Multi-Modal Attention Network Learning for Semantic Source Code Retrieval 解讀
Multi-Modal Attention Network Learning for Semantic Source Code Retrieva
Multi-Modal Attention Network Learning for Semantic Source Code Retrieval,題目意思是用於語意原始碼檢索的多模態注意網路學習,2019年發表於ASE的
## 研究什麼東西Background:
研究程式碼檢索技術,對於一個程式碼儲存庫進行方法級別的搜尋,給定一個描述程式碼片段功能的短文,從程式碼儲存庫中檢索特定的程式碼片段。

論文挑戰和貢獻

前人的做法
Gu等人[6]是第一個將深度學習網路應用於程式碼檢索任務的人,它在中間語意空間中捕捉語意原始碼與自然語言查詢之間的相關性。然而,這種方法仍然受到兩個主要限制:(a)原始碼的深層結構特徵經常被忽視。方法[6]捕獲了淺層原始碼資訊,包括方法名、程式碼標記和API序列,從而錯過了捕獲程式碼的豐富結構語意的機會。
本文
本文提出了一種新的用於語意原始碼檢索的多模注意力網路MMAN。開發了一種用於表示原始碼的非結構化和結構化特徵的綜合多模態表示,其中一個LSTM用於程式碼的順序標記,一個樹LSTM用於編碼的AST,一個GGNN(門控圖神經網路)用於編碼的CFG。此外,應用多模態注意力融合層為原始碼的每個模態的不同部分分配權重,然後將它們整合到單個混合表示中。在大規模真實世界資料集上的綜合實驗和分析表明,本文提出的模型可以準確地檢索程式碼片段,並且優於最先進的方法。
如何破局
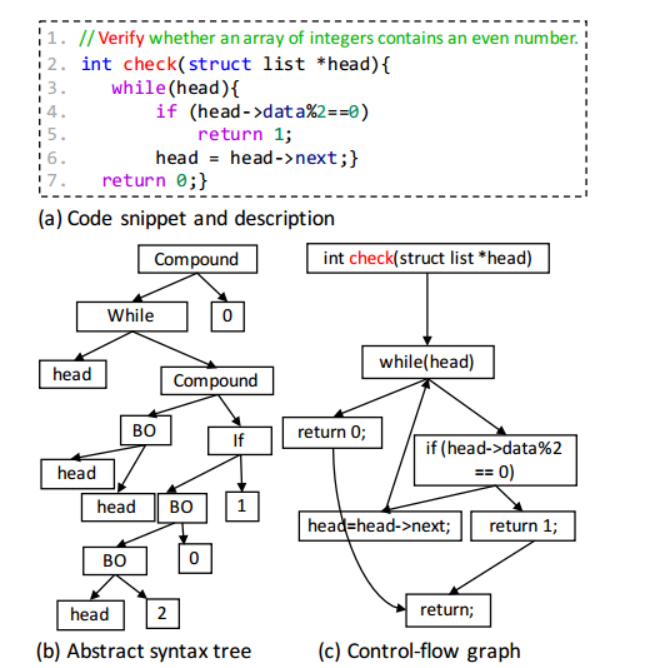
上述這些限制促使本文設計一個模型,該模型學習更全面的原始碼錶示,並具有可解釋性。一方面,對於限制(a),除了程式碼的標記外,本文還從程式碼的多個檢視中提取了更多的程式碼特徵,如抽象語法樹(AST)和控制流圖(CFG)1
因此,每個模態對最終程式碼錶示的貢獻可能不相等。對於給定的模態,它由許多元素(標記、AST/CFG中的節點)組成,通過表示學習將權重分配給不同的元素。
在本文中,本文設計了一種注意力機制,將多模態特徵整合到單個混合程式碼錶示中。
純文字(用於檢查),鍵入augmented AST(用於BinaryOperator)和CFG(用於while)。
這些表示關注不同檢視中程式碼的不同結構資訊,例如,AST上的每個節點表示一個令牌,CFG上的每個結點表示一個語句。這表明了考慮各種模式以更好地表示原始碼的必要性
有必要從多個檢視角度表示程式碼,特別是從結構化資訊表示程式碼,因為根據不同的程式碼錶示,兩個檢視上的令牌和語句的順序可能不同。例如,基於純文字,圖1(a)中「while」後面的標記是「()」,然後是「head」。不同的是,在AST上,「Compound」之後將有兩個可能的令牌,即分支測試「if」、「BinaryOperator」,如圖1(b)所示。類似地,在第6行最後一條語句中的標記「g」之後,將不會留下基於純文字的標記。然而,基於CFG,下一個標記是基於CFG的迴圈函數開頭的「while」。
不同的表示有不同的理解
為了解決上述兩個問題,本文提出了一種新的語意原始碼檢索模型,稱為多模注意力網路(MMAN)。本文不僅考慮了先前工作中研究的序列特徵(即方法名稱和標記),還考慮了結構特徵(即從程式碼中提取的AST和CFG)。
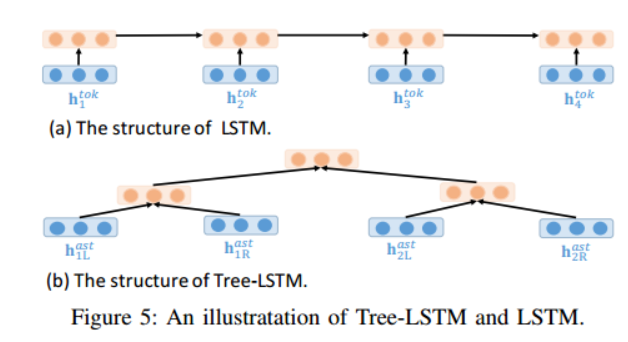
本文探索了一種新的多模態神經網路來同時有效地捕捉這些多模態特徵。特別地,我們使用LSTM[10]來表示程式碼片段的順序標記, 使用Tree LSTM[11]網路來表示抽象語法樹(AST),使用門控圖神經網路(GGNN)[12]來表示CFG。
為了克服可解釋性問題,本文設計了一種注意力機制,為原始碼的每個模態的不同部分分配不同的權重,並具有解釋能力。總之,本文的主要貢獻如下
本文提出了一種更全面的原始碼多模態表示方法,其中一個LSTM用於原始碼的順序內容,一個Tree LSTM用於原始碼的AST,一個GGNN用於原始碼中的CFG。此外,還應用了多模態融合層來整合這三種表示。
基本概念
設本文有一組 D,由 N 個程式碼片段組成,並具有相應的描述
每個程式碼片段和描述都可以看作是一系列標記
對於每個程式碼片段組成一個X組合,如下

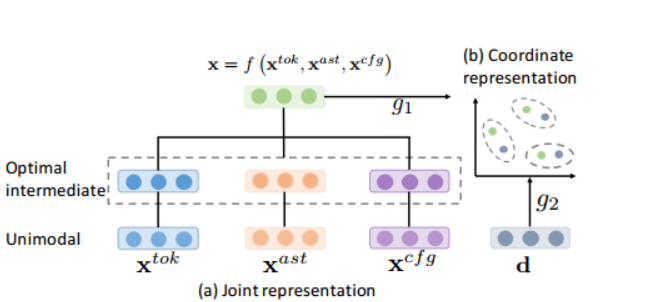
聯合學習和協調學習是多模態表示學習中的兩種策略,用於將不同模態(例如影象、文字、音訊等)的訊號融合或處理,以獲得一個共用的表示空間。
- 聯合學習(Joint Learning):聯合學習的目標是將不同模態的訊號組合到同一表示空間中。在聯合學習中,不同模態的特徵被同時傳入模型,並共同學習一個綜合的多模態表示。通過聯合學習,模型可以同時考慮不同模態之間的關聯性和互補性,從而更好地捕捉多模態資料的整體特徵。
例如,考慮一個影象和文字的聯合學習任務,本文希望將影象和文字的資訊融合到一個共用的表示空間中。可以使用深度神經網路模型,將影象輸入一個折積神經網路(CNN)進行影象特徵提取,將文字輸入一個迴圈神經網路(RNN)進行文字特徵提取,然後將它們的特徵向量連線或求平均,最終得到一個聯合的多模態表示
- 協調學習(Coordinated Learning):協調學習的目標是單獨處理每個模態的訊號,但對它們施加某些相似性約束,將它們對映到一箇中間的語意空間。在協調學習中,每個模態的特徵經過單獨的處理,然後通過某種方式約束它們的表示,使它們在語意上保持一致。
以影象和文字為例,協調學習可以通過一個共用的中間語意空間來實現。首先,使用一個影象編碼器將影象轉換為影象特徵向量,使用一個文字編碼器將文字轉換為文字特徵向量。然後,使用一個協調機制(例如,對抗性訓練、距離度量等),通過最小化影象和文字特徵之間的差異,將它們約束到一個共用的中間語意空間中。這樣,影象和文字的表示可以在中間語意空間中更好地對齊,使得它們在語意上更加一致。
總的來說,聯合學習將不同模態的訊號組合到同一表示空間中,而協調學習單獨處理每個模態的訊號,並約束它們在一箇中間語意空間中保持一致。這兩種策略都旨在實現多模態資料的有效融合和表示學習,以便更好地理解和處理多模態資訊。
下面的先把單峰的 token ast cfg算好
然後再融合成一個向量,最後再傳入到一個函數(深度學習網路)中獲得x
下面的這個d是要搜尋的關鍵字描述,和座標系進行匹配,將其投影到具有相似性約束/協調的中間語意空間中。這種協調的範例包括最小化餘弦距離或最大化相關性。本文采用餘弦相似度函數
工作流程
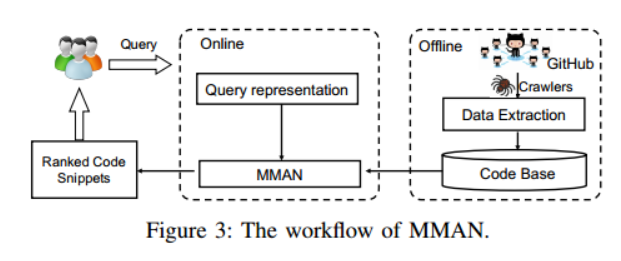
圖3展示瞭如何獲得經過訓練的模型的整體工作流程,其中包括離線訓練階段和線上檢索階段。在訓練階段,本文準備了一個大規模的帶註釋的<code,description>對的語料庫。然後將帶註釋的對輸入到本文提出的 MMAN 模型中進行訓練。
經過訓練,本文可以得到一個經過訓練的檢索網路。然後,給定自然語言查詢,經過訓練的網路可以檢索相關的原始碼片段。
具體各個元件如下
圖 4 是本文提出的 MMAN 模型的網路架構的概述。本文將框架分為三個子模組。 (a) 多模式程式碼錶示(參見
秒。 IV-B)。該模組用於將原始碼錶示到隱藏空間中。 (b) 多模態注意力融合(參見第 2 節)
IV-C)。該注意模組旨在為每種模態的不同部分分配不同的權重,然後將注意向量融合為單個向量。 (c) 模型學習(參見第 2 節)
我有)。該注意力模組旨在通過排名損失函數學習公共空間中的評論描述表示和程式碼錶示。本文將在以下部分詳細闡述該框架中的每個元件
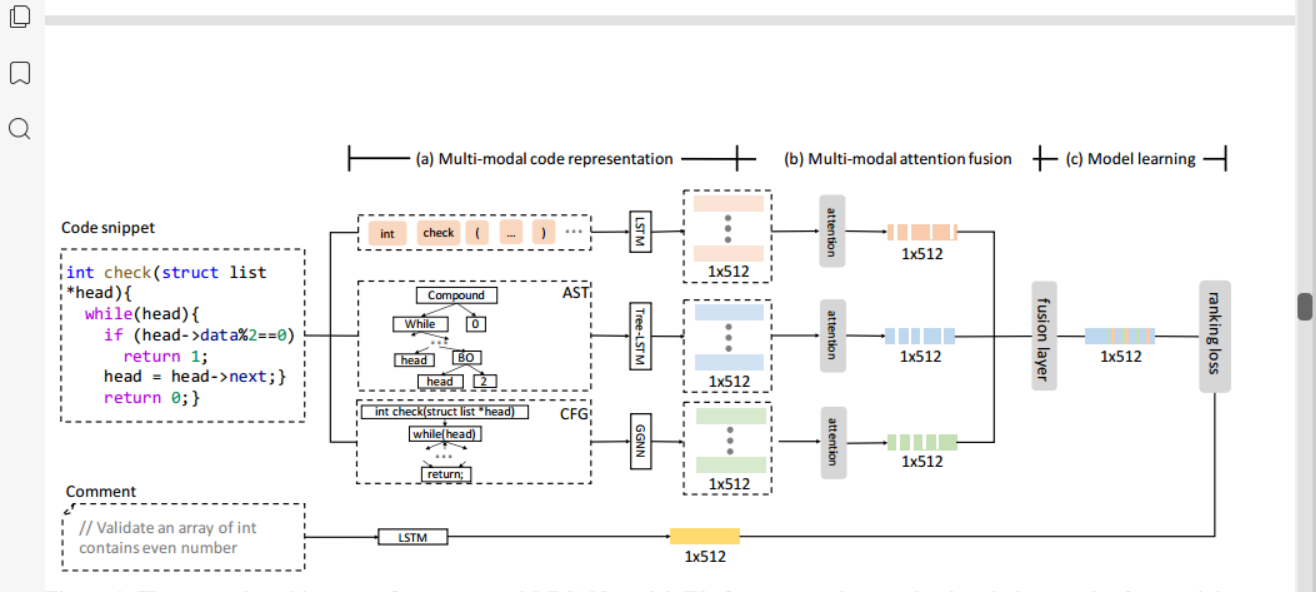
與以前僅利用順序標記來表示程式碼的方法不同,本文還考慮了原始碼的結構資訊,在本節中,本文提出了一種用於程式碼錶示的混合嵌入方法。本文使用 LSTM 來表示程式碼的 token,使用 Tree-LSTM 來表示程式碼的 AST,使用 GGNN 來表示程式碼的 CFG。
Tree-LSTM 自下而上遞迴地計算 N 的嵌入。假設左子節點和右子節點分別保持 LSTM 狀態 (hL; cL) 和 (hR; cR)。然後 N 的 LSTM 狀態 (h; c) 計算為
Tree-LSTM 和LSTM的遞推公式不一樣
cfg用one hot去編碼了
然後用三個資料用對應的網路或者模型訓練一次後,還需要用注意力機制,注意力機制每個權重是不一樣的,每個資料模型都有各自的權值
這一部分看論文的公式

最後再
多模態融合。然後,本文通過相應的注意力分數將多模態表示整合為單個表示。本文首先將它們連線起來,然後將它們輸入到單層線性網路中,該網路可以公式化如下

串聯了三個
然後關於描述,剛開始描述是從程式碼裡面拿進去訓練的,後面描述就是一個輸入
用LSTM生成了一個向量
如下圖

w是一個詞向量
最後的一個輸出h (des)就是輸入描述的向量了
如果程式碼片段和描述具有相似的語意,那麼它們的嵌入向量應該彼此接近。換句話說,給定任意程式碼片段 x 和任意描述 d,如果 d 是 x 的正確描述,本文希望它預測高相似性,否則預測低相似性
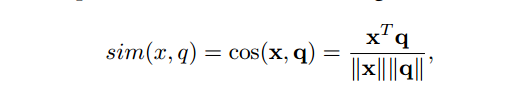
最後判斷相似度
其中 x 和 q 分別是程式碼和查詢的向量。
相似度越高,程式碼與給定查詢的相關性越強。
RQ1。與一些最先進的方法相比,本文提出的方法是否提高了程式碼檢索的效能?
• RQ2。原始碼的每種模式(例如原始碼的順序標記、AST、CFG)對最終檢索效能的有效性和貢獻是什麼,它們的組合又如何?
• RQ3。當改變程式碼長度、程式碼長度、程式碼 AST 節點數量、程式碼 CFG 節點數量和註釋長度時,本文提出的模型的效能如何?
• RQ4。本文提出的注意力機制的效能如何?注意力視覺化的可解釋性是什麼?
提取資料
難點
方法名很短的,就20行,提取的資訊,不多
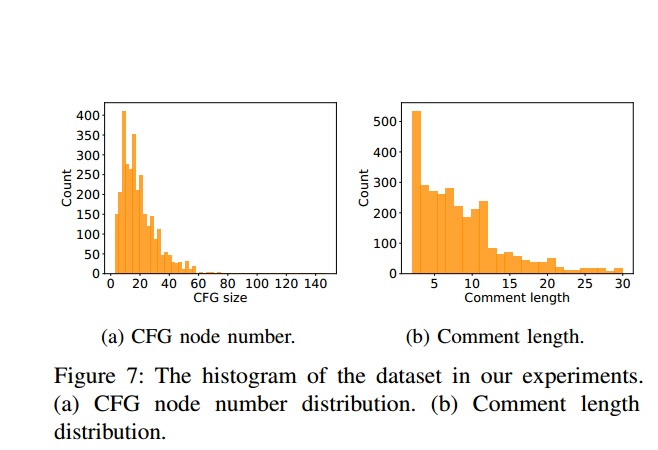
圖 7 顯示了測試資料上程式碼和註釋的長度分佈。從圖 7a 中,本文可以發現大多數程式碼片段的長度都在 20 到 40 之間。[52] 中的參照「函數幾乎不應該是 20 行長」也觀察到了這一點。從圖 7b 中,本文可以注意到幾乎所有評論的長度都小於 10。
這也證實了捕獲短文字與其相應程式碼片段之間的相關性的挑戰。
最後收集記得資料如下
<method name, tokens, AST, CFG, description>
關於每個元素的提取
方法名 對於每個 C 方法,本文提取其名稱,並根據駝峰大小寫將名稱解析為標記序列,如果它包含 _,則通過 _ 對其進行標記化。
真正程式碼 Token Extraction. To collect tokens from a C method, we
tokenize the code by f. , " ; ) ( ! (space)g. After
we tokenize function body, function name, we limit their max
length as 100 and 50 respectively.
先分割,然後統計token ,然後總共長度限制住 函數體 函數名 100 50
對於AST樹 作者也做了限制
具體怎麼限制的如下gpt4說的
I'll explain the method with an example, using a simple C code snippet and the corresponding AST. Let's consider the following C code:
c
Copy
int main() {
int a = 3;
int b = 4;
int c = a + b;
return c;
}
Here's a representation of the AST tree with the non-terminal nodes labeled:
Copy
1. FUNCTION_DEF
├── 2. DECL
└── 3. COMPOUND_STMT
├── 4. DECL
├── 5. DECL
├── 6. DECL
│ └── 7. BINARY_OP
│ ├── 8. REFERENCE
│ └── 9. REFERENCE
└──10. RETURN_STMT
└──11. REFERENCE
Now we will apply the two-step transformation mentioned in the paper to convert this AST to a binary tree:
Step 1 (Split nodes with more than 2 children):
We will traverse the tree in a top-down manner and split the nodes with more than 2 children. In our example, node 3 (COMPOUND_STMT) has 4 children.
After splitting node 3, we get the following binary tree:
Copy
1. FUNCTION_DEF
├── 2. DECL
└── 3. COMPOUND_STMT
├── 4. DECL
└──12. NEW_NODE
├── 5. DECL
└──13. NEW_NODE
├── 6. DECL
│ └── 7. BINARY_OP
│ ├── 8. REFERENCE
│ └── 9. REFERENCE
└──10. RETURN_STMT
└──11. REFERENCE
Step 2 (Combine nodes with 1 child with its child):
We will now combine nodes with only 1 child with their child:
Copy
1. FUNCTION_DEF
├── 2. DECL
└── 3. COMPOUND_STMT
├── 4. DECL
└──12. NEW_NODE
├── 5. DECL
└──13. NEW_NODE
├── 6. DECL
│ └── 7. BINARY_OP
│ ├── 8. REFERENCE
│ └── 9. REFERENCE
└──10. RETURN_STMT
└──11. REFERENCE
In this example, no nodes have exactly 1 child, so the tree remains the same.
Now we have a binary tree representation of the original AST, and this is the final result of the transformation.
對於CFG做了一些限制 兩個操作
CFG 提取。為了構建程式碼的 CFG,本文首先通過一個名為 SVF 的開源工具將 C 函數解析為 CFG [53] (https://github.com/SVF-tools/SVF),該工具已廣泛用於價值流分析[54],[55]。然後本文刪除具有相同語句或沒有語句的節點。對於具有相同語句的節點,本文首先保留在 SVF 的輸出中出現的節點並刪除其子節點,並將其子節點的子節點連結到它們。對於沒有宣告語句的節點(比如說空節點),本文刪除它們並將它們的子節點連結到它們的父節點。本文將 CFG 節點的最大大小設定為 512。
評估指標
對於自動評估,本文采用兩個常見的指標來衡量程式碼檢索的有效性,即 SuccessRate @k 和平均倒數排名(MRR),這兩個指標都已廣泛應用於資訊檢索領域。為了衡量搜尋結果的相關性,本文使用排名 k 的成功率。 SuccessRate @k 衡量排名前 k 的結果中可能存在多個正確結果的查詢的百分比 [6],[56],計算如下:

其中 Q 是一組查詢,δ(·) 是一個函數,如果輸入為 true,則返回 1,否則返回 0。 SuccessRate @k 很重要,因為更好的程式碼搜尋引擎應該允許開發人員通過檢查更少的返回結果來發現所需的程式碼。 SuccessRate 值越高,程式碼搜尋效能越好
還有MRR的指標
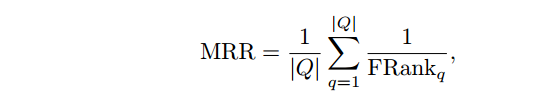
其中 jQj 是查詢集的大小。 MRR值越高,程式碼檢索效能越好。
具體實現
對於每個批次,程式碼都會使用特殊標記
總的比較
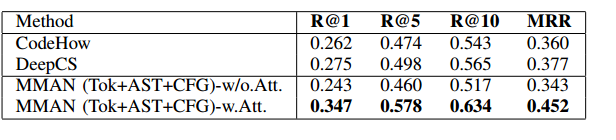
比較本文提出的模型 MMAN (Tok+AST+CFG)-w 的兩個變體的效能。或者w/o.Att.,本文可以觀察到本文設計的注意力機制確實具有積極的作用。
下面是作者對於各個模態的實驗
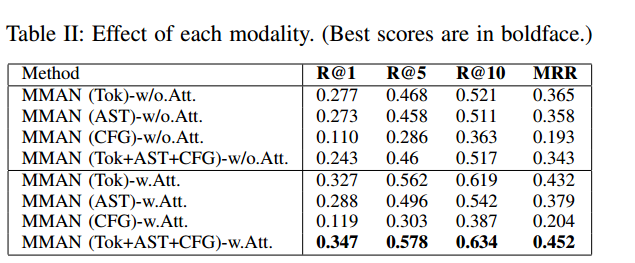
本文可以觀察到,合併更多的模式將獲得更好的效能,這表明這些模式之間存在互補而不是衝突的關係。比較有或沒有注意力的每種模態的效能,本文還發現本文設計的注意力機制對於將這些模態融合在一起具有積極的作用
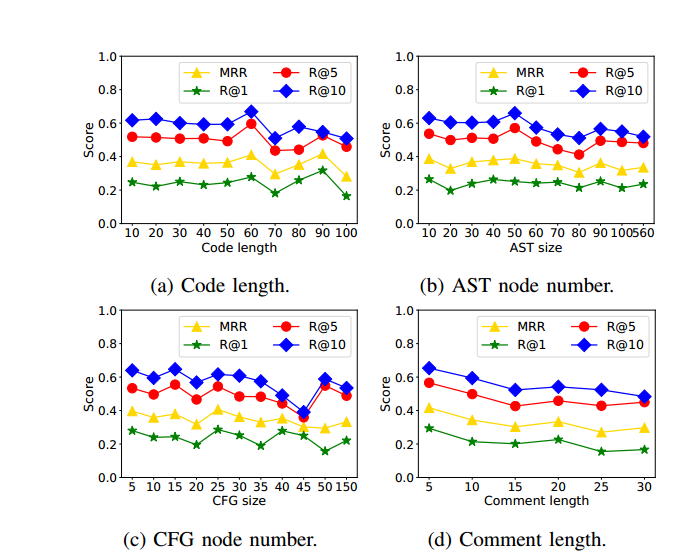
分析程式碼的長度是否會對模型有影響
為了分析本文提出的模型的魯棒性,本文研究了四個可能對程式碼和註釋表示產生影響的引數(即程式碼長度、程式碼 AST 節點數量、程式碼 CFG 節點數量和註釋長度)。圖 8a 顯示了本文提出的方法的效能,該方法基於具有不同程式碼和註釋長度的不同評估指標。
從圖8a(a)(b)(c)中,本文可以看到,在大多數情況下,即使程式碼長度或節點數量急劇增加,本文提出的模型也具有穩定的效能。
本文通過將其歸因於本文在模型中採用的混合表示來考慮這種影響。
比如說查一個 「Print any message in the axel structure 的方法名,用視覺化來看注意力機制對哪部分加權比較大
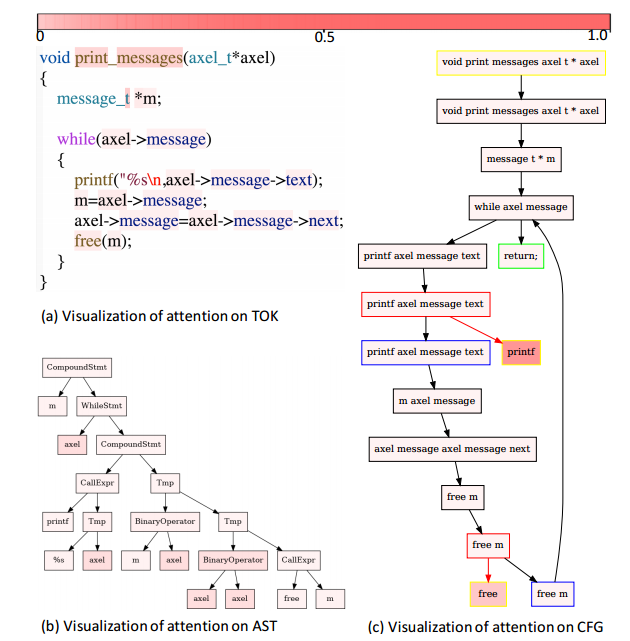
圖 10 視覺化了分配給程式碼每個部分的注意力權重。不同的模式,以便解釋程式碼的哪一部分對最終結果貢獻更大。
從圖10a中,本文可以看到,對token的注意力確實可以提取出函數名print_message等重要部分。
另一方面,從圖 10b 中,本文可以看到 AST 上的注意力在葉節點(例如 axel)以及一些操作節點(例如 BinaryOperator)上分配了更多權重。
觀察到 CFG 上的注意力在呼叫的函數節點(例如 prinf 和 free)上分配了更多權重。 CFG 可以描述原始碼片段的控制流,這一事實可以說明這一點