Go 並行模型—Goroutines
前言
Goroutines 是 Go 語言主要的並行原語。它看起來非常像執行緒,但是相比於執行緒它的建立和管理成本很低。Go 在執行時將 goroutine 有效地排程到真實的執行緒上,以避免浪費資源,因此您可以輕鬆地建立大量的 goroutine(例如每個請求一個 goroutine),並且您可以編寫簡單的,命令式的阻塞程式碼。因此,Go 的網路程式碼往往比其它語言中的等效程式碼更直接,更容易理解(這點從下文中的範例程式碼可以看出)。
對我來說,goroutine 是將 Go 這門語言與其它語言區分開來的一個主要特徵。這就是為什麼大家更喜歡用 Go 來編寫需要並行的程式碼。在下面討論更多關於 goroutine 之前,我們先了解一些歷史,這樣你就能理解為什麼你想要它們了。
基於 fork 和執行緒
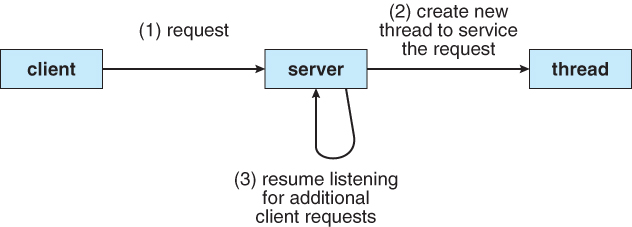
高效能伺服器需要同時處理來自多個使用者端的請求。有很多方法可以設計一個伺服器端架構來處理這個問題。最容易想到的就是讓一個主程序在迴圈中呼叫 accept,然後呼叫 fork 來建立一個處理請求的子程序。這篇 Beej's Guide to Network Programming 指南中提到了這種方式。
在網路程式設計中,fork 是一個很好的模式,因為你可以專注於網路而不是伺服器架構。但是它很難按照這種模式編寫出一個高效的伺服器,現在應該沒有人在實踐中使用這種方式了。
fork 同時也存在很多問題,首先第一個是成本: Linux 上的 fork 呼叫看起來很快,但它會將你所有的記憶體標記為 copy-on-write。每次寫入 copy-on-write 頁面都會導致一個小的頁面錯誤,這是一個很難測量的小延遲,程序之間的上下文切換也很昂貴。
另一個問題是規模: 很難在大量子程序中協調共用資源(如 CPU、記憶體、資料庫連線等)的使用。如果流量激增,並且建立了太多程序,那麼它們將相互爭奪 CPU。但是如果限制建立的程序數量,那麼在 CPU 空閒時,大量緩慢的使用者端可能會阻塞每個人的正常使用,這時使用超時機制會有所幫助(無論伺服器架構如何,超時設定都是很必要的)。
通過使用執行緒而不是程序,上面這些問題在一定程度上能得到緩解。建立執行緒比建立程序更「便宜」,因為它共用記憶體和大多數其它資源。在共用地址空間中,執行緒之間的通訊也相對容易,使用號誌和其它結構來管理共用資源,然而,執行緒仍然有很大的成本,如果你為每個連線建立一個新執行緒,你會遇到擴充套件問題。與程序一樣,你此時需要限制正在執行的執行緒的數量,以避免嚴重的 CPU 爭用,並且需要使慢速請求超時。建立一個新執行緒仍然需要時間,儘管可以通過使用執行緒池在請求之間回收執行緒來緩解這一問題。
無論你是使用程序還是執行緒,你仍然有一個難以回答的問題: 你應該建立多少個執行緒?如果您允許無限數量的執行緒,使用者端可能會用完所有的記憶體和 CPU,而流量會出現小幅激增。如果你限制伺服器的最大執行緒數,那麼一堆緩慢的使用者端就會阻塞你的伺服器。雖然超時是有幫助的,但它仍然很難有效地使用你的硬體資源。
基於事件驅動
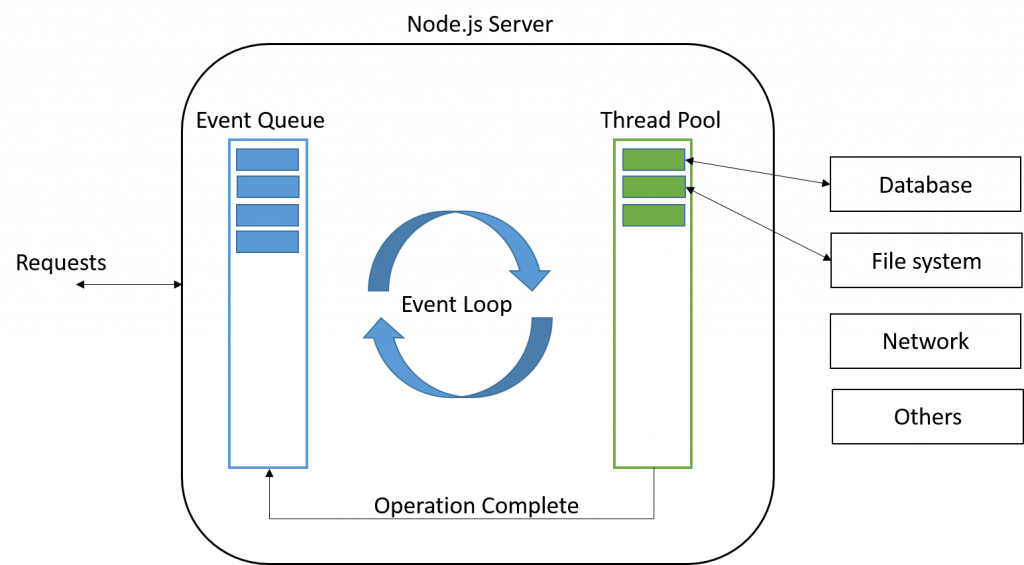
那麼既然無法輕易預測出需要多少執行緒,當如果嘗試將請求與執行緒解耦時會發生什麼呢?如果我們只有一個執行緒專門用於應用程式邏輯(或者可能是一個小的、固定數量的執行緒),然後在後臺使用非同步系統呼叫處理所有的網路流量,會怎麼樣?這就是一種 事件驅動 的伺服器端架構。
事件驅動架構模式是圍繞 select 系統呼叫設計的。後來像 poll 這樣的機制已經取代了 select,但是 select 是廣為人知的,它們在這裡都服務於相同的概念和目的。select 接受一個檔案描述符列表(通常是通訊端),並返回哪些是準備好讀寫的。如果所有檔案描述符都沒有準備好,則選擇阻塞,直到至少有一個準備好。
#include <sys/select.h>
#include <poll.h>
int select(int nfds,
fd_set *restrict readfds,
fd_set *restrict writefds,
fd_set *restrict exceptfds,
struct timeval *restrict timeout);
int poll(struct pollfd *fds,
nfds_t nfds,
int timeout);
為了實現一個事件驅動的伺服器,你需要跟蹤一個 socket 和網路上被阻塞的每個請求的一些狀態。在伺服器上有一個單一的主事件迴圈,它呼叫 select 來處理所有被阻塞的通訊端。當 select 返回時,伺服器知道哪些請求可以進行了,因此對於每個請求,它呼叫應用程式邏輯中的儲存狀態。當應用程式需要再次使用網路時,它會將通訊端連同新狀態一起新增回「阻塞」池中。這裡的狀態可以是應用程式恢復它正在做的事情所需的任何東西: 一個要回撥的 closure,或者一個 Promise。
從技術上講,這些其實都可以用一個執行緒實現。這裡不能談論任何特定實現的細節,但是像 JavaScript
這樣缺乏執行緒的語言也很好的遵循了這個模型。Node.js 更是將自己描述為「an event-driven JavaScript runtime, designed to build scalable network applications.」
事件驅動的伺服器通常比純粹基於 fork 或執行緒的伺服器更好地利用 CPU 和記憶體。你可以為每個核心生成一個應用程式執行緒來並行處理請求。執行緒不會相互爭奪 CPU,因為執行緒的數量等於核心的數量。當有請求可以進行時,執行緒永遠不會空閒,非常高效。效率如此之高,以至於現在大家都使用這種方式來編寫伺服器端程式碼。
從理論上講,這聽起來不錯,但是如果你編寫這樣的應用程式程式碼,就會發現這是一場噩夢。。。具體是什麼樣的噩夢,取決於你所使用的語言和框架。在 JavaScript 中,非同步函數通常返回一個 Promise,你給它附加回撥。在 Java gRPC 中,你要處理的是 StreamObserver。如果你不小心,你最終會得到很多深度巢狀的「箭頭程式碼」函數。如果你很小心,你就把函數和類分開了,混淆了你的控制流。不管怎樣,你都是在 callback hell 裡。
下面是一個 Java gRPC 官方教學 中的一個範例:
public void routeChat() throws Exception {
info("*** RoutChat");
final CountDownLatch finishLatch = new CountDownLatch(1);
StreamObserver<RouteNote> requestObserver =
asyncStub.routeChat(new StreamObserver<RouteNote>() {
@Override
public void onNext(RouteNote note) {
info("Got message \"{0}\" at {1}, {2}", note.getMessage(), note.getLocation()
.getLatitude(), note.getLocation().getLongitude());
}
@Override
public void onError(Throwable t) {
Status status = Status.fromThrowable(t);
logger.log(Level.WARNING, "RouteChat Failed: {0}", status);
finishLatch.countDown();
}
@Override
public void onCompleted() {
info("Finished RouteChat");
finishLatch.countDown();
}
});
try {
RouteNote[] requests =
{newNote("First message", 0, 0), newNote("Second message", 0, 1),
newNote("Third message", 1, 0), newNote("Fourth message", 1, 1)};
for (RouteNote request : requests) {
info("Sending message \"{0}\" at {1}, {2}", request.getMessage(), request.getLocation()
.getLatitude(), request.getLocation().getLongitude());
requestObserver.onNext(request);
}
} catch (RuntimeException e) {
// Cancel RPC
requestObserver.onError(e);
throw e;
}
// Mark the end of requests
requestObserver.onCompleted();
// Receiving happens asynchronously
finishLatch.await(1, TimeUnit.MINUTES);
}
上面程式碼官方的初學者教學,它不是一個完整的例子,傳送程式碼是同步的,而接收程式碼是非同步的。在 Java 中,你可能會為你的 HTTP 伺服器、gRPC、資料庫和其它任何東西處理不同的非同步型別,你需要在所有這些伺服器之間使用介面卡,這很快就會變得一團糟。
同時這裡如果使用鎖也很危險,你需要小心跨網路呼叫持有鎖。鎖和回撥也很容易犯錯誤。例如,如果一個同步方法呼叫一個返回 ListenableFuture 的函數,然後附加一個內聯回撥,那麼這個回撥也需要一個同步塊,即使它巢狀在父方法內部。
Goroutines
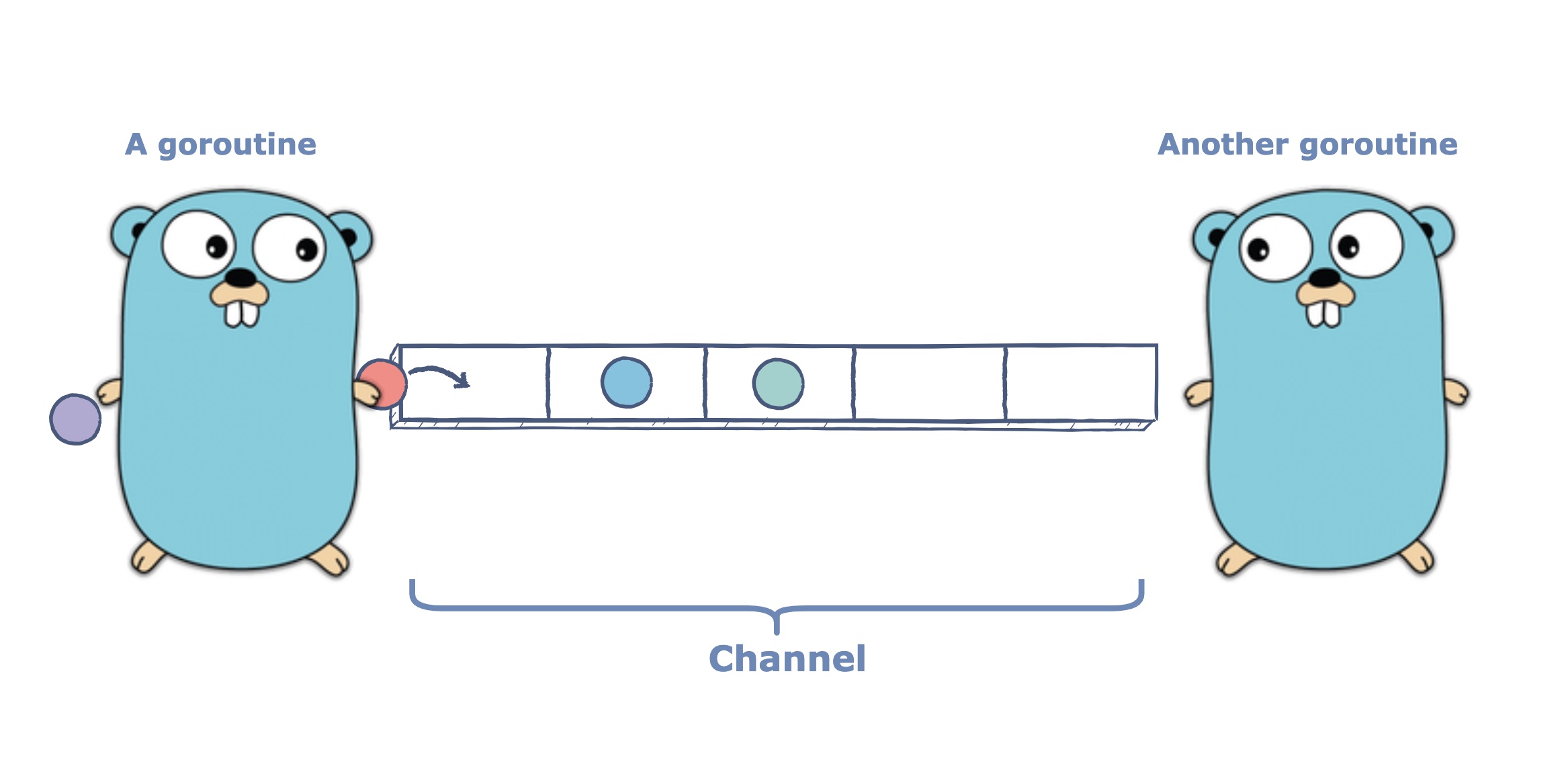
終於到了我們的主角——goroutines。它是 Go 語言版本的執行緒。像它語言(比如:Java)中的執行緒一樣,每個 gooutine 都有自己的堆疊。goroutine 可以與其它 goroutine 並行執行。與執行緒不同,goroutine 的建立成本非常低:它不繫結到 OS 執行緒上,它的堆疊開始非常小(初始只有 2 K),但可以根據需要增長。當你建立一個 goroutine 時,你實際上是在分配一個 closure,並在執行時將其新增到佇列中。
在內部實現中,Go 的執行時有一組執行程式的 OS 執行緒(通常每個核心一個執行緒)。當一個執行緒可用並且一個 goroutine 準備執行時,執行時將這個 goroutine 排程到執行緒上,執行應用程式邏輯。如果一個執行例程阻塞了像 mutex 或 channel 這樣的東西時,執行時將它新增到阻塞的執行 goroutine 集合中,然後將下一個就緒的執行例程排程到同一個 OS 執行緒上。
這也適用於網路:當一個執行緒程式在未準備好的通訊端上傳送或接收資料時,它將其 OS 執行緒交給排程器。這聽起來是不是很熟悉?Go 的排程器很像事件驅動伺服器中的主迴圈。除了僅僅依賴於 select 和專注於檔案描述符之外,排程器處理語言中可能阻塞的所有內容。
你不再需要避免阻塞呼叫,因為排程程式可以有效地利用 CPU。可以自由地生成許多 goroutine(可以每個請求一個!),因為建立它們的成本很低,而且不會爭奪 CPU,你不需要擔心執行緒池和執行器服務,因為執行時實際上有一個大的執行緒池。
簡而言之,你可以用乾淨的命令式風格編寫簡單的阻塞應用程式程式碼,就像在編寫一個基於執行緒的伺服器一樣,但你保留了事件驅動伺服器的所有效率優勢,兩全其美。這類程式碼可以很好地跨框架組合。你不需要 streamobserver 和 ListenableFutures 之間的這類介面卡。
下面讓我們看一下來自 Go gRPC 官方教學 的相同範例。可以發現這裡的控制流比 Java 範例中的更容易理
解,因為傳送和接收程式碼都是同步的。在這兩個 goroutines 中,我們都可以在一個 for 迴圈中呼叫 stream.Recv 和stream.Send。不再需要回撥、子類或執行器這些東西了。
stream, err := client.RouteChat(context.Background())
waitc := make(chan struct{})
go func() {
for {
in, err := stream.Recv()
if err == io.EOF {
// read done.
close(waitc)
return
}
if err != nil {
log.Fatalf("Failed to receive a note : %v", err)
}
log.Printf("Got message %s at point(%d, %d)", in.Message, in.Location.Latitude, in.Location.Longitude)
}
}()
for _, note := range notes {
if err := stream.Send(note); err != nil {
log.Fatalf("Failed to send a note: %v", err)
}
}
stream.CloseSend()
<-waitc
虛擬執行緒
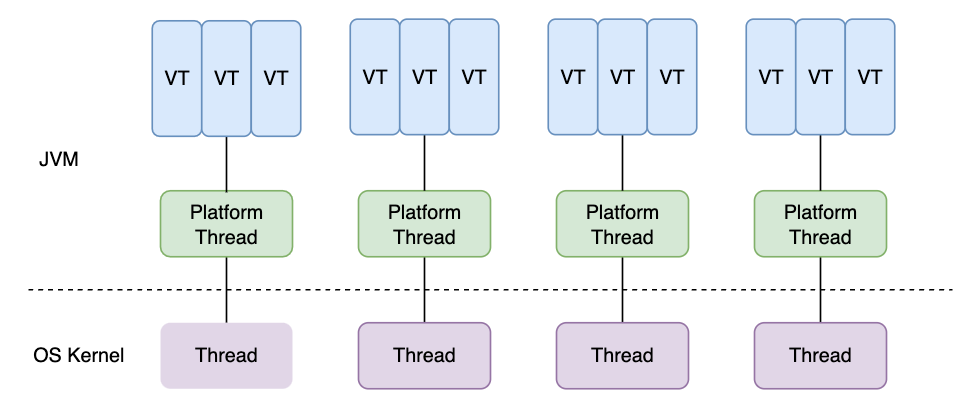
如何你使用 Java 這門語言,到目前為止,你要麼必須生成數量不合理的執行緒,要麼必須處理 Java 特有的回撥地獄。令人高興的是,JEP 444 中增加了 virtual threads,這看起來很像 Go 語言中的 goroutine。
建立虛擬執行緒的成本很低。JVM 將它們排程到平臺執行緒(platform threads,核心中的真實執行緒)上。平臺執行緒的數量是固定的,一般每個核心一個平臺執行緒。當一個虛擬執行緒執行阻塞操作時,它會釋放它的平臺執行緒,JVM
可能會將另一個虛擬執行緒排程到它上面。與 gooutine 不同,虛擬執行緒排程是共同作業的: 虛擬執行緒在執行阻塞操作之前不會服從於排程程式。這意味著緊迴圈可以無限期地保持執行緒。目前不清楚這是實現限制還是有更深層次的問題。Go 以前也有這個問題,直到 1.14 才實現了完全搶佔式排程(可見 GopherCon 2021)。
Java 的虛擬執行緒現在可以預覽,預計在 JDK 21 中成為 stable(官方訊息是預計 2023 年 9 月釋出)狀態。哈哈,很期待到時候能刪除大量的 ListenableFutures。每當引入一種新的語言或執行時特性時,都會有一個漫長的遷移過渡期,個人認為 Java 生態系統在這方面還是過於保守了。