【Python】萬字長文,Locust 效能測試指北(上)
Locust
Locust 是比較常見的效能測試工具,底層基於 gevent。官方介紹 它是一款易於使用、可編寫指令碼且可延伸的效能測試工具,可以讓我們使用常規 Python 程式碼定義使用者的行為,而不必陷入 UI 或限制性領域特定語言中.
Locust具有無限的可延伸性(只要提供使用者端python 程式碼,適用於所有協定的效能測試).
本文為開發效能自動化對比平臺時學習相關內容的記錄整理。
我們為什麼選擇locust
| 特點 | 說明 |
|---|---|
| 開源免費 | Locust是一個開源專案,無需支付費用,可以自由使用和客製化。 |
| 易於學習使用 | 使用Python編寫,學習路線平緩,擁有豐富的庫和社群支援。 |
| 可延伸性靈活性高 | 可以根據需要客製化測試,以便更準確地評估應用程式的效能。第三方外掛較多、 易於擴充套件。 |
| 實時統計 | 提供實時統計功能和Web介面,方便監控和分析測試結果。 |
| 易於整合 | 可以輕鬆地與持續整合和持續部署工具整合,自動執行效能測試。 |
| 適用大規模的效能測試 | 支援分散式,可以輕鬆地在多臺機器上執行測試,以模擬大量使用者。這使得它非常適合進行大規模的效能測試。 |
Locust的核心部件
Master節點
負責協調和管理整個測試過程,包括啟動和停止測試、分發任務、收集和彙總測試結果等。
Worker節點
實際執行測試任務的節點,根據Master節點分配的任務進行模擬使用者行為。
Web UI
提供視覺化的測試介面,方便使用者檢視測試結果、監控測試進度等。
測試指令碼(Load Test Script)
測試指令碼,定義模擬使用者行為的邏輯和引數,由Worker節點執行。
Locust內部執行呼叫鏈路
時序圖如下:
點選檢視時序圖說明
- 在測試啟動時,Runner 類的 start() 方法會被呼叫,該方法會依次呼叫 EventHook 類的 fire() 方法,觸發測試開始事件。
- Runner 類會根據設定建立 Environment 類的範例,並將其作為引數傳遞給 User 類和 TaskSet 類別建構函式,同時將 User 類和 TaskSet 類新增到 Environment 類的 user_classes 屬性中。
- 在測試執行期間,Runner 類會啟動多個使用者程序,每個使用者程序都會建立一個 User 類的範例,並呼叫 User 類的 run() 方法,該方法會呼叫 TaskSet 類的 run() 方法,從而執行使用者的任務。
- 在任務執行期間,User 類和 TaskSet 類會使用 Environment 類的 client 屬性來傳送請求,並使用 Environment 類的 stats 屬性來記錄統計資訊。
- 在任務執行完成後,TaskSet 類的 run() 方法會返回,User 類的 run() 方法會進入等待狀態,等待其他使用者完成任務。
- 在測試結束時,Runner 類的 stop() 方法會被呼叫,該方法會依次呼叫 EventHook 類的 fire() 方法,觸發測試結束事件。
注:fire() 方法是 Locust 中的 EventHook 類中的一個方法,用於觸發事件。在 Locust 的測試生命週期中,有多個事件可以被觸發,例如測試開始、測試結束、使用者啟動、使用者完成任務等。當這些事件發生時,EventHook 類會呼叫 fire() 方法,將事件傳遞給所有註冊了該事件的回撥函數。
locust 實踐
locust安裝
| 步驟 | 說明 |
|---|---|
| 點選跳轉安裝 Python3.7+ | 新版本標註需要Python3.7 or later |
pip install locust |
安裝 locust |
執行locust |
檢查是否安裝成功 |
$ locust -V
locust 2.15.1 from /Users/bingohe/Hebinz/venvnew/lib/python3.9/site-packages/locust (python 3.9.17)
入門範例
使用 locust 編寫用例時,約定大於設定:
test_xxx (一般測試框架約定)
dockerfile (docker約定)
locustfile.py (locust約定)
# locustfile.py
from locust import HttpUser, task
class HelloWorldUser(HttpUser): # 父類別是個User,表示要生成進行負載測試的系統的 HTTP「使用者」。每個user相當於一個協程連結 ,進行相關係統互動操作
@task # 裝飾器來標記為一個測試任務, 表示使用者要進行的操作:存取首頁 → 登入 → 增、刪改查
def hello_world(self):
wait_time = between(1, 5)
# self.client傳送 HTTP 請求,模擬使用者的操作
self.client.get("/helloworld")
啟動測試
GUI 模式啟動 locust
在有locustfile.py檔案的目錄直接執行locust命令,然後存取:http://0.0.0.0:8089/ 即可看到下面的介面:
$ locust
[2023-07-06 16:15:16,868] MacBook-Pro.local/INFO/locust.main: Starting web interface at http://0.0.0.0:8089 (accepting connections from all network interfaces)
[2023-07-06 16:15:16,876] MacBook-Pro.local/INFO/locust.main: Starting Locust 2.15.1
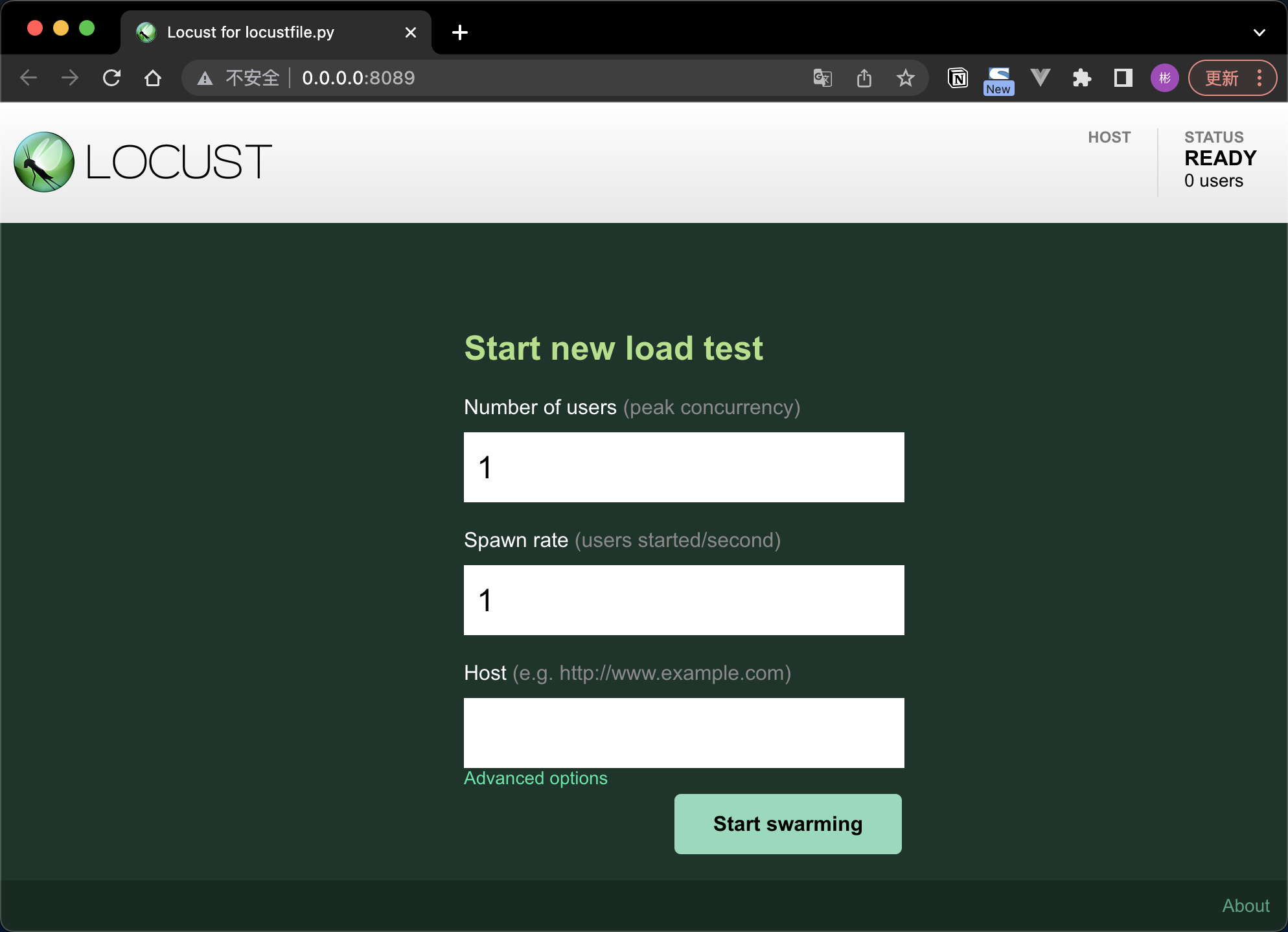
指標詳解:
- Number of users 模擬使用者數,預設 1
- Spawn rate : 生產數 (每秒)、 =>jmeter : Ramp-Up Period (in seconds), 預設 1
- Host (e.g. http://www.example.com) => 測試目標 svr 的 絕對地址
填寫 host點選 start 之後就會對被測服務如http://{host}/helloworld 發起請求。請求統計資料如下:
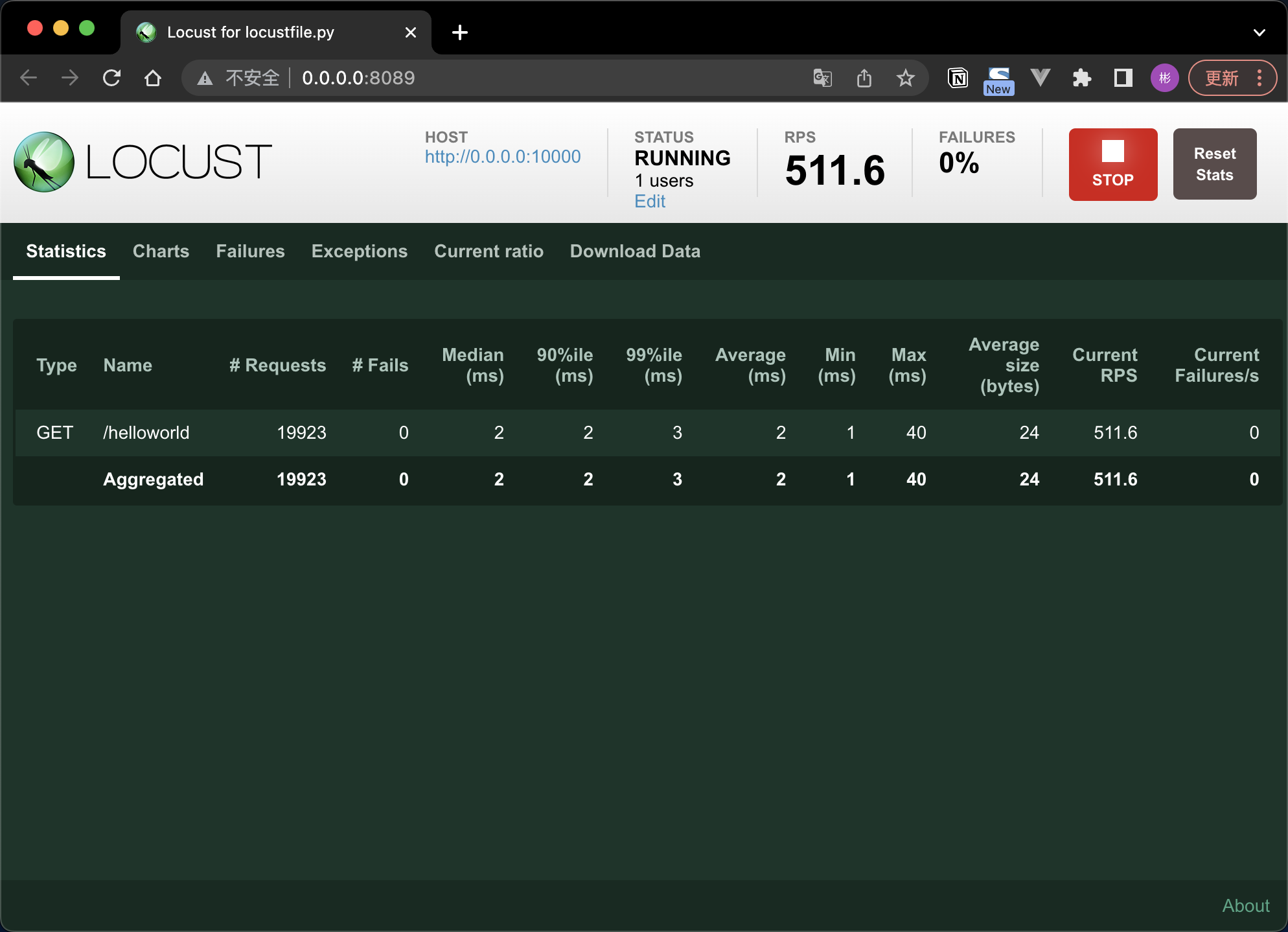
WebUI Tab說明:
| Tab名稱 | 功能描述 |
|---|---|
| New test | 點選該按鈕可對模擬的總虛擬使用者數和每秒啟動的虛擬使用者數進行編輯 |
| Statistics | 類似於 JMeter 中 Listen 的聚合報告 |
| Charts | 測試結果變化趨勢的曲線展示圖,包括每秒完成的請求數(RPS)、響應時間、不同時間的虛擬使用者數 |
| Failures | 失敗請求的展示介面 |
| Exceptions | 異常請求的展示介面 |
| Download Data | 測試資料下載模組,提供三種型別的 CSV 格式的下載,分別是:Statistics、responsetime、exceptions |
需要說明的是webui 模式有很多限制,主要用於偵錯,下面將要介紹的命令列模式更為常用。
命令列模式啟動 locust
locust -f locustfile.py --headless -u 500 -r 10 --host http://www.example.com -t 1000s
框架是通過命令locust執行的,常用引數有:
| 引數 | 含義 |
|---|---|
-f 或 --locustfile |
指定測試指令碼檔案的路徑 |
--headless |
以非 GUI 模式執行測試 |
-u 或 --users |
指定並行使用者數 |
-r 或 --spawn-rate |
指定使用者生成速率(即每秒生成的使用者數) |
-t 或 --run-time |
指定測試執行的最大時間 (單位:秒),與--no-web一起使用 |
--csv |
將測試結果輸出到 CSV 檔案中 |
--html |
將測試結果輸出為 HTML 報告 |
--host或者 -H |
指定被測服務的地址 |
-L |
紀錄檔級別,預設為INFO |
檢查點(斷言)
Locust預設情況下會根據HTTP狀態碼來判斷請求是否成功。對於HTTP狀態碼範圍在200-399之間的響應,Locust會將其視為成功。對於HTTP狀態碼在400-599之間的響應,Locust會將其視為失敗。
如果需要根據響應內容或其他條件來判斷請求是否成功,需要手動設定檢查點:
- 使用self.client提供的catch_response=True`引數, 新增locust提供的ResponseContextManager類的上下文方法手動設定檢查點。
- ResponseContextManager裡面的有兩個方法來宣告成功和失敗,分別是
success和failure。其中failure方法需要我們傳入一個引數,內容就是失敗的原因。
from locust import HttpUser, task, between
class MyUser(HttpUser):
# 思考時間:模擬真實使用者在瀏覽應用程式時的行為
wait_time = between(1, 5)
@task
def my_task(self):
# 基於Locust提供的ResponseContextManager上下文管理器,使用catch_response=True 引數來捕獲響應,手動標記成功或失敗,
with self.client.get("/some_page", catch_response=True) as response:
# 檢查狀態碼是否為200且響應中包含 "some_text"
if response.status_code == 200 and "some_text" in response.text:
# 如果滿足條件,標記響應為成功
response.success()
else:
# 如果條件不滿足,根據具體情況生成錯誤資訊
error_message = "Unexpected status code: " + str(response.status_code) if response.status_code != 200 else "Expected text not found in the response"
# 標記響應為失敗,並報告錯誤資訊
response.failure(error_message)
權重比例
如果需要請求有不同的比例,在Locust中,可以通過在@task裝飾器中設定weight引數為任務分配權重來實現。權重越高,任務被執行的頻率就越高。
from locust import HttpUser, task, between
class MyUser(HttpUser):
wait_time = between(1, 5)
# 設定權重為3,這個任務將被執行的頻率更高
@task(3)
def high_frequency_task(self):
self.client.get("/high_frequency_page")
# 設定權重為1,這個任務將被執行的頻率較低
@task(1)
def low_frequency_task(self):
self.client.get("/low_frequency_page")
在這個範例中,我們為high_frequency_task任務設定了權重為3,而為low_frequency_task任務設定了權重為1。這意味著在模擬使用者執行任務時,high_frequency_task任務被執行的頻率將是low_frequency_task任務的3倍。通過設定權重,我們可以根據實際需求調整不同任務在效能測試中的執行頻率。
點選檢視在Locust內部權重的實現原理
在Locust內部,權重是通過一個名為TaskSet的類來實現的。TaskSet類包含一個名為tasks的列表,該列表包含所有定義的任務。每個任務在列表中出現的次數等於其權重。當Locust選擇要執行的任務時,它會從tasks列表中隨機選擇一個任務,這樣權重較高的任務就有更高的概率被選中。
以下是一個簡化的TaskSet類範例,以幫助理解權重是如何在Locust內部實現的:
import random
class TaskSet:
def __init__(self):
self.tasks = []
def add_task(self, task, weight=1):
for _ in range(weight):
self.tasks.append(task)
def get_random_task(self):
return random.choice(self.tasks)
task_set = TaskSet()
task_set.add_task("high_frequency_task", weight=3)
task_set.add_task("low_frequency_task", weight=1)
# 當我們呼叫 get_random_task() 方法時,權重較高的任務有更高的概率被選中
random_task = task_set.get_random_task()
在這個範例中,我們建立了一個簡化的TaskSet類,它包含一個tasks列表和兩個方法:add_task()用於新增任務及其權重,get_random_task()用於隨機選擇一個任務。權重較高的任務在tasks列表中出現的次數更多,因此它們更有可能被get_random_task()方法選中。
在實際的Locust實現中,這個概念稍微複雜一些,但基本原理是相同的:通過權重調整任務在內部列表中出現的次數,從而影響任務被選中的概率。
引數化
在現實世界中,使用者的行為通常是多樣化的。他們可能使用不同的裝置、作業系統、網路條件等。為了更好地模擬這些場景,我們需要在測試中使用不同的引數。
在效能測試中,引數化是一種非常重要的技術手段。它允許我們使用不同的資料集執行相同的測試場景,從而更好地模擬真實世界的使用者行為。常用的引數化方法有兩種。
使用 Locust 的內建引數化功能
from locust import HttpUser, task, between
from locust.randoms import random_string, random_number
class MyUser(HttpUser):
wait_time = between(1, 5)
@task
def random_data(self):
random_str = random_string(10)
random_num = random_number(0, 100)
self.client.post("/random", json={"text": random_str, "number": random_num})
從外部檔案讀取引數
以已經設定成白名單的鑑權 session 為例:
import csv
from locust import HttpUser, task
class CSVReader:
def __init__(self, file, **kwargs):
try:
file = open(file)
except TypeError:
pass
self.file = file
self.reader = csv.reader(file, **kwargs) # iterator
def __next__(self):
try:
return next(self.reader)
except StopIteration:
# 如果沒有下一行,則從頭開始讀
self.file.seek(0, 0)
return next(self.reader)
session = CSVReader("session.csv")
class MyUser(HttpUser):
@task
def index(self):
customer = next(ssn_reader)
self.client.get(f"/pay?session={customer[0]}")
Tag
在Locust中,標籤(Tag)是用於對任務進行分類和篩選的一種方法。通過給任務新增標籤,可以在執行Locust時只執行具有特定標籤的任務。這在執行特定場景的效能測試或組織大量任務時非常有用。
使用場景
有時候我們會在同一個檔案中寫多個測試場景,但是執行的時候只想執行其中一部分,即當一個測試檔案中的task不止一個時,我們可以通過@tag給task打標籤進行分類,在執行測試時,通過--tags name執行指定帶標籤的task。
以下是一個使用標籤的範例:
from locust import HttpUser, task, between, tag
class MyUser(HttpUser):
wait_time = between(1, 5)
# 給任務新增一個名為 "login" 的標籤
@tag("login")
@task
def login_task(self):
self.client.post("/login", json={"username": "user", "password": "pass"})
# 給任務新增一個名為 "profile" 的標籤
@tag("profile")
@task
def profile_task(self):
self.client.get("/profile")
# 給任務新增兩個標籤:"shopping" 和 "checkout"
@tag("shopping", "checkout")
@task
def checkout_task(self):
self.client.post("/checkout")
在這個範例中,我們為三個任務分別新增了不同的標籤。login_task任務具有"login"標籤,profile_task任務具有"profile"標籤,而checkout_task任務具有"shopping"和"checkout"兩個標籤。
執行Locust時,可以通過使用--tags和--exclude-tags選項來指定要執行或排除的標籤。例如,要僅執行具有"login"標籤的任務,可以執行:
locust --tags login
要排除具有"shopping"標籤的任務,可以執行:
locust --exclude-tags shopping
這樣,我們就可以根據需要執行特定場景的效能測試,而不需要修改程式碼。
點選檢視如何在Locust屬性中指定 tag
在Locust中,可以使用tags屬性來在HttpUser子類中指定標籤。以下是一個範例:
from locust import HttpUser, task, between, tag
@tag("login")
class LoginTasks(HttpUser):
wait_time = between(1, 5)
@task
def login_task(self):
self.client.post("/login", json={"username": "user", "password": "pass"})
@tag("profile")
class ProfileTasks(HttpUser):
wait_time = between(1, 5)
@task
def profile_task(self):
self.client.get("/profile")
@tag("shopping", "checkout")
class CheckoutTasks(HttpUser):
wait_time = between(1, 5)
@task
def checkout_task(self):
self.client.post("/checkout")
在這個範例中,我們建立了三個不同的HttpUser子類,分別為LoginTasks、ProfileTasks和CheckoutTasks。我們在類級別使用@tag()裝飾器為每個子類新增了標籤。LoginTasks具有"login"標籤,ProfileTasks具有"profile"標籤,而CheckoutTasks具有"shopping"和"checkout"兩個標籤。
與之前的範例類似,可以使用--tags和--exclude-tags選項來指定要執行或排除的標籤。在這種情況下,標籤將應用於整個HttpUser子類,而不僅僅是單個任務。
集合點
什麼是集合點?
集合點用以同步虛擬使用者,以便恰好在同一時刻執行任務。在[測試計劃]中,可能會要求系統能夠承受1000 人同時提交資料,可以通過在提交資料操作前面加入集合點,這樣當虛擬使用者執行到提交資料的集合點時,就檢查同時有多少使用者執行到集合點,如果不到1000 人,已經到集合點的使用者在此等待,當在集合點等待的使用者達到1000 人時,1000 人同時去提交資料,從而達到測試計劃中的需求。
注意:Locust框架本身沒有直接封裝集合點的概念 ,需要間接通過gevent並行機制,使用gevent的鎖來實現。
在 Locust 中 實現集合點前,我們先了解兩個概念:
gevent中的Semaphore號誌locust中的事件勾點all_locusts_spawned
Semaphore
號誌(Semaphore)是一種用於控制對共用資源存取的同步原語。它是電腦科學和並行程式設計中的一個重要概念,最早由著名電腦科學家Edsger Dijkstra於1960s提出。號誌用於解決多執行緒或多程序環境中的臨界區問題,以防止對共用資源的競爭存取。
點選檢視`Semaphore`實現原理
號誌的工作原理是通過維護一個計數器來表示可用資源的數量。當一個執行緒或程序想要存取共用資源時,它需要請求號誌。號誌會檢查其計數器值:
如果計數器值大於0,表示有可用資源,號誌會減少計數器值並允許執行緒或程序存取共用資源。
如果計數器值等於0,表示沒有可用資源,號誌會阻塞執行緒或程序,直到其他執行緒或程序釋放資源。
當執行緒或程序完成對共用資源的存取後,它需要釋放號誌。此時,號誌會增加計數器值,表示資源已釋放並可供其他執行緒或程序使用。
號誌通常有兩種型別:
二進位制號誌(Binary Semaphore):計數器值只能為0或1。二進位制號誌通常用於實現互斥鎖(Mutex),以確保一次只有一個執行緒或程序存取共用資源。
計數號誌(Counting Semaphore):計數器值可以為任意正整數。計數號誌用於限制對共用資源的並行存取數量,以實現有限的資源池。
許多程式語言和庫都提供了號誌的實現,例如Python中的threading.Semaphore和gevent.lock.Semaphore。使用號誌可以幫助解決並行程式設計中的同步和資源競爭問題。
gevent.lock.Semaphore是gevent庫中提供的號誌實現。gevent是一個基於協程的Python並行庫,使用輕量級的綠色執行緒(greenlet)提供高效能的並行。gevent.lock.Semaphore允許您在gevent協程中同步對共用資源的存取。
以下是gevent.lock.Semaphore的主要特點和使用方法:
- 初始化:要建立一個號誌,您可以範例化
gevent.lock.Semaphore類。在初始化時,可以選擇設定號誌的初始值(預設值為1)。
from gevent.lock import Semaphore
# 建立一個具有預設初始值(1)的號誌
sem = Semaphore()
# 建立一個具有自定義初始值(5)的號誌
sem_with_initial_value = Semaphore(value=5)
- 請求資源(acquire):當協程需要存取共用資源時,它應該呼叫
Semaphore.acquire()方法。如果號誌的計數器值大於0,acquire()方法將減少計數器值並立即返回。如果計數器值為0,acquire()方法將阻塞協程,直到其他協程釋放資源。
sem.acquire()
# 在此處存取共用資源
- 釋放資源(release):當協程完成對共用資源的存取後,它應該呼叫
Semaphore.release()方法。這將增加號誌的計數器值,表示資源已釋放並可供其他協程使用。
# 完成對共用資源的存取
sem.release()
- 使用上下文管理器:
gevent.lock.Semaphore還可以作為上下文管理器使用,以確保在存取共用資源的程式碼塊結束時自動釋放號誌。這可以簡化程式碼並防止忘記釋放號誌。
with sem:
# 在此處存取共用資源
# 號誌會在這裡自動釋放
總之,gevent.lock.Semaphore是gevent庫中提供的號誌實現,用於在協程之間同步對共用資源的存取。通過使用Semaphore.acquire()和Semaphore.release()方法,您可以確保在gevent協程中正確處理並行存取。
all_locusts_spawned 事件
在 Locust 中,事件是一個非常重要的概念。事件允許我們在 Locust 的生命週期中的特定時刻執行自定義的操作。通過監聽和處理這些事件,我們可以擴充套件 Locust 的功能,以滿足測試需求。
spawning_complete 是 Locust 中的一個事件,表示所有的 Locust 使用者(user)已經生成完成。當 Locust 開始執行測試並生成使用者時,它會逐漸建立使用者範例。一旦所有的使用者都被建立,spawning_complete 事件就會被觸發。你可以在這個事件中執行一些特定的操作,例如輸出紀錄檔訊息、收集統計資訊或執行其他自定義操作。
要監聽 spawning_complete 事件,你可以使用 locust.events.spawning_complete 事件勾點。例如:
from locust import events
@events.spawning_complete.add_listener
def on_spawning_complete():
print("All users have been spawned!")
在這個範例中,當所有的使用者生成完成時,我們會輸出一條訊息 "All users have been spawned!"。你可以根據需要替換為其他操作。
點選檢視 `Locust` 生命週期中其他的事件
test_start:測試開始時觸發。spawning_start:生成使用者時觸發。user_add:每個使用者被新增時觸發。spawning_complete:所有使用者生成完成時觸發。request:每個請求發生時觸發。test_stop:測試停止時觸發。
瞭解完上面兩個概念,接下來我們只需要兩步走:
- 在指令碼啟動時,使用all_locust_spawned.acquire() 阻塞程序
- 編寫一個函數,在 使用者全部建立完成時觸發 all_locust_spawned.release()
範例程式碼:
from locust import HttpUser, task, between
from gevent.lock import Semaphore
from locust import events
all_locust_spawned = Semaphore()
all_locust_spawned.acquire() # 阻塞
class MyUser(HttpUser):
wait_time = between(1, 1)
def on_start(self):
global all_locust_spawned
all_locust_spawned.wait(3) # 同步鎖等待時間
@task
def task_rendezvous(self):
self.client.get("/rendezvous")
# 新增集合點事件處理器
@events.spawning_complete.add_listener # 所有的Locust範例產生完成時觸發
def on_spawning_complete(**_kwargs):
global all_locust_spawned
all_locust_spawned.release()
分散式
當我們需要大量的並行使用者,而單個計算機可能無法生成足夠的負載來模擬這種情況時,分散式壓力測試可以解決這個問題,我們可以通過將壓力測試分佈到多個計算機上來生成更大的負載,並更準確地評估系統的效能。
Locust 的限制
Locust 使用 Python 的 asyncio 庫來實現非同步 I/O,這意味著它可以充分利用多核 CPU 的效能。然而,由於 Python 的全域性直譯器鎖(GIL)限制,單個 Python 程序無法充分利用多核 CPU。
為了解決這個問題,Locust 支援在單個計算機上執行多個從節點(worker node),這樣可以充分利用多核 CPU 的效能。
當在單臺計算機上執行多個從節點時,每個從節點將執行在一個單獨的程序中,從而避免了 GIL 的限制。這樣,我們可以充分利用多核 CPU 的效能,生成更大的負載。
單機主從模式
注意: slave 的節點數要小於等於本機的處理器數
在單機主從模式下,主節點和從節點都執行在同一臺計算機上。這種模式適用於在本地開發環境中進行壓力測試,或者在具有多核 CPU 的單臺伺服器上進行壓力測試。以下是在單機主從模式下實現分散式壓力測試的步驟:
-
安裝 Locust:在計算機上安裝 Locust,使用
pip install locust命令進行安裝。 -
編寫 Locust 測試指令碼:編寫一個 Locust 測試指令碼,這個指令碼將在主節點和從節點上執行。將此指令碼儲存為
locustfile.py。 -
啟動主節點:在計算機上執行
locust --master命令啟動主節點,監聽預設埠(8089)。 -
啟動從節點:在計算機上執行
locust --worker --master-host 127.0.0.1命令啟動一個從節點。根據需要,可以啟動多個從節點。 -
執行分散式壓力測試:存取 Locust 的 Web 介面(http://127.0.0.1:8089),開始測試。
單機模式下,如何讓每個從節點都執行在不同的 CPU 上
點選檢視如何單機模式下,每個從節點都執行在不同的 CPU 上
在單機主從模式下,確保啟動的多個從節點執行在不同的 CPU 核心上,可以通過為每個從節點設定 taskset 命令來實現。taskset 是一個 Linux 命令,可以用來設定程序的 CPU 親和性,即將程序繫結到特定的 CPU 核心上執行。
以下是在單機主從模式下,確保啟動的多個從節點執行在不同 CPU 核心上的步驟:
-
啟動主節點:在計算機上執行
locust --master命令啟動主節點,監聽預設埠(8089)。 -
啟動從節點:在計算機上執行以下命令啟動從節點,並將其繫結到特定的 CPU 核心上:
taskset -c CORE_NUMBER locust --worker --master-host 127.0.0.1
其中,CORE_NUMBER 是要將從節點繫結到的 CPU 核心編號(從 0 開始)。例如,要將從節點繫結到第一個 CPU 核心上,可以執行以下命令:
taskset -c 0 locust --worker --master-host 127.0.0.1
- 根據需要,可以啟動多個從節點,並將它們分別繫結到不同的 CPU 核心上。例如,要將第二個從節點繫結到第二個 CPU 核心上,可以執行以下命令:
taskset -c 1 locust --worker --master-host 127.0.0.1
請注意,taskset 命令僅適用於 Linux 系統。在 Windows 或 macOS 上,可以嘗試使用類似的工具,例如 Windows 上的 start /affinity 命令或 macOS 上的 cpulimit 工具。
通過使用 taskset 命令或類似的工具,我們可以確保在單機主從模式下,啟動的多個從節點執行在不同的 CPU 核心上。這有助於充分利用多核 CPU 的效能,生成更大的負載。
多機主從模式
操作與單機模式基本一樣,存取 Locust 的 Web 介面時存取的時主節點的地址(http://MASTER_IP_ADDRESS:8089)。
因為主節點和從節點之間通過網路通訊。因此,在選擇主節點和從節點的計算機時,需要確保它們之間的網路連線暢通。此外,為了獲得準確的測試結果,務必確保主節點和從節點之間的網路延遲較低。
分散式模式下的命令引數
| 命令引數 | 說明 |
|---|---|
--master |
將當前 Locust 範例作為主節點(master node)執行。 |
--worker |
將當前 Locust 範例作為從節點(worker node)執行。 |
--master-host |
指定主節點的 IP 地址或主機名。預設值為 127.0.0.1。 |
--master-port |
指定主節點的埠號。預設值為 5557。 |
--master-bind-host |
指定主節點繫結的 IP 地址或主機名。預設值為 *(所有介面)。 |
--master-bind-port |
指定主節點繫結的埠號。預設值為 5557。 |
--expect-workers |
指定主節點期望連線的從節點數量。預設值為 1。 |
--expect-workers 引數用於指定主節點期望連線的從節點數量。如果實際連線的從節點數量沒有達到這個值,主節點會繼續等待,直到足夠的從節點連線上來。
在實際執行分散式壓力測試時,主節點會在 Web 介面上顯示連線的從節點數量。如果實際連線的從節點數量沒有達到 --expect-workers 指定的值,你可以在 Web 介面上看到一個警告訊息,提示你主節點正在等待更多從節點的連線。
docker 執行locust
使用 容器的方式執行 locust 的優勢和缺點都非常明顯:
| 優勢 | 描述 |
|---|---|
| 環境一致性 | Docker 可以確保在不同計算機上執行的 Locust 環境是一致的。 |
| 便於部署 | 使用 Docker 可以簡化 Locust 的部署過程。 |
| 易於擴充套件 | Docker 可以與容器編排工具結合使用,實現 Locust 從節點的自動擴充套件。 |
| 隔離性 | Docker 容器提供了一定程度的隔離性,將 Locust 執行環境與宿主機系統隔離。 |
| 缺點 | 描述 |
|---|---|
| 效能開銷 | Docker 容器可能存在一定程度的效能損失,與在宿主機上直接執行 Locust 相比。 |
| 學習曲線 | 對於不熟悉 Docker 的使用者,可能需要一定時間學習 Docker 的基本概念和使用方法。 |
| 系統資源佔用 | 執行 Docker 容器需要消耗一定的系統資源(如 CPU、記憶體、磁碟空間等)。 |
但是以下這些場景使用 Docker 來執行 Locust 是一個更好的選擇:
-
分散式壓力測試:在分散式壓力測試中,需要在多臺計算機上執行 Locust 主節點和從節點。使用 Docker 可以確保所有節點的執行環境一致,簡化部署過程。
-
雲環境部署:如果你需要在雲環境(如 AWS、Azure、GCP 等)中進行壓力測試,使用 Docker 可以簡化部署過程,並充分利用雲平臺提供的容器服務(如 Amazon ECS、Google Kubernetes Engine 等)。
-
CI/CD 整合:如果你需要將壓力測試整合到持續整合/持續部署(CI/CD)流程中,使用 Docker 可以簡化整合過程。許多 CI/CD 工具(如 Jenkins、GitLab CI、Travis CI 等)都支援 Docker 整合。
-
避免環境衝突:如果你的開發或測試環境中已經安裝了其他 Python 應用程式,可能會出現依賴項衝突。使用 Docker 可以將 Locust 執行環境與宿主機系統隔離,避免潛在的環境衝突。
-
團隊共同作業:在團隊共同作業過程中,使用 Docker 可以確保每個團隊成員都使用相同的 Locust 執行環境,從而避免因環境差異導致的問題。
具體使用步驟
-
首先,確保你已經安裝了 Docker。如果尚未安裝,請參考 Docker 官方檔案 以獲取適用於你的作業系統的安裝說明。
-
編寫一個 Locust 測試指令碼。例如,建立一個名為
locustfile.py的檔案,內容如下:
from locust import HttpUser, task, between
class MyUser(HttpUser):
wait_time = between(1, 5)
@task
def my_task(self):
self.client.get("/")
- 使用以下命令從 Docker Hub 拉取官方的 Locust 映象:
docker pull locustio/locust
- 使用以下命令在 Docker 中執行 Locust。
docker run --rm -p 8089:8089 -v $PWD:/mnt/locust locustio/locust -f /mnt/locust/locustfile.py --host TARGET_HOST
在這個命令中,我們將當前目錄(包含 locustfile.py 檔案)掛載到 Docker 容器的 /mnt/locust 目錄。然後,我們使用 -f 引數指定要執行的 Locust 測試指令碼,並使用 --host 引數指定目標主機地址。
- 存取 Locust 的 Web 介面。在瀏覽器中開啟
http://localhost:8089,你將看到 Locust 的 Web 介面。在這裡,你可以開始壓力測試並檢視結果。
通過以上步驟,你可以在 Docker 中執行 Locust,無需在本地環境中安裝 Locust。
總之,在需要確保環境一致性、簡化部署過程、整合到 CI/CD 流程、避免環境衝突或團隊共同作業的場景下,使用 Docker 來執行 Locust 是一個很好的選擇。通過使用 Docker,你可以輕鬆地在不同的計算機或雲環境中執行壓力測試,從而實現更大規模的分散式壓力測試。
高效能 FastHttpUser
Locust 的預設 HTTP 使用者端使用http.client。如果計劃以非常高的吞吐量執行測試並且執行 Locust 的硬體有限,那麼它有時效率不夠。
FastHttpUser 是 Locust 提供的一個特殊的使用者類,用於執行 HTTP 請求。與預設的 HttpUser 不同,FastHttpUser 使用 C 語言庫 gatling 編寫的 httpclient 進行 HTTP 請求, 有時將給定硬體上每秒的最大請求數增加了 5 到 6 倍。在相同的並行條件下使用FastHttpUser能有效減少對負載機的資源消耗從而達到更大的http請求。
優勢
-
效能:
FastHttpUser的主要優勢是效能。由於它使用 C 語言庫進行 HTTP 請求,它的效能通常比預設的HttpUser更高。這意味著在相同的硬體資源下,你可以使用FastHttpUser生成更大的負載。 -
資源佔用:與預設的
HttpUser相比,FastHttpUser通常具有較低的資源佔用(如 CPU、記憶體等)。這意味著在進行壓力測試時,你可以在同一臺計算機上執行更多的並行使用者。 -
更高的並行能力:由於
FastHttpUser的效能和資源佔用優勢,它可以更好地支援大量並行使用者的壓力測試。這對於需要模擬大量並行使用者的場景(如高流量 Web 應用程式、API 等)非常有用。
然而需要注意的是FastHttpUser 也有一些侷限性。例如,它可能不支援某些特定的 HTTP 功能(如自定義 SSL 證書、代理設定等)。在選擇使用 FastHttpUser 時,需要權衡效能優勢和功能支援。如果測試場景不需要大量並行使用者,或者需要特定的 HTTP 功能,使用預設的 HttpUser 可能更合適。
以下是一個使用 FastHttpUser 的 Locust 測試指令碼範例:
from locust import FastHttpUser, task, between
class MyFastHttpUser(FastHttpUser):
wait_time = between(1, 5)
@task
def my_task(self):
self.client.get("/")
測試gRPC等其他協定
locust 並非 http 介面測試工具 , 只是內建了 「HttpUser」 範例 ,理論上來說,只要提供使用者端,它可以測試任何協定。
如果有測試 gRPC、XML-RPC、requests-based libraries/SDKs等需求,可以參考:
https://docs.locust.io/en/stable/testing-other-systems.html
其他
主流效能測試工具對比
下面是 Locust、JMeter、Wrk 和 LoadRunner 四款效能測試工具的優缺點和支援的功能的對比表格:
| 工具名稱 | 優點 | 缺點 | 支援的功能 |
|---|---|---|---|
| Locust | - 簡單易用,支援 Python 語言 - 可以在程式碼中編寫測試場景,靈活性高 - 可以使用分散式部署,支援大規模測試 - 支援 Web 和 WebSocket 測試 |
- 功能相對較少,不支援 GUI - 對於非 Python 開發人員不太友好 - 在大規模測試時需要手動管理分散式節點 |
- HTTP(S)、WebSocket 測試 - 支援斷言、引數化、資料驅動等功能 - 支援分散式測試 |
| JMeter | - 功能豐富,支援多種協定 - 支援 GUI,易於使用 - 支援分散式部署,支援大規模測試 - 支援外掛擴充套件,可以擴充套件功能 |
- 效能較差,不適合高並行測試 - 記憶體佔用較高,需要較大的記憶體 - 學習曲線較陡峭 |
- HTTP(S)、FTP、JDBC、JMS、LDAP、SMTP、TCP、UDP 等多種協定的測試 - 支援斷言、引數化、資料驅動等功能 - 支援分散式測試 |
| Wrk | - 效能優異,支援高並行測試 - 支援 Lua 指令碼編寫,靈活性高 - 支援多種輸出格式,方便結果分析 |
- 功能相對較少,不支援 GUI - 只支援 HTTP 協定測試 - 學習曲線較陡峭 |
- HTTP(S) 測試 - 支援斷言、引數化、資料驅動等功能 |
| LoadRunner | - 功能豐富,支援多種協定 - 支援 GUI,易於使用 - 支援分散式部署,支援大規模測試 - 支援外掛擴充套件,可以擴充套件功能 |
- 價格較高,不適合小型團隊使用 - 學習曲線較陡峭 - 對於非 Windows 平臺的支援不夠友好 |
- HTTP(S)、FTP、JDBC、JMS、LDAP、SMTP、TCP、UDP 等多種協定的測試 - 支援斷言、引數化、資料驅動等功能 - 支援分散式測試 |
需要注意的是,這些工具的優缺點和支援的功能只是相對而言的,具體使用時需要根據實際需求和場景選擇。
合抱之木,生於毫末;九層之臺,起於累土;千里之行,始於足下。