聊一聊Java中的Steam流
1 引言
在我們的日常程式設計任務中,對於集合的製造和處理是必不可少的。當我們需要對於集合進行分組或查詢的操作時,需要用迭代器對於集合進行操作,而當我們需要處理的資料量很大的時候,為了提高效能,就需要使用到並行處理,這樣的處理方式是很複雜的。流可以幫助開發者節約寶貴的時間,讓以上的事情變得輕鬆。
2 流簡介
流到底是什麼呢?簡要的定義為「從支援資料處理操作的源生成的元素序列」,接下來對於這個定義進行簡要分析。
2.1 支援資料處理操作
流的資料處理操作和資料庫的可以宣告式的指定分組或查詢等功能支援類似,和函數語言程式設計的思想一致,如filter、map、reduce、find、match、sort等操作,這些流操作可以序列執行,也可以並行執行。
2.2 源
流會使用一個提供資料的源,可以通過三種方式來建立物件流,一種是由集合物件建立流:
List<Integer> list = Arrays.asList(111,222,333);
Stream<Integer> stream = list.stream();
一種是由陣列建立流:
IntStream stream = Arrays.stream(new int(){111,222,333});
一種是由靜態方法Stream.of()建立流,底層還是Arrays.stream():
Stream<Integer> stream = Stream.of(111, 222, 333);
Stream stream = Stream.of(111, 222, 333);
從有序集合生成流時會保留原有的順序。由列表生成的流,其元素順序與列表一致。
還有兩種特殊的流:
- 空流:Stream.empty()
- 無限流:Stream.genarate()
2.3 元素序列
流也可以和集合一樣存取包含特定的元素型別的一組有序值,但是它們的主要目的不一樣,集合的主要目的是在於儲存和存取元素,流的主要目的在於表達計算。
3 流的思想
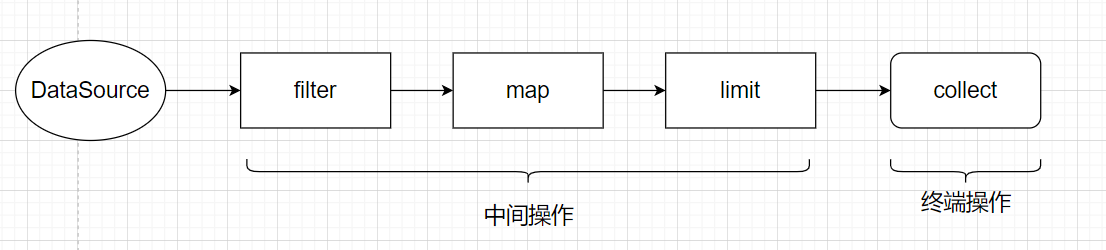
流式思想和生產中的流水線具有異曲同工之妙,很多流模型都會返回一個流,這些模型都只負責它所需要做的事情,並不需要格外的記憶體空間來儲存處理的結果。這些流模型可以被連結起來形成一個大的流水線,我們在這個過程中不關注中間步驟的資料被如何處理,只需要使用整個流水線處理後的結果。接下來的程式碼可以體現這種思想,程式碼中以商品為例,我們要篩選出商品中體積大於200的前兩個商品的名字。
首先是商品類的定義:
public class Goods {
private final String Name;
private final Integer Volume;
public Goods(String name, Integer volume) {
Name = name;
Volume = volume;
}
public String getName() {
return Name;
}
public Integer getVolume() {
return Volume;
}
}
接下來是商品集合的定義:
List<Goods> goods = Arrays.asList(new Goods("土豆",10),
new Goods("冰箱",900),new Goods("辦公椅",300));
接下來獲取我們想要的結果:
List<String> twofoods = goods.stream()//獲取流
.filter(goods1 -> goods1.getVolume()>200)//篩選商品體積大於200的
.map(Goods::getName)//獲取商品名稱
.limit(2)//篩選頭兩個商品
.collect(Collectors.toList());//將結果儲存在list中
這樣看來,通過流來處理我們的特定需求,是不是比使用集合的迭代要方便很多呢?
4 流處理的特性
- 不儲存資料
- 不會改變資料來源
- 只可被使用一次
這裡我們使用一個測試類StreamCharacteristic來驗證流處理的以上特性:
import org.springframework.util.Assert;
import java.util.Arrays;
import java.util.List;
import java.util.stream.Collectors;
import java.util.stream.Stream;
public class StreamCharacteristic {
public void test1(){
List<Integer> list = Arrays.asList(1,2,2,5,6,9);
list.stream().distinct();
System.out.println(list.size());
}
public void test2(){
List<String> list = Arrays.asList("wms", "KA", "5.0");
Stream<String> stream = list.stream();
stream.forEach(System.out::println);
stream.forEach(System.out::println);
}
}
test1()中的結果為6,儘管我們對於list物件所生成的Stream流做了去重操作distinct(),但是不影響資料來源list。
test2()中呼叫了兩次 stream.forEach方法來列印每一個單詞,第二次呼叫時,丟擲了一個「java.lang.IllegalStateException」異常:「stream has already been operated upon or closed」。這說明流不儲存資料,遍歷完後這個流已經被消費掉了,而且流不可以重複使用。
5 流操作與流的使用
將所有的流操作連線起來可以組合成一個管道,管道有兩類操作:中間操作和終端操作。
StreamAPI常用的中間操作有:filter,map,limit,sorted,distinct。
StreamAPI常用的終端操作有:forEach,count,collect。
在使用流的時候,主要需要三個要素:一個用來執行查詢的資料來源,用來形成一條流的流水線的中間操作鏈,一個能夠執行流水線並能生成結果的終端操作。
下圖展示了流的整個操作流程:
6 總結
- 流是從支援資料處理操作的源生成的元素序列
- 流的思想類似於生產中的流水線
- 流不儲存資料,不改變資料來源,只能被改變一次
- 流的操作主要分為中間操作和終端操作兩大類
作者:京東物流 王辰瑋
來源:京東雲開發者社群 自猿其說Tech