基於詞袋(Bag of Words)和SVM的圖片分類
摘要
雖然現在已經是深度學習的時代了,傳統的機器學習方法日漸甚微,不過有些演演算法還是有著旺盛的生命力,比如SIFT、SVM,在一些深度學習演演算法中也能看到它們的影子。這些人工設計的經典特徵和分類器可以讓我們感受到那個時代計算機視覺的魅力。網際網路上,需要處理識別的影象越來越多,為此影象分類搜尋引擎所需的分類能力要求越來越高,在影象處理領域內也成為越來越熱點的課題。對目標進行分類是人類的天生能力,對於計算機,現實世界的呈現方式大多是以圖片的方式(視訊本質上也是圖片)輸入,因而圖片的分類是實現人工智慧的重要部分。詞袋模型是基於自然語言模型而提出的一種檔案描述方法,被廣泛研究用於影象的分析和處理中。本文介紹了一種基於詞袋的圖片分類方法,首先提取圖片的SIFT特徵通過聚類得到「視覺詞典」,然後統計詞頻獲得突破的詞袋描述,最後通過SVM進行有監督的圖片分類。
原始碼及完整報告:
演演算法使用C++ MFC實現,基於OpenCV。
https://mbd.pub/o/bread/ZJuTlZ5u 或
https://www.syjshare.com/res/1TUR49UG
詞袋(Bag of Words, BoW)
在圖片的分類中首先需要解決的是對影象的描述,最初對影象的描述是直接利用圖片的顏色資訊,但是影象的色彩往往隨著光強,物體方向等變化而變化,因此魯棒性很差。現在的方式是在圖片中提取能夠表徵圖片全域性或區域性的特徵作為對影象的描述,從而使得得到的影象描述具有光照不變性、旋轉不變性、尺度不變性等特性。然而這種直接基於影象底層基礎上的特徵不含有語意資訊,無法完成對影象生成語意的理解。而基於詞袋的影象描述則在一定程度上解決了這一問題。
詞袋模型最先是由Josef等基於自然語言處理模型而提出的。在這種模型中,文字(段落或者檔案)被看作是無序的詞彙集合,忽略語法甚至是單詞的順序。詞袋模型的原理非常簡單,詞袋模型是文字的簡化描述模型。在此模型中, 文字\(x_{1} ,x_{2},x_{3}\) 被表達成無序的單詞組合,不去考慮語法與詞序。以文字為例,如果一個文字\(X\)表示一連串有順序的詞的排列,那麼機器對於\(X\)的識別其實就是計算出它在所有文字詞語中出現的可能,也就是概率為多個詞語概率的相乘如\(p(X)=p(x_{1})*p(x_{2}|x_{1})*p(x_{3}|x_{2})...p(x_{n}|x_{n-1})\),而詞袋模型就是這種文字模型的特例,即\(x_{k}\) 出現的概率與前面的文字無關,故有\(p(X)=p(x_{1})*p(x_{2})*...p(x_{n})\) 成立。
類比一篇文章由很多文字 (textual words) 組合而成,如果將一張圖片表示成由許多 視覺單詞(visual words) 組合而成,就能將過去在文字檢索(text retrieval)領域的技巧直接利用在影象檢索(image retrieval)中,以文字檢索系統現在的效率,影象表示的「文字化」也有助於大規模(large-scale)影象檢索系統的效率。
詞袋模型中關鍵的一步是要生成詞典,對圖片來說即是要生成「視覺詞典」,而這首先需要提取圖片的特徵形成圖片特徵描述子集合,然後通過聚類的方式形成視覺單詞,從而形成視覺詞典。再統計待分類圖片的詞頻,通過分類器即可實現對圖片的分類或高階語意的理解。
基於詞袋模型的圖片分類基本流程
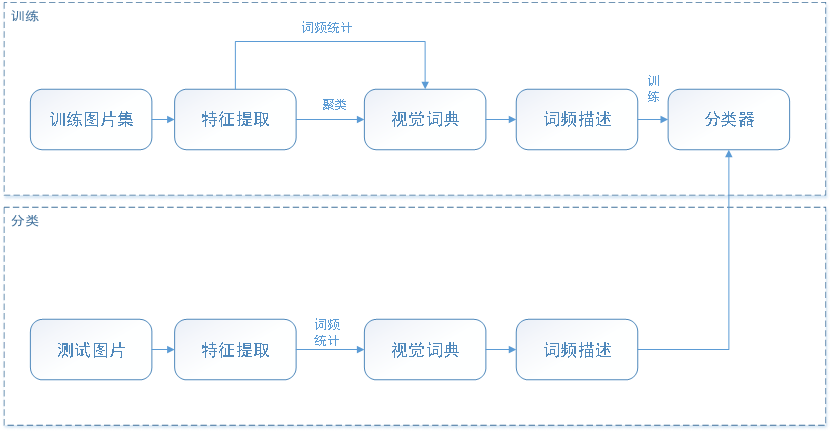
如引言所述,基於詞袋的模型首先需要要在大量的已知類別的訓練圖片集中提取圖片特徵形成多個預選詞,然後通過聚類形成視覺詞典,然後通過詞典統計圖片的詞頻從而形成圖片的基於視覺詞典的特徵描述。將得到圖片詞袋描述及其類別作為輸入訓練分類器。分類時,首先提取待分類圖片的特徵,然後形成圖片的詞袋描述,將描述輸入到訓練得到的分類器,即可得到待分類圖片的類別
特徵提取是形成詞袋的關鍵一步,也是一個研究的熱點。目前比較著名的特徵提取方法主要有HoG,SIFT,LBP等方法。SIFT(Scale-Invariant Feature Transform),即尺度不變特徵最早於1999年由David Lowe 提出,並在2004年進一步改進。SIFT特徵是影象的區域性特徵,其對旋轉、尺度縮放、亮度變化保持不變性,對視角變化、仿射變換、噪聲也保持一定程度的穩定性。SIFT特徵提取通過尺度空間極值檢測、關鍵點定位、主方向確定、關鍵點描述四步最終形成128維的具有多種不變特性的特徵點,能夠很好的表徵圖片的區域性特徵。這些不變性使得SIFT成為目前最火的特徵提取演演算法之一。
儘管有計算複雜度高的不足,SIFT演演算法仍然是效能最好、應用最廣泛的基於區域性特徵的影象特徵提取方法。因而本文在特徵提取部分選取SIFT演演算法作簡要介紹。
SIFT特徵提取通過尺度空間極值檢測、關鍵點定位、主方向確定、關鍵點描述四步最終形成128維的具有多種不變特性的特徵點。
多尺度空間極值點檢測
SIFT要查詢的點是一些十分突出的點,這些點不會因光照條件改變,尺度變化等環境變化而消失,比如角點、邊緣點、暗區域的亮點以及亮區域的暗點。要保證尺度不變性,首先要保證提取出的特徵點不因目標的尺度變化而變化。這個可以通過建立尺度空間來完成。
尺度空間中各尺度影象的模糊程度逐漸變大,能夠模擬人在距離目標由近到遠時目標在視網膜上的形成過程。
高斯核是唯一可以產生多尺度空間的核,一個影象的尺度空間\(L(x,y,\delta )\) 定義為原始影象\(I(x,y)\) 與一個尺度可變的2維高斯函\(G(x,y,\delta)\) 的折積運算。
其中\((x,y)\)是尺度空間座標,\({\delta}\) 代表尺度,決定影象的平滑程度,值越大影象越粗糙(模糊),反之越精細。通過折積運算,一幅影象可以生成圖2所示的高斯金字塔空間,這個空間由幾塔(octave)影象組成,一塔影象包括幾層(interval)影象。同塔影象大小一致,尺度不同,塔間圖片是降取樣的關係。
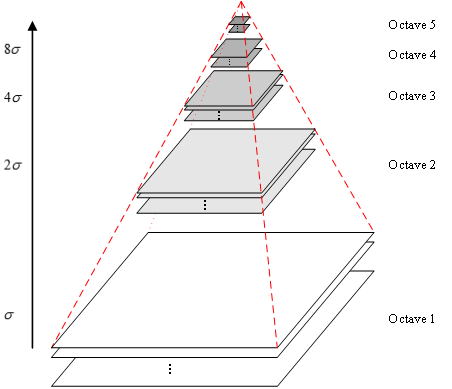
通過上面的操作,得到了塔數為O,塔內層數為S+3的高斯金字塔。LoG(Laplacian of Gaussian) 運算元能夠很好的找到影象中的興趣點,但是需要大量的計算。而DoG(Difference of Gaussian)運算元與LoG運算元由直接關係,且計算量很小,所有可以用來代替LoG來進行興趣點的查詢。DoG:
通過DoG可以得到尺度空間的差分高斯金字塔
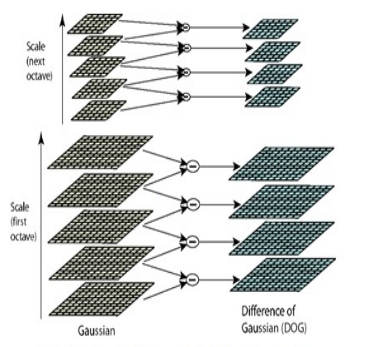
差分高斯金字塔

關鍵點查詢
生成了DoG高斯金字塔,就可以在該尺度空間檢測極值點。 一個點如果在DOG尺度空間本層以及上下兩層的26個領域中是最大或最小值時,就認為該點是影象在該尺度下的一個特徵點。如圖3。
通過上面的步驟,就可以粗略的檢測到影象中的關鍵點。
關鍵點精確定位
以上極值點的搜尋是在離散空間中進行的,檢測到的極值點並不是真正意義上的極值點。同時還要去除低對比度和邊界響應這些不穩定的關鍵點。
通過關鍵點周圍點的資訊擬合三維二次函數可以精確確定關鍵點的位置, DoG函數在影象邊緣有較強的邊緣響應,而一旦特徵落在圖形的邊緣上,這些點就是不穩定的點,因此還需要排除邊緣響應。這一點可以通過Hessian矩陣完成。
關鍵點主方向計算
上一節中確定了每幅圖中的特徵點,為每個特徵點計算一個方向,依照這個方向做進一步的計算, 利用關鍵點鄰域畫素的梯度方向分佈特性為每個關鍵點指定方向引數,使運算元具備旋轉不變性。
首先在與關鍵點尺度相應的高斯影象\(L(x,y,\delta)\) 上計算關鍵點領域視窗內畫素點的梯度幅度和方向:
上式中,\(m(x,y)\)和 \(\theta(x,y)\)分別為高斯金字塔\((x,y)\)處梯度的大小和方向。
然後用直方圖統計領域畫素的梯度方向和幅值,梯度直方圖的範圍是0~360度,其中,每10度一個柱,共36個柱。直方圖的主峰值(最大峰值)代表了關鍵點處鄰域梯度的主方向,即關鍵點的主方向。
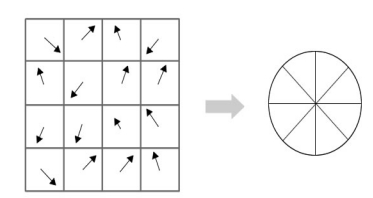
關鍵點主方向計算
至此,影象的關鍵點已檢測完畢,每個關鍵點有三個資訊:位置、尺度、方向;同時也就使關鍵點具備平移、縮放、和旋轉不變性。
生成描述子
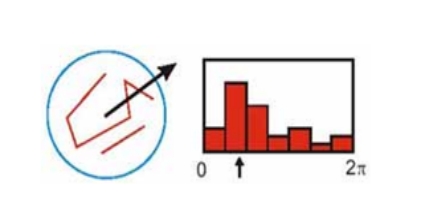
描述的目的是在關鍵點計算後,用一組向量將這個關鍵點描述出來,這個描述子不但包括關鍵點,也包括關鍵點周圍對其有貢獻的畫素點。用來作為目標匹配的依據,也可使關鍵點具有更多的不變特性,如光照變化、3D視點變化等。
描述子生成圖示
首先,將座標軸旋轉到關鍵點的主方向。只有以主方向為零點方向來描述關鍵點才能使其具有旋轉不變性。
其次,以關鍵點為中心取1616的視窗。然後計算每個44的小塊上計算8個方向的梯度方向直方圖,繪製每個梯度方向的累加值(高斯加權),即可形成一個種子點。每個種子點有8個方向向量資訊。
這樣就可以對每個特徵點形成一個448=128維的描述子,每一維都可以表示4*4個格子中一個的scale/orientation. 將這個向量歸一化之後,就進一步去除了光照的影響。
這個128維的描述向量就可以用於影象匹配等應用中了。
特徵詞典的生成
上一節得到的SIFT特徵點即是預選的「視覺單詞」,當提取了若干特徵點後,其數量往往巨大,而且特徵點是區域性特徵。但是在龐大的特徵資料庫中,僅僅幾個單一的特徵點無法完成影象描述的重大任務。此時,聚類就顯得格外重要,它將大量相似的128維特徵向量通過一定的規則進行整合,尋找出若干相似的特徵點聚為一類作為詞典中的一個詞,以此來代表一類特徵點,方便後期的影象描述,增加描述的可信度,提高描述的速度。
K-means演演算法是很典型的基於距離的聚類演演算法,採用距離作為相似性的評價指標,即認為兩個物件的距離越近,其相似度就越大。該演演算法認為簇是由距離靠近的物件組成的,因此把得到緊湊且獨立的簇作為最終目標。其演演算法過程如下:
1)從N個檔案隨機選取K個檔案作為質心
2)對剩餘的每個檔案測量其到每個質心的距離,並把它歸到最近的質心的類
3)重新計算已經得到的各個類的質心
4)迭代2~3步直至新的質心與原質心相等或小於指定閾值,演演算法結束。
經過K-means聚類,圖片中提取出的SIFT特徵就形成了對應的視覺詞典。
SVM分類器
通過聚類得到的詞典,即可將圖片的特徵轉化為對應的詞頻表(如統計直方圖)。這樣每幅圖片就可以用一個詞典向量來表示了,然後將這些向量作為分類器的輸入進行訓練即可得到分類器。本文中選擇的是SVM(支援向量機)進行分類。
支援向量機(英語:Support Vector Machine,常簡稱為SVM)是一種監督式學習的方法,可廣泛地應用於統計分類以及迴歸分析。
支援向量機將向量對映到一個更高維的空間裡,在這個空間裡建立有一個最大間隔超平面。在分開資料的超平面的兩邊建有兩個互相平行的超平面。建立方向合適的分隔超平面使兩個與之平行的超平面間的距離最大化。其假定為,平行超平面間的距離或差距越大,分類器的總誤差越小。支援向量機通過學習已知樣本來獲得決策邊界,來完成對未知樣本的分類。這種學習是有監督的學習。
本文中訓練時,是將多類問題看作二類問題,即訓練某類時以此類為正樣本,其它類為負樣本。測試時,計算測試樣本分作某一類的概率,取最大概率的分類為測試樣本的類別。
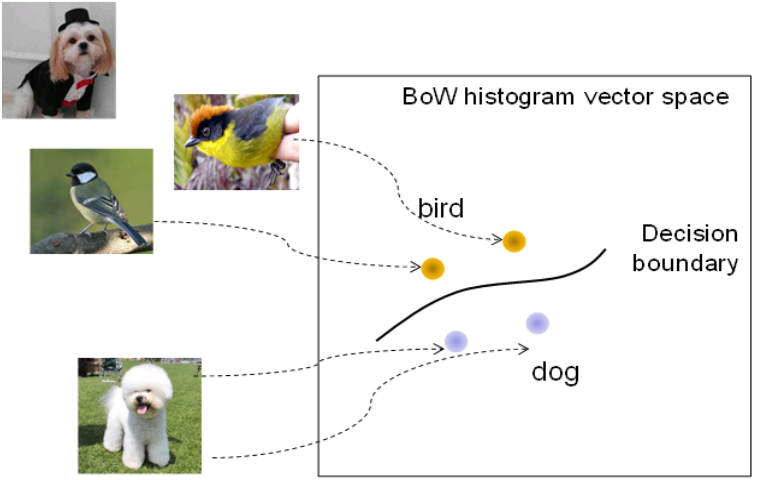
利用決策邊界進行有監督分類
實驗結果
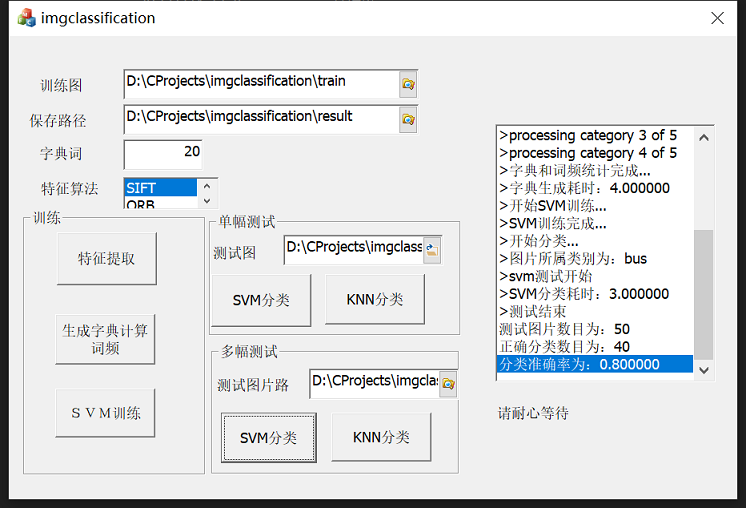
測試圖片使用corel圖片庫,選擇了其中5個類別各20張圖作為訓練集訓練分類器,並選擇同類別各20張作為測試集測試分類的準確性。並且與K階最近鄰分類器作對比(取K為9)。測試平臺為T6600CPU,系統為WINDOWS8.1。
訓練圖片集
表2 測試圖片集
測試時通過加大Kmeans聚類的類數可以達到不同的效果,基本上Kmeans類數越大,SVM分類的效果越好。這也很容易理解,K-means聚類個數即代表了生成的詞典中詞的個數,詞數越多,對影象的描述更精確。但隨著詞數的增加,字典的生成時間會增加。
2者的關係如下表:
| 視覺詞個數 | SVM分類 | KNN分類 | 字典生成耗時(s) | ||||
| 正確分類個數 | 正確率 | 分類耗時(s) | 正確分類個數 | 正確率 | 分類耗時(s) | ||
| 2 | 18 | 0.36 | 69 | 21 | 0.42 | 69 | 69 |
| 5 | 33 | 0.66 | 72 | 34 | 0.68 | 71 | 81 |
| 10 | 38 | 0.76 | 77 | 36 | 0.72 | 77 | 110 |
| 20 | 42 | 0.84 | 100 | 37 | 0.74 | 97 | 232 |
| 50 | 42 | 0.84 | 102 | 37 | 0.74 | 98 | 240 |
| 100 | 43 | 0.86 | 111 | 35 | 0.70 | 103 | 447 |
| 200 | 44 | 0.88 | 110 | 38 | 0.76 | 94 | 647 |
| 500 | 47 | 0.94 | 118 | 28 | 0.56 | 101 | 978 |
| 1000 | 47 | 0.94 | 135 | 27 | 0.54 | 108 | 1294 |
由表可以看出,對比KNN分類,SVM在單詞個數不太小時,都會好於KNN,並且在單詞數較大時,效果遠好於KNN的分類,準確率達到了94%。
總結
本文介紹了一個典型的基於詞袋和SVM分類器的圖片分類方法。基於詞袋的圖片分析技術由於具有對圖片進行語意理解的潛力,因此得到廣泛研究。SVM分類器也是目前非常火熱的分類方法之一。實驗結果表明,二者結合用於圖片的有監督分類可以得到很好的效果。但由於詞袋沒有考慮詞的順序,對於圖片也就是沒有考慮特徵的空間分佈資訊,因而還有待改進,也有人提出了Spatial pyramid matching方法進行分尺度,分塊的處理,得到了一定改善,但仍有待研究。
參考文獻
[1] Lowe, David G. "Distinctive image features from scale-invariant keypoints." International journal of computer vision 60.2 (2004): 91-110.
[2] Wallach, Hanna M. "Topic modeling: beyond bag-of-words." Proceedings of the 23rd international conference on Machine learning. ACM, 2006.
[3] Dalal, Navneet, and Bill Triggs. "Histograms of oriented gradients for human detection." Computer Vision and Pattern Recognition, 2005. CVPR 2005. IEEE Computer Society Conference on. Vol. 1. IEEE, 2005.
[4] Chang, Chih-Chung, and Chih-Jen Lin. "LIBSVM: a library for support vector machines." ACM Transactions on Intelligent Systems and Technology (TIST) 2.3 (2011): 27.
[5] Tong, Simon, and Edward Chang. "Support vector machine active learning for image retrieval." Proceedings of the ninth ACM international conference on Multimedia. ACM, 2001.
原始碼及完整報告:
演演算法使用C++ MFC實現,基於OpenCV。
https://mbd.pub/o/bread/ZJuTlZ5u 或
https://www.syjshare.com/res/1TUR49UG
本文來自部落格園,作者:CoderInCV,轉載請註明原文連結:https://www.cnblogs.com/haoliuhust/p/17527366.html