使用部分寫時複製提升Lakehouse的 ACID Upserts效能
使用部分寫時複製提升Lakehouse的 ACID Upserts效能
譯自:Fast Copy-On-Write within Apache Parquet for Data Lakehouse ACID Upserts
傳統的寫時複製會直接讀取並處理(解壓解碼等)整個檔案,然後更新相關資料頁並儲存為新的檔案,但大部分場景下,upsert並不會更新所有資料頁,這就導致其做了很多無用功。
文章中引入了一種新的寫時複製,它會建立指向Apache Parquet檔案的資料頁的索引,並跳過不相關的資料頁(不會對這部分資料進行解壓解碼等操作),以此來加速資料的處理。
術語
- copy-on-write:寫時複製
- merge-on-write:讀時合併
概述
隨著儲存表格式的發展,越來越多的公司正在基於Apache Hudi、Apache Iceberg和Delta Lake等工具來構建lakehouse,以滿足多種使用場景,如增量處理。但隨著資料卷的增加,upsert的執行速度可能會帶來一定的影響。
在各種儲存表中,Apache Parquet是其中最主要的檔案格式。下面我們將討論如何通過構建二級索引並對Apache Parquet進行一些創新來提升在Parquet檔案中upsert資料的速度。我們還會通過效能測試來展示相較傳統的Delta Lake和Hudi寫時複製的速度(提升3x~20x倍)。
起因
高效的 ACID upsert 對於今天的lakehouse至關重要,一些重要的使用場景,如資料儲存和Change Data Capture (CDC)嚴重依賴ACID upsert。雖然 Apache Hudi, Apache Iceberg 和 Delta Lake中已經大規模採用了upsert,但隨著資料卷的增加,其執行速度也在降低(特別是寫時複製模式)。有時較慢的upsert會成為消耗時間和資源的點,甚至會阻塞任務的執行。
為了提升upsert的速度,我們在具有行級索引的Apache Parquet檔案中引入了部分寫時複製,以此來跳過那些不必要的資料頁(Apache Parquet中的最小儲存單元)。術語"部分"指檔案中與upsert相關的資料頁。一般場景中只需要更新一小部分檔案,而大部分資料頁都可以被跳過。通過觀察,發現相比Delta Lake和Hudi的傳統寫時複製,這種方式提升了3~20倍的速度。
Lakehouse中的寫時複製
本文中我們使用Apache Hudi作為例子,但同樣適用於Delta Lake和Apache Iceberg。Apache Hudi支援兩種型別的upserts操作:寫時複製和讀時合併。通過寫時複製,所有具有更新範圍內記錄的檔案都將被重寫為新檔案,然後建立包含新檔案的新snapshot後設資料。相比之下,讀時合併會建立增量更新檔案,並由讀取器(reader)進行合併。
下圖給出了一個資料表更新單個欄位的例子。從邏輯的角度看,對User ID1的email欄位進行了更新,其他欄位都沒變。從物理角度看,表資料儲存在磁碟中的單獨檔案中,大多數情況下,這些檔案會基於時間或其他分割區機制進行分組(分割區)。Apache Hudi使用索引系統在每個分割區中定位所需的檔案,然後再完整地進行讀取,更新記憶體中的email欄位,最後寫入磁碟並形成新的檔案。下圖中紅色的部分表示重寫產生的新檔案。
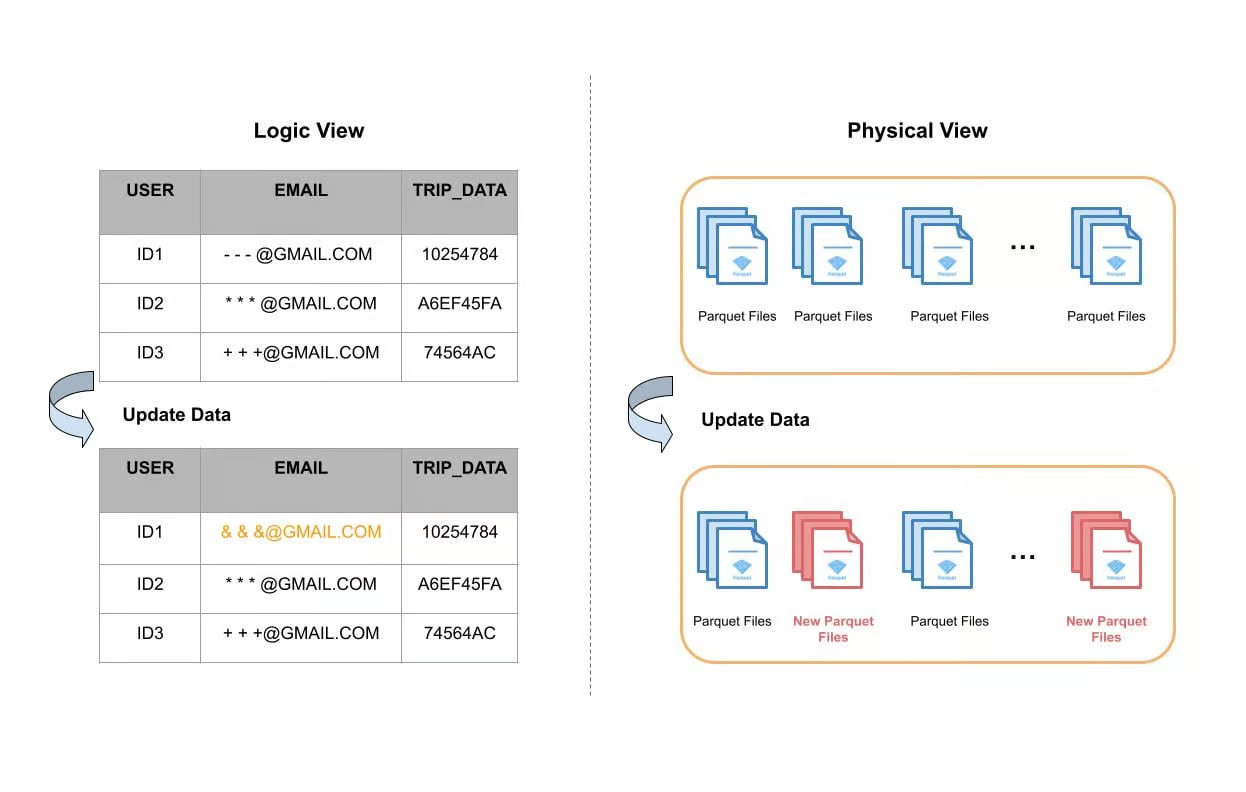
圖1:表upsert的邏輯和物理檔案視角
使用Apache Hudi構建大型事務資料湖一文中提到,一些表更新可能會涉及到90%的檔案,進而導致重寫資料湖中的特定大型表中約100TB的資料。因此寫時複製對於很多使用場景至關重要。較慢的寫時複製不僅會導致任務執行時間變長,還會消耗更多的計算資源。在一些使用場景中可以觀察到使用了相當數量的vCore,等同於花費了上百萬美元。
引入行級別的二級索引
在討論如何在Apache 中提升寫時複製之前,我們打算引入Parquet 行級別的二級索引,用於幫助在Parquet中定位資料頁,進而提升寫時複製。
當首次寫入一個Parquet檔案或通過離線讀取Parquet檔案時會構建行級別的二級索引,它會將record對映為[file, row-id],而不是[file]。例如,可以使用RECORD_ID作為索引key,FILE和Row_IDs分別指向檔案和每個檔案的偏移量。
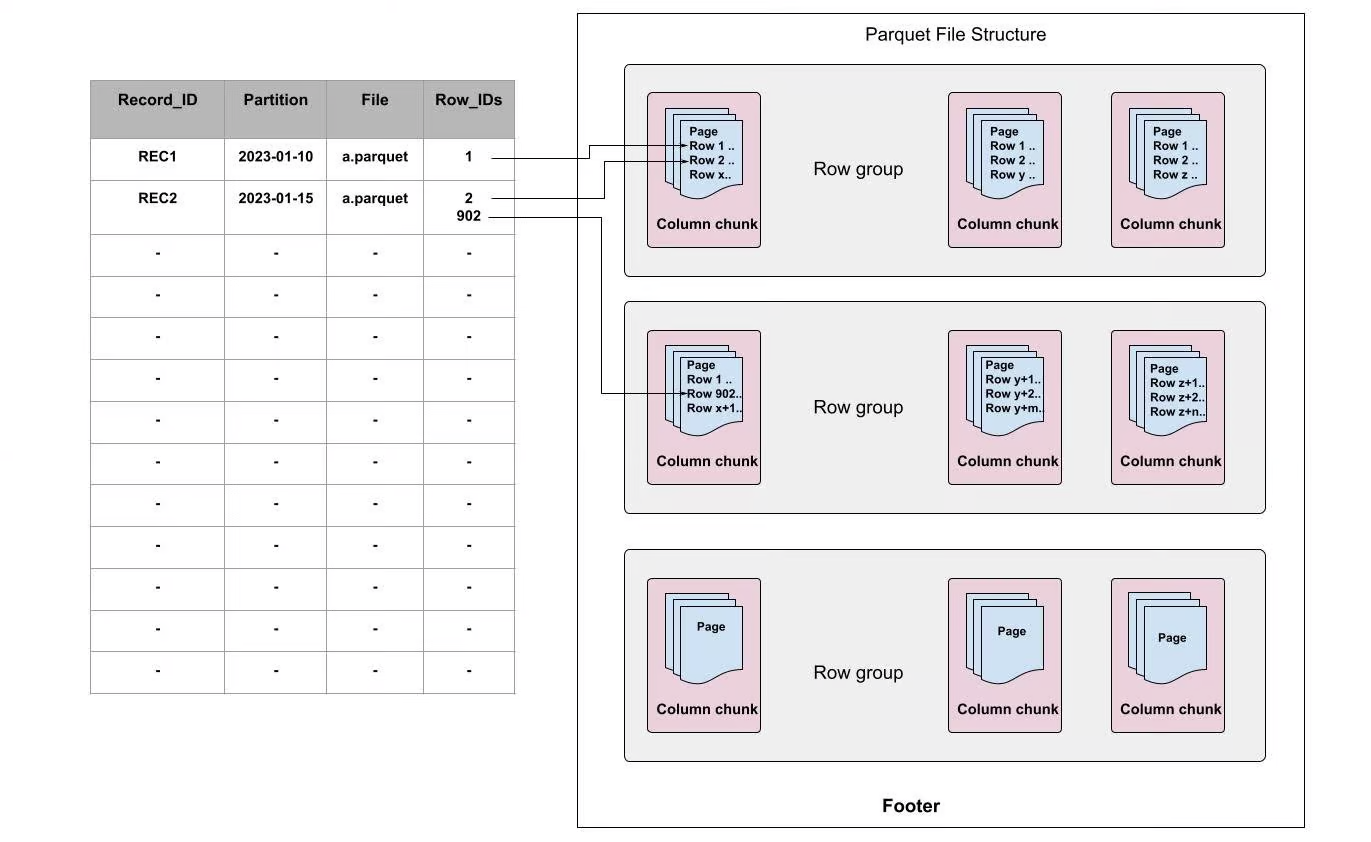
圖2:Apache Parquet中行級別的索引
在Apache Parquet內部,資料被分為多個row groups。每個row group由一個或多個column chunks構成(column chunk對應資料集中的一列),然後每個column chunk 會被寫成資料頁格式。一個block包含多個頁,它是存取單個record前必須讀取的最小單元。在頁內部,除了編碼的目錄頁,每個欄位都追加了值、重複級別和定義級別。
如上圖所示,每個索引都指向頁中record所在的行。使用行級別的索引時,當接收到更新時,我們不僅僅可以快速定位哪個檔案,還可以定位需要更新的資料頁。使用這種方式可以幫助我們跳過不需要更新的頁,並節省大量計算資源,加速寫時複製的過程。
Apache Parquet中的寫時複製
我們在Apache Parquet中引入了一種新的寫時複製方式來加速lakehouse的upserts。我們只對Parquet檔案中相關的資料頁執行寫時複製更新,而對於無關的頁,只是將其複製為位元組快取而沒有做任何更改。這減少了在更新操作期間需要更新的資料量,並提高了效能。
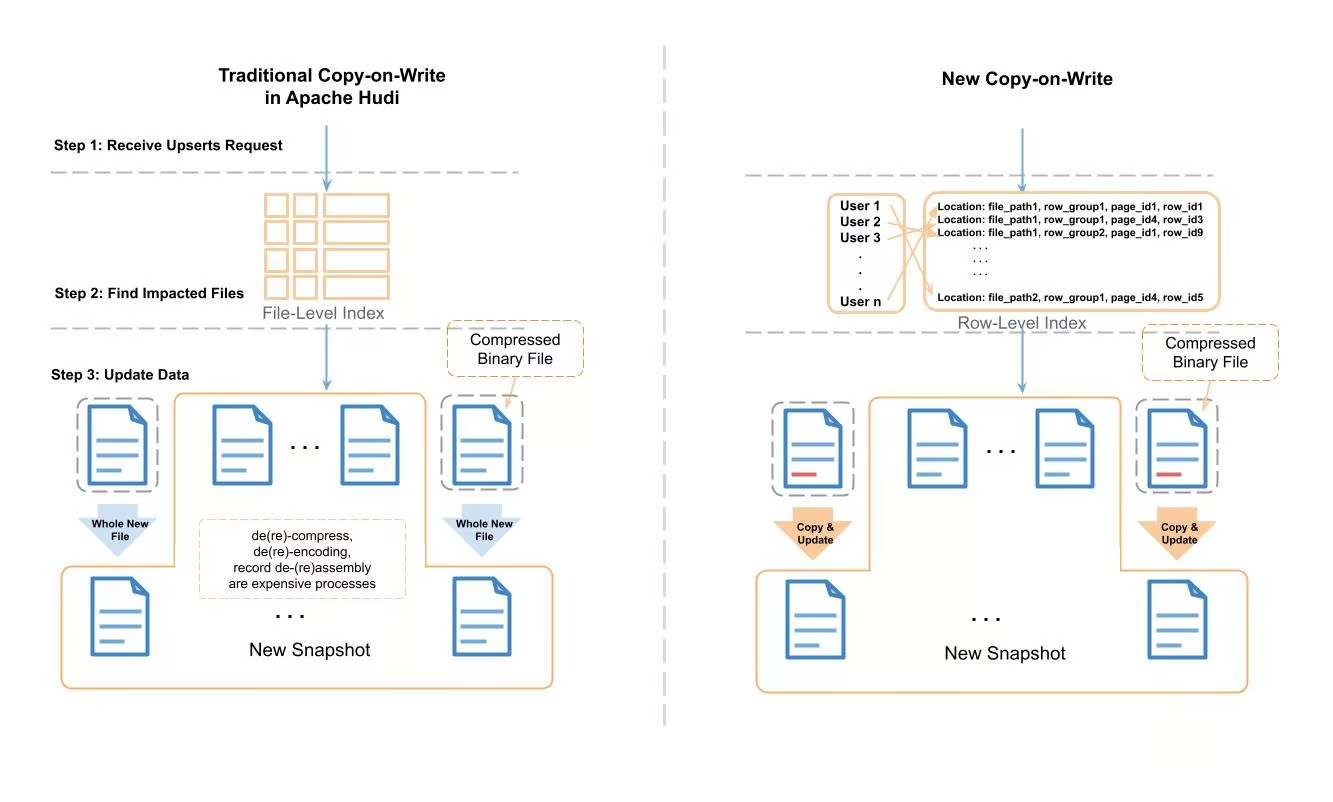
圖3:Apache Hudi傳統寫時複製和新寫時複製的比較
上面展示了新的寫時複製和傳統的寫時複製的處理過程。在傳統的Apache Hudi upsert中,Hudi會使用record 索引 來定位需要修改的檔案,然後一個record一個record地將檔案讀取到記憶體中,然後查詢需要修改的record。在應用變更之後,它會將資料寫入一個全新的檔案中。在讀取-修改-寫入的過程中,會產生消耗大量CPU週期和記憶體的任務(如壓縮/解壓縮,編碼/解碼,組裝/拆分record等)。
為了處理所需的時間和資源消耗,我們使用行級別的索引和Parquet後設資料來定位需要修改的頁,對於不在修改範圍的頁,只需要將其作為位元組快取拷貝到新檔案即可,無需壓縮/解壓縮,編碼/解碼,組裝/拆分record等。我們將該過程稱為"拷貝&更新"。下圖描述了更多細節:
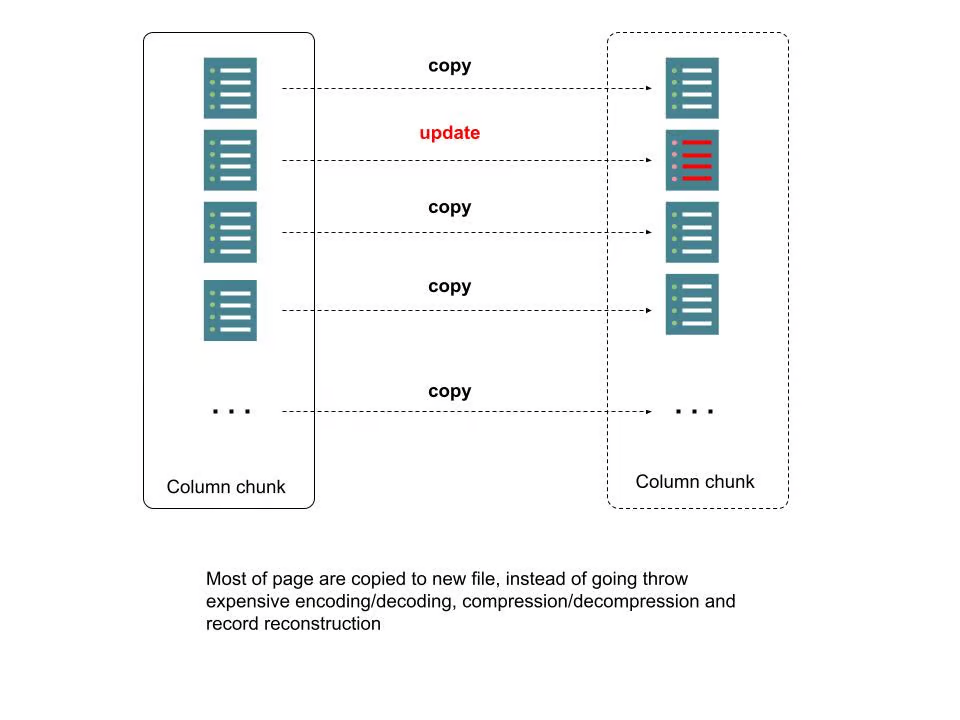
圖4:Parquet檔案中的新寫時複製
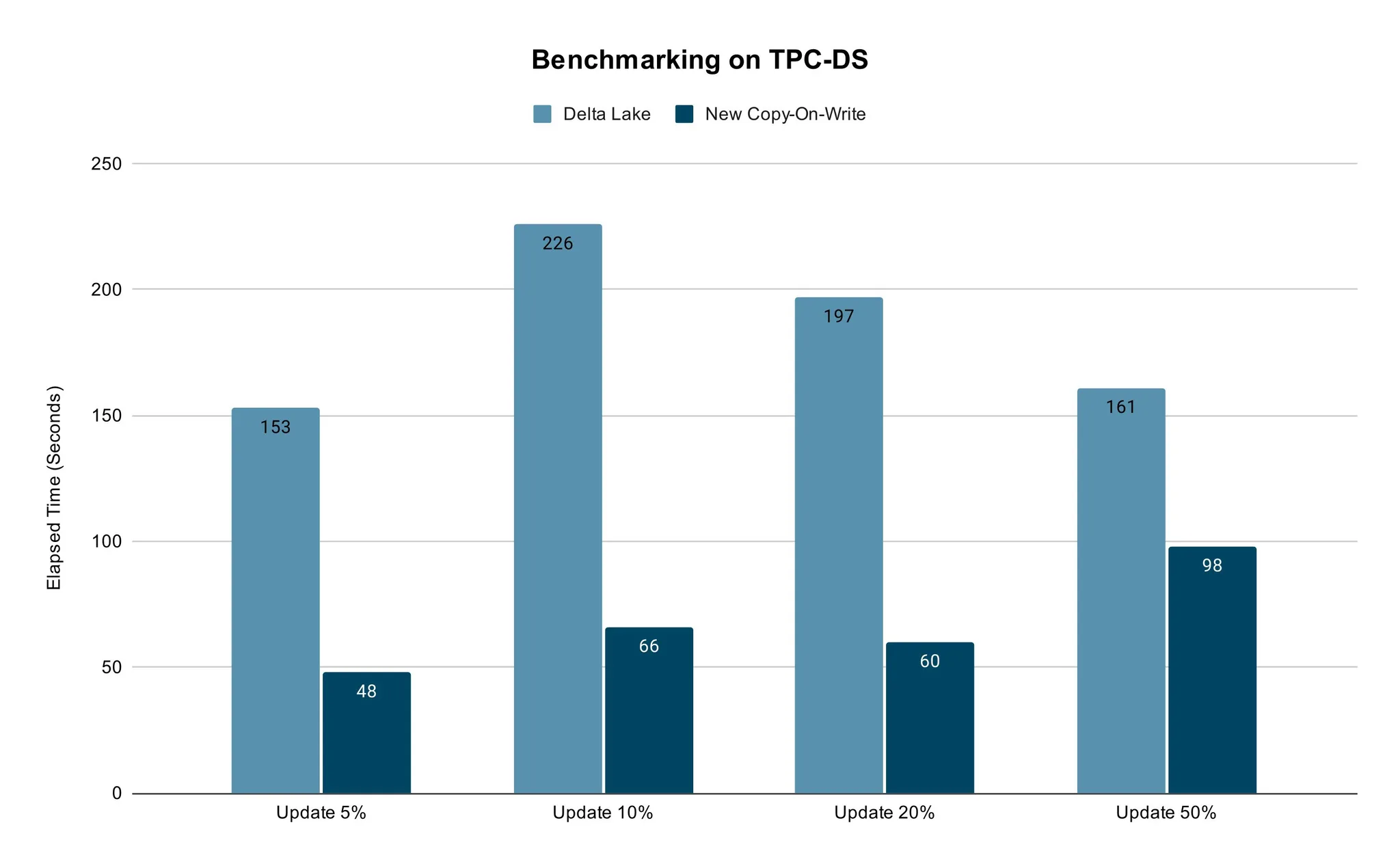
效能測試
我們使用傳統的TPC-DS 資料方式測試比較了新的寫時複製的效能。
我們採用具有相同vCore數量的TPC-DS銷售資料和Spark作業的記憶體設定,並用開箱即用的設定進行了測試。我們對5%~50%的資料進行了更新,然後比較Delta Lake和新的寫時複製所花費的時間。對於真實的使用場景來說,50%的資料更新已經足夠了。
測試結果表明,新方法的更新速度更快。不同百分比資料的更新場景下都能保證其效能優勢。
總結
總之,高效的ACID upserts對今天的lakehouse至關重要。隨著Apache Hudi, Delta Lake 和 Apache Iceberg 的廣泛採納,upserts的慢操作也面臨挑戰,特別是在資料卷不斷擴充套件的情況下。為了解決這個問題,我們在具有行級索引的Apache Parquet檔案中引入了部分寫時複製,以此來跳過對不需要的資料頁的讀寫。在效能測試中展現了明顯的效能優勢。該方法使公司能夠高效地執行資料刪除和CDC,並適用於其他依賴於lakehouse中高效表更新的場景。
本文來自部落格園,作者:charlieroro,轉載請註明原文連結:https://www.cnblogs.com/charlieroro/p/17527915.html