盤點!國內隱私計算學者在 USENIX Security 2023 頂會上的成果

USENIX Security 是國際公認的網路安全與隱私計算領域的四大頂級學術會議之一、CCF(中國計算機學會) 推薦的 A 類會議。
每年的 USENIX Security 研討會都會彙集大量研究人員、從業人員、系統管理員、系統程式設計師和其他對計算機系統、網路安全和隱私最新進展感興趣的人。
近日,在 2023 年 USENIX 安全研討會(USENIX Security Symposium-2023)上,共計發表了隱私計算相關文章 51 篇,涉及聯邦學習、同態加密、安全多方計算等多個隱私計算領域,作為網路安全與隱私計算領域的頂級會議,它的錄取率常年低於 20%。
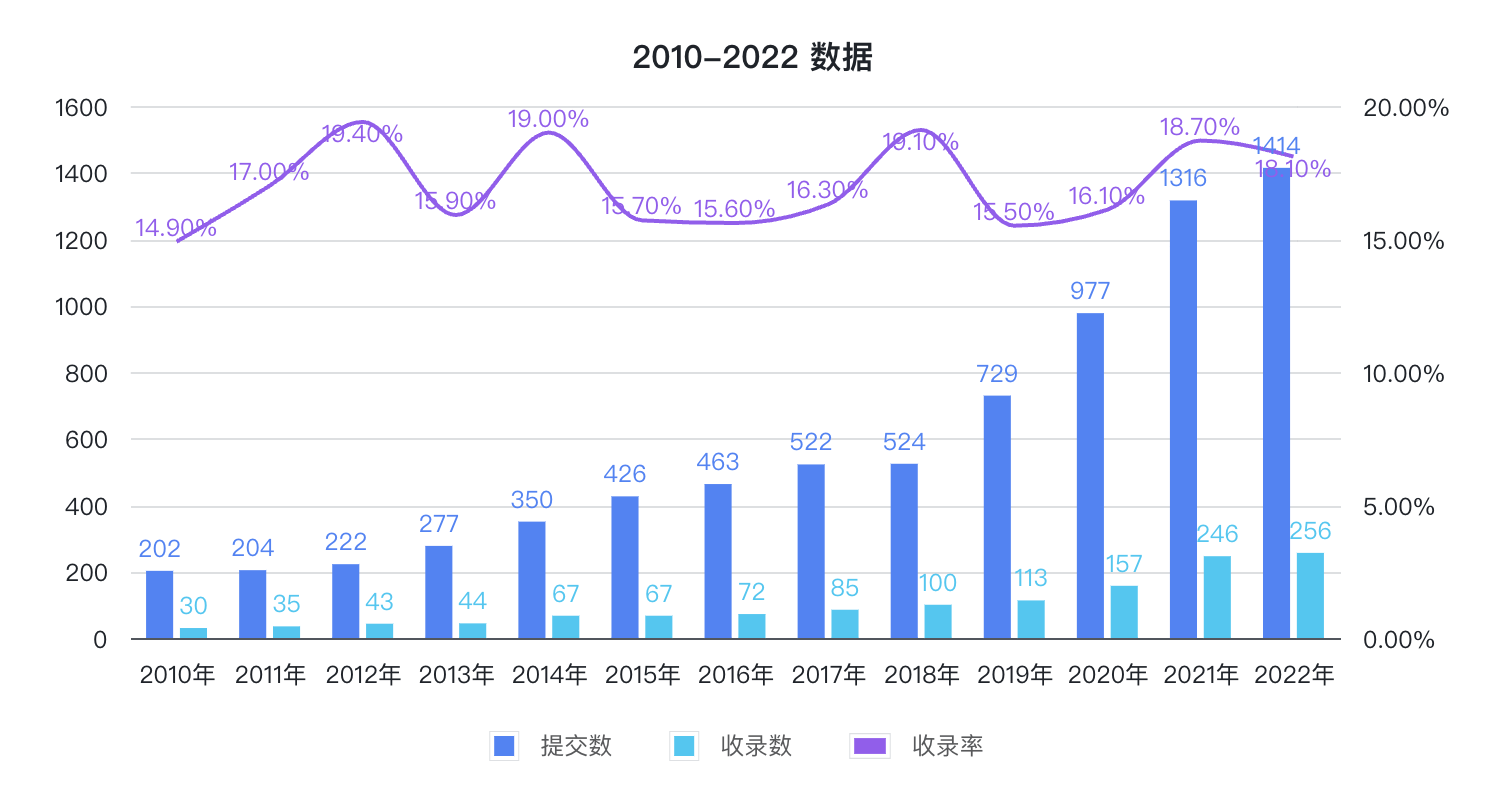
今年的會議上國內學者貢獻了非常多的優秀成果,我們選取幾個熱門領域來簡單盤點一下。
一、成果領域分佈
| 成果領域 | 入選篇數 | 國內研究者參與優秀成果 |
|---|---|---|
| 差分隱私(DP) | 3 | Fine-grained Poisoning Attack to Local Differential Privacy Protocols for Mean and Variance Estimation (第一作者:西安電子科技大學) |
| 可信執行環境(TEE) | 4 | CIPHERH: Automated Detection of Ciphertext Side-channel Vulnerabilities in Cryptographic Implementations(第一作者:南方科技大學,其他成員來自香港科技大學、螞蟻集團) Controlled Data Races in Enclaves: Attacks and Detection (第三作者:南方科技大學) |
| 聯邦學習(FL) | 3 | Gradient Obfuscation Gives a False Sense of Security in Federated Learning (第二作者:浙江大學) |
| 零知識證明(ZK) | 2 | TAP: Transparent and Privacy-Preserving Data Services (第三作者:西南大學) |
| 同態加密(HE) | 3 | Squirrel: A Scalable Secure Two-Party Computation Framework for Training Gradient Boosting Decision Tree (全員來自阿里巴巴集團和螞蟻集團) |
| 隱私集合計算(PSU) | 3 | Linear Private Set Union from Multi-Query Reverse Private Membership Test (全員來自中國科學院資訊工程研究所資訊保安國家重點實驗室、中國科學院大學、山東大學、密碼科學技術國家重點實驗室、阿里巴巴集團) |
| 隱私資料分析 | 8 | Lalaine: Measuring and Characterizing Non-Compliance of Apple Privacy Labels (第四作者:阿里巴巴集團獵戶座實驗室) |
| AI 隱私增強 | 3 | V-CLOAK: Intelligibility-, Naturalness- & Timbre-Preserving Real-Time Voice Anonymization (成員來自浙江大學與武漢大學) |
二、熱門領域盤點
注:因為篇幅有限,本文只列舉了國內學者優秀成果的一部分內容。
2.1 差分隱私(DP)
- 論文:Fine-grained Poisoning Attack to Local Differential Privacy Protocols for Mean and Variance Estimation
- 中文:用於均值和方差估計的區域性差分隱私協定的細粒度中毒攻擊
- 國內研究者:西安電子科技大學(第一作者)
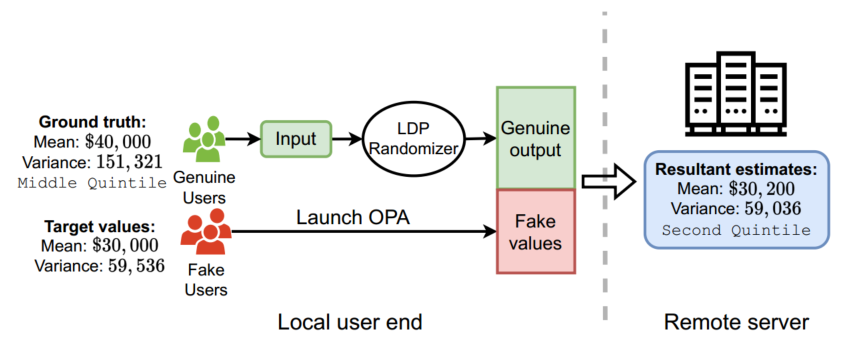
儘管區域性差異隱私(LDP)保護個人使用者的資料不受不可信資料管理員的推斷,但最近的研究表明,攻擊者可以從使用者端發起資料中毒攻擊,將精心製作的虛假資料注入 LDP 協定,以最大限度地扭曲資料管理員的最終估計。
在這項工作中,研究團隊通過提出一種新的細粒度攻擊來進一步推進這一知識,該攻擊允許攻擊者微調並同時操縱均值和方差估計,這是許多現實世界應用程式中流行的分析任務。(威脅現實世界大量實際應用程式資料安全)
為了實現這一目標,該攻擊利用 LDP 的特性將假資料注入本地 LDP 範例的輸出域。稱為輸出中毒攻擊(OPA)。
研究者觀察到較小的隱私損失增強了 LDP 的安全性,實現了安全隱私的一致性,這與先前工作中已知的安全隱私權衡相矛盾。(突破已有研究,發現新結論)
研究者進一步研究了一致性,並揭示了 LDP 資料中毒攻擊的威脅格局的更全面的觀點,針對直觀地向 LDP 提供錯誤輸入的基線攻擊來全面評估新提出的攻擊。
實驗結果表明,在三個真實世界的資料集上,OPA 優於基線。研究者還提出了一種新的防禦方法,可以從汙染的資料收集中恢復結果的準確性,併為安全的 LDP 設計提供了見解。(在給出攻擊方法的同時,提供了有效的防禦方法)
2.2 可信執行環境(TEE)
- 論文:CIPHERH: Automated Detection of Ciphertext Side-channel Vulnerabilities in Cryptographic Implementations
- 中文:CIPHERH-密碼實現中密文側通道漏洞的自動檢測
- 國內研究者:南方科技大學(第一作者)

密文側通道是一種新型的側通道,利用可信執行環境(TEE)的確定性記憶體加密。它使對手能夠從邏輯上或物理上讀取加密記憶體的密文,從而以高保真度破壞由TEE保護的加密實現。
先前的研究得出結論,密文側通道不僅對首次發現該漏洞的 AMD SEV-SNP 有效,而且對所有具有確定性記憶體加密的TEE都是嚴重威脅。
在本文中,研究者提出了 CIPHERH,這是一個實用的框架,用於自動分析加密軟體和檢測易受密文側通道攻擊的程式點。(提出自動化的側通道攻擊檢測框架)
CIPHERH 設計用於在生產密碼軟體中執行實用的混合分析,具有快速的動態汙點分析以跟蹤整個程式中祕密的使用情況,以及對每個「汙點」函數的靜態符號執行過程,並使用符號約束來推斷密文側通道漏洞。
通過經驗評估,從 OpenSSL、MbedTLS 和 WolfSSL 的最先進的 RSA 和 ECDSA/EDCH 實現中發現了 200 多個易受攻擊的程式點。有代表性的案例已經報告給開發商,並由開發商確認或修補。(在實際產品中發現大量攻擊風險)
2.3 聯邦學習(FL)
- 論文名稱:Gradient Obfuscation Gives a False Sense of Security in Federated Learning
- 中文:梯度混淆在聯邦學習中給人一種虛假的安全感
- 國內研究者:浙江大學(第二作者)
聯邦學習已被提議作為一種保護隱私的機器學習框架,使多個使用者端能夠在不共用原始資料的情況下進行共同作業。然而,在此框架中的設計並不能保證使用者端隱私保護。
先前的工作表明,聯合學習中的梯度共用策略可能容易受到資料重建攻擊。然而,在實踐中,考慮到高通訊成本或由於隱私增強要求,使用者端可能不傳送原始梯度。

經驗研究表明,梯度模糊處理,包括通過梯度噪聲注入的有意模糊處理和通過梯度壓縮的無意模糊處理,可以提供更多的隱私保護,防止重建攻擊。
在這項工作中,研究者針對聯邦學習中的影象分類任務提出了一種新的重建攻擊框架。研究者展示了常用的梯度後處理程式,如梯度量化、梯度稀疏化和梯度擾動,在聯邦學習中可能會給人一種虛假的安全感。(證明了已有防護防護手段失效)
與先前的研究相反,研究者認為隱私增強不應被視為梯度壓縮的副產品。此外,研究者在所提出的框架下設計了一種新的方法來在語意層面重建影象。研究者量化了語意隱私洩露,並將其與傳統的影象相似性得分進行了比較。研究者的比較挑戰了文獻中的影象資料洩漏評估方案。研究結果強調了重新審視和重新設計現有聯合學習演演算法中使用者端資料隱私保護機制的重要性。(凸顯了設計針對聯邦學習使用者端新的資料隱私保護機制的重要性)
2.4 零知識證明(ZK)
- 論文名稱:TAP: Transparent and Privacy-Preserving Data Services
- 中文:透明和保護隱私的資料服務
- 國內研究者:西南大學(第三作者)
如今,使用者期望處理其資料的服務提供更高的安全性。除了傳統的資料隱私和完整性要求外,他們還期望透明度,即服務對資料的處理可由使用者和可信的審計員進行驗證。研究者的目標是構建一個多使用者系統,為大量操作提供資料隱私、完整性和透明度,同時實現實際效能。(強調隱私計算的使用者透明度屬性)
為此,研究者首先確定使用經過身份驗證的資料結構的現有方法的侷限性。研究者發現它們分為兩類:
- 向其他使用者隱藏每個使用者的資料,但可驗證操作範圍有限的操作(例如CONIKS、Merkle2 和責任證明)
- 支援廣泛的可驗證操作,但使所有資料公開可見的操作(如 IntegridDB 和 FalconDB)
然後,研究者提出 TAP 來解決上述限制。TAP的關鍵元件是一種新穎的樹資料結構,它支援有效的結果驗證,並依賴於使用零知識範圍證明的獨立審計,以表明樹是正確構建的,而不會洩露使用者資料。
TAP 支援廣泛的可驗證操作,包括分位數和樣本標準差。研究者對 TAP 進行了全面評估,並將其與兩個最先進的基線(即 IntegridDB 和 Merkle2)進行了比較,表明該系統在規模上是實用的。(相比最先進的基線模型,提出的方案是可行的)
2.5 同態加密(HE)
- 論文名稱:Squirrel: A Scalable Secure Two-Party Computation Framework for Training Gradient Boosting Decision Tree
- 中文:一種可延伸且安全的訓練梯度提升決策樹的兩方計算框架
- 國內研究者:全員來自阿里巴巴集團和螞蟻集團

梯度提升決策樹(GBDT)及其變體由於其強大的可解釋性而在工業中得到廣泛應用。安全多方計算允許多個資料所有者聯合計算一個函數,同時保持他們的輸入私有。
在這項工作中,研究團隊提出了 Squirrel,這是一個基於垂直分割資料集的兩方 GBDT 訓練框架,其中兩個資料所有者各自擁有相同資料樣本的不同特徵。Squirrel 對半誠實的對手是保密的,在訓練過程中不會透露任何敏感的中間資訊。
Squirrel 還可以擴充套件到具有數百萬樣本的資料集,即使在廣域網(WAN)下也是如此。(支援廣域網下的百萬樣本模型訓練)
Squirrel 通過 GBDT 演演算法和高階密碼學的幾種新穎的聯合設計實現了其高效能。
-
提出一種新的高效機制,使用不經意轉移來隱藏每個節點上的樣本分佈 (全新的高效節點分佈隱藏機制)
-
提出一種使用基於格的同態加密(HE)的梯度聚合的高度優化方法,比現有的同態計算方法快三個數量級。(超越現有方法多個數量級)
-
提出一種新的協定來評估祕密共用值上的 sigmoid 函數,比現有的兩種方法改進了 19 倍-200 倍。
結合所有這些改進,Squirrel 在具有 5 萬個樣本的資料集上每棵樹的成本不到 6 秒,比 Pivot(VLDB 2020)高出 28 倍以上。研究者還表明,Squirrel 可以擴充套件到具有超過一百萬個樣本的資料集,例如,在 WAN 上每棵樹大約 90 秒。(2min 以內完成百萬樣本資料集生成單決策樹)
2.6 隱私集合計算(PSU)
- 論文名稱:Linear Private Set Union from Multi-Query Reverse Private Membership Test
- 中文:多查詢反向私有成員測試中的線性私有集並集
- 國內研究者:全員來自中國科學院資訊工程研究所資訊保安國家重點實驗室、中國科學院大學、山東大學、密碼科學技術國家重點實驗室、阿里巴巴集團
專用集並集(PSU)協定使雙方(各自持有一個集)能夠在不向任何一方透露任何其他資訊的情況下計算其集的並集。
到目前為止,有兩種已知的方法來構建 PSU 協定。
- 第一種:主要依賴於加性同態加密(AHE),這通常是低效的,因為它需要對每個專案執行非恆定數量的同態計算。
- 第二種:主要基於 Kolesnikov 等人最近提出的遺忘轉移和對稱金鑰操作(ASIACRYPT 2019)。
第二種具有良好的實用效能,比第一個快幾個數量級。然而,這兩種方法都不是最優的,因為它們的計算和通訊複雜性都不是 O(n),其中 n 是集合的大小。因此,構建最優PSU協定的問題仍然懸而未決的問題。(雖然已有一些方案,但是都會隨著集合的擴大帶來較大開銷,不滿足實際需求)
在這項工作中,研究團隊通過提出一個來自遺忘傳輸的 PSU 通用框架和一個新引入的稱為多查詢反向私有成員身份測試(mq-RPMT)的協定來解決這個開放問題。研究者提出了 mq-RPMT 的兩種通用構造。
- 第一種:基於對稱金鑰加密和一般的 2PC 技術。
- 第二種:基於可重新隨機化的公鑰加密。
這兩種結構都導致 PSU 具有線性計算和通訊複雜性。(設計了線性複雜度的方案,突破原本的複雜度限制)
研究團隊實現了兩個 PSU 協定,並將它們與最先進的 PSU 進行了比較。實驗表明,研究團隊的基於 PKE 的協定在所有方案中具有最低的通訊能力,根據集合大小的不同,通訊能力降低了 3.7−14.8 倍。根據網路環境的不同,研究團隊的 PSU 方案的執行時間比最先進的方案快 1.2−12 倍。(實驗證明,通訊能力最大提升 14 倍,執行時間快 12 倍)
三、最後
恭喜上述國內研究團隊在隱私計算頂會上「露臉」,同時也說明隱私計算技術正在逐漸從理論方法走向實際應用,充分利用隱私計算技術可以在滿足隱私保護需求的同時,順應資料要素流通的發展趨勢,助力數位經濟健康發展。中國的學術界和工業界將繼續深入合作,打造更好的優質隱私計算產品,實現資料「可用不可見、可用不可存、可控可計量」的安全流通,助力數位中國健康發展。
PrimiHub 一款由密碼學專家團隊打造的開源隱私計算平臺。我們專注於分享資料安全、密碼學、聯邦學習、同態加密等隱私計算領域的技術和內容。