prometheus描點原理
大家好,我是藍胖子,關於prometheus的入門教學有很多,拿我之前學prometheus的經歷來講,看了很多教學,還是會對prometheus的描點以及背後的統計原理感到迷惑,所以今天我們就來分析下這部分,來揭開其神祕的面紗。
我們先來看看prometheus裡的資料模型是怎麼樣的,只有知道了資料結構,才能理解對後續這些資料如何描點,如何計算出相應指標值。
資料模型
prometheus中存的是時序資料,時序資料有個特點是每條資料都有一個時間戳,並且時序資料都有一個metric_name(指標名),和一系列的label,以及當前指標的值value。當用prometheus web控制檯查詢出來的就是一條條時序資料,如下圖所示:

時序資料描述一個指標的表示式可以歸納為:
metric_name{label_name1=label_val1,label_name2=label_val2,....}
表示式開頭是指標名,{}裡的就是指標的標籤。
在prometheus中,如果指標名和標籤完全相同,那麼將會認為他們是同一個指標,將一個指標不同時間戳的時序資料稱為指標的樣本。
這裡要特別明確一點,用過prometheus 使用者端的同學都知道prometheus有四大指標型別Counter,Guage,Histogram,Summary,但無論是哪種指標型別在prometheus伺服器端這邊都是按照上述的指標格式進行儲存的,prometheus server在儲存時並不會去存特定某個指標是什麼指標型別。
理解了prometheus server儲存資料的型別,我們再來看看對prometheus server 進行查詢時的資料返回型別。
prometheus server提供了兩個api對外提供查詢,分別是query 和query_range ,在prometheus中 用vector 型別表示單個時間點的指標資料,用matrix 表示一組時間點的指標資料。所以query_range api只能返回matrix 型別的資料。我們用prometheus web控制檯演示下。
首先來看下在table列進行查詢時涉及的查詢,在table列進行查詢會呼叫到query 的api,其返回結果既可以是matrix 型別,也可以是vector 型別。

如上圖所示,查詢返回的是vector型別的資料 , 我們在table這一欄輸入PromQl查詢語句,預設是查出當前時間最新的指標,可以看到返回的result是一個陣列,因為匹配查詢語句的不止一個指標,接著返回了指標的時間戳以及對應的值val。
在table這一列除了查詢某個指標的瞬時值,還可以查某段時間內的值,對應的prometheus server api的返回型別就將是matrix型別了 ,如下圖所示,我們可以修改PromQl語句讓其查1m內的資料:

如上圖所示,將查詢語句改為go_memstats_other_sys_bytes{}[1m] 後返回的就是matrix型別的資料了,它表示一組時間點的資料。
其實看到這裡,你應該能想到,prometheus繪圖就是根據matrix型別的資料進行描點繪圖的 。
描點原理
緊接著,我們就來看下prometheus的描點繪圖原理。
首先要明確一點,繪圖的原理本質上就是在一個個時間片段裡進行描點,然後再將各個點連起來就形成了隨時間變化的監控圖Graph。所以在描點繪圖時,用到的資料查詢結果僅僅只能是matrix型別,因為只有它才能表示一個指標一組時間點的樣本值。
我們再回顧下matrix資料格式是怎樣的,
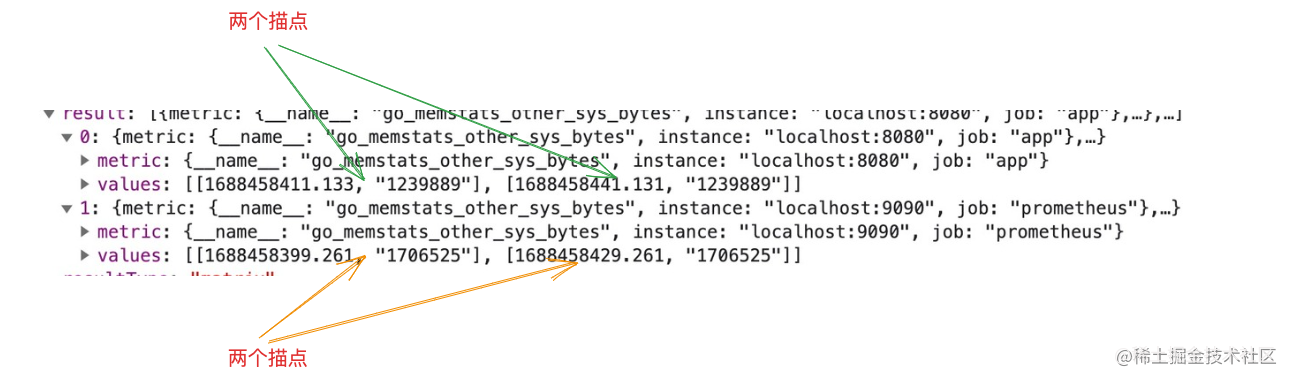
matrix資料格式的返回,每個指標都會攜帶一組時間點的樣本,到時候描點時就是根據這些樣本點的時間點為橫座標,樣本的值為縱座標進行繪圖的。
接著,我們來看下繪圖用到的查詢資料api, 和在table欄進行查詢不同,在繪圖介面查詢資料用到的api是query_range ,query_range返回的資料格式是matrix 型別的資料
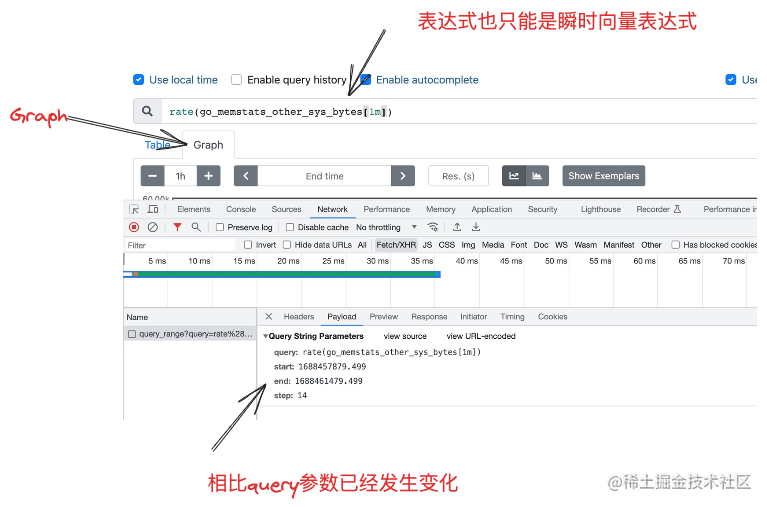
注意下query_range的引數,已經和query不同了,因為query畢竟只查基於某個時間點的資料,而query_range是查某段時間的資料,所以query_range有個開始時間start和結束時間end,除此以外,它還有個引數step,這個引數是表示將start和end之間的時間段按step步長分割為更小的時間段,然後在每個小的時間段內將會產生一個描點 。最後就是將指標的描點全部連線起來就是一個曲線了。
描點是如何計算出來的
知道了在每個小的時間段內,prometheus會產生一個描點,我們還需要知道描點究竟是如何計算出來的。
拿截圖的表示式rate(go_memstats_other_sys_bytes[1m]) 舉例,假設時間區間[start,end]被step分成了3小段。
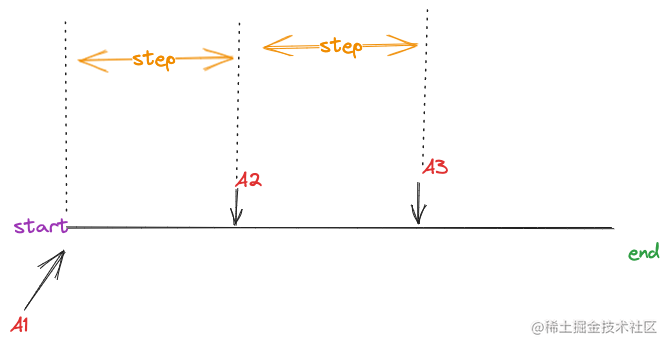
如上圖,其中每段的開始時間戳分別是A1,A2,A3,按step進行累加,這3個小的時間段將會產生3個描點,每個描點計算規則如下:
val=rate函數(當前時間段與當前時間段減去1m這段時間內的所有樣本)
每個描點,都會執行一次rate函數得到描點的value值,描點的時間戳則是每個小的時間段開始的時間,而計算的樣本則是 每個小的時間段開始時間到 之前的1m的時間範圍內篩選出來的。
histogram_quantile 表示式如何描點的?
上面的描點例子比較簡單,我們來看一個複雜點的,這個也是Histogram 指標型別統計的原理。
如下,我們通常會用到histogram_quantile去計算服務介面時間的耗時情況。
histogram_quantile(0.99,rate(server_handle_seconds_bucket{}[1m]))
它描點的邏輯依然逃不開 將一個大的時間段分為小的時間段,並且每個小的時間段產生描點。也就是說,每個小的時間段也都會執行一次histogram_quantile 函數得到描點值,但histogram_quantile的樣本值從哪裡得來呢?
是在小的時間段內通過rate函數計算得到的,rate函數的樣本來源也和剛才講的一樣,是當前時間段與當前時間段減去1m這段時間內的所有樣本。
思考題
這樣的確得到了3個描點,能繪製出曲線來,但最開始我在看到這個表示式還是很疑惑的,因為它將之前的每個直方圖的指標都進行了rate計算,這樣在用histogram_quantile計算最終分位數的時候不會導致結果變化嗎?這就涉及到了histogram_quantile計算分為數的邏輯,有空我會在下篇文章繼續分析。