clickhouse使用入門
轉載請註明出處(~ ̄▽ ̄)~嚴禁用於商業目的的轉載~
導語:同學,你也不想你根本不懂ClickHouse,卻趕鴨子上架使用的事情被其他人知道吧?
寫在前面:本文旨在讓原先有一定SQL基礎的人快速簡單瞭解ClickHouse的(關鍵)概念/特性,側重於使用方面的介紹比較而非原理/實現挖掘。文章算是個人摘錄學習+理解,主要參考資料為ClickHouse官方(英文)檔案(畢竟絕對權威),寫於2023年5月,請注意時效性。
簡要介紹
ClickHouse是一個用於聯機分析處理(OLAP)的列式資料庫管理系統(DBMS),擁有著及其卓越的查詢速度。OLAP是一種面向分析的處理,用於處理大量的資料並支援複雜的分析和查詢操作。諸如BI系統等重資料分析的場景,都應重點考慮使用OLAP資料庫,而其中ClickHouse又是OLAP資料庫星海中最璀璨的一顆星。
ClickHouse的場景特點
縱使ClickHouse有千般萬好,但是能真正契合系統需求的資料庫,才是最合適的。因此,在我們正式邁進ClickHouse使用大門之前,我想有必要先識其長短。

上圖截自ClickHouse官方檔案,與其說這是olap的場景,不妨說是ClickHouse的常見場景。其中我覺得有必要指出的是:
1.」查詢相對較少」,這意味著ClickHouse並行查詢能力不強(官方建議每秒最多查詢100次),原因在於對於每條查詢,ClickHouse都會盡可能動用伺服器的CPU、記憶體資源等,而不同於MySQL單條SQL是單執行緒的,資源消耗更不可控(當然ClickHouse本身也有相關引數可以設定查詢消耗的資源情況)。
2.」結果適合於單個伺服器的RAM中」,結合上面所說,每條查詢都會消耗ClickHouse不少的(記憶體)資源,因此不要無腦join大表,否則Memorylimitexceeded警告。
在開始更有意義的讚美之前,讓我再對ClickHouse進行一些」自由的批評」:
1.儘管ClickHouse與mysql等資料庫一樣支援標準SQL語法(甚至相容了mysql的\G語法)以及視窗函數等,但是相關子查詢暫未支援,但將來會實現。
2.稀疏索引使得ClickHouse不適合通過其鍵檢索單行的點查詢。(稀疏索引只儲存非零值,因此在進行點查詢時需要遍歷整個索引才能找到對應的行,這會導致點查詢的效能較低)
ClickHouse基礎
連線及資料格式
連線方式
ClickHouse提供了HTTP和TCP以及gRPC三種方式的介面,非常方便,其中ClickHouse-client是基於TCP方式的,不同的client和伺服器版本彼此相容。
以HTTP介面方式存取時,需注意使用GET方法請求時是預設readonly的。換句話說,若要作修改資料的查詢,只能使用POST方法。
此外,除了上述的介面形式,ClickHouse甚至支援了MySQL wire通訊協定,生怕像我一樣的MySQL boy難以上手。簡單的設定之後,就能輕鬆使用mysqlclient連線ClickHouse伺服器,頗有import pytorch as tf之感(這何嘗不是一種語言層面的ntr)。不過也有一些限制,不支援prepared查詢以及某些資料型別會以字串形式傳送。同樣命運的還有PostgreSQL。
當然,更常見的使用方式還是各語言實現的client庫。如今ClickHouse的生態早已成熟,無論是各類程式語言亦或是常見的InfrastructureProducts(怎麼翻都彆扭乾脆貼原文,後同)(如kafka、k8s、grafana等),都有現成的庫將其結合起來使用。
資料格式
ClickHouse支援豐富的輸入/輸出格式,簡單來說就是TSV、CSV、JSON、XML、Protobuf、二進位制格式以及一些Hadoop生態下常見的資料格式。此外ClickHouse本身也有一些模式推斷相關的函數,能從檔案/hdfs等資料來源推斷出表的結構,算是個有趣的功能。
資料型別
常用的:
整型:追求極致效能的ClickHouse,自然是會在位元組維度上錙銖必較的,整型型別的可選範圍為(U)Int8到Int256,當然講究相容的ClickHouse也是允許你定義BIGINT、BOOL、INT4之類的,會對應到相應的位元組數型別上。什麼,你還要像mysql那樣定義展示寬度(11)?對不起,做不到.jpg。
浮點數:Float32⬄FLOAT、Float64⬄DOUBLE,需注意計算可能出現Inf和NaN。
Bool:內部等同於UInt8。
String:位元組數沒有限制,與LONGTEXT,MEDIUMTEXT,TINYTEXT,TEXT,LONGBLOB,MEDIUMBLOB,TINYBLOB,BLOB,VARCHAR,CHAR同義。
Date:取值範圍[1970-01-01,2149-06-06](當前)。
DateTime:具體到秒的時間。可以指定時區,如DateTime('Asia/Shanghai'),如不指定將使用ClickHouse伺服器的時區設定。
時區僅用作以文字形式輸入輸出資料時的轉換(所以時區函數是沒有計算cost的),實際以unix timestamp儲存。因此,如果插入資料時寫211046400和1976-09-09 00:00:00是等效的(時區為東八區的話)。
array:定義方式為array(T),下標起始為1,可以定義多維陣列。陣列元素最大可為一百萬個。陣列內的元素型別需相容,不相容將丟擲異常。可通過sizeN-1快速獲得對應第N維的長度。
Tuple:定義方式為Tuple(arg1 type1,arg2 type2…)。後續可通過類似a.b的方式獲取對應的值。元組間的比較為依次比較各元素大小。
Nullable:可用Nullable修飾一個型別,使其允許包含NULL值,代價是,被修飾的列無法作為表的索引項。同時,為了儲存Nullable值,ClickHouse還會額外使用一個帶有NULL掩碼的檔案來區分列的預設值與NULL值,會在儲存空間以及效能上造成額外負擔。
也正是因為特殊對待了Nullable的欄位,可以用`欄位名`.null(這個值將返回1或0標識是否為空值)快速找到對應欄位為null的行。
總之,能用業務邏輯來區分空值,就儘量不要定義Nullable欄位。
AggregateFunction:黑魔法,用法是AggregateFunction(func,types_of_argument..),如AggregateFunction(uniq,UInt64)。目前只支援uniq,anyIf和quantiles聚合函數。
可以配合xx-State函數得到中間狀態,通過xx-Merge函數得到結果。好處就是可以將計算狀態序列化到表裡,減少資料儲存量。通常是通過物化檢視實現的。
SimpleAggregateFunction:類似於AggregateFunction型別,支援更多的聚合函數,且無需應用xx-Merge和xx-State函數來得到值。
不常用的(我覺得):
Decimal:
P-精度。有效範圍:[1:76],決定可以有多少個十進位制數位(包括分數)。
S-規模。有效範圍:[0:P],決定數位的小數部分中包含的小數位數。
FixedString(N):顧名思義,需注意N為位元組,當欄位的位元組數剛好與指定的N相等時最高效,適合存一些明確的列舉。超過會丟擲異常。
UUID:配合generateUUIDv4函數食用更佳。
Date32:範圍為有符號32位元整數,表示相對1970-01-01的的天數。
DateTime64:時間範圍[1900-01-01 00:00:00,2299-12-31 23:59:59.99999999]。但不同於DateTime會與String自動轉換,需藉助諸如toDateTime64之類的時間處理常式。
列舉:有Enum8和Enum16兩種型別,將預定字串與整型數位關聯。插入列舉值之外的值將丟擲異常,列舉值不能直接跟數位作比較。
LowCardinality:用法是LowCardinality(data_type),data_type的可選型別為String,FixedString,Date,DateTime及除Decimal外的數位型別。
即將所在列的不同值對映到一個較短的編碼,當少於10000個不同的值時ClickHouse可以進行更高效的資料儲存和處理。比列舉型別有更高的效能和靈活性。
域(Domain):域是出於使使用者易用等目的,在不修改原型別底層表示的情況下為基礎型別新增了部分特性的型別,使用者不能自定義域。目前有IPV4和IPV6兩個型別,用途可顧名思義。
Nested:定義方式為Nested(name1Type1,Name2Type2,…),如DistrictNested(ProvinceString,CityString),後續就可以通過District.City存取具體值,將得到陣列物件。(重生之我在DB定義結構體)
flatten_nested設為0(非預設值)可以無限套娃Nested型別。Alter命令操作Nested型別會受限。
地理位置:包含了Point、Ring、Polygon、MultiPolygon四種型別,即Tuple(Float64,Float64),Array(Point),Array(Ring),Array(Polygon)。其中Polygon的表示方式為首元素為最外層輪廓的點集合,其餘元素視作多邊形的」洞」。
字典:定義方式Map(key,value),key可為String,Integer,LowCardinality,FixedString,UUID,Date,DateTime,Date32,Enum,value型別任意,包括Map本身。取數時寫法也與各大程式語言相同,當key不存在時預設返回型別的零值,也支援a.keys和a.values這樣的語法。(Re:從零開始的異世界DB寫Map生活)
SQL語句

ClickHouse支援的SQL語句如上所示,內容太多了。。只簡單挑些重點看下,先留個坑。
SELECT
小技巧:
select取最終列時,可以使用COLUMNS表示式來以re2的正規表示式語法查詢匹配的列,如COLUMNS(‘a’)可以匹配aa,ab列,效果類似python的re.search方法,查詢大寬表的時,這個功能還是非常好用的。
此外,配合APPLY(<func>),EXCEPT(col_name..),REPLACE(<expr>ascol_name)這三個語法糖,有時能大大簡化SQL,如:
SELECT COLUMNS(‘_w’) EXCEPT(‘test’) APPLY(max) from my_table
就能迅速找出帶_w且不帶test的列,並計算他們的最大值。(想想有時只需要簡單分析部分列,卻要施法吟唱半天)
有時需要對單獨某個查詢設定特殊設定時,也可在語句最後直接加上SETTINGS xx,這樣設定就只會對本次查詢生效。
ARRAY JOIN:
用於生成一個新表,該表具有包含該初始列中的每個單獨陣列元素的列,而其他列的值將被重複顯示。單行變多行的經典操作。空陣列將不包含在結果中,LEFT ARRAY JOIN則會包含。
可同時ARRAY JOIN多個陣列,這種情況下得到的結果並非笛卡爾積。也可以ARRAY JOIN Nested型別。
DISTINCT:
如果需要只對某幾列去重,需用DISTINCTON(column1,column2..),否則視作對全部列去重。DISTINCT子句是先於ORDER BY子句執行的。
與不使用聚合函數而對某些列進行GROUPBY相比,結果一般是相同的,但使用DISTINCT時,已處理的資料塊會立馬輸出,而無需等待整個查詢執行完成。
INTERSECT、UNION、EXCEPT:
將兩個查詢進行交併補,列數等資訊需匹配。重複行多時INTERSECT DISTINCT效果更好。
FROM:
可在資料來源名後加上FINAL修飾符,ClickHouse會在返回結果之前完全合併資料,從而執行給定表引擎合併期間發生的所有資料轉換。只適用於MergeTree-引擎族。使用FINAL修飾符的SELECT查詢啟用了並行執行,但仍比不帶FINAL的查詢更慢,一是因為這會在查詢執行過程中合併資料,二是FINAL會額外讀取主鍵列。多數情況下不推薦使用,通常可以通過假設MergeTree的後臺程序還未生效(引擎部分再談),並使用聚合函數來達到同樣效果。
此外不同於很多資料庫在你缺失相關引數時給個錯誤,ClickHouse在很多地方都做了預設引數的設定。比如在你不指定FROM子句時,預設從system.one表查詢,以及支援select count()(會傾向於選取最小的列進行計數)這樣的寫法。不過這好不好嘛,還是智者見智仁者見仁,在不理解的情況下被暗戳戳地坑一把也是可能的。
Join:
除了支援標準的SQL JOIN型別,還支援ASOF JOIN,常用於根據時間序列不完全匹配地join多個表,比如用來匹配使用者事件活動記錄。
涉及到分散式表的join:
當使用普通JOIN時,將查詢傳送到遠端伺服器。在每個伺服器上單獨形成右表。
當使用GLOBAL ... JOIN時,首先請求者伺服器執行一個子查詢來計算正確的表。此臨時表將傳遞到每個遠端伺服器,並使用傳輸的臨時資料對其執行查詢。
當執行JOIN操作時,與查詢的其他階段相比,執行順序沒有進行優化。JOIN操作會在WHERE過濾和聚合之前執行。
同樣的join操作在子查詢中又會再次執行一次,要避免這種情況可以考慮使用Join這個表引擎。
預設情況下,ClickHouse使用雜湊聯接演演算法。 ClickHouse取右表並在記憶體中為其建立雜湊表。(所以一個很重要的最佳實踐是join表時把小表放在右表)在達到某個記憶體消耗閾值後,ClickHouse會回退到合併聯接演演算法。
INSERT INTO
插入資料時會對寫入的資料進行一些處理,按照主鍵排序,按照分割區鍵對資料進行分割區等。所以如果在寫入資料中包含多個分割區的混合資料時,將會顯著的降低INSERT的效能。為了避免這種情況:
- 資料總是以儘量大的batch進行寫入,如每次寫入100,000行。
- 資料在寫入ClickHouse前預先的對資料進行分組。
在以下的情況下,效能不會下降:
- 資料總是被實時的寫入。
- 寫入的資料已經按照時間排序。
也可以非同步的、小規模的插入資料,這些資料會被合併成多個批次,然後安全地寫入到表中。這是通過設定async_insert來實現的,非同步插入的方式只支援HTTP協定,並且不支援資料去重。
CREATE
Materialized(物化檢視)
建立語法:
CREATE MATERIALIZED VIEW [IF NOT EXISTS] [db.]table_name [ON CLUSTER] [TO[db.]name] [ENGINE = engine] [POPULATE] AS SELECT ...
建立不帶TO [db].[table]的物化檢視時,必須指定ENGINE–用於儲存資料的表引擎。
使用TO [db].[table]建立物化檢視時,不得使用POPULATE。
具體實現:當向SELECT中指定的表插入資料時,插入資料的一部分被這個SELECT查詢轉換,結果插入到檢視中。
ClickHouse 中的物化檢視更像是插入觸發器。 如果檢視查詢中有一些聚合,則它僅應用於一批新插入的資料。對源表現有資料的任何更改(如更新、刪除、刪除分割區等)都不會更改物化檢視。
ClickHouse 中的物化檢視在出現錯誤時沒有確定性行為。這意味著已經寫入的塊將保留在目標表中,但出現錯誤後的所有塊則不會寫入。
如果指定POPULATE,則在建立檢視時將現有表資料插入到檢視中,就像建立一個CREATE TABLE ... AS SELECT ...一樣。否則,查詢僅包含建立檢視後插入表中的資料。不建議使用POPULATE,因為在建立檢視期間插入表中的資料不會插入其中。
SELECT查詢可以包含DISTINCT、GROUP BY、ORDER BY、LIMIT……請注意,相應的轉換是在每個插入資料塊上獨立執行的。 例如,如果設定了GROUP BY,則在插入期間聚合資料,但僅在插入資料的單個封包內。資料不會被進一步聚合。例外情況是使用獨立執行資料聚合的ENGINE,例如SummingMergeTree。
在物化檢視上執行ALTER查詢有侷限性,因此可能不方便。如果物化檢視使用構造TO [db.]name,你可以DETACH檢視,為目標表執行ALTER,然後ATTACH先前分離的檢視。
檢視看起來與普通表相同。 例如,它們列在SHOW TABLES查詢的結果中。
ALTER
UPDATE
沒錯,update操作被置於ALTER操作下,這意味著ClickHouse的update操作不像oltp資料庫那般輕量級,應儘量避免使用。是通過mutation來實現的。
Mutations(突變)
用來操作表資料的ALTER查詢是通過一種叫做「突變」的機制來實現的,最明顯的是ALTER TABLE … DELETE和ALTER TABLE … UPDATE。它們是非同步的後臺程序,類似於MergeTree表的合併,產生新的「突變」版本的資料part(後面會詮釋這個概念)。
對於*MergeTree表,通過重寫整個資料part來執行突變。沒有原子性——一旦突變的part準備好,part就會被替換,並且在突變期間開始執行的SELECT查詢將看到來自已經突變的part的資料,以及來自尚未突變的part的資料。
突變完全按照它們的產生順序排列,並按此順序應用於每個part。突變還與「INSERT INTO」查詢進行排序:在提交突變之前插入表中的資料將被突變,而在此之後插入的資料將不會被突變。注意,突變不會以任何方式阻止插入。
突變查詢在新增突變條目後立即返回(對於複製表是到ZooKeeper,對於非複製表到檔案系統)。突變本身使用系統組態檔來設定非同步執行。要跟蹤突變的程序,可以使用system.mutations表。成功提交的變異將繼續執行,即使ClickHouse伺服器重新啟動。沒有辦法回滾突變一旦提交,但如果突變卡住了,可以使用KILL MUTATION阻止突變的執行。
完成突變的條目不會立即刪除(保留條目的數量由finished_mutations_to_keep儲存引擎引數決定)。
DELETE
刪除的行會被立即標記為已刪除,並將自動從所有後續查詢中過濾掉。資料清理在後臺非同步發生。此功能僅適用於 MergeTree 表引擎系列。這就是ClickHouse的輕量級刪除
原理:當執行DELETE時,ClickHouse 僅儲存一個掩碼,其中每一行都被標記為「現有」或「已刪除」。 掩碼實現為一個隱藏的_row_exists系統列,所有可見行該列儲存為 True,刪除的行儲存為False。僅當一個資料part中部分行被刪除了,這個欄位才會出現。
DELETE操作實際上是被翻譯成ALTER TABLE update _row_exists = 0 WHERE …的mutation操作。
引擎
資料庫引擎
Atomic
ClickHouse的預設資料庫引擎,支援非阻塞的DROP TABLE、RENAME TABLE和具有原子性的EXCHANGE TABLE操作。
DROP TABLE時只會將表標記為已刪除,並且把後設資料移到/clickhouse_path/metadata_dropped/,然後通知後臺執行緒稍後刪除,這個延遲時間可指定,也可設為同步刪除。
Lazy
在最後一次存取之後,只在記憶體中儲存expiration_time_in_seconds秒。只能用於*Log表。它是為儲存許多小的*Log表而優化的,對於這些表,存取之間有很長的時間間隔。
PostgreSQL、MySQL、SQLite
……用於在ClickHouse與上述三種資料庫間交(tou)換(jia)資料。其中不能在MySQL引擎上執行RENAME、CREATETABLE和ALTER來修改表的結構。
另外還有幾個實驗性的引擎,不談。
表引擎
表引擎(即表的型別)決定了:
- 資料的儲存方式和位置,寫到哪裡以及從哪裡讀取資料
- 支援哪些查詢以及如何支援。
- 並行資料存取。
- 索引的使用(如果存在)。
- 是否可以執行多執行緒請求。
- 資料複製引數。
MergeTree系列
MergeTree系列的引擎是ClickHouse中最核心的引擎,提供了列式儲存、自定義分割區、稀疏主鍵索引和二級跳數索引等功能。基於MergeTree的引擎都在部分特定用例下新增了額外的功能,而且通常是在後臺執行額外的資料操作來實現的。缺點是這些引擎相對笨重,如果需要許多小表來存一些臨時資料,可以考慮Log系列引擎。
MergeTree
主要特點:
- 儲存按主鍵排序。
- 指定了分割區鍵時,會擷取分割區資料,增加查詢效率。
- 支援資料取樣。
完整語句參考:
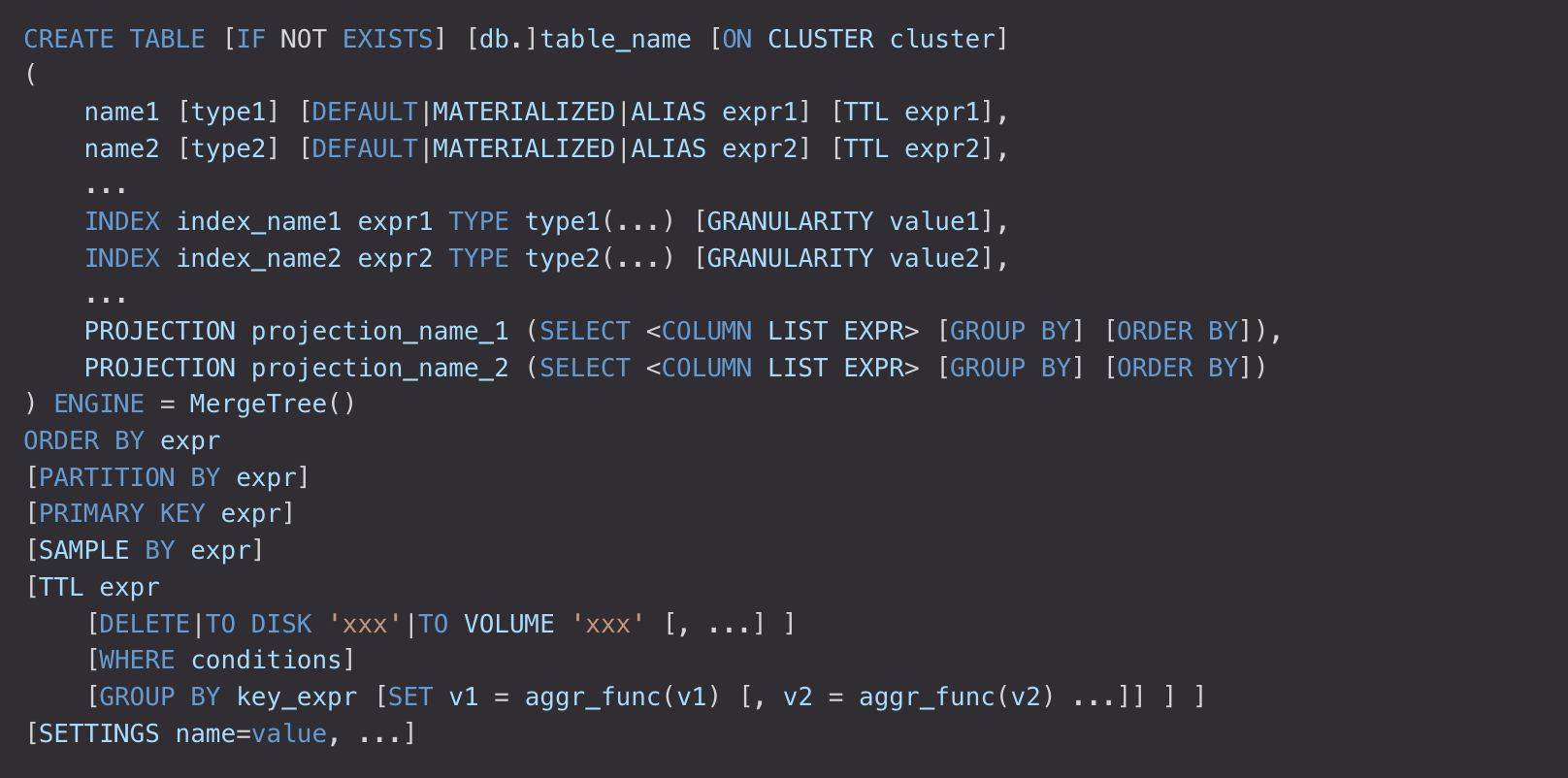
重要引數說明:
ORDER BY:排序鍵
如果沒有用PRIMARY KEY明確定義主鍵,那麼該鍵將被當做主鍵。
如果不需要排序,可以使用ORDERBY tuple()。
排序鍵包含多列時,查詢時走索引依然遵循最左匹配規則。
PARTITION BY:分割區鍵
大多數情況下,不需要分使用區鍵。即使需要使用,也不需要使用比月更細粒度的分割區鍵。分割區不會加快查詢(這與ORDER BY表示式不同)。永遠也別使用過細粒度的分割區鍵。
要按月分割區,可以使用表示式toYYYYMM(date_column)。
PRIMARY KEY:主鍵
大部分情況下不需要再專門指定一個PRIMARY KEY子句。ClickHouse不要求主鍵唯一。
INDEX:跳數索引
後面介紹。
儲存細節:
不同分割區的資料會被分成不同的片段(part,後同),ClickHouse在後臺合併資料片段以便更高效儲存。
資料片段可以以Wide或Compact格式儲存。在Wide格式下,每一列都會在檔案系統中儲存為單獨的檔案,在Compact格式下所有列都儲存在一個檔案中。Compact格式可以提高插入量少插入頻率頻繁時的效能。
每個資料片段被邏輯的分割成顆粒(granules)。顆粒是ClickHouse中進行資料查詢時的最小不可分割資料集。ClickHouse不會對行或值進行拆分,所以每個顆粒總是包含整數個行。每個顆粒的第一行通過該行的主鍵值進行標記,ClickHouse會為每個資料片段建立一個索引檔案來儲存這些標記。對於每列,無論它是否包含在主鍵當中,ClickHouse都會儲存類似標記。
顆粒的大小通過表引擎引數index_granularity(預設8192)和index_granularity_bytes(10Mb)控制。顆粒的行數的在[1,index_granularity]範圍中,這取決於行的大小。如果單行的大小超過了index_granularity_bytes設定的值,那麼一個顆粒的大小會超過index_granularity_bytes。在這種情況下,顆粒的大小等於該行的大小。
詳談主鍵與索引:
主鍵的選擇:
稀疏索引使得ClickHouse可以處理極大量的行,因為大多數情況下,這些索引常駐於記憶體。
長的主鍵會對插入效能和記憶體消耗有負面影響,但主鍵中額外的列並不影響SELECT查詢的效能。
可以使用ORDER BY tuple()語法建立沒有主鍵的表。在這種情況下ClickHouse根據資料插入的順序儲存。如果在使用INSERT...SELECT時希望保持資料的排序,可以設定max_insert_threads=1。
主鍵與排序鍵不同的情況:
ClickHouse可以做到指定一個跟排序鍵不一樣的主鍵,此時排序鍵用於在資料片段中進行排序,主鍵用於在索引檔案中進行標記的寫入。這種情況下,主鍵表示式元組必須是排序鍵表示式元組的字首。
當使用SummingMergeTree和AggregatingMergeTree引擎時,這個特性非常有用。通常在使用這類引擎時,表裡的列分兩種:維度和度量。典型的查詢會通過任意的GROUP BY對度量列進行聚合並通過維度列進行過濾。由於SummingMergeTree和AggregatingMergeTree會對排序鍵相同的行進行聚合,所以把所有的維度放進排序鍵是很自然的做法。但這將導致排序鍵中包含大量的列,並且排序鍵會伴隨著新新增的維度不斷的更新。
在這種情況下合理的做法是,只保留少量的列在主鍵當中用於提升掃描效率,將維度列新增到排序鍵中。
部分單調序列:
如一個月中的天數。它們在一個月的範圍內形成一個單調序列,但如果擴充套件到更大的時間範圍它們就不再單調了,這就是一個部分單調序列。如果使用者使用部分單調的主鍵建立表,ClickHouse同樣會建立一個稀疏索引。當用戶從這類表中查詢資料時,ClickHouse會對查詢條件進行分析。如果使用者希望獲取兩個索引標記之間的資料並且這兩個標記在一個月以內,ClickHouse可以在這種特殊情況下使用到索引,因為它可以計算出查詢引數與索引標記之間的距離。
如果查詢引數範圍內的主鍵不是單調序列,那麼ClickHouse無法使用索引。
ClickHouse在任何主鍵代表一個部分單調序列的情況下都會使用這個邏輯。(這個故事告訴我們為什麼預設主鍵和排序鍵相同)
跳數索引:
範例:INDEX a(u64*i32,s) TYPE minmax GRANULARITY 3。複合列上也能建立。
*MergeTree系列的表可以指定跳數索引。跳數索引是指資料片段按照粒度分割成小塊後,將上述SQL的granularity_value數量的小塊組合成一個大的塊,對這些大塊寫入索引資訊,這樣有助於使用where篩選時跳過大量不必要的資料,減少SELECT需要讀取的資料量。
Projection:
投影(projection)類似於物化檢視,但儲存在分割區目錄,即與原表的資料分割區在同一個分割區目錄下。可通過投影定義語句SELECT <column list expr> [GROUP BY] <group keys expr> [ORDER BY] <expr>生成。使用可能還需要設定一些引數。
如指定了Group by子句則投影的引擎將變為AggregatingMergeTree,同時所有的聚合函數變為AggregateFunction。指定了ORDER BY子句則會使用對應的key作為主鍵。更多範例可參考:2021年ClickHouse最王炸功能來襲,效能輕鬆提升40倍。
簡單來說,跟物化檢視的區別可以看作是——不用再顯式定義一個物化檢視了,對應用層遮蔽了基礎資料和統計資料的區別。兩類資料你都直接查原表即可。
並行存取:
MergeTree引擎也是MVCC(多版本並行控制)的。
列與表的TTL:
設定TTL即設定資料的過期時間,當列的TTL過期時,ClickHouse會將資料替換成對應資料型別的預設值,當該列所有資料都過期時,該列的資料將會被刪除。(列式資料庫,小子!)主鍵列不可指定。
當表的TTL過期時,過期行會被操作(刪除或轉移),還可通過WHERE和GROUP BY條件指定符合條件的行。GROUP BY表示式必須是表主鍵的字首。
資料副本
MergeTree系列的引擎的表都支援資料副本,只需在引擎名前加上Replicated。
ReplacingMergeTree
該引擎和MergeTree的不同之處在於它會刪除排序鍵值相同的重複項,適用於在後臺清除重複的資料以節省空間。但只會在資料合併期間進行,而合併會在後臺一個不確定的時間進行。雖然可以呼叫OPTIMIZE語句發起計劃外的合併,但須知OPTIMIZE語句會引發對資料的大量讀寫。
SummingMergeTree
當合並SummingMergeTree表的資料片段時,ClickHouse會把所有具有相同主鍵的行合併為一行,該行包含了被合併的行中具有數值資料型別的列的sum值。即便如此,當需要聚合資料時仍應該使用sum函數來聚合,因為後臺合併的時間是不確定的。
對於AggregateFunction 型別的列,ClickHouse 根據對應函數表現為AggregatingMergeTree引擎的聚合。
而對於Nested型別的列,ClickHouse會將第一列視作key,其他列視作values進行聚合。
AggregatingMergeTree
將一個資料片段內所有具有相同排序鍵的行替換成一行,這一行會儲存一系列聚合函數的狀態。引擎使用AggregateFunction和SimpleAggregateFunction型別來處理所有列。可以看做SummingMergeTree是AggregatingMergeTree的特化(表現上而言)。
可以使用AggregatingMergeTree表來做增量資料的聚合統計,包括物化檢視的資料聚合。
要插入資料,需使用帶有-State-聚合函數的INSERT SELECT語句。從AggregatingMergeTree表中查詢資料時,需使用GROUP BY子句並且要使用與插入時相同的聚合函數,但字尾要改為-Merge。
CollapsingMergeTree
CollapsingMergeTree 會非同步的刪除(摺疊)這些除了特定列 Sign 有 1 和 -1 的值以外,其餘所有欄位的值都相等的成對的行。沒有成對的行將會被保留。
Sign為1和-1的行應按照一定的順序寫入,合併相當取決於記錄的一致性,否則實現不了預期的摺疊效果(即先Sign=1後Sign=-1),聚合統計時也應考慮上Sign欄位對結果的影響。可以使用Final修飾符強制進行摺疊而不聚合,但是效率低下。
此外,插入時Sign=1和Sign=-1的記錄應該在兩次insert語句中分別插入,以保證他們在不同的資料片段(part),否則也不會執行合併操作。
個人覺得,難用(其實我想說沒用),或者是我沒找到正確的開啟方式。
VersionedCollapsingMergeTree
顧名思義,是上面那位的兄弟,只不過多了一個Version列,允許以多個執行緒的任何順序插入資料。Version列有助於正確摺疊行,即使它們以錯誤的順序插入。
當ClickHouse合併資料部分時,它會刪除具有相同主鍵和版本但Sign值不同的一對行。
當ClickHouse插入資料時,它會按主鍵對行進行排序。 如果Version列不在主鍵中,ClickHouse將其隱式新增到主鍵作為最後一個欄位並使用它進行排序。
由於ClickHouse具有不保證具有相同主鍵的所有行都將位於相同的結果資料片段中,甚至位於相同的物理伺服器上的特性,以及上面說的資料合併時機的不確定性,所以想要最終的資料還是免不了group by等聚合操作。
GraphiteMergeTree
該引擎用來對Graphite型別資料進行瘦身及彙總。如果不需要對Graphite資料做彙總,那麼可以使用任意的表引擎;但若需要,那就採用GraphiteMergeTree引擎。它能減少儲存空間,同時能提高Graphite資料的查詢效率。
Log引擎系列
共同特點:
- 資料儲存在磁碟上。
- 寫入時將資料追加在檔案末尾。
- 支援並行存取資料時上鎖。(執行insert語句時,表會被上寫鎖)
- 不支援突變操作。(參見alter)
- 不支援索引。(表明範圍查詢效率不高)
- 非原子地寫入資料。
各引擎差異:
Log引擎為表中的每一列使用不同的檔案。StripeLog將所有的資料儲存在一個檔案中。因此StripeLog引擎在作業系統中使用更少的描述符,但是Log引擎提供更高的讀效能。兩者都支援並行的資料讀取。
TinyLog引擎是該系列中最簡單的引擎並且提供了最少的功能和最低的效能。TinyLog引擎不支援並行讀取和並行資料存取,並將每一列儲存在不同的檔案中。
Log
Log與TinyLog的不同之處在於,」標記」 的小檔案與列檔案存在一起。這些標記寫在每個資料塊上,並且包含偏移量,這些偏移量指示從哪裡開始讀取檔案以便跳過指定的行數。這使得可以在多個執行緒中讀取表資料。Log引擎適用於臨時資料。
StripeLog
需要寫入許多小資料量(小於一百萬行)的表的場景下使用這個引擎。
寫資料
StripeLog引擎將所有列儲存在一個檔案中。對每一次Insert請求,ClickHouse 將資料塊追加在表檔案的末尾,逐列寫入。
ClickHouse 為每張表寫入以下檔案:
- data.bin— 資料檔案。
- index.mrk— 帶標記的檔案。標記包含了已插入的每個資料塊中每列的偏移量。
StripeLog引擎不支援ALTER UPDATE和ALTER DELETE操作。
讀資料
帶標記的檔案使得 ClickHouse 可以並行的讀取資料。這意味著SELECT請求返回行的順序是不可預測的。
TinyLog
此表引擎通常使用場景:一次寫入資料,然後根據需要多次讀取。
查詢在單個流中執行。該引擎適用於相對較小的表(最多約 1,000,000 行)。如果你有很多小表,使用這個表引擎是有意義的,因為它比紀錄檔引擎更簡單(需要開啟的檔案更少)。
與外部系統整合的引擎
正如上面提到的ClickHouse對mysql等資料庫的"支援",實際上在表引擎上也提供了與外部系統的多種整合方式,如下所示。具體不再介紹,有需要可以去官網瞭解。

其他特殊引擎:
Distributed
分散式引擎本身不儲存資料, 但可以在多個伺服器上進行分散式查詢。 讀是自動並行的。讀取時,遠端伺服器表的索引(如果有的話)會被使用。
建立語法:
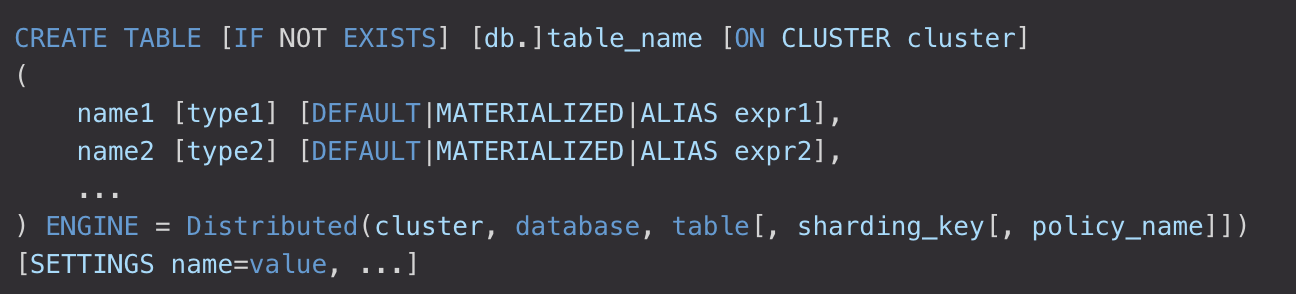
也可使用AS語法使得分散式表指向本地表。
分散式引擎引數
- cluster- 服務為設定中的叢集名
- database- 遠端資料庫名
- table- 遠端資料表名
- sharding_key- (可選) 分片key
- policy_name- (可選) 規則名,它會被用作儲存臨時檔案以便非同步傳送資料
settings中可進行一些分散式設定。
資料不僅在遠端伺服器上讀取,而且在遠端伺服器上進行部分處理。例如,對於帶有 GROUP BY的查詢,資料將在遠端伺服器上聚合,聚合函數的中間狀態將被傳送到請求者伺服器。然後將進一步聚合資料。
叢集:
叢集是通過伺服器組態檔來設定的。叢集名稱不能包含點號。
設定了副本後,讀取操作會從每個分片裡選擇一個可用的副本。可設定負載平衡演演算法。 如果跟伺服器的連線不可用,則會嘗試短超時的重連。如果重連失敗,則選擇下一個副本,依此類推。如果跟所有副本的連線嘗試都失敗,則嘗試用相同的方式再重複幾次。
要檢視叢集資訊,可通過system.clusters表。
寫入資料:
向叢集寫資料的方法有兩種:
一,自已指定要將哪些資料寫入哪些伺服器,並直接在每個分片上執行寫入。這是最靈活的解決方案 – 你可以使用任何分片方案,對於複雜業務特性的需求,這可能是非常重要的。這也是最佳解決方案,因為資料可以完全獨立地寫入不同的分片。
二,在分散式表上執行 INSERT。(噠咩,不推薦)在這種情況下,分散式表會跨伺服器分發插入資料。為了寫入分散式表,必須要設定分片鍵(最後一個引數)。當然,如果只有一個分片,則寫操作在沒有分片鍵的情況下也能工作,因為這種情況下分片鍵沒有意義。
資料是非同步寫入的。對於分散式表的 INSERT,資料塊只寫本地檔案系統。之後會盡快地在後臺傳送到遠端伺服器。
如果在 INSERT 到分散式表時伺服器節點丟失或重啟(如,裝置故障),則插入的資料可能會丟失。如果在表目錄中檢測到損壞的資料分片,則會將其轉移到broken子目錄,並不再使用。
關於分片:
分片可在組態檔中定義‘internal_replication’引數。
此引數設定為true時,寫操作只選一個正常的副本寫入資料。如果分散式表的子表是複製表(*ReplicaMergeTree),請使用此方案。換句話說,這其實是把資料的複製工作交給實際需要寫入資料的表本身而不是分散式表。
若此引數設定為false(預設值),寫操作會將資料寫入所有副本。實質上,這意味著要分散式表本身來複制資料。這種方式不如使用複製表的好,因為不會檢查副本的一致性,並且隨著時間的推移,副本資料可能會有些不一樣。
選擇將一行資料傳送到哪個分片的方法是,首先計算分片表示式,然後將這個計算結果除以所有分片的權重總和得到餘數。該行會傳送到那個包含該餘數的從’prev_weight’到’prev_weights + weight’的前閉後開區間對應的分片上,其中 ‘prev_weights’ 是該分片前面的所有分片的權重和,‘weight’ 是該分片的權重。
分片表示式可以是由常數和表列組成的任何返回整數表示式。
下面的情況,需要關注分片方案:
- 使用需要特定鍵連線資料( IN 或 JOIN )的查詢。如果資料是用該鍵進行分片,則應使用本地 IN 或 JOIN 而不是 GLOBAL IN 或 GLOBAL JOIN,這樣效率更高。
- 使用大量伺服器,但有大量小查詢,為了使小查詢不影響整個叢集,讓單個客戶的資料處於單個分片上是有意義的。或者你可以設定兩級分片:將整個叢集劃分為層,一個層可以包含多個分片。單個客戶的資料位於單個層上,根據需要將分片新增到層中,層中的資料隨機分佈。然後給每層建立分散式表,再建立一個全域性的分散式表用於全域性的查詢。
Dictionary
可以將字典資料展示為一個ClickHouse的表。需要在XML組態檔中定義字典。官網檔案語焉不詳,更多介紹可見https://blog.csdn.net/vkingnew/article/details/106973674。
(不太好用的亞子)
Merge
本身不儲存資料,但可用於同時從任意多個其他的表中讀取資料。 讀是自動並行的,不支援寫入。讀取時,那些被真正讀取到資料的表的索引(如果有的話)會被使用。
建立語法:

如果tables_regexp命中了Merge 表本身,也不會真正引入,以免迴圈參照,但建立兩個表遞迴讀取對方資料是可行的。
Merge引擎的一個典型應用是可以像使用一張表一樣使用大量的TinyLog表。
Executable和ExecutablePool
這兩個引擎用於關聯指令碼和具體表,表中的資料將由執行指令碼後生成。指令碼被放在」users_scripts」目錄下。建立表時不會立即呼叫指令碼,指令碼將在表被查詢時呼叫。
剛開始感覺這個引擎沒什麼用,為什麼我不直接單獨跑指令碼把資料收集好之後再將它們插入表呢?轉念想到指令碼程式碼倉庫裡的幾百個(無名)指令碼及對應的(無名)表,瞬間感覺這功能還怪有用的。(查詢表對應的生成指令碼)
(當然,我沒用過,等你去用)
應用及可能的坑點
應用
ClickHouse典型應用場景主要包括以下幾個方面:
- 巨量資料儲存和分析:ClickHouse能夠高效地儲存和處理海量資料,支援PB級別的資料儲存和分析,可以快速地處理大規模資料分析和資料探勘任務。
- 實時資料分析和查詢:ClickHouse支援實時查詢和分析,具有高速的資料讀取和計算能力,可以在秒級別內返回查詢結果,適用於需要快速響應資料查詢和分析的業務場景。
- 紀錄檔處理和分析:ClickHouse能夠高效地處理紀錄檔資料,支援實時的紀錄檔分析和查詢,可以幫助企業快速地發現和解決問題。
- 業務智慧分析:ClickHouse支援複雜的資料分析和計算,可以進行高階的資料探勘和機器學習演演算法,幫助企業進行業務智慧分析和決策。
總的來說,ClickHouse適用於需要處理大規模資料和實時查詢的業務場景,例如資料包表、紀錄檔分析、業務智慧分析、廣告平臺等。
其他要說的
part與partition:
這兩個概念,我覺得是ClickHouse檔案中容易搞混的一點,特別中文檔案中出現的謎之概念『片段、片塊、部分、部件、分片』,如果不是原先就對ClickHouse有較深刻的認識,可能一時反應不過來具體指代的是什麼。關於這兩者的區別,在這個連結及頁面內的連結中有較好的闡述。
關注ClickHouse版本:
ClickHouse的官方中文檔案相對英文檔案,內容要稍微落後些(你說跟俄文比如何?阿巴阿巴)。比如中文檔案中說ClickHouse不支援視窗函數,但英文檔案中表示已經支援;中文檔案中沒有projection的介紹;中文檔案中表示ClickHouse使用ZooKeeper維護後設資料,然而在英文檔案中表示使用ClickHouse Keeper維護後設資料;等等等等。同樣的,你的生產環境的ClickHouse版本也許與ClickHouse最新版有不小差距,所以在你考慮使用某個功能時,記得先看下當前版本是否已經支援。
關於ZooKeeper:
如上所述,ZooKeeper是ClickHouse常見版本的資訊協調者。然而實際上一些行為紀錄檔也會存在其上,表的一些schema資訊也會在上面做校驗。而on cluster等操作也是依賴此實現的,在資料量較大時可能會有一些意外的阻塞情況發生,所以不要太依賴ClickHouse的on cluster等會依賴ZooKeeper的操作,能拿到具體節點的情況下,到每個節點上單獨執行是更穩妥的。作為國內ClickHouse的佈道者,宇宙條已經替大家踩過相關的坑了(當然我們團隊也踩了一次)。
此外ClickHouse本身引擎對子查詢的SQL優化效率不高,應儘量避免複雜的子查詢語句。否則這些」cool cooler coolest」的SQL,在叢集負載壓力逐漸上來之後,可能會變成半夜裡響個不停的業務告警通知。
後記
原本打算從頭到尾細看一遍官方檔案+搜尋對應關鍵詞的文章來完整系統地瞭解一下ClickHouse。但內容之多,懶癌晚期發作加上別的原因最後寫得有些虎頭蛇尾。後面有人看、有心情、有意義再完善吧。。咕咕
最後,本人非資料專業戶(有一說一挺多特性雖然寫了但只雲用過),理解不到位之處,還請大佬『務必回覆!』