4.2 x64dbg 針對PE檔案的掃描
通過運用LyScript外掛並配合pefile模組,即可實現對特定PE檔案的掃描功能,例如載入PE程式到記憶體,驗證PE啟用的保護方式,計算PE節區記憶體特徵,檔案FOA與記憶體VA轉換等功能的實現,首先簡單介紹一下pefile模組。
pefile模組是一個用於解析Windows可執行檔案(PE檔案)的Python模組,它可以從PE檔案中提取出檔案頭、節表、匯入表、匯出表、資源表等資訊,也可以修改PE檔案的一些屬性。可以用於分析針對Windows平臺的惡意軟體、編寫自己的PE檔案修改工具等場景。
使用pefile模組可以快速方便地定位到PE檔案的一些關鍵資訊,例如程式入口點、程式頭、程式碼的開始和結束位置等,在基於PE檔案進行逆向分析和開發中非常有用。在Python中使用pefile模組也非常簡單,通過匯入模組和載入PE檔案後就可以輕鬆獲取和修改PE檔案的各種屬性了。
4.2.1 獲取PE結構記憶體節表
在讀者使用LyScript掃描程序PE結構之前,請讀者自行執行pip install pefile將pefile模組安裝到系統中,接著我們開始實現第一個功能,將PE可執行檔案中的記憶體資料通過PEfile模組開啟並讀入記憶體,實現PE引數解析。
此功能的核心實現原理,通過get_local_base()得到text節的基址,然後再通過get_base_from_address()函數得到text節得到程式的首地址,通過read_memory_byte依次讀入資料到記憶體中,最後使用pefile.PE解析為PE結構,其功能如下所示:
- 1.使用
MyDebug模組建立並初始化dbg物件,連線偵錯環境。 - 2.呼叫
dbg.get_local_base()獲取偵錯程式的基地址,將其賦值給local_base變數。 - 3.呼叫
dbg.get_base_from_address(local_base)將偵錯程式地址轉換為程式入口地址,將轉換後的地址賦值給base變數。 - 4.使用迴圈遍歷方式讀取偵錯程式首地址處的
4096位元組資料並儲存到byte_array位元組陣列中。 - 5.使用
pefile模組建立一個PE檔案物件oPE,並將byte_array作為資料來源傳入。 - 6.最後使用
dump_dict()方法從PE檔案物件中提取出可選頭資訊並列印輸出timedate變數。
具體的實現細節可以總結為如下程式碼形式;
from LyScript32 import MyDebug
import pefile
if __name__ == "__main__":
# 初始化
dbg = MyDebug()
dbg.connect()
# 得到text節基地址
local_base = dbg.get_local_base()
# 根據text節得到程式首地址
base = dbg.get_base_from_address(local_base)
byte_array = bytearray()
for index in range(0,4096):
read_byte = dbg.read_memory_byte(base + index)
byte_array.append(read_byte)
oPE = pefile.PE(data = byte_array)
timedate = oPE.OPTIONAL_HEADER.dump_dict()
print(timedate)
儲存並執行這段程式碼,讀者可以看到如下所示的輸出效果;

總體上,這段程式碼的作用是利用偵錯程式將偵錯程式的首地址處的4096位元組讀入記憶體,然後使用pefile模組將其解析為PE檔案,最後輸出PE檔案的可選頭資訊。該程式碼可以用於在偵錯過程中對偵錯程式的PE檔案進行逆向分析和研究。
接著我們繼續向下解析,通常讀者可通過oPE.sections獲取到當前程序的完整節資料,如下通過LyScirpt模組配合PEFile模組解析記憶體映象中的section節表屬性,其完整程式碼如下所示;
from LyScript32 import MyDebug
import pefile
if __name__ == "__main__":
# 初始化
dbg = MyDebug()
dbg.connect()
# 得到text節基地址
local_base = dbg.get_local_base()
# 根據text節得到程式首地址
base = dbg.get_base_from_address(local_base)
byte_array = bytearray()
for index in range(0,8192):
read_byte = dbg.read_memory_byte(base + index)
byte_array.append(read_byte)
oPE = pefile.PE(data = byte_array)
for section in oPE.sections:
print("%10s %10x %10x %10x"
%(section.Name.decode("utf-8"), section.VirtualAddress,
section.Misc_VirtualSize, section.SizeOfRawData))
dbg.close()
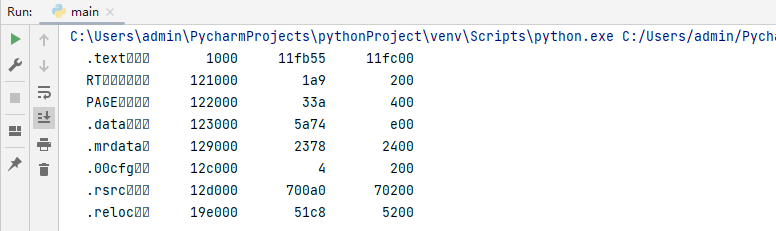
讀者可自行執行這段程式碼片段,則會看到當前被載入程序中記憶體節表的完整輸出,這段程式碼輸出效果如下圖所示;
4.2.2 計算節表記憶體Hash雜湊值
接著我們繼續再進一步,實現計算PE節表Hash雜湊值,Hash函數的計算常用於病毒木馬特徵值的標記,通過對特定檔案進行雜湊值生成,即可得知該檔案的版本,從而實現快速鎖定原始檔的目的。
什麼是Hash雜湊值
雜湊雜湊值通常被用作數位簽章、資料完整性驗證、訊息認證等等領域,它可以根據資料的內容計算出一個固定長度的值(通常是16到64位元組),並且在資料被篡改的情況下會生成不同的雜湊值,因此可以用來在不傳輸原資料的情況下驗證資料的完整性。
例如,我們可以使用MD5雜湊函數對一個檔案進行雜湊計算,得到一個128位元的雜湊雜湊值,將其與原始檔案共同儲存在另一個不同的地方。當我們需要驗證此檔案是否被篡改時,只需要重新對檔案進行雜湊計算,得到一個新的雜湊值,並將其與原來儲存的雜湊值進行比對,如果兩個值相同,就可以確定檔案未被篡改。
什麼是Hash雜湊函數
雜湊雜湊函數,也叫雜湊函數,是一種將任意長度的訊息對映到固定長度的雜湊值的函數。它通常是通過執行一系列演演算法將輸入資料轉換為一個固定大小的二進位制資料而實現的。
雜湊雜湊函數是密碼學中的重要工具之一,它具有不可逆性、單向性(難以從雜湊值反推源資料)、抗碰撞性(不同的源資料計算出來的雜湊值相等的概率很小)等特性,廣泛應用於資料加密、身份認證、數位簽章等領域。
常見的雜湊雜湊函數有MD5、SHA-1、SHA-2、SHA-3等,其中SHA-2是應用最廣泛的雜湊函數之一,在許多加密協定和安全標準中被廣泛使用。雖然雜湊函數具有不可逆性,但是由於計算能力的不斷提高,一些強大的計算能力可以被用來破解雜湊函數,因此選擇合適的雜湊函數也非常重要。
我們以MD5以及CRC32為例,如果讀者需要計算程式中每個節的雜湊值,則需通過dbg.get_section()函數動態獲取到所有程式中的節,並取出addr,name,size三個欄位,通過封裝的md5()以及crc32等函數完成計算並輸出,這段程式碼的核心實現流程如下所示;
import binascii
import hashlib
from LyScript32 import MyDebug
def crc32(data):
return "0x{:X}".format(binascii.crc32(data) & 0xffffffff)
def md5(data):
md5 = hashlib.md5(data)
return md5.hexdigest()
if __name__ == "__main__":
dbg = MyDebug()
dbg.connect()
# 迴圈節
section = dbg.get_section()
for index in section:
# 定義位元組陣列
mem_byte = bytearray()
address = index.get("addr")
section_name = index.get("name")
section_size = index.get("size")
# 讀出節內的所有資料
for item in range(0,int(section_size)):
mem_byte.append( dbg.read_memory_byte(address + item))
# 開始計算特徵碼
md5_sum = md5(mem_byte)
crc32_sum = crc32(mem_byte)
print("[*] 節名: {:10s} | 節長度: {:10d} | MD5特徵: {} | CRC32特徵: {}"
.format(section_name,section_size,md5_sum,crc32_sum))
dbg.close()
執行後等待片刻,讀者應該可以看到如下圖所示的輸出結果,圖中每一個節的雜湊值都被計算出來;

4.2.3 驗證PE啟用的保護模式
PE檔案的保護模式包括了、隨機基址(Address space layout randomization,ASLR)、資料不可執行(Data Execution Prevention,DEP)、強制完整性(Forced Integrity,FCI)這四種安全保護機制,它們的主要作用是防止惡意軟體攻擊,並提高系統的安全性和可靠性。
1.隨機基址(Address space layout randomization,ASLR)
隨機基址是一種Windows作業系統中的記憶體防護機制,它可以使惡意軟體難以通過記憶體地址預測來攻擊應用程式。在隨機基址機制下,作業系統會隨機改變應用程式的地址空間佈局,使得每次執行時程式在記憶體中載入的地址不同,從而防止攻擊者憑藉對程式記憶體地址的猜測或破解來攻擊程式。
隨機基址的驗證方式是定位到PE結構的pe.OPTIONAL_HEADER.DllCharacteristics並對PE檔案的OPTIONAL_HEADER中的DllCharacteristics屬性進行取值位運算操作並以此作為判斷的依據:
- 首先,使用
hex()將pe.OPTIONAL_HEADER.DllCharacteristics轉換為16進位制字串。 - 然後,將該16進位制字串和
0x40進行按位元與運算。 - 最後,將得到的結果與
0x40進行比較。
根據微軟的檔案,pe.OPTIONAL_HEADER.DllCharacteristics是一個32位元的掩碼屬性,用於描述PE檔案的一些特性。其中DllCharacteristics的第7位(從0開始)表示該檔案是否啟用了ASLR(Address Space Layout Randomization)特性,如果啟用,則對應值為0x40。因此,上述程式碼的作用是判斷該PE檔案是否啟用了ASLR特性。如果結果為真,則說明該檔案啟用了ASLR;否則,說明該檔案未啟用ASLR。
資料不可執行(Data Execution Prevention,DEP)
資料不可執行是一種Windows作業系統中的記憶體防護機制,它可以防止惡意軟體針對系統記憶體中的資料進行攻擊。在DEP機制下,作業系統會將記憶體分為可執行和不可執行兩部分,其中不可執行部分主要用於存放程式資料,而可執行部分用於存放程式碼。這樣當程式試圖執行不可執行的資料時,作業系統會立即終止程式,從而防止攻擊者通過操縱程式資料來攻擊系統。
同樣使用位運運算元&,對PE檔案的OPTIONAL_HEADER中的DllCharacteristics屬性進行了取值並進行了位運算操作。該程式碼的具體意義為:
- 首先,使用hex()將
pe.OPTIONAL_HEADER.DllCharacteristics轉換為16進位制字串。 - 然後,將該16進位制字串和
0x100進行按位元與運算。 - 最後,將得到的結果與
0x100進行比較。
根據微軟的檔案,pe.OPTIONAL_HEADER.DllCharacteristics是一個32位元的掩碼屬性,用於描述PE檔案的一些特性。其中,DllCharacteristics的第8位元(從0開始)表示該檔案是否啟用了NX特性(No eXecute),如果啟用,則對應值為0x100。NX特性是一種記憶體保護機制,可以防止惡意程式碼通過將資料區域當作程式碼區域來執行程式碼,提高了系統的安全性。因此,上述程式碼的作用是判斷該PE檔案是否啟用了NX特性。如果結果為真,則說明該檔案啟用了NX特性;否則,說明該檔案未啟用NX特性。
強制完整性(Forced Integrity,FCI)
強制完整性是一種Windows作業系統中的強制措施,它可以防止惡意軟體通過DLL注入來攻擊系統。在FCI機制下,作業系統會通過數位簽章和其他校驗措施對系統DLL和其他關鍵檔案進行驗證,確保這些檔案沒有被修改或替換。如果檢測到檔案已被修改或替換,作業系統將會拒絕這些檔案並終止相關程序,這樣可以保護系統的完整性和安全性。
同樣使用位運運算元&,對PE檔案的OPTIONAL_HEADER中的DllCharacteristics屬性進行了取值並進行了位運算操作。該程式碼的具體意義為:
- 首先,使用hex()將
pe.OPTIONAL_HEADER.DllCharacteristics轉換為16進位制字串。 - 然後,將該16進位制字串和0x80進行按位元與運算。
- 最後,將得到的結果與0x80進行比較。
根據微軟的檔案,pe.OPTIONAL_HEADER.DllCharacteristics是一個32位元的掩碼屬性,用於描述PE檔案的一些特性。其中,DllCharacteristics的第7位(從0開始)表示該檔案是否啟用了動態基址特性(Dynamic Base),如果啟用,則對應值為0x40。動態基址特性與ASLR(Address Space Layout Randomization)功能是緊密相關的,當啟用ASLR時,動態基址特性也會被自動啟用。因此,上述程式碼的作用是判斷該PE檔案是否啟用了動態基址特性。如果結果為真,則說明該檔案啟用了動態基址特性;否則,說明該檔案未啟用動態基址特性。
根據如上描述,要想實現檢查程序內所有模組的保護方式,則首先要通過dbg.get_all_module()獲取到程序的所有模組資訊,當模組資訊被讀入後,通過dbg.read_memory_byte()獲取到該記憶體的機器碼,並通過pefile.PE(data=byte_array)裝載到記憶體,通過對不同數值與與運算即可判定是否開啟了保護。
- 隨機基址 hex(pe.OPTIONAL_HEADER.DllCharacteristics) & 0x40 == 0x40
- 資料不可執行 hex(pe.OPTIONAL_HEADER.DllCharacteristics) & 0x100 == 0x100
- 強制完整性 hex(pe.OPTIONAL_HEADER.DllCharacteristics) & 0x80 == 0x80
那麼根據如上描述,這段核心程式碼可以總結為如下案例;
from LyScript32 import MyDebug
import pefile
if __name__ == "__main__":
# 初始化
dbg = MyDebug()
dbg.connect()
# 得到所有載入過的模組
module_list = dbg.get_all_module()
print("-" * 100)
print("模組名 \t\t\t 基址隨機化 \t\t DEP保護 \t\t 強制完整性 \t\t SEH異常保護 \t\t")
print("-" * 100)
for module_index in module_list:
print("{:15}\t\t".format(module_index.get("name")),end="")
# 依次讀入程式所載入的模組
byte_array = bytearray()
for index in range(0, 4096):
read_byte = dbg.read_memory_byte(module_index.get("base") + index)
byte_array.append(read_byte)
oPE = pefile.PE(data=byte_array)
# 隨機基址 => hex(pe.OPTIONAL_HEADER.DllCharacteristics) & 0x40 == 0x40
if ((oPE.OPTIONAL_HEADER.DllCharacteristics & 64) == 64):
print("True\t\t\t",end="")
else:
print("False\t\t\t",end="")
# 資料不可執行 DEP => hex(pe.OPTIONAL_HEADER.DllCharacteristics) & 0x100 == 0x100
if ((oPE.OPTIONAL_HEADER.DllCharacteristics & 256) == 256):
print("True\t\t\t",end="")
else:
print("False\t\t\t",end="")
# 強制完整性=> hex(pe.OPTIONAL_HEADER.DllCharacteristics) & 0x80 == 0x80
if ((oPE.OPTIONAL_HEADER.DllCharacteristics & 128) == 128):
print("True\t\t\t",end="")
else:
print("False\t\t\t",end="")
if ((oPE.OPTIONAL_HEADER.DllCharacteristics & 1024) == 1024):
print("True\t\t\t",end="")
else:
print("False\t\t\t",end="")
print()
dbg.close()
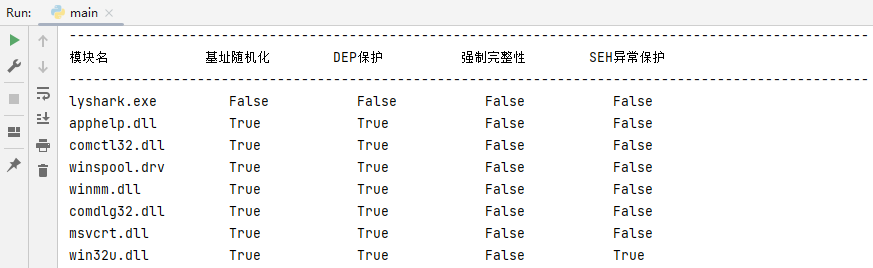
讀者可以執行這段案例,即可看到如下圖所示的輸出效果;
4.2.4 PE結構的FOA/VA/RAV轉換
在PE檔案結構中,VA、RVA和FOA都是用來描述記憶體中資料的位置和在檔案中的偏移量,具體含義如下:
- VA(Virtual Address):虛擬地址,也叫映像地址,是指在記憶體中的地址。VA通常是程式執行時要存取的地址,由作業系統進行地址轉換對映到實體地址上。
- RVA(Relative Virtual Address):相對虛擬地址,是指當前位置相對於所在塞段的起始地址的偏移量。RVA通常是用於描述PE檔案中的各個段的相對位置,它不像VA一樣是用於真正執行程式的,而是在載入 PE 檔案時進行重定位所使用的。
- FOA(File Offset Address):檔案偏移量,是指在檔案中的偏移量,也就是從檔案起始位置到資料的偏移量。FOA通常是用於描述PE檔案中的各個段和頭資訊在檔案中的位置,可以用來定位和修改檔案中的資料。
需要注意的是,這三種地址是不同的,其值也不同。VA和RVA通常是在Windows作業系統中使用;FOA通常是在PE檔案處理時使用。在PE檔案載入時,Windows作業系統會將RVA轉換為VA,將程式的段載入到記憶體中,並根據需要對其進行重定位(如果程式碼中包含有絕對地址的話),然後將控制權交給程式的入口點,程式進入執行狀態。
首先實現VA轉為FOA的案例,在這段核心程式碼中,通過dbg.get_base_from_address(dbg.get_local_base())獲取到記憶體中的程式基地址,並與VA地址相減得到記憶體中的RVA地址,並呼叫PEfile庫中的get_offset_from_rva完成轉換。
def get_offset_from_va(pe_ptr, va_address):
# 得到記憶體中的程式基地址
memory_image_base = dbg.get_base_from_address(dbg.get_local_base())
# 與VA地址相減得到記憶體中的RVA地址
memory_local_rva = va_address - memory_image_base
# 根據RVA得到檔案內的FOA偏移地址
foa = pe_ptr.get_offset_from_rva(memory_local_rva)
return foa
其次是將FOA檔案偏移轉為VA虛擬地址,此類程式碼與上方程式碼基本一致,通過pe_ptr.get_rva_from_offset先得到RVA相對偏移,然後在通過dbg.get_base_from_address(dbg.get_local_base())得到記憶體中程式基地址,然後計算VA地址,最後直接計算得到VA地址。
def get_va_from_foa(pe_ptr, foa_address):
# 先得到RVA相對偏移
rva = pe_ptr.get_rva_from_offset(foa_address)
# 得到記憶體中程式基地址,然後計算VA地址
memory_image_base = dbg.get_base_from_address(dbg.get_local_base())
va = memory_image_base + rva
return va
最後一種則是將FOA檔案偏移地址轉為RVA相對地址,此類程式碼中通過列舉所有節中的引數,並以此動態計算出實際的RVA地址返回。
# 傳入一個FOA檔案地址轉為RVA地址
def get_rva_from_foa(pe_ptr, foa_address):
sections = [s for s in pe_ptr.sections if s.contains_offset(foa_address)]
if sections:
section = sections[0]
return (foa_address - section.PointerToRawData) + section.VirtualAddress
else:
return 0
最終將三段程式碼整合在一起,即可構成一個互相轉換的案例,至於PE結構的解析問題,詳細度過PE結構篇的你不需要我做太多的解釋了。
from LyScript32 import MyDebug
import pefile
# 傳入一個VA值獲取到FOA檔案地址
def get_offset_from_va(pe_ptr, va_address):
# 得到記憶體中的程式基地址
memory_image_base = dbg.get_base_from_address(dbg.get_local_base())
# 與VA地址相減得到記憶體中的RVA地址
memory_local_rva = va_address - memory_image_base
# 根據RVA得到檔案內的FOA偏移地址
foa = pe_ptr.get_offset_from_rva(memory_local_rva)
return foa
# 傳入一個FOA檔案地址得到VA虛擬地址
def get_va_from_foa(pe_ptr, foa_address):
# 先得到RVA相對偏移
rva = pe_ptr.get_rva_from_offset(foa_address)
# 得到記憶體中程式基地址,然後計算VA地址
memory_image_base = dbg.get_base_from_address(dbg.get_local_base())
va = memory_image_base + rva
return va
# 傳入一個FOA檔案地址轉為RVA地址
def get_rva_from_foa(pe_ptr, foa_address):
sections = [s for s in pe_ptr.sections if s.contains_offset(foa_address)]
if sections:
section = sections[0]
return (foa_address - section.PointerToRawData) + section.VirtualAddress
else:
return 0
if __name__ == "__main__":
dbg = MyDebug()
dbg.connect()
# 載入檔案PE
pe = pefile.PE(name=dbg.get_local_module_path())
# 讀取檔案中的地址
rva = pe.OPTIONAL_HEADER.AddressOfEntryPoint
va = pe.OPTIONAL_HEADER.ImageBase + pe.OPTIONAL_HEADER.AddressOfEntryPoint
foa = pe.get_offset_from_rva(pe.OPTIONAL_HEADER.AddressOfEntryPoint)
print("檔案VA地址: {} 檔案FOA地址: {} 從檔案獲取RVA地址: {}".format(hex(va), foa, hex(rva)))
# 將VA虛擬地址轉為FOA檔案偏移
eip = dbg.get_register("eip")
foa = get_offset_from_va(pe, eip)
print("虛擬地址: 0x{:x} 對應檔案偏移: {}".format(eip, foa))
# 將FOA檔案偏移轉為VA虛擬地址
va = get_va_from_foa(pe, foa)
print("檔案地址: {} 對應虛擬地址: 0x{:x}".format(foa, va))
# 將FOA檔案偏移地址轉為RVA相對地址
rva = get_rva_from_foa(pe, foa)
print("檔案地址: {} 對應的RVA相對地址: 0x{:x}".format(foa, rva))
dbg.close()
如上程式碼中所傳遞地址必須保證是正確的,否則會報錯,讀者應根據自己的需求選擇對應的函數來執行,程式碼執行後輸出效果如下圖所示;

4.2.5 PE結構檢索SafeSEH記憶體地址
SafeSEH(Safe Structured Exception Handling)是Windows作業系統提供的一種安全保護機制,用於防止惡意軟體利用緩衝區溢位漏洞來攻擊應用程式。
當應用程式使用結構化例外處理機制(SEH)時,其例外處理連結串列(ExceptionHandler連結串列)可以被攻擊者用來執行程式碼注入攻擊。這是由於例外處理連結串列本質上是一個指標陣列,如果應用程式使用了未經驗證的指標指向例外處理函數,則攻擊者可以構造惡意的例外處理模組來覆蓋原有的處理程式,從而迫使程式執行攻擊者注入的程式碼。這種攻擊技術被稱為SEH注入(SEH Overwrite)。
為了解決這個問題,SafeSEH機制被引入到Windows作業系統中。其主要思想是在應用程式的匯入表中加入了一個SafeSEH表,用於儲存由編譯器生成的SEH處理常式的地址列表。在程式執行時,Windows作業系統將檢查程式SEH連結串列中的指標是否存在SafeSEH表中。如果該指標不存在於SafeSEH表中,則Windows作業系統將終止應用程式的執行。SafeSEH機制可以提高系統的安全性和可靠性,防止惡意軟體利用緩衝區溢位和SEH注入等漏洞來攻擊應用程式。
SafeSEH的檢索問題,讀者可依據如下步驟依次實現;
- 1.初始化偵錯程式dbg,並執行dbg.connect()連線到正在執行的程序。
- 2.memory_image_base = dbg.get_base_from_address(dbg.get_local_base()):獲取程式記憶體映象的基地址。
- 3.peoffset = dbg.read_memory_dword(memory_image_base + int(0x3c)):通過PE頭的偏移地址得到PE頭的基地址。
- 4.flags = dbg.read_memory_word(pebase + int(0x5e)):讀取PE頭中的DllCharacteristics屬性的值,使用了read_memory_word函數,該值用於判斷是否開啟了SafeSEH保護。
- 5.如果flags值的第10位(即0x400)為1,則說明該程式已開啟了SafeSEH保護,並輸出保護狀態為「NoHandler」;否則不列印狀態資訊。
- 6.numberofentries = dbg.read_memory_dword(pebase + int(0x74)):讀取PE頭中的NumberOfRvaAndSizes屬性的值,該值用來描述資料目錄表中的專案個數。
- 7.如果numberofentries值大於10,則說明該PE檔案結構異常,退出程式。
- 8.sectionaddress和sectionsize用於指定程式頭表中第10個PE節的地址和大小。如果第10個節大小不為0且為0x40或與第一個DWORD和第二個DWORD的值相等,則說明該程式在節表中找到了SafeSEH記錄。
- 9.sehlistaddress和sehlistsize指定
SafeSEH記錄列表的地址和大小。如果sehlistaddress不為0且sehlistsize不為0,則說明該程式啟用了SafeSEH保護,並輸出保護狀態。 - 10.如果condition等於False,則說明PE結構不符合要求或未啟用SafeSEH保護。如果data小於0x48,則說明該DLL或EXE程式無法被識別。如果sehlistaddress和sehlistsize不同時等於零,則列印SafeSEH保護中的長度。
查詢SafeSEH記憶體地址,讀入PE檔案到記憶體,驗證該程式的SEH保護是否開啟,如果開啟則嘗試輸出SEH記憶體地址,其實現程式碼可總結為如下案例;
from LyScript32 import MyDebug
import struct
LOG_HANDLERS = True
if __name__ == "__main__":
dbg = MyDebug()
dbg.connect()
# 得到PE頭部基地址
memory_image_base = dbg.get_base_from_address(dbg.get_local_base())
peoffset = dbg.read_memory_dword(memory_image_base + int(0x3c))
pebase = memory_image_base + peoffset
flags = dbg.read_memory_word(pebase + int(0x5e))
if(flags & int(0x400)) != 0:
print("SafeSEH | NoHandler")
numberofentries = dbg.read_memory_dword(pebase + int(0x74))
if numberofentries > 10:
# 讀取 pebase+int(0x78)+8*10 | pebase+int(0x78)+8*10+4 讀取八位元組,分成兩部分讀取
sectionaddress, sectionsize = [dbg.read_memory_dword(pebase+int(0x78)+8*10),
dbg.read_memory_dword(pebase+int(0x78)+8*10 + 4)
]
sectionaddress += memory_image_base
data = dbg.read_memory_dword(sectionaddress)
condition = (sectionsize != 0) and ((sectionsize == int(0x40)) or (sectionsize == data))
if condition == False:
print("[-] SafeSEH 無保護")
if data < int(0x48):
print("[-] 無法識別的DLL/EXE程式")
sehlistaddress, sehlistsize = [dbg.read_memory_dword(sectionaddress+int(0x40)),
dbg.read_memory_dword(sectionaddress+int(0x40) + 4)
]
if sehlistaddress != 0 and sehlistsize != 0:
print("[+] SafeSEH 保護中 | 長度: {}".format(sehlistsize))
if LOG_HANDLERS == True:
for i in range(sehlistsize):
sehaddress = dbg.read_memory_dword(sehlistaddress + 4 * i)
sehaddress += memory_image_base
print("SEHAddress = {}".format(hex(sehaddress)))
dbg.close()
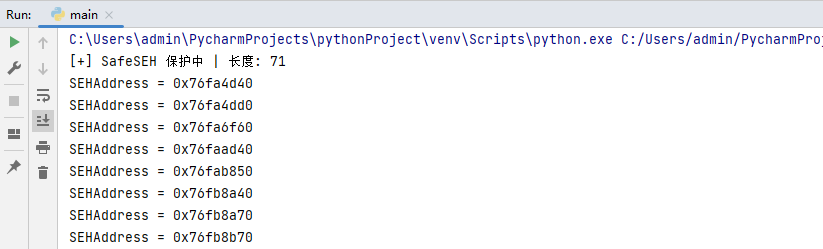
執行這段程式碼,則可輸出當前程序內所有啟用SafeSEH的記憶體地址空間,如下圖所示;
原文地址
文章出處:https://www.cnblogs.com/LyShark/p/17533827.html
本部落格所有文章除特別宣告外,均採用 BY-NC-SA 許可協定。轉載請註明出處!