深入解析Redis的LRU與LFU演演算法實現
作者:vivo 網際網路伺服器團隊 - Luo Jianxin
重點介紹了Redis的LRU與LFU演演算法實現,並分析總結了兩種演演算法的實現效果以及存在的問題。
一、前言
Redis是一款基於記憶體的高效能NoSQL資料庫,資料都快取在記憶體裡, 這使得Redis可以每秒輕鬆地處理數萬的讀寫請求。
相對於磁碟的容量,記憶體的空間一般都是有限的,為了避免Redis耗盡宿主機的記憶體空間,Redis內部實現了一套複雜的快取淘汰策略來管控記憶體使用量。
Redis 4.0版本開始就提供了8種記憶體淘汰策略,其中4種都是基於LRU或LFU演演算法實現的,本文就這兩種演演算法的Redis實現進行了詳細的介紹,並闡述其優劣特性。
二、Redis的LRU實現
在介紹Redis LRU演演算法實現之前,我們先簡單介紹一下原生的LRU演演算法。
2.1 LRU演演算法原理
LRU(The Least Recently Used)是最經典的一款快取淘汰演演算法,其原理是 :如果一個資料在最近一段時間沒有被存取到,那麼在將來它被存取的可能性也很低,當資料所佔據的空間達到一定閾值時,這個最少被存取的資料將被淘汰掉。
如今,LRU演演算法廣泛應用在諸多系統內,例如Linux核心頁表交換,MySQL Buffer Pool快取頁替換,以及Redis資料淘汰策略。
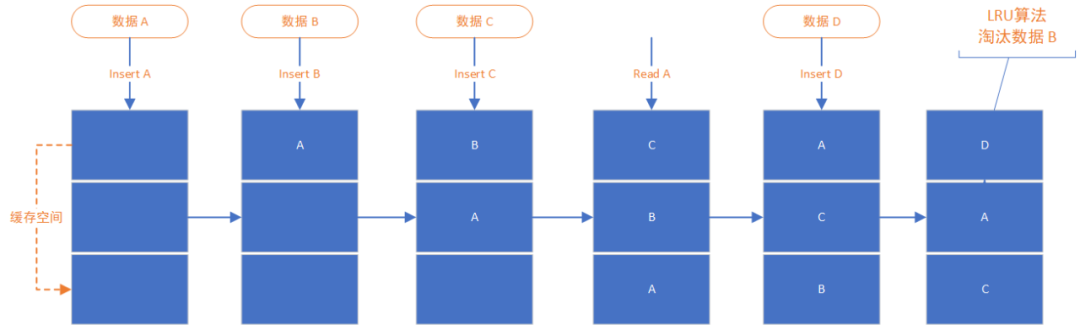
以下是一個LRU演演算法示意圖:
-
向一個快取空間依次插入三個資料A/B/C,填滿了快取空間;
-
讀取資料A一次,按照存取時間排序,資料A被移動到快取頭部;
-
插入資料D的時候,由於快取空間已滿,觸發了LRU的淘汰策略,資料B被移出,快取空間只保留了D/A/C。
一般而言,LRU演演算法的資料結構不會如示意圖那樣,僅使用簡單的佇列或連結串列去快取資料,而是會採用Hash表 + 雙向連結串列的結構,利用Hash表確保資料查詢的時間複雜度是O(1),雙向連結串列又可以使資料插入/刪除等操作也是O(1)。
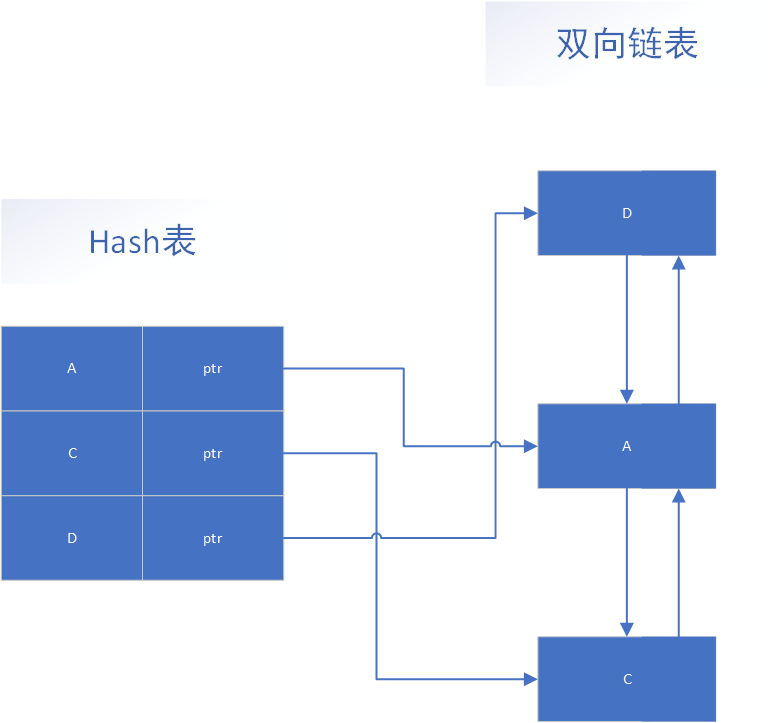
如果你很熟悉Redis的資料型別,你會發現這個LRU的資料結構與ZSET型別OBJ_ENCODING_SKIPLIST編碼結構相似,只是LRU資料排序方式更簡單一些。
2.2 Redis LRU演演算法實現
按照官方檔案的介紹,Redis所實現的是一種近似的LRU演演算法,每次隨機選取一批資料進行LRU淘汰,而不是針對所有的資料,通過犧牲部分準確率來提高LRU演演算法的執行效率。
Redis內部只使用Hash錶快取了資料,並沒有建立一個專門針對LRU演演算法的雙向連結串列,之所以這樣處理也是因為以下幾個原因:
-
篩選規則,Redis是隨機抽取一批資料去按照淘汰策略排序,不再需要對所有資料排序;
-
效能問題,每次資料存取都可能涉及資料移位,效能會有少許損失;
-
記憶體問題,Redis對記憶體的使用一向很「摳門」,資料結構都很精簡,儘量不使用複雜的資料結構管理資料;
-
策略設定,如果線上Redis範例動態修改淘汰策略會觸發全部資料的結構性改變,這個Redis系統無法承受的。
redisObject是Redis核心的底層資料結構,成員變數lru欄位用於記錄了此key最近一次被存取的LRU時鐘(server.lruclock),每次Key被存取或修改都會引起lru欄位的更新。
#define LRU_BITS 24
typedef struct redisObject {
unsigned type:4;
unsigned encoding:4;
unsigned lru:LRU_BITS; /* LRU time (relative to global lru_clock) or
* LFU data (least significant 8 bits frequency
* and most significant 16 bits access time). */
int refcount;
void *ptr;
} robj;預設的LRU時鐘單位是秒,可以修改LRU_CLOCK_RESOLUTION宏來改變單位,LRU時鐘更新的頻率也和server.hz引數有關。
unsigned int LRU_CLOCK(void) {
unsigned int lruclock;
if (1000/server.hz <= LRU_CLOCK_RESOLUTION) {
atomicGet(server.lruclock,lruclock);
} else {
lruclock = getLRUClock();
}
return lruclock;
}由於lru欄位僅佔用了24bit的空間,按秒為單位也只能儲存194天,所以可能會出現一個意想不到的結果,即間隔194天存取Key後標記的時間戳一樣,Redis LRU淘汰策略區域性失效。
2.3 LRU演演算法缺陷
LRU演演算法僅關注資料的存取時間或存取順序,忽略了存取次數的價值,在淘汰資料過程中可能會淘汰掉熱點資料。
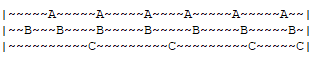
如上圖所示,時間軸自左向右,資料A/B/C在同一段時間內被分別存取的數次。資料C是最近一次存取的資料,按照LRU演演算法排列資料的熱度是C>B>A,而資料的真實熱度是B>A>C。
這個是LRU演演算法的原理性問題,自然也會在Redis 近似LRU演演算法中呈現,為了解決這個問題衍生出來LFU演演算法。
三、Redis的LFU實現
3.1 LFU演演算法原理
LFU(Least frequently used)即最不頻繁存取,其原理是:如果一個資料在近期被高頻率地存取,那麼在將來它被再存取的概率也會很高,而存取頻率較低的資料將來很大概率不會再使用。
很多人看到上面的描述,會認為LFU演演算法主要是比較資料的存取次數,畢竟存取次數多了自然存取頻率就高啊。實際上,存取頻率不能等同於存取次數,拋開存取時間談存取次數就是在「耍流氓」。
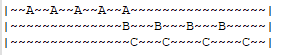
在這段時間片內資料A被存取了5次,資料B與C各被存取了4次,如果按照存取次數判斷資料熱度值,必然是A>B=C;如果考慮到時效性,距離當前時間越近的存取越有價值,那麼資料熱度值就應該是C>B>A。因此,LFU演演算法一般都會有一個時間衰減函數參與熱度值的計算,兼顧了存取時間的影響。
LFU演演算法實現的資料結構與LRU一樣,也採用Hash表 + 雙向連結串列的結構,資料在雙向連結串列內按照熱度值排序。如果某個資料被存取,更新熱度值之重新插入到連結串列合適的位置,這個比LRU演演算法處理的流程複雜一些。
3.2 Redis LFU演演算法實現
Redis 4.0版本開始增加了LFU快取淘汰策略,也採用資料隨機篩選規則,然後依據資料的熱度值排序,淘汰掉熱度值較低的資料。
3.2.1 LFU演演算法程式碼實現
LFU演演算法的實現沒有使用額外的資料結構,複用了redisObject資料結構的lru欄位,把這24bit空間拆分成兩部分去使用。
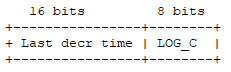
-
由於記錄時間戳在空間被壓縮到16bit,所以LFU改成以分鐘為單位,大概45.5天會出現數值折返,比LRU時鐘週期還短。
-
低位的8bit用來記錄熱度值(counter),8bit空間最大值為255,無法記錄資料在存取總次數。
LFU熱度值(counter)的演演算法實現:
#define LFU_INIT_VAL 5
/* Logarithmically increment a counter. The greater is the current counter value
* the less likely is that it gets really implemented. Saturate it at 255. */
uint8_t LFULogIncr(uint8_t counter) {
if (counter == 255) return 255;
double r = (double)rand()/RAND_MAX;
double baseval = counter - LFU_INIT_VAL;
if (baseval < 0) baseval = 0;
double p = 1.0/(baseval*server.lfu_log_factor+1);
if (r < p) counter++;
return counter;
}-
counter 小於或等於 LFU_INIT_VAL 時候,資料一旦被存取命中, counter接近100%概率遞增1;
-
counter 大於 LFU_INIT_VAL 時候,需要先計算兩者差值,然後作為分母的一部分參與遞增概率的計算;
-
隨著counter 數值的增大,遞增的概率逐步衰減,可能數次的存取都不能使其數值加1;
-
當counter 數值達到255,就不再進行數值遞增的計算過程。
LFU counter的計算也並非「一塵不變」,為了適配各種業務資料的特性,Redis在LFU演演算法實現過程中引入了兩個可調引數:

熱度值counter的時間衰減函數:
unsigned long LFUDecrAndReturn(robj *o) {
unsigned long ldt = o->lru >> 8;
unsigned long counter = o->lru & 255;
unsigned long num_periods = server.lfu_decay_time ? LFUTimeElapsed(ldt) / server.lfu_decay_time : 0;
if (num_periods)
counter = (num_periods > counter) ? 0 : counter - num_periods;
return counter;
}閱讀完以上的內容,是否感覺似曾相似?實際上LFU counter計算過程就是對存取次數進行了數值歸一化,將資料存取次數對映成熱度值(counter),數值的範圍也從[0,+∞)對映到另一個維度的[0,255]。
3.3.2 LFU Counter分析
僅從程式碼層面分析研究Redis LFU演演算法實現會比較抽象且枯燥,無法直觀的呈現counter遞增概率的演演算法效果,以及counter數值與存取次數的關係。
在lfu_log_factor為預設值10的場景下,利用Python實現Redis LFU演演算法流程,繪製出LFU counter遞增概率曲線圖:
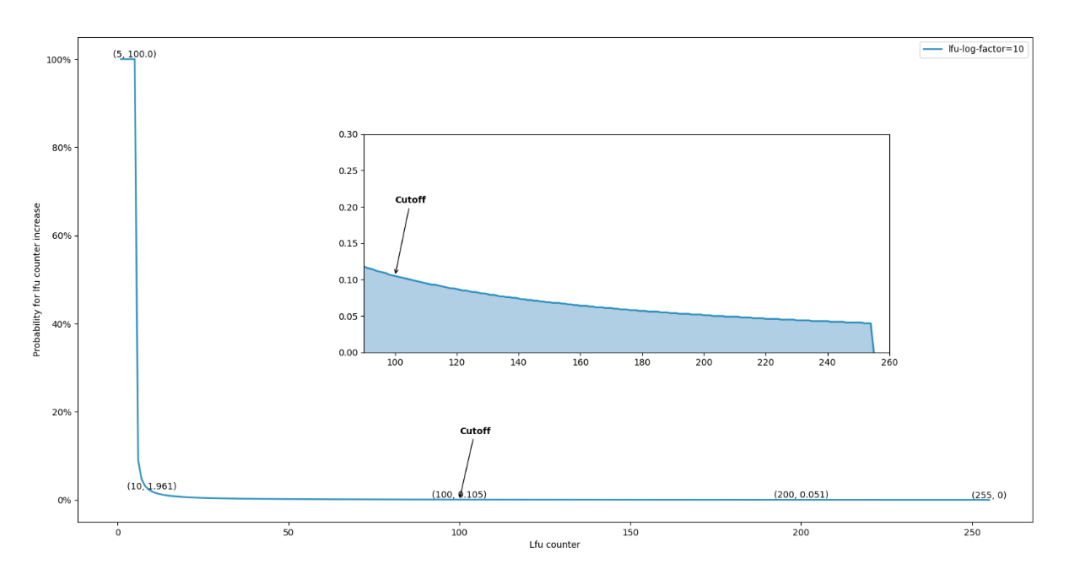
可以清晰的觀察到,當LFU counter數值超過LFU_INIT_VAL之後,曲線出現了垂直下降,遞增概率陡降到0.2%左右,隨後在底部形成一個較為緩慢的衰減曲線,直至counter數值達到255則遞增概率歸於0,貼合3.3.1章節分析的理論。
保持Redis系統設定預設值的情況下,對同一個資料持續的存取,並採集此資料的LFU counter數值,繪製出LFU counter數值曲線圖:
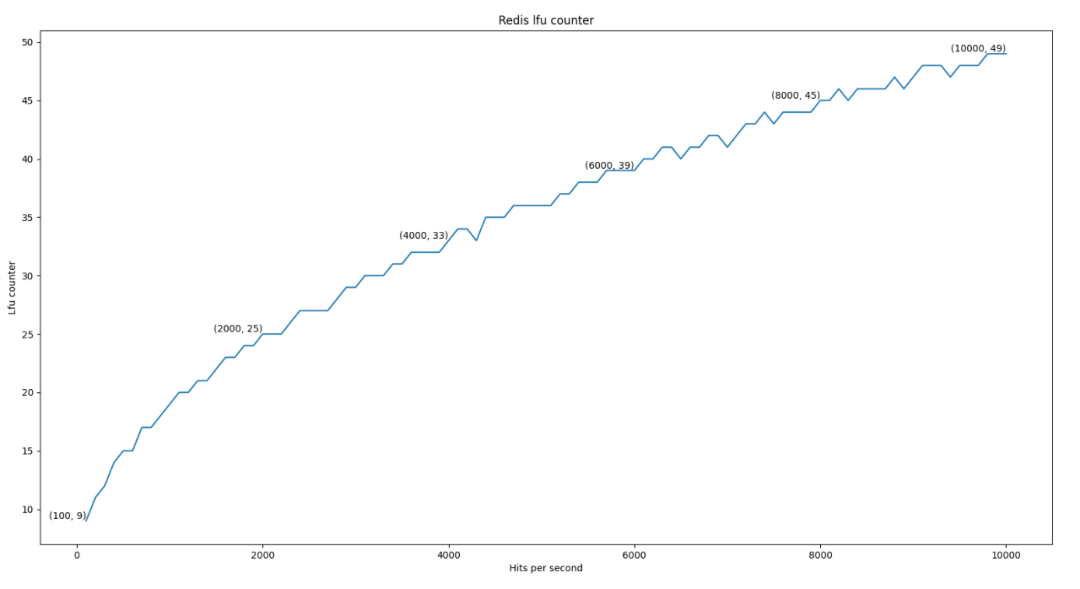
隨著存取次數的不斷增加,LFU counter數值曲線呈現出爬坡式的遞增,形態趨近於根號曲線,由此推測出以下觀點:
-
在存取次數相同的情況下,counter數值不是固定的,大概率在一個範圍內波動;
-
在同一個時間段內,資料之間存取次數相差上千次,才可以通過counter數值區分出哪些資料更熱,而「溫」資料之間可能很難區分熱度。
四、總結
通過對Redis LRU與LFU演演算法實現的介紹,我們可以大體瞭解兩種演演算法策略的優缺點,在Redis運維過程中,可以依據業務資料的特性去選擇相應的演演算法。
如果業務資料的存取較為均勻,OPS或CPU利用率一般不會出現週期性的陡升或陡降,資料沒有體現出相對的「冷熱」特性,即建議採用LRU演演算法,可以滿足一般的運維需求。
相反,業務具備很強時效性,在活動推廣或大促期間,業務某些資料會突然成為熱點資料,監控上呈現出OPS或CPU利用率的大幅波動,為了能抓取熱點資料便於後期的分析或優化,建議一定要設定成LFU演演算法。
在Used_memory接近Maxmemory的情況下,Redis一直都採用隨機的方式篩選資料,且篩選的個數極其有限,所以,LFU演演算法無法展現出較大的優勢,也可能會淘汰掉比較熱的資料。
參考文獻: