【Azure Event Hub】自定義告警(Alert Rule)用來提示Event Hub的訊息incoming(生產)與outgoing(消費)的異常情況
問題描述
在使用Azure Service Bus的時候,我們可以根據Queue中目前存在的訊息數來判斷當前訊息是否有積壓的情況。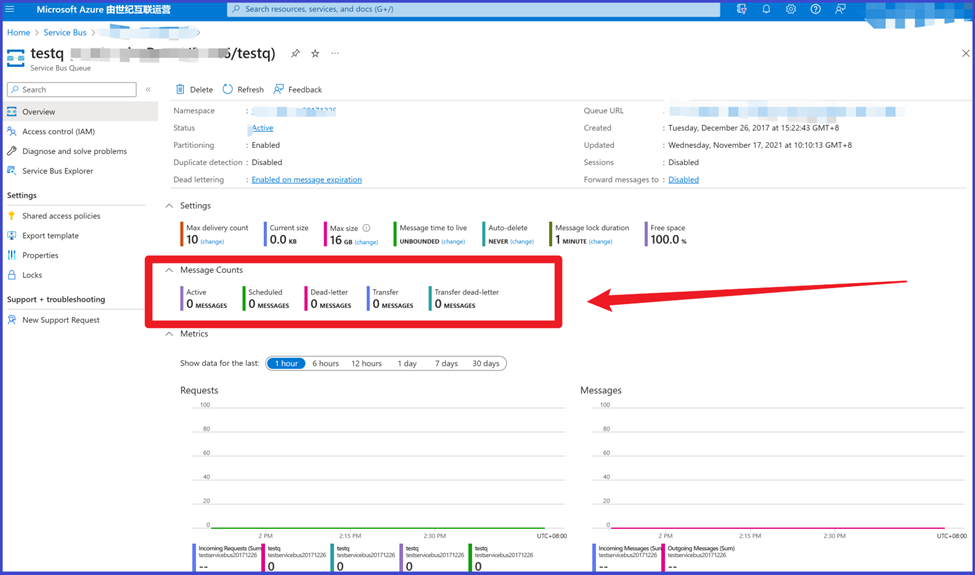
但是,在Event Hub中,因為所有訊息都會被存留到預先設定的保留時間(預設是7天), 所以無法通過訊息數來判斷當前的訊息是否有積壓或者是有多餘重複消費。
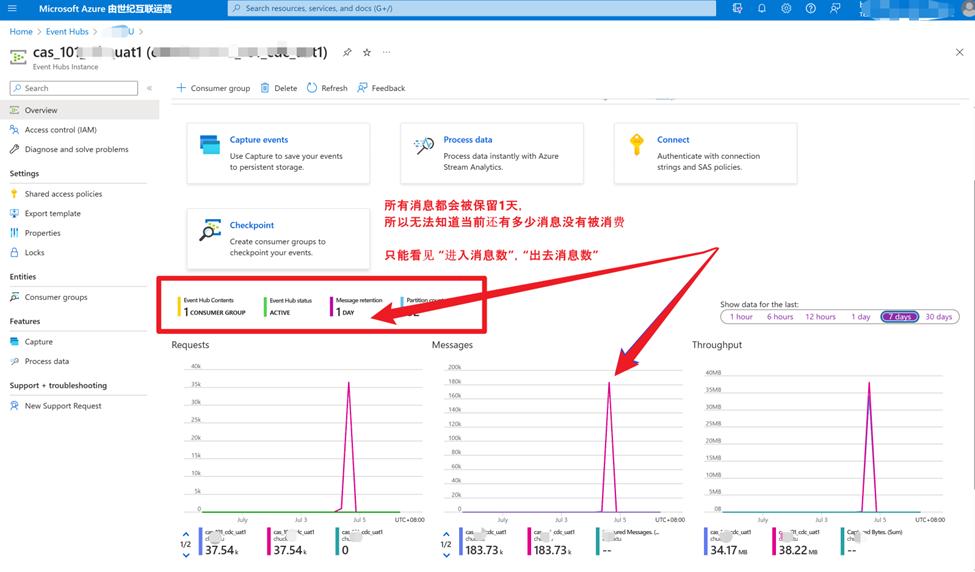
當消費端出現異常情況,在沒有incoming的情況下,還是存在大量的outgoing,這種情況如何來提前預警呢?是否可以通過設定告警規則來及時通知運維人員呢?
如下圖這樣Outgoing 大於 incoming的情況
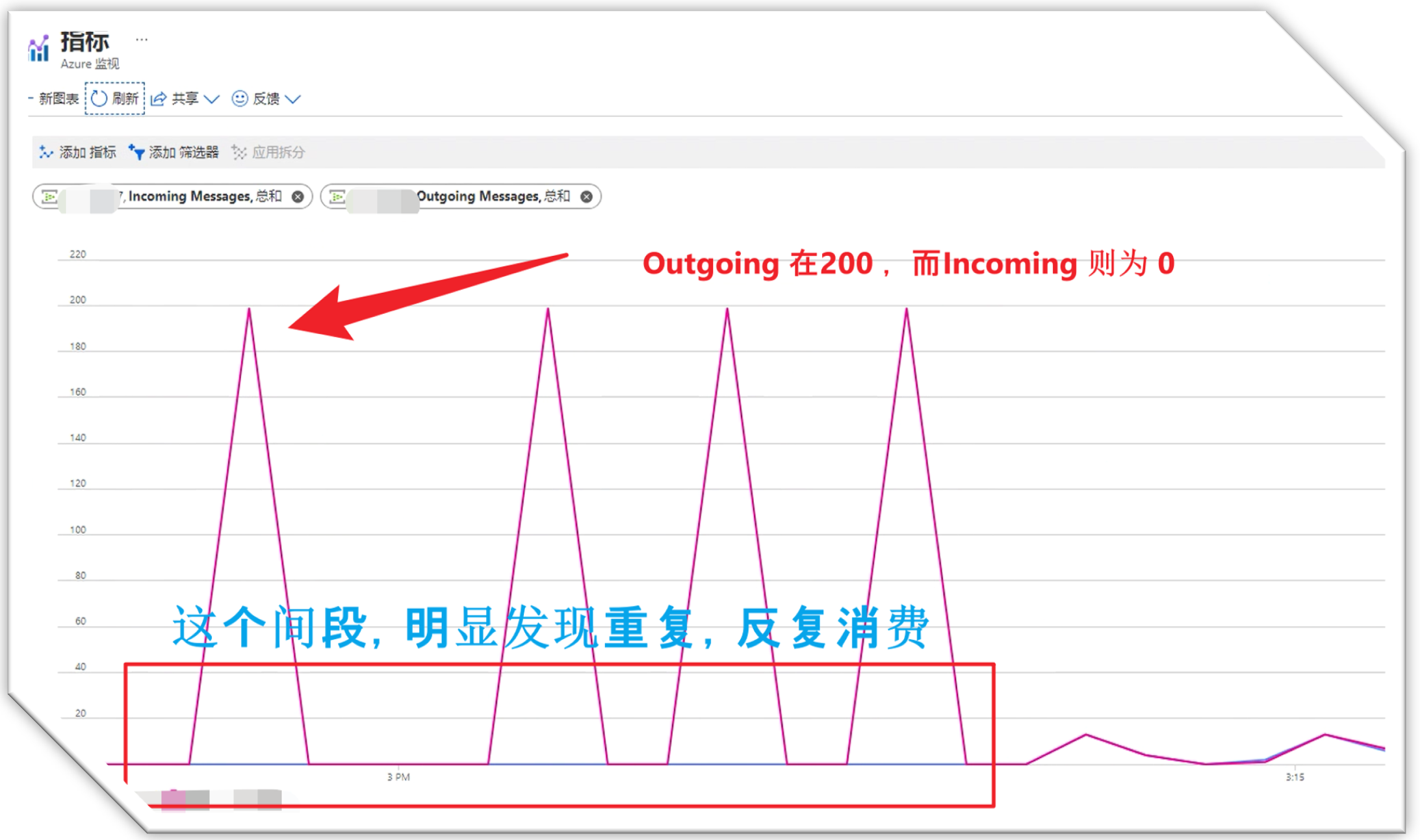
問題解答
在Azure服務中,PaaS資源都可以根據指標資料來設定告警,但是這是基於該服務有這型別指標的情況。
如現在Event Hub中 Outgoing Message 和Incoming Message不匹配的情況,由於Event Hub自身的指標中,並沒有一個指標表示 Outgoing 與 Incoming 之間的差距值。 如果需要知道兩個指標間的差值,就需要從收集的Metrics指標中進行自定義查詢語句,並根據結果進行閾值設定。
主要的步驟有:
1)收集Event Hub Metrics指標到Log A中
- 設定診斷紀錄檔,紀錄檔傳送到Log Analytics Workspace中
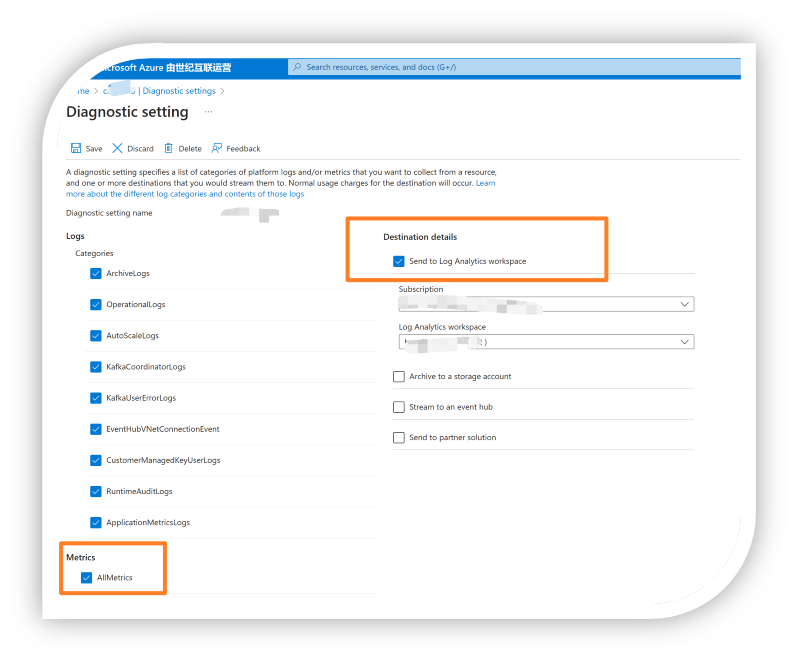
詳細步驟,可參考官網:https://docs.azure.cn/zh-cn/event-hubs/monitor-event-hubs
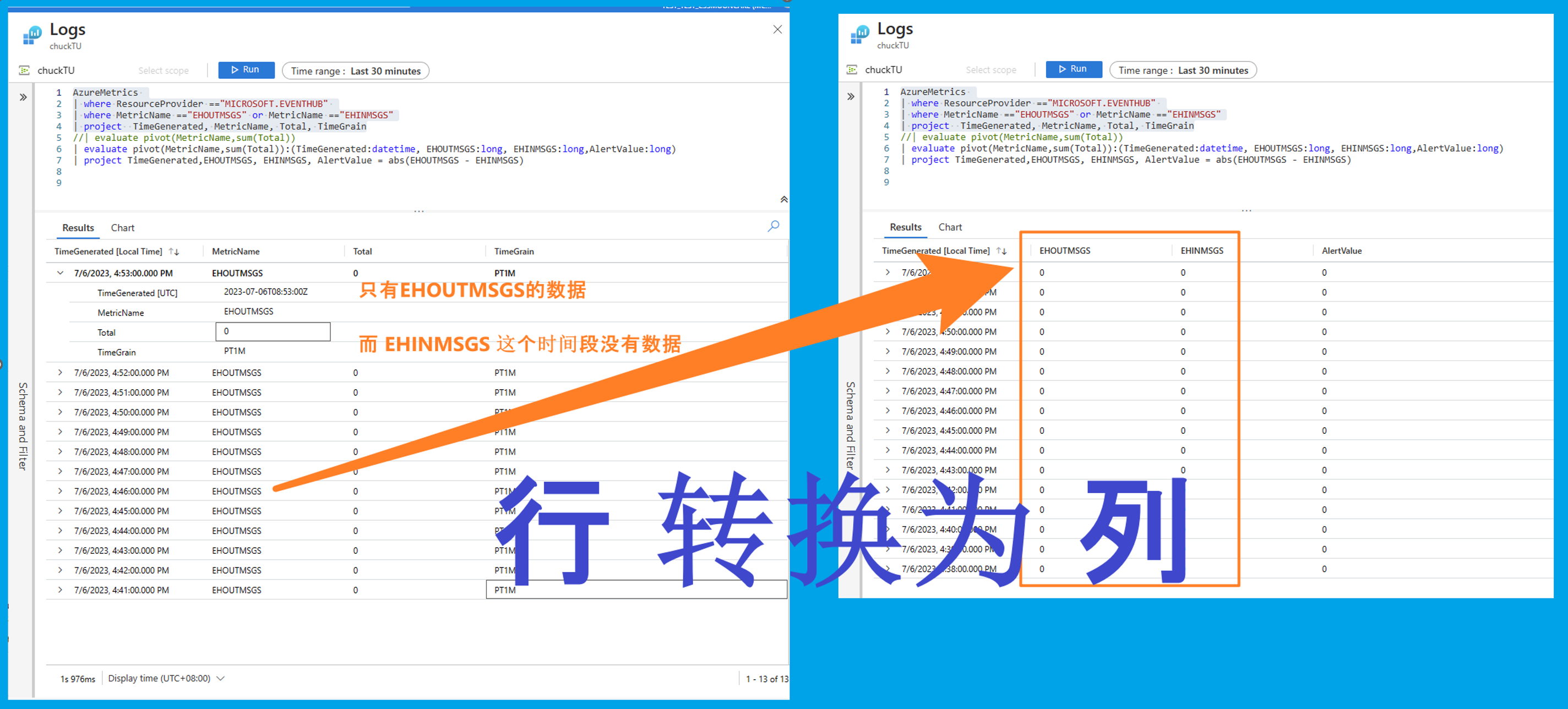
2)自定義查詢語句,在Kusto中進行行列轉換,絕對值轉換
範例Kusto語句
AzureMetrics | where ResourceProvider =="MICROSOFT.EVENTHUB" | where MetricName =="EHOUTMSGS" or MetricName =="EHINMSGS" | project TimeGenerated, MetricName, Total, TimeGrain | evaluate pivot(MetricName,sum(Total)):(TimeGenerated:datetime, EHOUTMSGS:long, EHINMSGS:long,AlertValue:long) | project TimeGenerated,EHOUTMSGS, EHINMSGS, AlertValue = abs(EHOUTMSGS - EHINMSGS)
說明:
1: EHOUTMSGS 表示Event Hub Outgoing Messages 統計值
2: EHINMSGS表示 Event Hub Incoming Messages 統計值
3: pivot 函數執行把多行資料轉換為多列。此處通過MetricsName的值的不同而轉換為 EHOUTMSGS 和 EHINMSGS 兩列,並且根據TimeGenerated時間值進行Total統計。在同一個時間點的資料歸併為一行資料。
4:AlertValue = abs(EHOUTMSGS - EHINMSGS), 計算差值並取絕對值,然結果顯示為正
PIVOT使用的前後對比效果:
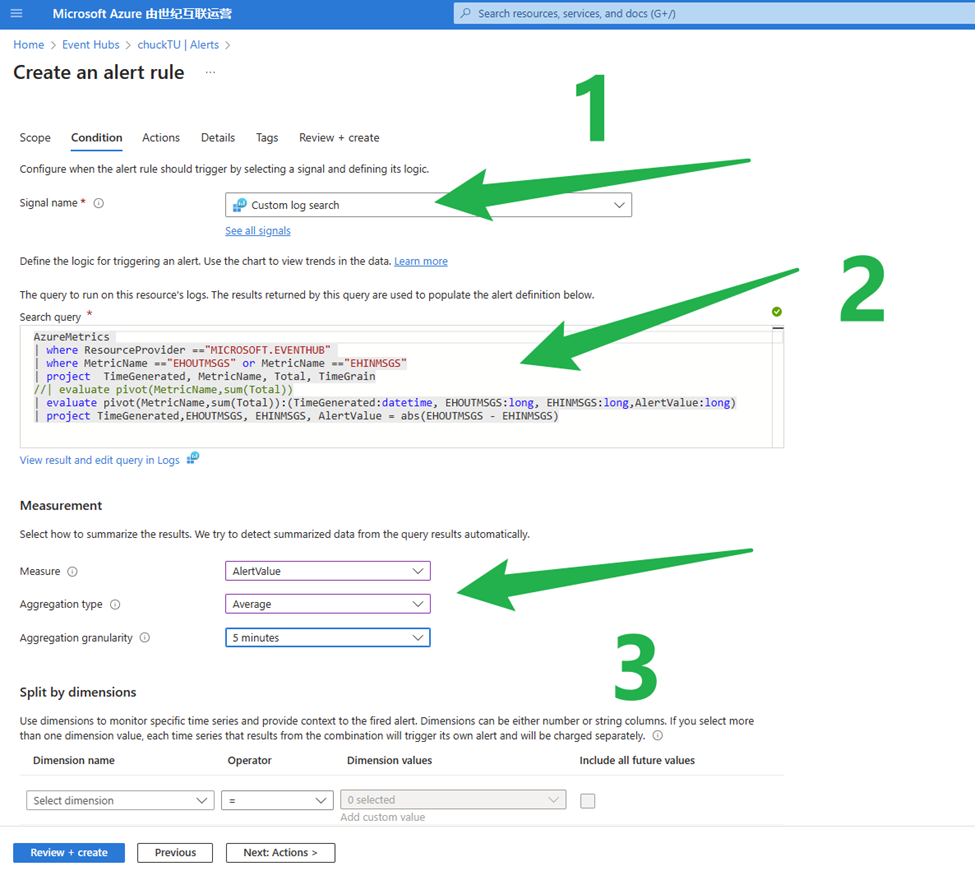
3)設定自定義指標
- 選擇 Signal Name 為 Custom Log search
- 輸入第二步中的Kusto Query 語句
- 在Measurement選擇 AlertVaule, Average, 並以5分鐘為一個時間週期進行判斷
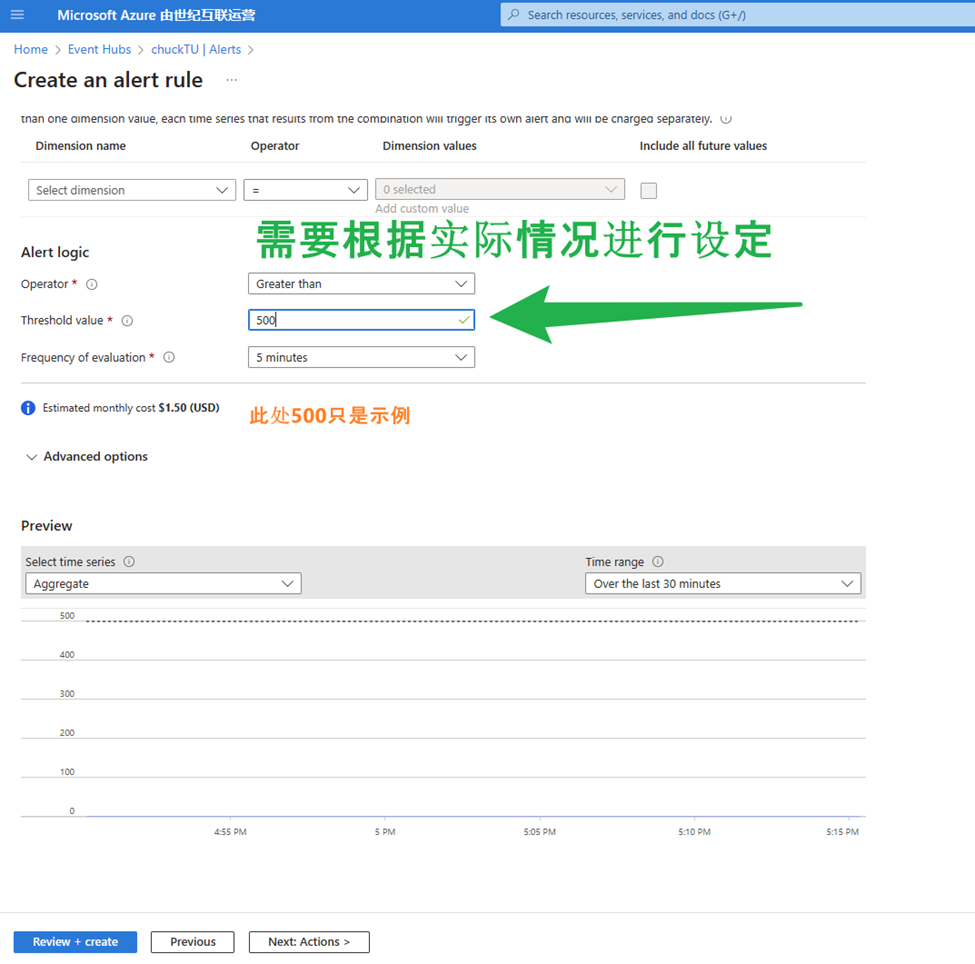
4)設定閾值
在Alert Logic 部分中,這是閾值即可。這裡也是觸發Alert的關鍵點,需要根據實際情況來決定一個合理的值。
【結束】
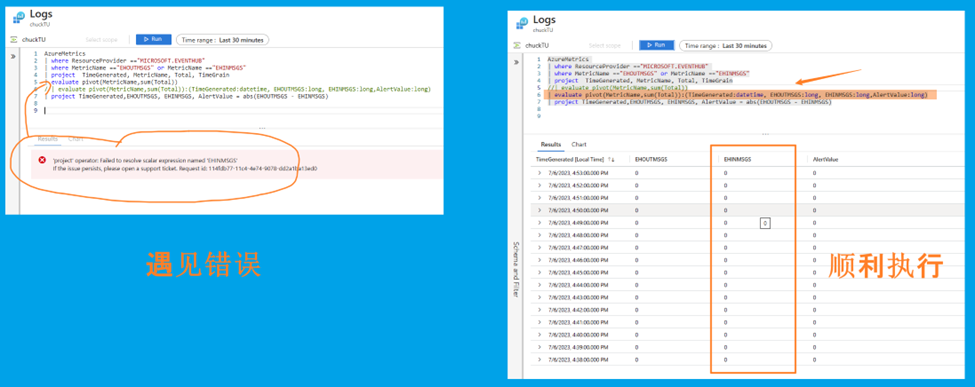
附錄:為什麼pivot 語句中特意的新增了 輸出格式的結構體呢?
| evaluate pivot(MetricName,sum(Total)):(TimeGenerated:datetime, EHOUTMSGS:long, EHINMSGS:long,AlertValue:long)

新增OutputSchema的目的就為了避免查詢結構體中缺少了需要統計的欄位值而報錯('project' operator: Failed to resolve scalar expression named 'EHINMSGS' I)。
如下效果對比:
當在複雜的環境中面臨問題,格物之道需:濁而靜之徐清,安以動之徐生。 雲中,恰是如此!