Prometheus-3:一文詳解promQL
2023-07-07 15:01:09
讀前提示:
本文字數較多且緊湊,最好預留15min一次性看完,好營養,易吸收。
promQL詳解
Prometheus提供了內建的資料查詢語言PromQL(全稱為Prometheus Query Language),支援使用者進行實時的資料查詢及聚合操作。
PromQL基本介紹
Prometheus基於指標名稱(metrics name)以及附屬的標籤集(labelset)唯一定義一條時間序列:
- 指標名稱代表著監控目標上某類可測量屬性的基本特徵標識
- 標籤則是這個基本特徵上再次細分的多個可測量維度
時間序列資料:按照時間順序記錄系統、裝置狀態變化的資料,每個資料稱為一個樣本:
- 資料採集以特定的時間週期進行,因而,隨著時間流逝,將這些樣本資料記錄下來,將生成一個離散的樣本資料序列
- 該序列也稱為向量(Vector);而將多個序列放在同一個座標系內(以時間為橫軸,以序列為縱軸),將形成一個由資料點組成的矩陣
Prometheus資料模型
Prometheus中,每個時間序列都由指標名稱(Metric Name)和標籤(Label)來唯一標識,格式為「{
指標名稱:通常用於描述系統上要測定的某個特徵;
- 例如,http_requests_total表示接收到的HTTP請求總數;
- 支援使用字母、數位、下劃線和冒號,且必須能匹配RE2規範的正規表示式;
標籤:鍵值型資料,附加在指標名稱之上,從而讓指標能夠支援多緯度特徵;可選項;
- 例如,http_requests_total{method=GET}和http_requests_total{method=POST}代表著兩個不同的時間序列;
- 標籤名稱可使用字母、數位和下劃線,且必須能匹配RE2規範的正規表示式;
- 以「_ _」為字首的名稱為Prometheus系統預留使用

指標名稱及標籤使用注意事項
指標名稱和標籤的特定組合代表著一個時間序列;
- 指標名稱相同,但標籤不同的組合分別代表著不同的時間序列
- 不同的指標名稱自然更是代表著不同的時間序列
promQL的資料型別
PromQL的表示式中支援4種資料型別:
- 即時向量(Instant Vector):特定或全部的時間序列集合上,具有相同時間戳的一組樣本值稱為即時向量;
- 範圍向量(Range Vector):特定或全部的時間序列集合上,在指定的同一時間範圍內的所有樣本值;
- 標量(Scalar):一個浮點型的資料值;
- 字串(String):支援使用單引號、雙引號或反引號進行參照,但反引號中不會對跳脫字元進行跳脫
資料型別演示
先看個例子,後邊會詳細講解:
- 即時向量,例如:node_cpu_seconds_total{job="nodes"},返回同一時間一組樣本值
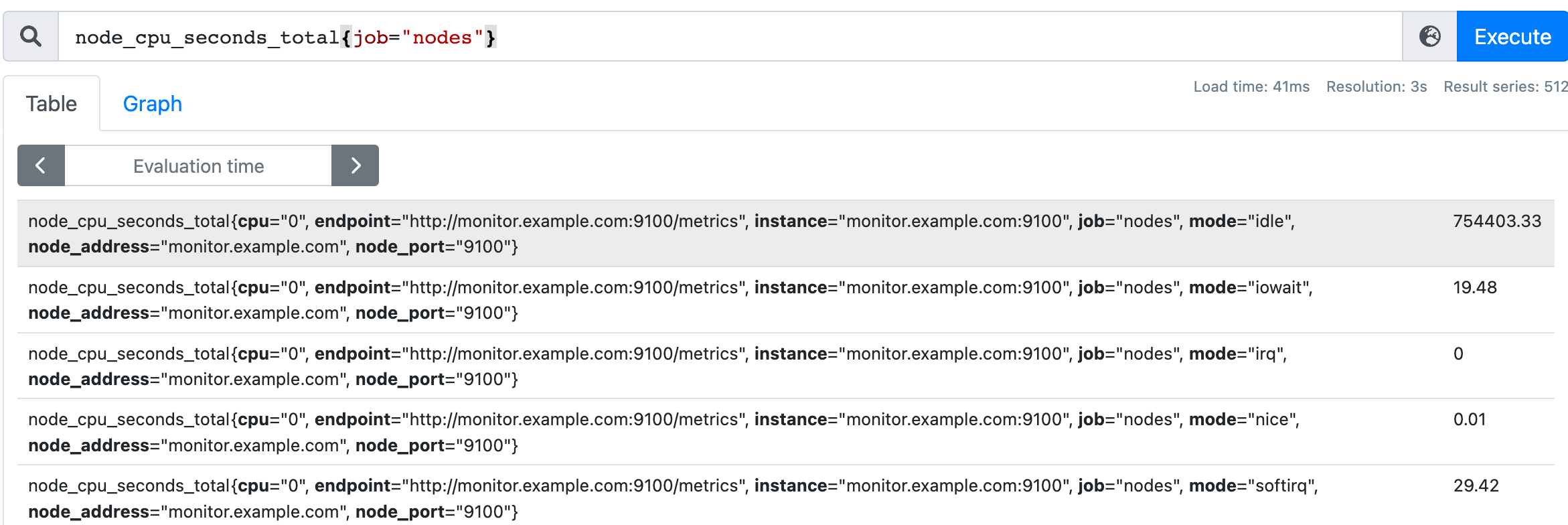
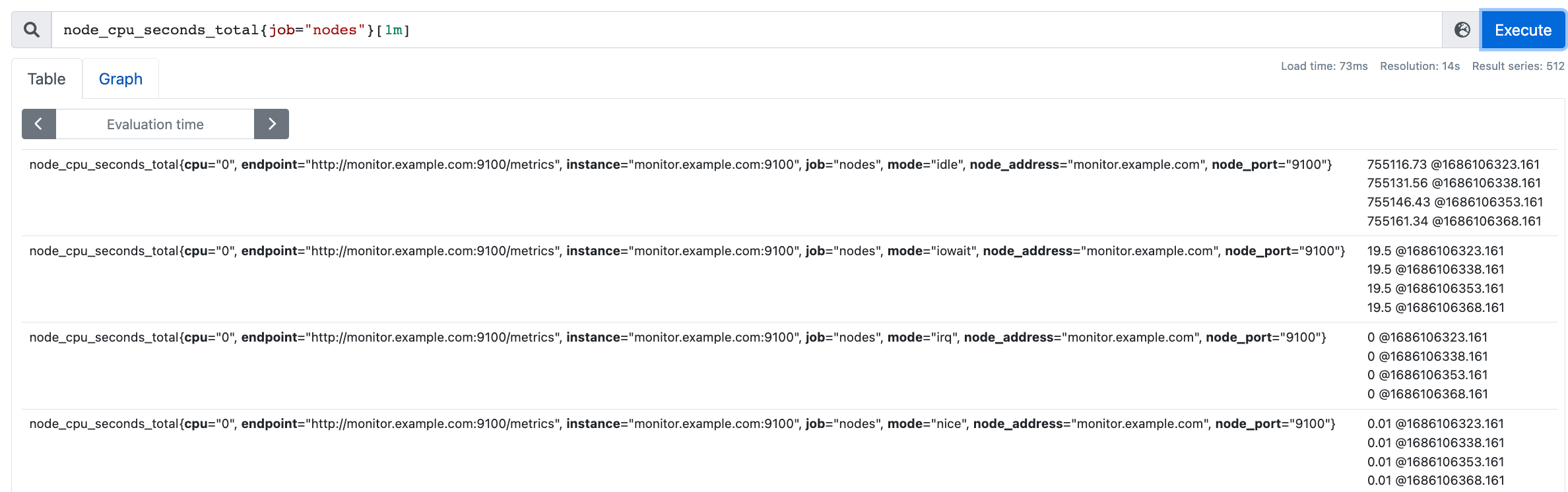
- 範圍向量,例如:node_cpu_seconds_total{job="nodes"}[1m],返回1min內的所有樣本值
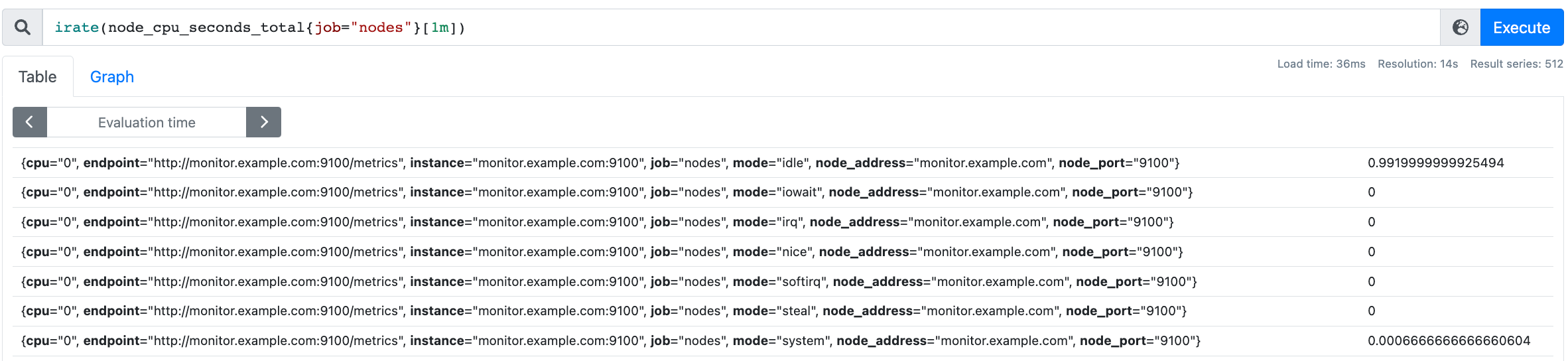
- 標量,例如:irate(node_cpu_seconds_total{job="nodes"}[1m]),返回一個浮點型的資料值
- 字串,例如:node_cpu_seconds_total{job="nodes"},"nodes"就是字串型別。
向量表示式使用要點
表示式的返回值型別亦是即時向量、範圍向量、標量或字串四種型別之一,但是,有些使用場景要求表示式返回值必須滿足特定的條件,例如:
- 需要將返回值繪製成圖形時,僅支援即時向量型別的資料
- 對於諸如rate一類的速率函數來說,其要求使用的卻又必須是範圍向量型的資料
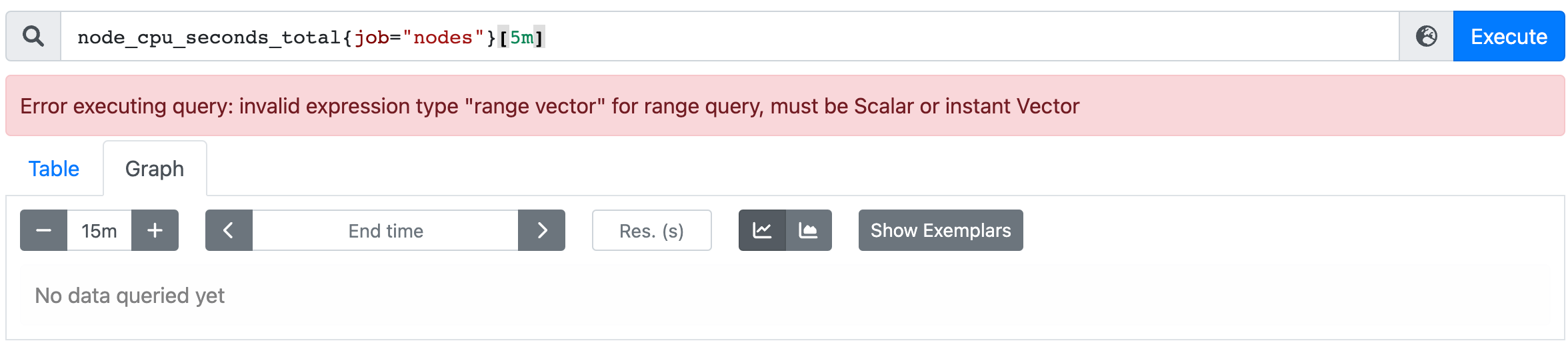
由於範圍向量型資料不能用於表示式瀏覽器中圖形繪製功能,若使用,瀏覽器會返回「Error executing query: invalid expression type "range vector" for range query, must be Scalar or instant Vector」一類的錯誤:
匹配器
匹配器用於定義標籤過濾條件,目前支援以下四種匹配操作符:
- =:選擇與提供的字串完全相同的標籤
- !+:選擇與提供的字串不相同的標籤
- =~:選擇正規表示式與提供的字串(或子字串)相匹配的標籤
- !~:選擇正規表示式與提供的字串(或子字串)不匹配的標籤。
注意事項:
- 匹配到空標籤值的匹配器時,所有未定義該標籤的時間序列同樣符合條件
- 正規表示式將執行完全錨定機制,它需要匹配指定標籤的整個值
- 向量選擇器至少要包含一個指標名稱,或者至少有一個不會匹配到空字串的匹配器
- 使用"__name__"作為標籤名稱,還能夠對指標名稱進行過濾,例:{name=~"http_request.*"}
即時向量選擇器
即時向量選擇器由兩部分組成
- 指標名稱:用於限定特定指標下的時間序列,即負責過濾指標;可選;
- 匹配器(Matcher):或稱為標籤選擇器,用於過濾時間序列上的標籤;定義在{}之中;可選;
定義即時向量選擇器時,以上兩個部分應該至少給出一個;於是,這將存在以下三種組合:
- 僅給定指標名稱,或在標籤名稱上使用了空值的匹配器,例如node_cpu_seconds_total和node_cpu_seconds_total{}相等
- 僅給定匹配器,返回所有符合給定匹配器的所有時間的即使樣本,例如:{job="nodes"}
- 指標名稱和匹配器的組合,返回符合條件的所有時間序列上的即時樣本,例如上邊的node_cpu_seconds_total{job="nodes"}
範圍向量選擇器
同即時向量選擇器的唯一不同之處在於,範圍向量選擇器需要在表示式後緊跟一個方括號[ ]來表達需在時間時序上返回的樣本所處的時間範圍;
- 時間範圍:以當前時間為基準時間點,指向過去一個特定的時間長度;例如[5m]便是指過去5分鐘之內;
- 時間格式:一個整數後緊跟一個時間單位,例如「5m」中的「m」即是時間單位;
- 可用的時間單位有ms(毫秒)、s(秒)、m(分鐘)、h(小時)、d(天)、w(周)和y(年);
- 必須使用整數時間,且能夠將多個不同級別的單位進行串聯組合,以時間單位由大到小為順序,例如1h30m,但不能使用1.5h;
需要注意的是,範圍向量選擇器返回的是一定時間範圍內的資料樣本,雖然不同時間序列的資料抓取時間點相同,但它們的時間戳並不會嚴格對齊;多個Target上的資料抓取需要分散在抓取時間點前後一定的時間範圍內,以均衡Prometheus Server的負載;因而,Prometheus在趨勢上準確,但並非絕對精準。
偏移量修改器
預設情況下,即時向量選擇器和範圍向量選擇器都以當前時間為基準時間點,而偏移量修改器能夠修改該基準;
偏移量修改器的使用方法是緊跟在選擇器表示式之後使用「offset」關鍵字指定,例如:
- 「http_requests_total offset 5m」,表示獲取以http_requests_total為指標名稱的所有時間序列在過去5分鐘之時的即時樣本
- 「http_requests_total[5m] offset 1d」,表示獲取距此刻1天時間之前的5分鐘之內的所有樣本
PromQL的指標型別
PromQL有四個指標型別,它們主要由Prometheus的使用者端庫使用:
- Counter:計數器,單調遞增,除非重置(例如伺服器或程序重啟)
- Gauge:儀表盤,可增可減的資料
- Histogram:直方圖,將時間範圍內的資料劃分成不同的時間段,並各自評估其樣本個數及樣本值之和,因而可計算出分位數
- 可用於分析因異常值而引起的平均值過大的問題
- 分位數計算要使用專用的histogram_quantile函數
- Summary:類似於Histogram,但使用者端會直接計算並上報分位數
Counter
通常,Counter的總數並沒有直接作用,而是需要藉助於rate、topk、increase和irate等函數來生成樣本資料的變化狀況(增長率):
- rate(http_requests_total[2h]),獲取2小內,該指標下各時間序列上的http總請求數的增長速率;
- topk(3, http_requests_total),獲取該指標下http請求總數排名前3的時間序列;
- irate(http_requests_total[2h]),高靈敏度函數,用於計算指標的瞬時速率;
- 基於樣本範圍內的最後兩個樣本進行計算,相較於rate函數來說,irate更適用於短期時間範圍內的變化速率分析;
Gauge
Gauge用於儲存其值可增可減的指標的樣本資料,常用於進行求和、取平均值、最小值、最大值等聚合計算;也會經常結合PromQL的predict_linear和delta函數使用:
- predict_linear(v range-vector, t, scalar)函數可以預測時間序列v在t秒後的值,它通過線性迴歸的方式來預測樣本資料的Gauge變化趨勢;
- predict_linear(node_sockstat_TCP_inuse{node_port="9100"}[2h],4*3600)根據近兩小時的資料,預測出接下來4小時的tcp socket的活躍連線數

- delta(v range-vector)函數計算範圍向量中每個時間序列元素的第一個值與最後一個值之差,從而展示不同時間點上的樣本值的差值;
- delta(node_netstat_Tcp_CurrEstab{node_port="9100"}[2h]),返回該伺服器活躍狀態的TCP連線數與2小時之前的差異;

Histogram
Histogram是一種對資料分佈情況的圖形表示,由一系列高度不等的長條圖(bar)或線段表示,用於展示單個測度的值的分佈:
- 它一般用橫軸表示某個指標維度的資料取值區間,用縱軸表示樣本統計的頻率或頻數,從而能夠以二維圖的形式展現數值的分佈狀況
- 為了構建Histogram,首先需要將值的範圍進行分段,即將所有值的整個可用範圍分成一系列連續、相鄰(相鄰處可以是等同值)但不重疊的間隔,而後統計每個間隔中有多少值
- 從統計學的角度看,分位數不能被聚合,也不能進行算術運算
對於Prometheus來說,Histogram會在一段時間範圍內對資料進行取樣(通常是請求持續時長或響應大小等),並將其計入可設定的bucket(儲存桶)中
- Histogram事先將特定測度可能的取值範圍分隔為多個樣本空間,並通過對落入bucket內的觀測值進行計數以及求和操作
- 與常規方式略有不同的是,Prometheus取值間隔的劃分採用的是累積(Cumulative)區間間隔機制,即每個bucket中的樣本均包含了其前面所有bucket中的樣本,因而也稱為累積直方圖:
- 可降低Histogram的維護成本
- 支援粗略計算樣本值的分位數
- 單獨提供了_sum和_count指標,從而支援計算平均值
Histogram型別的每個指標有一個基礎指標名稱,它會提供多個時間序列:
- _bucket{le=""}:觀測桶的上邊界(upper inclusive bound),即樣本統計區間,最大區間(包含所有樣本)的名稱為_bucket{le="+Inf"};
- _sum:所有樣本觀測值的總和;
- _count :總的觀測次數,它自身本質上是一個Counter型別的指標;
累積間隔機制生成的樣本資料需要額外使用內建的histogram_quantile()函數即可根據Histogram指標來計算相應的分位數(quantile),即某個bucket的樣本數在所有樣本數中佔據的比例:
- histogram_quantile()函數在計算分位數時會假定每個區間內的樣本滿足線性分佈狀態,因而它的結果僅是一個預估值,並不完全準確;
- 預估的準確度取決於bucket區間劃分的粒度;粒度越大,準確度越低;
Summary
指標型別是使用者端庫的特性,而Histogram在使用者端僅是簡單的桶劃分和分桶計數,分位數計算由Prometheus Server基於樣本資料進行估算,因而其結果未必準確,甚至不合理的bucket劃分會導致較大的誤差;
- Summary是一種類似於Histogram的指標型別,但它在使用者端於一段時間內(預設為10分鐘)的每個取樣點進行統計,計算並儲存了分位數數值,Server端直接抓取相應值即可;
- 但Summary不支援sum或avg一類的聚合運算,而且其分位數由使用者端計算並生成,Server端無法獲取使用者端未定義的分位數,而Histogram可通過PromQL任意定義,有著較好的靈活性;
對於每個指標,Summary以指標名稱為字首,生成如下幾個個指標序列:
- {quantile="<φ>"},其中φ是分位點,其取值範圍是(0 ≤φ≤ 1);計數器型別指標;如下是幾種典型的常用分位點;
- 0、0.25、0.5、0.75和1幾個分位點;
- 0.5、0.9和0.99幾個分位點;
- 0.01、0.05、0.5、0.9和0.99幾個分位點;
- _sum,抓取到的所有樣本值之和;
- _count,抓取到的所有樣本總
Prometheus的聚合函數
聚合表示式
PromQL中的聚合操作語法格式可採用如下面兩種格式之一:
- ([parameter,] ) [without|by (
- [without|by (
分組聚合:先分組、後聚合
- without:從結果向量中刪除由without子句指定的標籤,未指定的那部分標籤則用作分組標準;
- by:功能與without剛好相反,它僅使用by子句中指定的標籤進行聚合,結果向量中出現但未被by子句指定的標籤則會被忽略;
- 為了保留上下文資訊,使用by子句時需要顯式指定其結果中原本出現的job、instance等一類的標籤
事實上,各函數工作機制的不同之處也僅在於計算操作本身,PromQL對於它們的執行邏輯相似。
11個聚合函數
- sum( ):對樣本值求和;
- avg ( ) :對樣本值求平均值,這是進行指標資料分析的標準方法;
- count ( ) :對分組內的時間序列進行數量統計;
- stddev ( ) :對樣本值求標準差,以幫助使用者瞭解資料的波動大小(或稱之為波動程度);
- stdvar ( ) :對樣本值求方差,它是求取標準差過程中的中間狀態;
- min ( ) :求取樣本值中的最小者;
- max ( ) :求取樣本值中的最大者;
- topk ( ) :逆序返回分組內的樣本值最大的前k個時間序列及其值;
- bottomk ( ) :順序返回分組內的樣本值最小的前k個時間序列及其值;
- quantile ( ) :分位數用於評估資料的分佈狀態,該函數會返回分組內指定的分位數的值,即數值落在小於等於指定的分位區間的比例;
- count_values ( ) :對分組內的時間序列的樣本值進行數量統計;
二元運運算元
PromQL支援基本的算術運算和邏輯運算,這類運算支援使用操作符連線兩個運算元,因而也稱為二元運運算元或二元操作符;
支援的運算:
- 兩個標量間運算;
- 即時向量和標量間的運算:將運運算元應用於向量上的每個樣本;
- 兩個即時向量間的運算:遵循向量匹配機制;
將運運算元用於兩個即時向量間的運算時,可基於向量匹配模式(Vector Matching)定義其運算機制;
算術運算
支援的運運算元:+(加)、-(減)、*(乘)、/(除)、%(取模)和^(冪運算);
比較運算
支援的運運算元:==(等值比較)、!=(不等)、>、<、>=和<=(小於等於);
邏輯/集合運算
支援的運運算元:and(並且)、or(或者)和unless(除了);
目前,該運算僅允許在兩個即時向量間進行,尚不支援標量參與運算;
二元運運算元優先順序
- ^
- *, /, %
- +, -
- ==, !=, <=, <, >=, >
- and, unless
- or
- 具有相同優先順序的運運算元滿足結合律(左結合),但冪運算除外,因為它是右結合機制;
- 可以使用括號( )改變運算次序;
向量匹配
即時向量間的運算是PromQL的特色之一;運算時,PromQL為會左側向量中的每個元素找到匹配的元素,其匹配行為有兩種基本型別
- 一對一 (One-to-One)
- 一對多或多對一 (Many-to-One, One-to-Many)
向量一對一匹配
即時向量的一對一匹配
- 從運運算元的兩邊表示式所獲取的即時向量間依次比較,並找到唯一匹配(標籤完全一致)的樣本值;
- 找不到匹配項的值則不會出現在結果中;
匹配表示式語法:
<vector expr> <bin-op> ignoring(<label list>) <vector expr>
<vector expr> <bin-op> on(<label list>) <vector expr>
ignore:定義匹配檢測時要忽略的標籤;
on:定義匹配檢測時只使用的標籤;
舉例
有這樣一組資料:
method_code:http_errors:rate5m{method="get", code="500"} 24
method_code:http_errors:rate5m{method="get", code="404"} 30
method_code:http_errors:rate5m{method="put", code="501"} 3
method_code:http_errors:rate5m{method="post", code="500"} 6
method_code:http_errors:rate5m{method="post", code="404"} 21
method:http_requests:rate5m{method="get"} 600
method:http_requests:rate5m{method="del"} 34
method:http_requests:rate5m{method="post"} 120
運算表示式:
method_code:http_errors:rate5m{code="500"} / ignoring(code) method:http_requests:rate5m
如果不加 ignoring(code) 的話,左邊將無法匹配到右邊的結果,因為兩邊向量沒有完全一致的標籤,此時是這種情況:
#左邊
method_code:http_errors:rate5m{method="get", code="500"} 24
method_code:http_errors:rate5m{method="post", code="500"} 6
#右邊
method:http_requests:rate5m{method="get"} 600
method:http_requests:rate5m{method="del"} 34
method:http_requests:rate5m{method="post"} 120
只有將code標籤忽略,成為這種情況:
#左邊
method_code:http_errors:rate5m{method="get"} 24
method_code:http_errors:rate5m{method="post"} 6
#右邊
method:http_requests:rate5m{method="get"} 600
method:http_requests:rate5m{method="del"} 34
method:http_requests:rate5m{method="post"} 120
這時左邊和右邊就有一模一樣的標籤組合,所以完成了1對1匹配。
最終結果:
{method="get"} 0.04 // 24 / 600
{method="post"} 0.05 // 6 / 120
向量一對多/多對一匹配
- 「一」側的每個元素,可與「多」側的多個元素進行匹配;
- 必須使用group_left或group_right明確指定哪側為「多」側;
匹配表示式語法:
<vector expr> <bin-op> ignoring(<label list>) group_left(<label list>) <vector expr>
<vector expr> <bin-op> ignoring(<label list>) group_right(<label list>) <vector expr>
<vector expr> <bin-op> on(<label list>) group_left(<label list>) <vector expr>
<vector expr> <bin-op> on(<label list>) group_right(<label list>) <vector expr>
ignore:定義匹配檢測時要忽略的標籤;
on:定義匹配檢測時只使用的標籤;
舉例
還是這樣一組資料:
method_code:http_errors:rate5m{method="get", code="500"} 24
method_code:http_errors:rate5m{method="get", code="404"} 30
method_code:http_errors:rate5m{method="put", code="501"} 3
method_code:http_errors:rate5m{method="post", code="500"} 6
method_code:http_errors:rate5m{method="post", code="404"} 21
method:http_requests:rate5m{method="get"} 600
method:http_requests:rate5m{method="del"} 34
method:http_requests:rate5m{method="post"} 120
運算表示式:
method_code:http_errors:rate5m / ignoring(code) group_left method:http_requests:rate5m
此時的資料是這樣的:
#左邊:
method_code:http_errors:rate5m{method="get", code="500"} 24
method_code:http_errors:rate5m{method="get", code="404"} 30
method_code:http_errors:rate5m{method="put", code="501"} 3
method_code:http_errors:rate5m{method="post", code="500"} 6
method_code:http_errors:rate5m{method="post", code="404"} 21
#右邊
method:http_requests:rate5m{method="get"} 600
method:http_requests:rate5m{method="del"} 34
method:http_requests:rate5m{method="post"} 120
因為忽略的code標籤,最終結果:
{method="get", code="500"} 0.04 // 24 / 600
{method="get", code="404"} 0.05 // 30 / 600
{method="post", code="500"} 0.05 // 6 / 120
{method="post", code="404"} 0.175 // 21 / 120
至此,promQL聚合語句基本總結完畢,後續會prometheus的自動發現,以及relabel等常用功能進行演示,歡迎關注。