OpenCV計算機視覺學習(14)——淺談常見影象字尾(png, jpg, bmp)的區別(opencv讀取語意分割mask的坑)
如果需要處理的原圖及程式碼,請移步小編的GitHub地址
傳送門:請點選我
如果點選有誤:https://github.com/LeBron-Jian/ComputerVisionPractice
本來不想碎碎念,但是我已經在影象字尾上栽倒兩次了。而且因為無意犯錯,根本找不到問題。不論是在深度學習的語意分割中,還是在影象處理的軟體(Halcon, Cognex)中都載過跟頭,於是痛定思痛,決定將自己的經驗寫進這篇部落格中,如果看到這篇的看官,希望不要再犯了。
問題1:亂修改影象字尾名稱,部分軟體會報錯(halcon error #5580:PNG:file is not a PNG file)
首先是下面的報錯,因為openCV使用多了,我們經常會通過cv2.imread()載入出三通道的影象,所以預設影象都是BGR的,無論影象是png, bmp 還是 jpg。反正都可以讀出三通道的,即使有時候無意將影象字尾命名為png或者jpg(或者我們網上下載的資料集中被修改了字尾),我們都不在意。但是實際上部分軟體不會像opencv自動處理,我在這裡就報錯了。
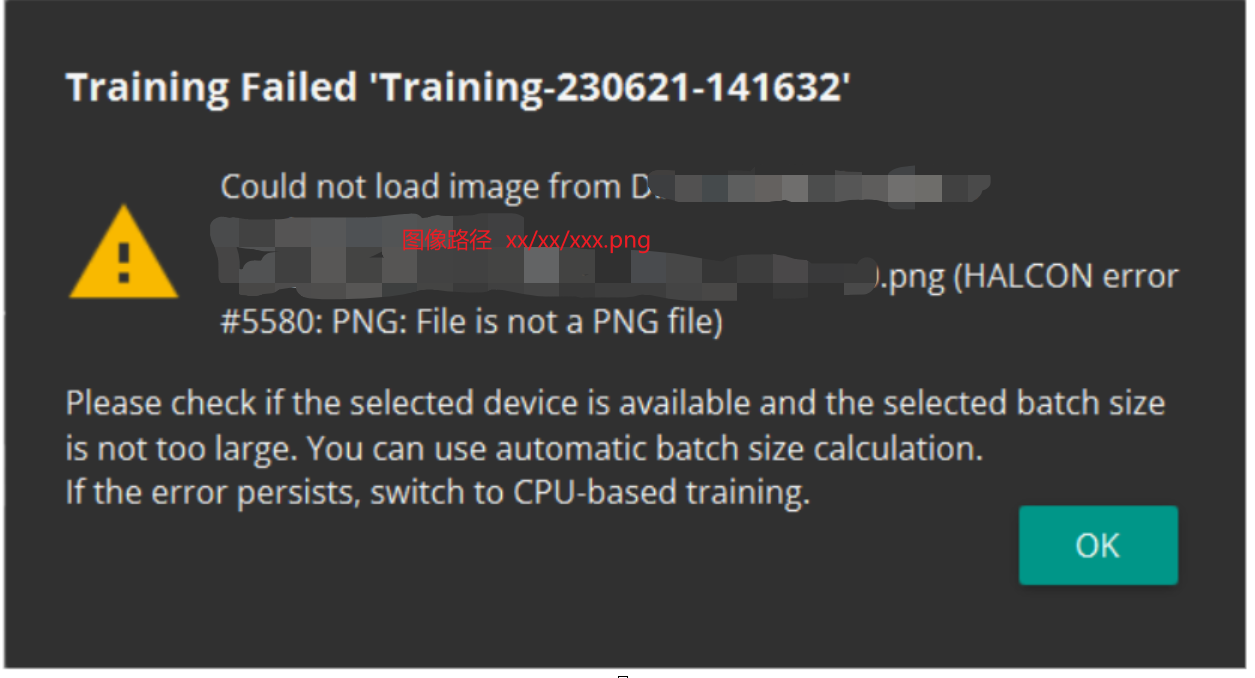
具體深入下去,就是下圖,實際上影象字尾是jpg,但是我拿到的資料是png,而我直接喂入軟體就報錯如上:

實際上這兩個影象都是png影象,但是可能就會出現有些人誤命名,將其影象字尾命名為jpg。這就導致了上面的問題。
我們具體分析,當我們將影象字尾從.png修改為.jpg時,實際上並沒有改變影象的編碼方式和檔案結構。而如我上面所說,OpenCV是一個功能強大的計算機視覺庫,它可以根據檔案的實際內容來識別影象格式,而不僅僅依賴於檔案字尾。因此,OpenCV能夠讀取被錯誤命名的影象檔案。
然而,其他一些軟體可能只依賴於檔案字尾來確定影象格式,而不會嘗試解析檔案內容。當你將影象字尾從.png修改為.jpg時,這些軟體可能會嘗試按照JPEG格式去解析該檔案,但是由於檔案實際上是一個PNG格式的影象,所以會報錯並指出檔案不是一個有效的PNG檔案。
所以要正確地處理影象檔案,建議使用正確的檔案字尾來反映實際的影象格式。這樣可以確保不同的軟體能夠正確地解析和處理影象檔案。
問題2:影象隨便儲存為jpg,結果mask結果對不上
當我寫這篇部落格的時候,我發現也有網友有同樣的問題,哈哈哈,於是我就更堅決了自己要寫這個的原因。
首先復現一下下面問題,並解釋一下。
我們就將輸出的影象儲存為影象(即jpg和png),然後讀取出來,看看結果:
import sys
import os
import numpy as np
def count_pixel_values(image):
count_res = {}
# 統計畫素值數量
pixel_counts = np.bincount(image.flatten())
# 顯示結果
for pixel_value, count in enumerate(pixel_counts):
if count > 0:
count_res[pixel_value] = count
return count_res
# 讀取一張影象,將其轉換為灰度圖
image = cv2.imread(r"./Abyssinian_1.png", 0)
# 建立二值影象
binary_image = np.zeros_like(image, dtype=np.uint8)
binary_image[image == 1] = 0 # 畫素值1對應0畫素
binary_image[image == 2] = 125 # 畫素值2對應125畫素
binary_image[image == 3] = 255 # 畫素值3對應255畫素
# 1, 我將二值圖結果儲存為jpg 和png,我們分別看看
# cv2.imwrite(r"./cat.png", binary_image)
# cv2.imwrite(r"./cat.jpg", binary_image)
# 2, 我分別開啟png 和 jpg 的影象
png_mask = cv2.imread(r"./cat.png", 0)
jpg_mask = cv2.imread(r"./cat.jpg", 0)
print(np.array_equal(png_mask, binary_image), np.sum(png_mask != binary_image))
pixel_counts_png = count_pixel_values(png_mask)
print(pixel_counts_png)
print(np.array_equal(jpg_mask, binary_image), np.sum(jpg_mask != binary_image))
pixel_counts_jpg = count_pixel_values(jpg_mask)
print(pixel_counts_jpg)
# 使用sys.getsizeof()函數來獲取影象物件的大小
# 使用os.path.getsize()函數來獲取影象檔案的大小
binary_image_memory_size = sys.getsizeof(binary_image)
png_mask_memory_size = sys.getsizeof(png_mask)
jpg_mask_memory_size = sys.getsizeof(jpg_mask)
print("二值圖影象記憶體大小: {} 位元組".format(binary_image_memory_size))
print("jpg二值圖影象記憶體大小: {} 位元組".format(png_mask_memory_size))
print("png二值圖影象記憶體大小: {} 位元組".format(jpg_mask_memory_size))
binary_image_file_size = os.path.getsize(r"./Abyssinian_1.png")
png_mask_file_size = os.path.getsize(r"./cat.png")
jpg_mask_file_size = os.path.getsize(r"./cat.jpg")
print("二值圖影象檔案大小: {} 位元組".format(binary_image_file_size))
print("jpg二值圖影象檔案大小: {} 位元組".format(png_mask_file_size))
print("png二值圖影象檔案大小: {} 位元組".format(jpg_mask_file_size))
"""
True 0
{0: 22938, 125: 198766, 255: 18296}
False 8258
{0: 21455, 1: 701, 2: 414, 3: 234, 4: 95, 5: 27, 6: 7, 7: 4, 8: 1, 119: 2, 120: 27, 121: 147, 122: 259, 123: 517, 124: 839, 125: 195208, 126: 879, 127: 449, 128: 258, 129: 123, 130: 38, 131: 17, 132: 3, 248: 7, 249: 12, 250: 71, 251: 170, 252: 421, 253: 911, 254: 1625, 255: 15079}
"""
分析: 實際上我的binary_image影象只有1,2,3三個畫素,即使我轉換為0, 125, 255後,仍然只有三個畫素 但是當我儲存結果為PNG的時候,結果無誤,仍然是三個畫素 而我儲存結果是JPG的時候,結果存在誤差,為多個畫素
結論: 當將二值化的影象儲存為jpg的時候,會出現影象損壞,所以儲存影象的時候,使用jpg需要謹慎 。
當我檢視影象本身的大小的時候 :
二值圖影象記憶體大小: 240120 位元組 jpg二值圖影象記憶體大小: 240120 位元組 png二值圖影象記憶體大小: 240120 位元組 二值圖影象檔案大小: 2994 位元組 jpg二值圖影象檔案大小: 3814 位元組 png二值圖影象檔案大小: 18127 位元組
在OpenCV中,影象儲存為不同字尾(如PNG、JPEG、BMP)的檔案時,它們的檔案格式和儲存方式是不同的,儘管它們可能在視覺上看起來相同。 這是因為不同的影象格式使用不同的壓縮演演算法和編碼方式來儲存影象資料。這些格式有各自的優勢和特點,適用於不同的應用和需求。
還有下面的:
比如我們檢視一張特殊的png格式的mask影象,如下(特殊是因為是彩色的灰度圖):
和一張正常的mask影象,如下:
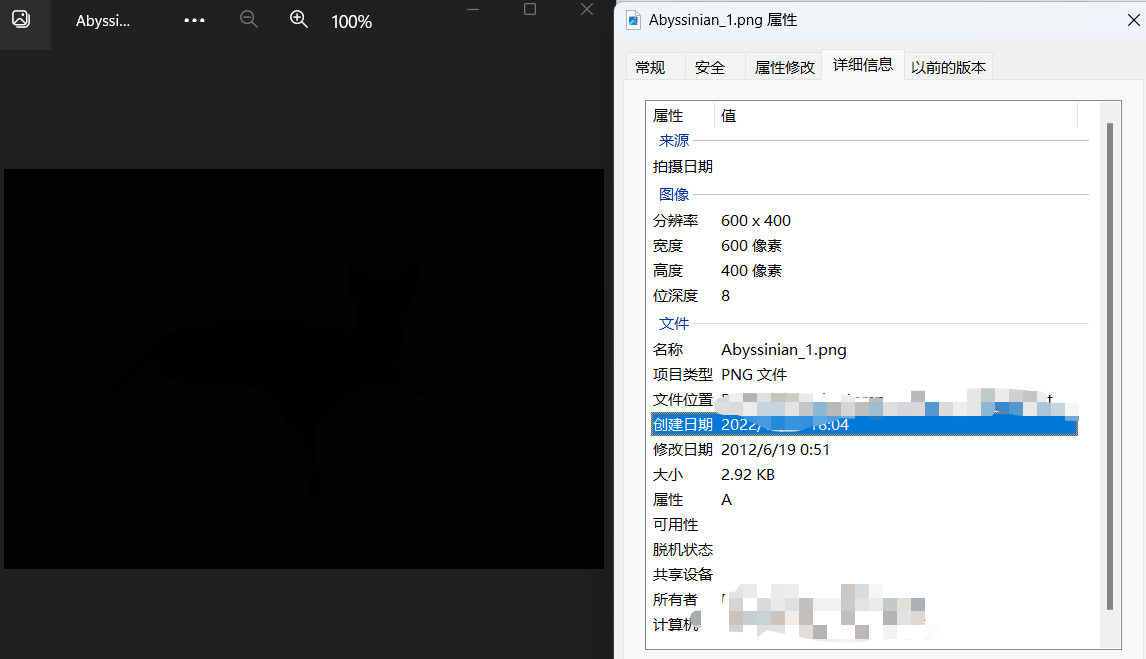
我們對比一下,實驗如下:
import cv2
from PIL import Image
import numpy as np
"""
測試任務:
1,使用opencv直接讀取png影象
2,使用opencv讀取png影象,以原始的通道順序讀取PNG影象,而不進行任何顏色通道的轉換
3,使用PIL庫讀取png影象
4,判斷opencv讀取的影象是否修改畫素值
測試方案及結論:
1,使用語意分割的mask影象,畫素只有1,2,3進行測試。
測試結果如下:
cv_img shape: (400, 600)
cv_origin_img shape: (400, 600)
pil_img_np shape: (400, 600)
0
0
pixel_counts_png_cv1: {1: 22938, 2: 198766, 3: 18296}
pixel_counts_png_cv2: {1: 22938, 2: 198766, 3: 18296}
pixel_counts_png_pil: {1: 22938, 2: 198766, 3: 18296}
測試結論:
對於畫素只有1,2,3的影象,無論用什麼讀取結果都一樣。
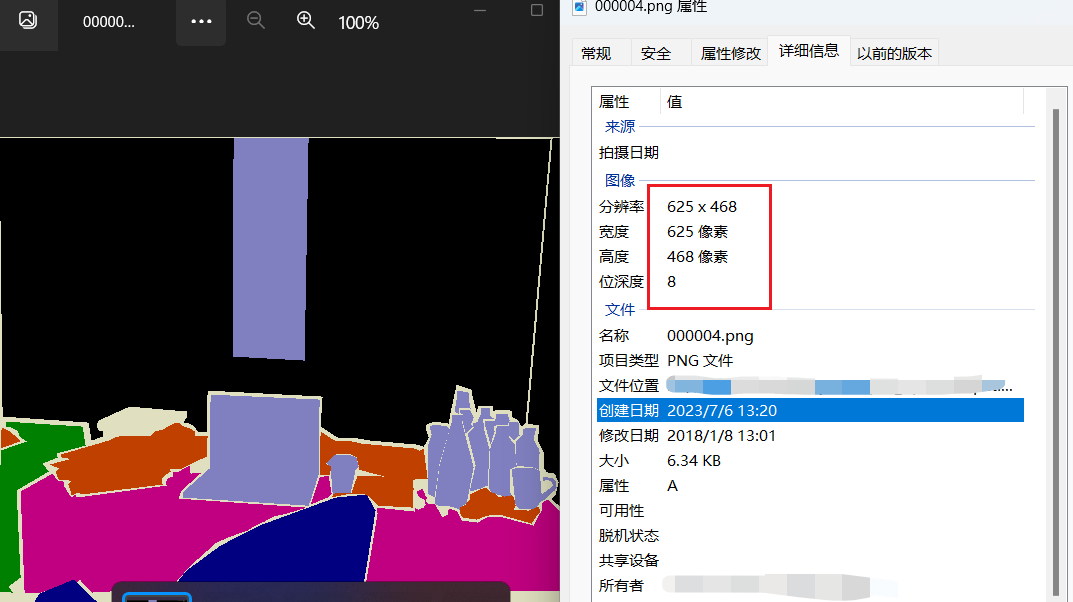
2, 測試我截圖的那個哥們,我使用的是PNG圖片,而且是8bit的深度,但是有些影象會不變,有些會變。
使用語意分割的mask影象,是彩色影象。
測試結果如下:
cv_img shape: (468, 625)
cv_origin_img shape: (468, 625, 3)
pil_img_np shape: (468, 625)
128589
1
pixel_counts_png_cv1: {0: 163911, 15: 16626, 72: 36210, 75: 5261, 95: 12644, 135: 37681, 220: 20167}
pixel_counts_png_cv2: {0: 584361, 64: 12644, 128: 133459, 192: 106702, 224: 40334}
pixel_counts_png_pil: {0: 163911, 2: 5261, 4: 16626, 13: 36210, 25: 12644, 39: 37681, 255: 20167}
385767
測試結論:
對於畫素存在多個不同的pixel的話,可以看出opencv讀取資料,會修改畫素值。
"""
def count_pixel_values(image):
count_res = {}
# 統計畫素值數量
pixel_counts = np.bincount(image.flatten())
# 顯示結果
for pixel_value, count in enumerate(pixel_counts):
if count > 0:
count_res[pixel_value] = count
return count_res
# img_path = r"./Abyssinian_1.png"
img_path = r"./000004.png"
# opencv 直接讀取影象(會預設轉換為BGR)
cv_img = cv2.imread(img_path)
# 因為我們知道要對比的是單通道的影象,所以先轉換為灰度圖
cv_img = cv2.cvtColor(cv_img, cv2.COLOR_BGR2GRAY)
# opencv讀取原始通道
cv_origin_img = cv2.imread(img_path, cv2.IMREAD_UNCHANGED)
# PIL 庫讀取image
pil_img = Image.open(img_path)
pil_img_np = np.array(pil_img)
print("cv_img shape: ", cv_img.shape)
print("cv_origin_img shape: ", cv_origin_img.shape)
print("pil_img_np shape: ", pil_img_np.shape)
print(np.sum(cv_img != pil_img_np))
print(np.sum(cv_origin_img != pil_img_np))
pixel_counts_png_cv1 = count_pixel_values(cv_img)
pixel_counts_png_cv2 = count_pixel_values(cv_origin_img)
pixel_counts_png_pil = count_pixel_values(pil_img_np)
print("pixel_counts_png_cv1: ", pixel_counts_png_cv1)
print("pixel_counts_png_cv2: ", pixel_counts_png_cv2)
print("pixel_counts_png_pil: ", pixel_counts_png_pil)
merge_cv = cv2.merge([cv_img, cv_img, cv_img])
merge_pil = cv2.merge([pil_img_np, pil_img_np, pil_img_np])
print(np.sum(merge_cv != merge_pil))
總結:對兩個問題的分析和總結
上面的實驗和錯誤點,都說明了一個問題。對於儲存影象格式為png還是jpg,我們根本不清楚,也不是很理解這二者到底有啥區別,到底哪個儲存畫素高,哪個低。哪個佔的記憶體大,哪個小。哪個改變畫素,哪個儲存原始畫素,實際上都一臉懵逼。
於是我覺得要解決上面問題,首先必須瞭解其構成原理。下面詳細學習一下。
1,影象字尾jpg, bmp, png的定義
1.1 JPG的定義
JPEG(Joint Photographic Experts Group)是一種常見的有失真壓縮點陣圖影象格式,廣泛用於儲存和傳輸照片和其他真實場景影象。它的目標是通過壓縮演演算法在影象質量和檔案大小之間找到平衡。它通過犧牲一些細節來減小影象檔案的大小。JPEG格式通常用於儲存照片、彩色影象等,以便在網路上共用或用於顯示,因為它可以在相對較小的檔案大小下提供較好的視覺質量。
以下是JPEG影象格式的一些簡介:
-
有失真壓縮:JPEG使用有失真壓縮演演算法,通過犧牲一些影象細節來減小檔案大小。壓縮程度可以通過調整壓縮質量引數來控制,不同的壓縮質量會導致不同程度的影象質量損失。
-
適用於連續色調影象:JPEG主要用於儲存連續色調的影象,特別是照片和真實場景影象。它對顏色和亮度的變化有較好的表示能力,適用於自然影象的壓縮和顯示。
-
24位元位深:JPEG支援真彩色影象,即每個畫素使用24位元(RGB三通道)來表示顏色。這使得JPEG可以表示約1677萬種顏色。
-
可調壓縮質量:JPEG允許使用者根據需要選擇不同的壓縮質量。較高的壓縮質量會產生較大的檔案大小,同時保留更多的影象細節。較低的壓縮質量會產生更小的檔案大小,但會引入更明顯的影象質量損失。
-
不支援透明度:JPEG不支援像PNG那樣的透明度,它只能表示不透明畫素。這使得它不適合用於需要透明背景的影象,如圖示和疊加影象。
-
平臺無關性:JPEG影象格式是平臺無關的,可以在不同的作業系統和軟體中進行讀取和顯示。
JPEG影象格式在影象壓縮和儲存領域具有廣泛應用,特別是用於照片和真實場景影象。然而,由於有失真壓縮的特性,JPEG格式不適合用於需要精確無失真表示和透明度的應用,如圖形設計、影象處理和需要保留細節的專業應用。
1.2 PNG的定義
PNG(Portable Network Graphics)是一種無失真的點陣圖影象格式,廣泛用於儲存和傳輸影象。它的目標是提供一種比傳統的GIF格式更好的替代方案,同時避免了GIF格式的一些限制和專利問題。它可以保留影象的原始質量和細節。PNG格式通常用於儲存需要保持高質量且不損失細節的影象,例如圖示、透明背景的影象等。
以下是PNG影象格式的一些簡介:
-
無失真壓縮:PNG使用無失真壓縮演演算法,不會引入影象質量損失。相比於有失真壓縮格式如JPEG,PNG適用於那些需要保留細節和影象質量的應用,例如影象編輯、圖形設計和Web影象。
-
Alpha通道支援:PNG支援透明度和半透明效果,通過Alpha通道可以定義畫素的不透明度。這使得PNG成為合適的選擇用於影象疊加和合成。
-
256級灰度和真彩色支援:PNG支援灰度影象(8位元位深)和真彩色影象(24位元位深)。真彩色PNG影象可以顯示約1677萬種顏色,提供更豐富和精確的顏色表示。
-
支援無失真透明度:PNG的透明度支援不僅限於簡單的完全透明和完全不透明,還可以定義不同的透明度級別,實現更復雜的透明效果。
-
平臺無關性:PNG影象格式是平臺無關的,可以在不同的作業系統和軟體中進行讀取和顯示。
-
版權和專利:PNG是一種開放標準格式,沒有涉及專利或版許可權制。這使得PNG成為一種廣泛採用的影象格式。
總體而言,PNG影象格式在保持影象質量、支援透明度和顏色表示方面具有優勢,並被廣泛應用於影象處理、Web影象、圖形設計和其他需要保留影象細節和質量的應用中。
1.3 GIF的定義
GIF(Graphics Interchange Format)是一種常見的無失真壓縮點陣圖影象格式,廣泛用於儲存和傳輸簡單的動畫和圖形。GIF影象格式最初由CompuServe開發,後來成為網際網路上最流行的影象格式之一。
以下是GIF影象格式的一些簡介:
-
無失真壓縮:GIF使用無失真壓縮演演算法,不會引入影象質量損失。這使得它適用於儲存和傳輸需要保留細節和影象質量的應用。
-
索引調色盤:GIF使用調色盤技術,其中影象中的每個畫素值通過調色盤中的索引來表示。調色盤最多可以包含256種不同的顏色。
-
動畫支援:GIF支援多幀動畫,可以在一張影象檔案中儲存多個影象幀,通過控制幀間延遲時間來建立簡單的動畫效果。
-
透明度支援:GIF支援透明畫素,其中一個顏色被定義為透明。這使得GIF影象可以顯示透明背景,並與其他影象疊加。
-
簡單圖形和動畫:GIF主要用於儲存簡單的圖形、圖示和動畫。它對於影象的顏色數目和細節有一定的限制,通常不適用於照片和真實場景影象。
-
支援LZW壓縮演演算法:GIF使用LZW(Lempel-Ziv-Welch)壓縮演演算法來減小檔案大小。該演演算法通過建立和使用字典來編碼影象資料,以進一步壓縮資料。
GIF影象格式在Web影象、圖示、簡單動畫和圖形設計中得到廣泛應用。由於它的無失真壓縮和透明度支援,GIF影象通常用於需要保留影象質量和簡單動畫的情況。然而,由於調色盤限制和對顏色和細節的限制,GIF不適用於需要更高質量和更豐富顏色表示的照片和真實場景影象。
1.4 BMP的定義
BMP(Bitmap)是一種常見的無壓縮點陣圖影象格式,它是Windows作業系統中最常見的影象格式之一。BMP影象格式以畫素為單位儲存影象資料,提供了物件的精確控制和編輯,以下是BMP影象格式的一些簡介:
- 無壓縮:BMP使用無壓縮的點陣圖資料儲存影象,不會引入影象質量損失。它以原始畫素資料的形式儲存每個畫素的顏色值,因此檔案大小相對較大。
- 位深度:BMP支援不同的位深度,包括1位(黑白影象)、8位元(256級灰度或調色盤索引顏色)和24位元(真彩色,約1677萬種顏色)。高位深的BMP影象可以提供更精確的顏色表示和影象細節。
- 畫素資料佈局:BMP影象按行儲存畫素資料,每行的畫素從左到右依次排列。每個畫素可以使用RGB顏色模式(對於24位元位深)或調色盤索引(對於8位元位深)來表示。
- 支援透明色:BMP影象可以指定一個顏色作為透明色,使得該顏色在影象顯示時變為透明,適用於一些特殊效果的實現。
- 平臺無關性:BMP影象格式是平臺無關的,可以在不同的作業系統和軟體中進行讀取和顯示。
- 大檔案大小:由於無壓縮的特性,BMP影象檔案大小相對較大,對儲存和傳輸的需求較高。這使得BMP不太適用於Web影象和需要節省儲存空間的應用。
BMP影象格式適用於那些需要對影象進行精確編輯、保留影象細節和顏色準確性的應用。然而,由於檔案大小較大和缺乏壓縮,BMP影象在Web影象和儲存空間受限的場景中使用較少。
1.5 常見的JPEG和PNG的區別
雖然我上面已經摘抄出了其定義,但是我估計大多數人不仔細看,所以我直接將常見的JPEG和PNG的區別整理如下。
JPEG和PNG是常見的影象格式,它們在影象壓縮、質量損失、透明度支援等方面存在一些區別。下面是一些主要的區別:
-
壓縮演演算法:
- JPEG使用有失真壓縮演演算法,它通過減少影象中的細節和顏色資訊來減小檔案大小。這導致在高壓縮比下會損失一些細節,併產生一些壓縮偽影。
- PNG使用無失真壓縮演演算法,它能夠保持影象的原始質量和細節。它適用於儲存需要保持高質量且不損失細節的影象,但檔案大小通常比JPEG大。
-
顏色支援:
- JPEG主要適用於彩色影象,它能夠顯示數百萬種顏色。
- PNG支援全綵色影象,並能夠顯示透明度。它還支援索引調色盤,可以減小檔案大小。
-
透明度支援:
- JPEG不支援透明度。任何影象中的透明部分將以黑色或白色進行填充。
- PNG支援透明度,並能夠將影象中的某些部分設定為完全透明,以便與背景融合。
-
檔案大小:
- JPEG在相同視覺質量下,檔案大小通常比PNG要小。這使得它適用於在頻寬受限的環境下傳輸影象,如網路傳輸。
- PNG檔案大小通常比JPEG大,因為它使用無失真壓縮演演算法。這使得它適用於需要保持高質量的影象儲存,如圖示、透明背景等。
1.6 什麼是影象位深
當我們看到一張數位影像時,我們常常會關注影象的顏色、細節和質量。這些特徵與影象的位深(Bit Depth)密切相關。影象位深是指數位影像中每個畫素所使用的二進位制位數,用於表示顏色或亮度的資訊量或精度。本文將介紹影象位深的定義、常見的位深型別以及它們之間的區別。
位深定義: 位深表示每個畫素值所使用的二進位制位數。較高的位深可以提供更多的顏色或灰度級別,從而實現更準確的顏色表示和更細緻的影象細節。例如,一個8位元位深的影象可以表示256個不同的亮度或顏色級別(0-255),而一個16位元位深的影象可以表示65,536個級別。
常見的位深型別:
- 1位(2色):1位位深的影象只能表示兩個顏色或灰度級別,通常為黑色和白色。
- 8位元(256色):8位元位深的影象可表示256個不同的顏色或灰度級別。這種位深常用於網頁影象、簡單的圖形和影象處理應用。
- 24位元(真彩色):24位元位深的影象通常稱為真彩色影象,因為它能夠表示約1677萬種顏色。這是最常見的影象位深,適用於照片、影象處理和顯示應用。
- 32位元(增強色彩):32位元位深的影象在真彩色基礎上加入了額外的通道,通常為透明度通道(Alpha通道)。這種位深常用於影象合成和透明效果。
位深之間的區別: 不同的位深具有不同的顏色精度和可表示範圍。較高的位深可以提供更豐富的顏色或灰度級別,更好地保留影象的細節和質量。然而,較高的位深也需要更多的儲存空間來儲存影象資料,並對影象處理和顯示的計算資源有更高的要求。
總結: 影象位深是指數位影像中每個畫素所使用的二進位制位數,用於表示顏色或亮度的資訊量或精度。不同的位深可以提供不同的顏色精度和細節級別,常見的位深包括1位、8位元、24位元和32位元。通過選擇適當的位深,我們可以平衡影象質量和儲存需求,以滿足特定應用的需求。
2 如何檢視真實的影象字尾
如果真的被修改了字尾,那麼我們如何檢視檔案字尾呢,下面方法可以讓其原形畢露。
2.1 常見的影象格式及其十六進位制
下面是一些常見影象格式及其檔案頭的十六進位製表示:
-
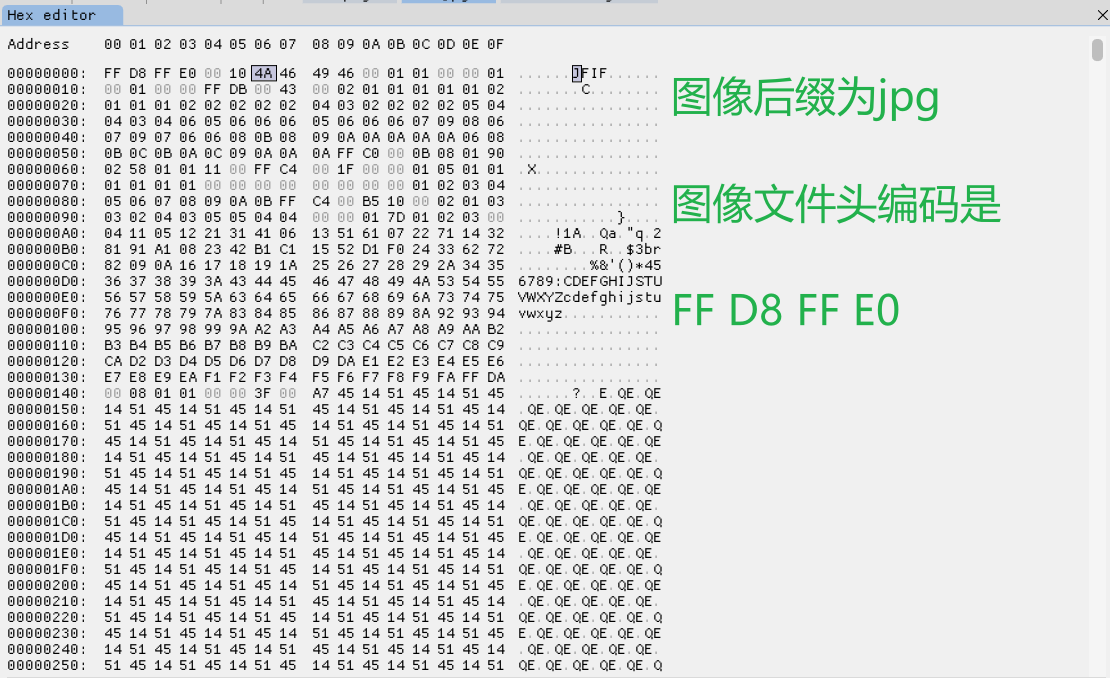
JPEG/JPG:
- 檔案頭:FF D8 FF
- 檔案尾(結束標記):FF D9
-
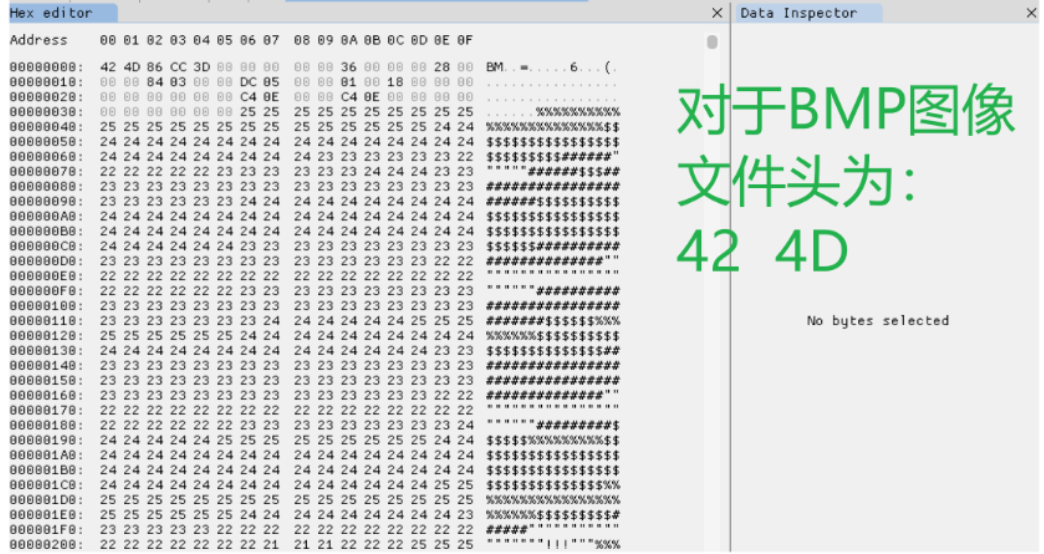
BMP:
- Windows BMP(非壓縮)檔案頭:42 4D
- Windows BMP(壓縮)檔案頭:42 4D
- OS/2 BMP檔案頭:42 4D
-
PNG:
- 檔案頭:89 50 4E 47 0D 0A 1A 0A
- 檔案尾(IEND標記):49 45 4E 44 AE 42 60 82
-
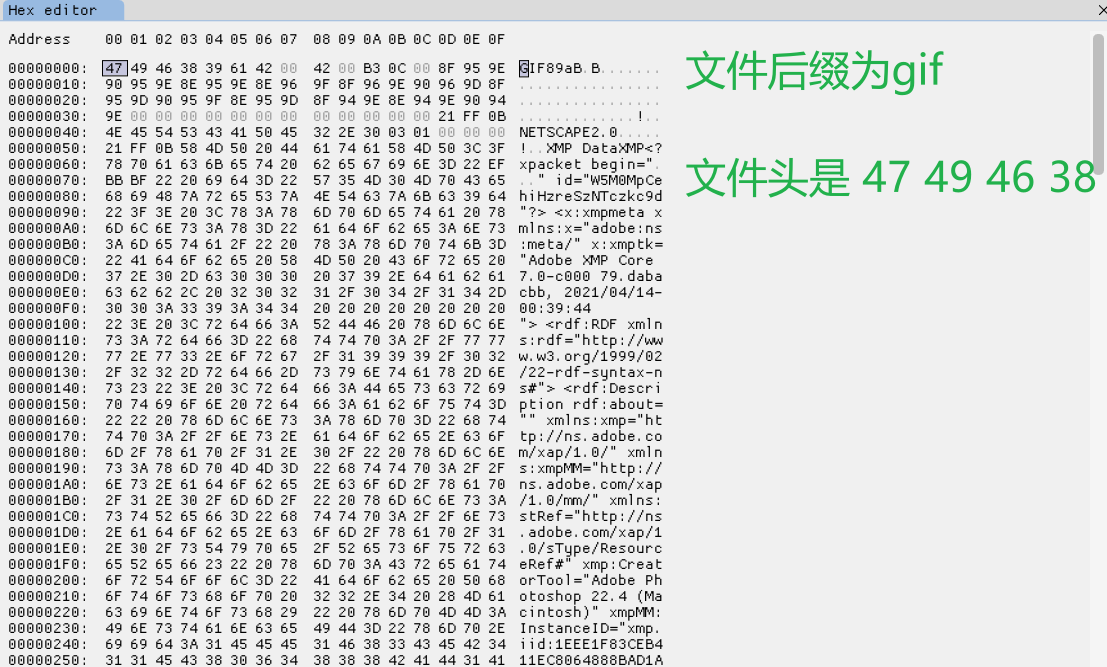
GIF:
- 檔案頭:47 49 46 38 39 61 或 47 49 46 38 37 61
- 檔案尾(結束標記):00 3B
-
TIFF:
- Little-Endian(Intel)格式檔案頭:49 49 2A 00
- Big-Endian(Motorola)格式檔案頭:4D 4D 00 2A
-
ICO:
- 檔案頭:00 00 01 00
-
PSD (Photoshop):
- 檔案頭:38 42 50 53
-
WebP:
- 檔案頭:52 49 46 46 ?? ?? ?? ?? 57 45 42 50
-
SVG (可縮放向量圖形):
- 檔案頭:3C 73 76 67
這些是一些常見的影象格式及其檔案頭的十六進位製表示。請注意,檔案頭的確切值可能因特定軟體、檔案版本或其他因素而有所變化。因此,在實際應用中,最好使用專門的影象處理庫或工具來解析和處理不同影象格式的檔案。
2.2 使用專門的工具解析影象
下面看看我們上面整理的檔案頭是否正確,下面檢視四種常見的不同字尾的檔案的檔案頭:
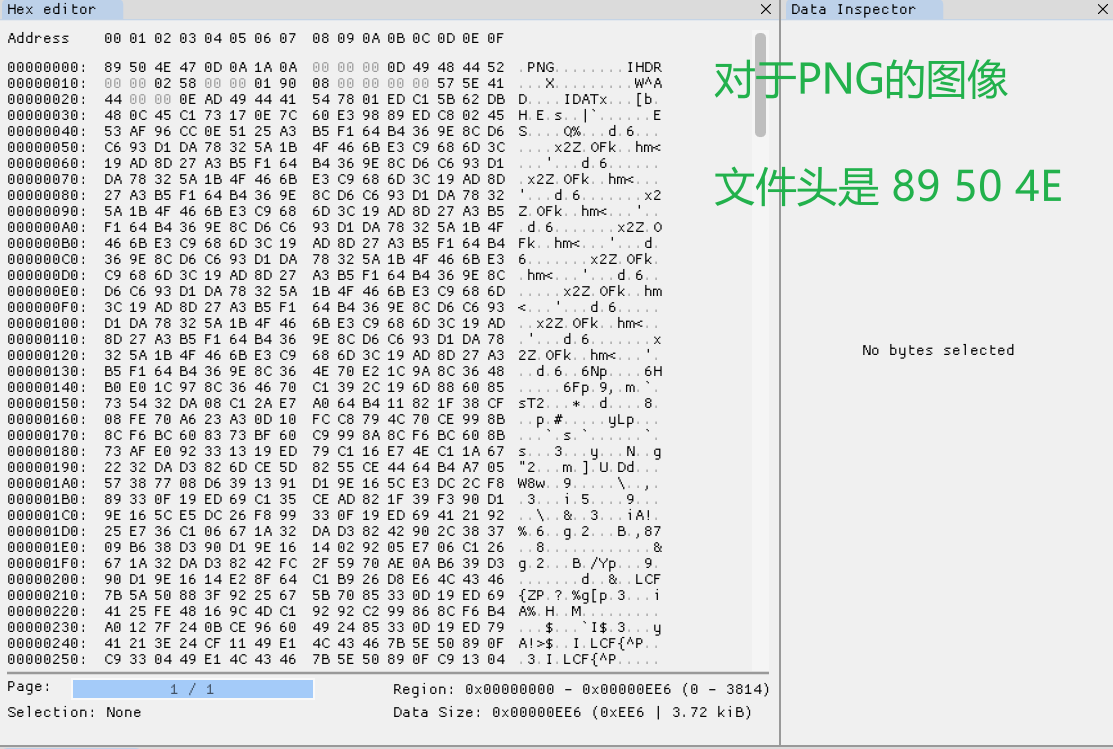
3,為什麼opencv讀取資料的格式都是BGR呢?
為了瞭解清楚,我還特意查了為什麼opencv讀取資料的格式是BGR而不是RGB呢?
OpenCV讀取影象時將其表示為BGR(藍綠紅)通道順序的畫素排列。這是因為在許多計算機視覺應用中,BGR通道順序是最常用的,尤其是在早期的彩色影象處理中。歷史上,BGR通道順序的選擇與許多計算機視覺庫和工具的設計有關,包括OpenCV。這些庫和工具在早期的硬體和軟體平臺上的開發中,採用了BGR通道順序的表示方式。
OpenCV讀取影象為BGR的歷史原因可以追溯到早期計算機視覺應用的發展和硬體限制。在計算機視覺領域的早期,主要應用是在基於CRT(陰極射線管)顯示器的計算機系統上進行影象處理。在這些系統中,影象資料通常是以RGB(紅綠藍)通道順序儲存的,因為CRT顯示器的光柵掃描方式是從左上角開始,按照RGB的順序逐行掃描。
然而,在早期的電腦架構和作業系統中,處理影象資料的方式可能與顯示器的儲存方式不同。由於BGR通道順序在一些早期影象處理庫和工具中被採用,OpenCV也選擇了這種通道順序。
此外,早期的計算機系統在記憶體中儲存影象資料時採用了連續的行優先(row-major)儲存方式。而BGR通道順序在這種儲存方式下能夠更好地利用記憶體的連續性,從而提高影象資料的讀取效率。
儘管現代計算機和顯示器普遍使用RGB通道順序,但由於OpenCV的廣泛應用和與現有程式碼的相容性考慮,保持了BGR通道順序作為預設的影象表示方式。
需要注意的是,雖然OpenCV預設將影象讀取為BGR通道順序,但可以使用適當的函數將影象轉換為其他通道順序,如前面提到的cv2.cvtColor()函數。這使得在OpenCV中進行RGB格式影象的處理仍然是可行的。
在現代計算機視覺領域,許多其他工具和庫使用RGB(紅綠藍)通道順序來表示影象。RGB通道順序更符合人眼感知顏色的方式,因為光的三原色是紅、綠和藍。
4,python如何轉換png到JPG,JPG到PNG
當然,OpenCV也是OK的,直接儲存的時候設定影象字尾即可,但是因為我推薦使用PIL庫。所以我的範例指令碼都是使用PIL庫實現的,程式碼如下:
from PIL import Image
"""
使用PIL庫儲存不同格式的影象(常見的轉換,比如jpg轉png, png轉jpg)
這裡驗證的是:
1,將 jpg 轉換為 png,並儲存
2,將儲存的png 讀取出來再儲存為 jpg
3,對於儲存的jpg 和原始的jpg 看結果是否相等
結論:
False
原因:
JPEG格式對影象進行壓縮時,會丟失一些細節和畫素資訊,因此還原回去的影象與原始的PNG影象可能存在一些差異。
將PNG影象儲存為JPEG格式會引起一定程度的影象壓縮損失,因為JPEG是一種有失真壓縮格式。因此,還原回去的影象和原始的img不會完全相等。
"""
# step1: 將 jpg 格式儲存為png
img_jpg = Image.open("./test/cat.jpg")
# save()有兩個引數,第一個是儲存轉換後檔案的檔案路徑,第二個引數是要轉換的檔案格式。
img_jpg.save("./test/cat_jpg2png.png", "PNG")
#
img_png = Image.open("./test/cat_jpg2png.png")
img_png.save("./test/cat_jpg2png2jpg.jpg", "JPEG")
img_origin_jpg = Image.open("./test/cat.jpg")
img_convert_jpg = Image.open("./test/cat_jpg2png2jpg.jpg")
print(img_origin_jpg.getdata(), type(img_convert_jpg.getdata()))
# <ImagingCore object at 0x000001D5E4197590> <class 'ImagingCore'>
pixels1 = list(img_origin_jpg.getdata())
pixels2 = list(img_convert_jpg.getdata())
print(pixels1 == pixels2)
# False