來處理新的資料。
Immutable Memory-Table:immutable memory-table在記憶體中是不可修改的資料結構,它是將memory-table轉變為SSTable的一種中間狀態。目的是為了在轉存過程中不阻塞寫操作。寫操作可以由新的memory-table處理,而不用因為鎖住memory-table而等待。
SST或SSTable:有序鍵值對集合,是LSM樹組在磁碟中的資料的結構。如果SSTable比較大的時候,還可以根據鍵的值建立一個索引來加速SSTable的查詢。SSTable會存在多個,並且按Level設計,每一層級會存在多個SSTable檔案。
4.2.2 LSM-Tree執行過程
寫入過程
- 首先會檢查每個區域的儲存是否達到閾值,未達到會直接寫入;
- 如果Immutable Memory-Table存在,會等待其壓縮過程。
- 如果Memory-Table已經寫滿,Immutable Memory-Table 不存在,則將當前Memory-Table設定為Immutable Memory-Table,生成新的Memory-Table,再觸發壓縮,隨後進行寫入。
- 寫的過程會先寫入WAL,成功後才會寫Memory-Table,此刻寫入才完成。
資料存在的位置,按順序會依次經歷WAL、Memory-Table、Immutable Memory-Table、SSTable。其中SSTable是資料最終持久化的位置。而事務性寫入只需要經歷WAL和Memory-Table即可完成。
查詢過程
1.根據目標key,逐級依次在Memory-Table、Immutable Memory-Table、SSTable中查詢
2.其中SSTable會分為幾個級別,也是按Level中進行查詢。
- Level-0級別,RocksDB會採用遍歷的方式,所有為了查詢效率,會控制Level-0的檔案個數。
- 而Level-1及以上層級的SSTable,資料不會存在交疊,且由於儲存有序,會採用二分查詢提高效率。
RocksDB為了提高查詢效率,每個Memory-Table和SSTable都會有相應的Bloom Filter來加快判斷Key是否可能在其中,以減少查詢次數。
刪除和更新過程
當有刪除操作時,並不需要像B+樹一樣,在磁碟中的找到相應的資料後再刪除。
- 首先會在通過查詢流程,在Memory-Table、Immuatble Memory-Table中進行查詢。
- 如果找到則對結果標記為「刪除」。
- 否則會在結尾追加一個節點,並標記為「刪除」
在真正刪除前,未來的查詢操作,都會先找到這個被標記為「刪除」的記錄。 - 之後會在某一時刻,通過壓縮過程真正刪除它。
更新操作和刪除操作類似,都是隻操作記憶體區域的結構,寫入一個標誌,隨後真正的更新操作被延遲在合併時一併完成。由於操作是發生在記憶體中,其讀寫效能也能保障。
4.3 RockDB 的優缺點
優點
- 將資料拆分為幾百M大小的塊,然後順序寫入
- 首次寫入的目的地是記憶體,採用WAL設計思路,加上順序寫,提高寫入的能力,時間複雜度近似常數
- 支援事務,但L0層的資料,key的區間有重疊,支援較差
缺點
- 讀寫放大嚴重
- 應對突發流量的時候,削峰能力不足
- 壓縮率有限
- 索引效率較低
- 壓縮過程比較消耗系統資源,同時對讀寫影響較大
5 總結
以上針對TiDB的整體架構進行建單介紹,並著重描述了TiKV是如何組織資料、如何儲存資料。將其Key-Value的設計思路,與MySQL的索引結構進行對比,識別相似與差異。TiDB依賴RockDB實現了持久化,其中的Lsm-Tree,作為B+Tree的改進結構,其關注中心是「如何在頻繁的資料改動下保持系統讀取速度的穩定性」,以順序寫磁碟作為目標,假設頻繁地對資料進行整理,力求資料的順序性,帶來讀效能的穩定,同時也帶來了一定程度的讀寫放大問題。
作者:京東物流 耿宏宇
來源:京東雲開發者社群 自猿其說Tech