MySQL儲存之為什麼要使用B+樹做為儲存結構?
導言:
在使用MySQL資料庫的時候,我們知道了它有兩種物理儲存結構,hash儲存和B+樹儲存,由於hash儲存使用的少,而B+樹儲存使用的範圍就多些,如 InnoDB和MYISAM引擎都是使用的B+樹作為儲存結構,
B+樹,顧名思義,它還是樹形結構,那麼它是怎麼演變過來的,那麼就需要從資料結構的角度來分析了
一.順序查詢
無序線性表
在計算機發展之初,使用什麼來儲存資料,一般都是使用順序儲存來做的,比如連結串列或者資料,它們有很明顯的特點就是線性結構
當一些資料儲存在陣列中後,每次查詢都需要從前往後,或者從後往前,在演演算法中可以叫它蠻力法,一次一次的對比找到結果,效率十分低下

使用線性資料表搜尋查詢效率很不穩定,運氣好的時候可能一下就找到了結果,運氣不好又要找到最後,當然在小範圍的查詢或者臨時儲存是由用的
那麼繼續基於線性查詢,我們很快就發現普通的順序表查詢是可優化的,
我們現在查詢的資料都是未排序的,如果我們在插入或者說構造資料結構的時候就先排序,再按要求查詢會怎麼樣呢?
有序線性表

這種優化以後的查詢,我們稱之為折半查詢,在排好序的有序序列中,通過key值和當前順序結構的中間元素對比,如果比此元素大,說明key值在後面部分,如果比此元素小,說明key值在前面部分,否則運氣很好直接返回
折半查詢就伴隨著大量的剪枝操作,每次比較都會裁去一般的元素不用繼續比較了,這樣效率就高了起來,但是相對應的是我們插入資料就麻煩了,可能插入新資料都需要伴隨大量的移動
其實這種思想我們早就在樹結構中體現了,既然線性表中不好插入新資料,那麼非線性結構能否優化這個問題呢?
二.非線性結構查詢
二元搜尋樹
使用樹的方式查詢,它天生的優勢就是自帶二分查詢的功能,基本的樹定義我們就不用介紹了,主要是基於二叉查詢樹的特性
它是自帶折半查詢,每次查詢也是剪枝
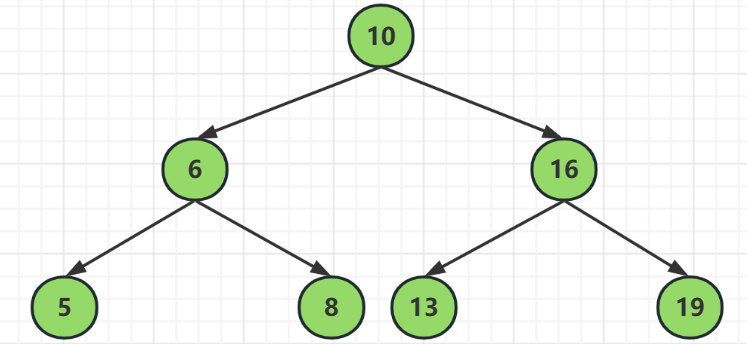
二叉查詢樹的特點就是以父節點為基準,總有左子樹小於父節點,右子樹大於父節點
我們在查詢的時候和折半查詢都是差不多的時間複雜度,並且每次查詢都會減少一半的待比較的元素,那麼二叉查詢樹的插入資料的效率如何呢
很顯然,對於單憑資料插入,其實每個新加入的元素都能在最後一層找到自己的位置,不會有元素移動的情況
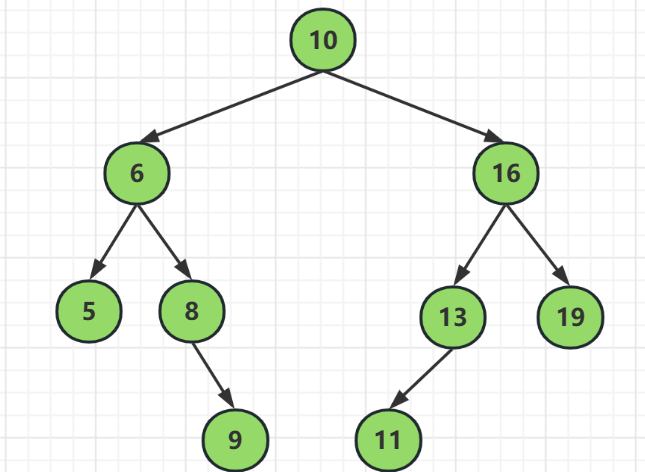
這是比較好的情況了,其實在一棵合理的樹的基礎上,我們進行增加資料或者刪除資料是很方便的,所以二叉查詢樹的特性在建樹的過程中序列很重要
如果一個序列的區間是連續變化很大,或者直接是遞增或遞減序列的時候,二叉查詢樹的優勢就會退化成線性結構,後期新資料的插入和刪除舊資料也是一樣的會退化成線性結構
比如我們給定一個遞增的序列:5,6,8,9,10,11,13,16,19
這個序列直接使用二元搜尋樹的特性去建樹會發生什麼呢?
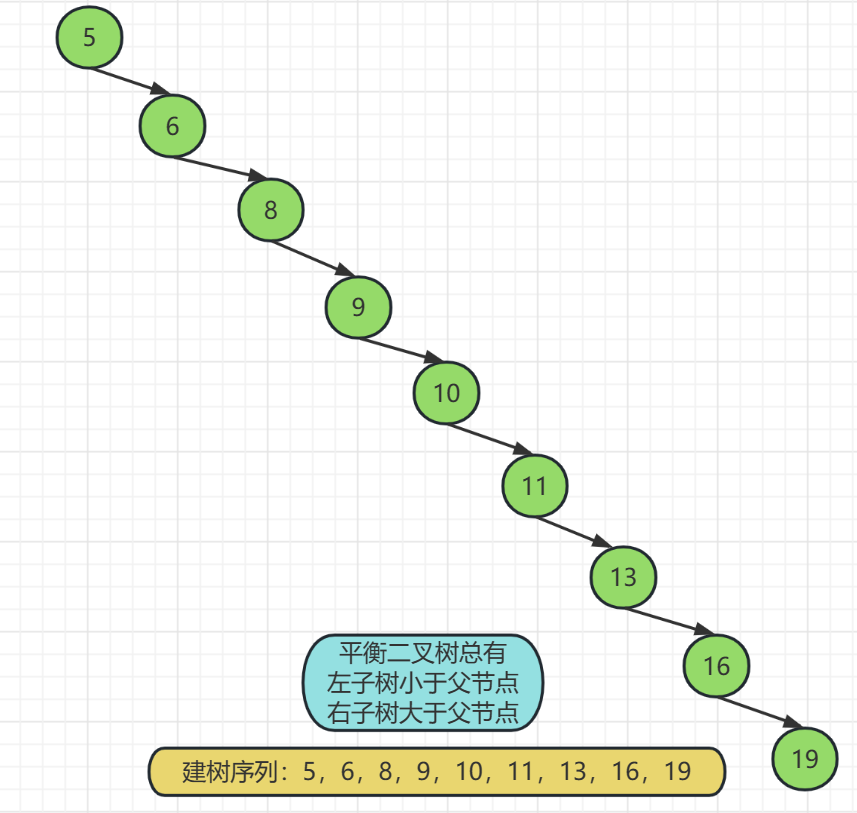
如上圖,如果一個序列是連續的,使用二元搜尋樹的特性直接建樹是很不合理的,上面的樹看起來和線性結構都是一樣的,換而言之它就是一個線性結構,我們說過線性結構對於大量的插入刪除操作十分不便
所以使用二叉收索樹直接建樹是非常不方便的,所以要更換建樹的方式
平衡二元樹(AVL)
平衡二元樹是基於二叉查詢樹的特性,對於插入資料進行調整的
它的要求是除了要滿足二叉查詢樹的特點,還需要滿足左子樹高度 - 右子樹的高度 小於等於 1,也就是左右子樹的層數最多相差一層,在上面的例圖中,一個連續的序列導致樹的右子樹明顯大於左子樹,所以它肯定不是平衡二元樹
平衡二元樹是通過旋轉得到的穩定的二元樹
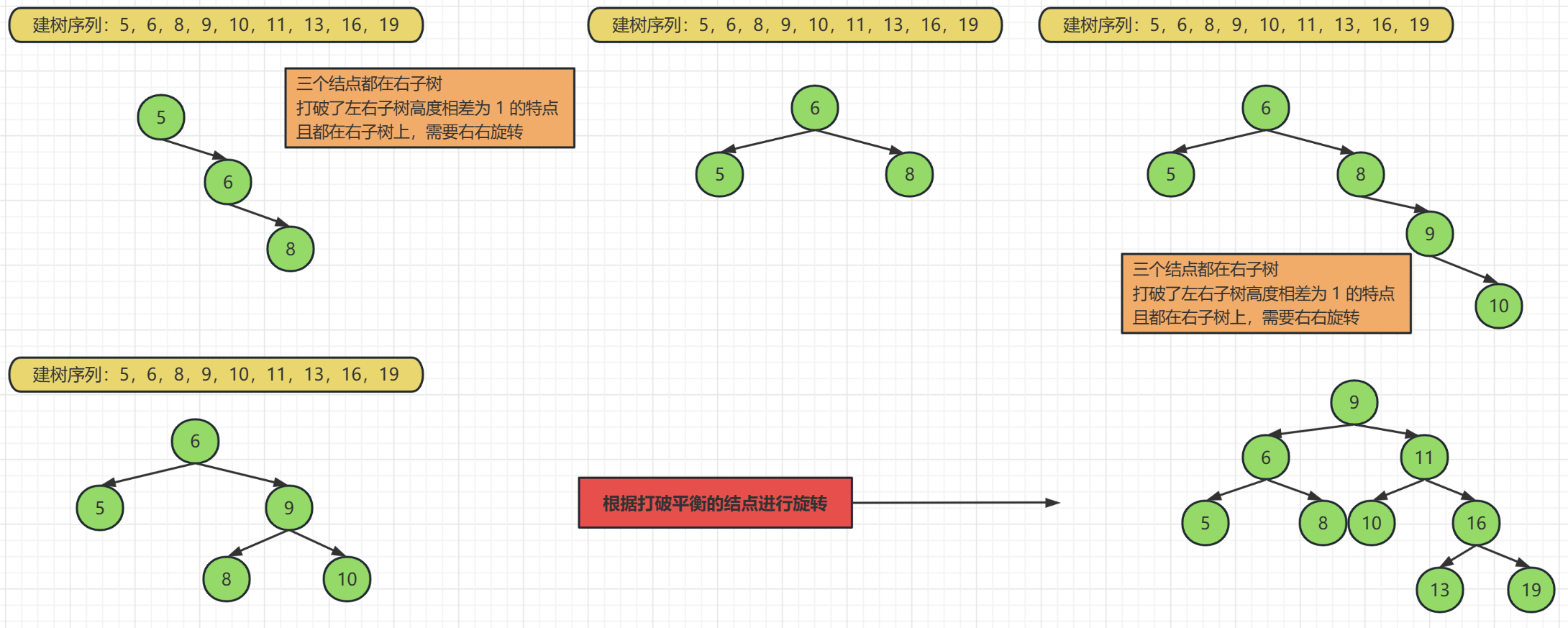
通過平衡二元樹的旋轉規則,我們可以很快的構造出一棵平衡二元樹,
這樣的構造方式就不存在插入新資料的時候會導致樹形結構退化成線性結構的可能性了
對於平衡二元樹的旋轉規則,一共有四種,可以看看我以前寫的部落格 二元樹補充 中有詳細的介紹
當使用了平衡二元樹解決了新增資料和建樹的難題,有具有二叉查詢樹的特性,對於小範圍的查詢已經不是問題了,
問題是MySQL是一個大型的資料管理系統,它內部的儲存資料都是非常多的,如果說我有100個資料,交給平衡二元樹來查詢,它有7層,也就是說它最壞的請款要查詢7次才能找到資料
那要是10000條資料呢,就需要14層,對於14次磁碟操作是很費時間的,資料庫是多人共用系統,也就是所每個人都需要14次磁碟操作,肯定是不合算的,
基於上面的分析,我們可以發現一個很明顯的特徵,那就是查詢次數和樹的層數是有關係的,如果層數低了,那麼查詢效率就高了
就比如我如果把100條資料為7層的樹,構造成6層,5層等等,是不是查詢效率就高起來了,
那麼怎麼優化呢?其實很簡單,原來平衡二元樹不是結點只存一個元素嗎?我們就要打破它,多存幾個資料
這就是平衡多路查詢樹
B樹(平衡多路查詢樹)
B樹的是多路查詢樹,這就意味著其實它的結點可能不止一個元素,大多數情況都是多元素的
當多路和查詢樹合在在一起後我們可以知道,它滿足二叉查詢樹的特點,也就是左子樹小於根節點,右子樹大於根結點
多路有表示每個結點不再存放單一的元素,而是一個有序的序列
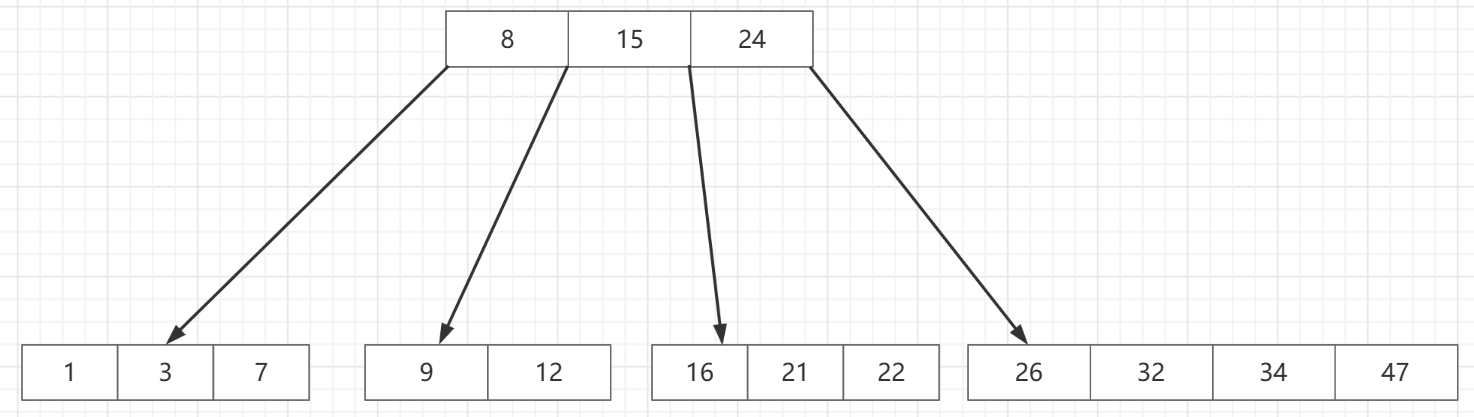
如上圖,就是一棵B樹,
多路,根結點到子結點有多條路可以走
查詢樹,始終滿足左子樹小於根節點,右子樹大於根節點
對於B樹的結點,在這裡好像元素個數都是不一樣的,其實這是根據234樹的一個拓展,因為B樹的結點都是通過上溢得來的,而每個結點插入資料不一樣,上溢的次數不一樣
我們可以簡單的瞭解一下234樹的上溢方式:

在B樹中由於是多結點,所以上溢的地方不同,也就導致各個結點不一致
上面的描述只是介紹了基本的B樹結構,其實在真正的B樹儲存中,它的結點是即儲存索引,也儲存資料的
B樹的儲存其實已經很優了,但是對於資料庫系統來說,使用B樹來做儲存結構有不足,其中包括非葉子結點中即存資料又儲存索引,查詢不穩定,存在有些查詢一次就可以拿到結果,而有些查詢卻需要其最底層,其中其它層都有可能,所以查詢資料的頻率不穩定
其二它不符合資料庫的查詢準則,那就是大範圍查詢,由於資料分佈在磁碟的各個磁區內,一旦一個磁區取值沒到範圍,就需要重新磁頭定位,十分麻煩
所以,為了符合資料庫自身的特點,B+樹就誕生了
B+樹
B+樹的其它特性都是和B樹一樣的,我們重點講一下它們的不同點
B+樹在非葉子結點都不在儲存資料,而是都儲存索引,而葉子結點都儲存資料,關於B+樹索引部分可以參考 MySQL儲存之B+樹中索引部分
這樣改裝以後有什麼好處呢?
- 非葉子結點都存索引,索引一多,指向的資料也會變多,葉子結點的資料就會變多,整個樹的樹高就會變低,層數低了,查詢效率就高了
- 資料都在葉子結點,所以說每次查詢都需要在最底層去,不存在根節點就返回資料的情況,查詢資料的穩定性就高了

B+樹的第二個特特點就是在資料庫查詢的時候,我們有很多情況下都需要取一片連續的區域
如果使用B樹來定位的話一旦在葉子結點沒有取完,那麼就會重新從頭結點開始進行磁頭定位,十分影響效率,所以在B+樹中,在葉子結點的尾部增加了指標,用於指向下一片區域,用於磁頭的連續取值
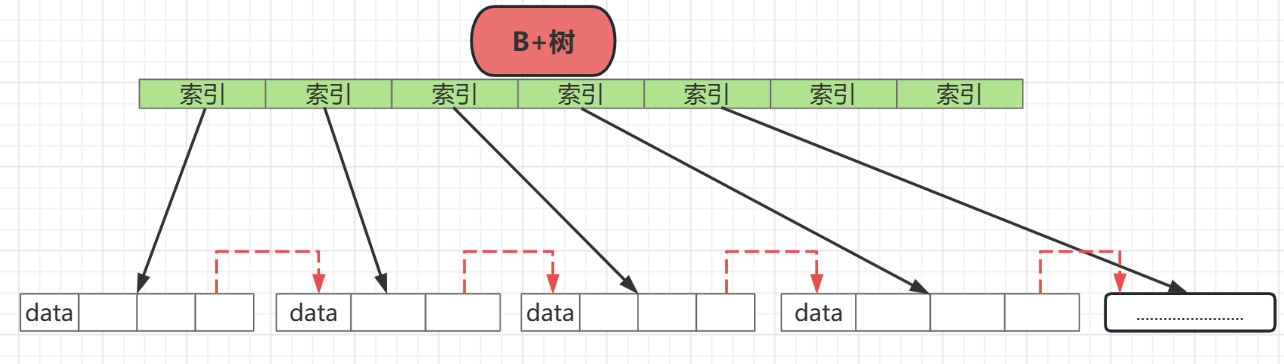
如上圖,正是這些尾部指標,才能使得B+樹在連續取值的時候效率高,這也貼合資料庫查詢操作多的特點
所以B+樹的優勢在於查詢穩定,且連續取值效率高
至於MySQL為什麼不適用紅黑樹而使用B+樹這類問題,很重要要的一點就是查詢效率
紅黑樹的平衡條件是左子樹和右子樹高度可以相差一倍,一旦資料量一多,效率就太不穩定了
但是紅黑樹寬泛的平衡條件,在程式執行的堆空間是很高效的,寬泛的平衡代表不需要過多的旋轉
所以,各自在各自的領域有各自的優勢,就目前來看B+樹比紅黑樹更適合資料庫的儲存,
大家也可以去深入瞭解一下紅黑樹,我所描述的就這麼多,希望學術同仁不吝賜教。