資料倉儲效能測試方法論與工具集
目錄
資料倉儲 v.s. 傳統資料庫
隨著 5G 網路和 IoT 技術的興起,以及越來越複雜多變的企業經營環境,都在促使著包括工業製造、能源、交通、教育和醫療在內的傳統行業紛紛開啟了數位化轉型之路。由於長尾效應的存在,千行百業的數位化轉型過程中必然會釋放出比以往任何時候都要龐大的海量資料。那麼如何對這些湧現的資料集合進行有效的儲存、分析和利用,繼而幫忙企業進行運營決策優化甚至創造出新的獲客模式和商業模式形成競爭力,就成為了擺在企業主面前亟需解決的問題。
在這樣的需求背景下,我們也觀察到近年來市場上正在出現越來越多的資料倉儲產品。資料倉儲(Data Warehouse)是一種用於整合、儲存和分析大規模結構化資料與非結構化資料的資料管理系統。相對於傳統的僅用於資料儲存的資料庫(Database)而言,資料倉儲更是一種專門設計的 「資料儲存 + 資料分析 + 資料管理" 一體化解決方案,強調資料的易用性、可分析性和可管理性,提供了包括:資料淨化、整合、轉換、複雜查詢、報表生成和資料分析等功能,用於幫助企業實現基於資料的決策制定和數位化運營場景。
更具體而言,下列表格中從技術層面更細緻的對比了兩者的區別:
| 對比項 | 傳統資料庫 | 雲原生資料倉儲 |
|---|---|---|
| 需求面向 | 面向資料儲存,主要用於支援事務處理以滿足業務操作的需求。 | 面向大規模資料儲存與高效能資料分析,主要用於資料分析和決策支援和,以滿足企業的報表、分析和資料探勘需求。 |
| 資料結構和組織方式 | 通常以表格的形式組織資料,採用關係型資料模型,通過 SQL 語句進行資料操作。 | 採用星型或雪花型的結構,將資料組織成事實表和維度表,通過複雜的查詢和分析操作進行資料處理。 |
| 資料處理複雜性 | 通常處理相對較小規模和實時的資料。 | 處理的資料量通常很大,並且涉及到多個源系統的資料整合和轉換,需要處理複雜的查詢和分析操作,同時相容 SQL 語句。 |
| 可延伸性 | 從分析到方案制定再到落地實施,週期較長。 | 線上水平擴充套件,分鐘級擴充套件。 |
| 資料量級 | 一般處理 TB 左右以下效能良好,隨著資料量增加維護難度增加。 | 支援 TB 至 PB 量級,通過平臺管理功能進行運維範例管理和監控。 |
| DBA 維護成本 | 工作量較大,中介軟體,SQL 優化效能分析要求 DBA 有豐富的技術經驗。 | 平臺化運維管理,功能模組化處理,DBA 工作更便捷高效。 |
| 資料分片 | 參照中介軟體層需要手動維護分片規則,制定不當容易出現資料傾斜。 | 分散式資料庫自身具有路由分片演演算法,分佈相對均勻可按需調整。 |
可見,在資料價值爆發的時代背景中,資料倉儲在千行百業中都有著相應的應用場景,例如:
- 金融和銀行業:應用資料倉儲平臺對大量的金融資料進行分析和建模,繼而支援風險評估、交易分析和決策制定。
- 零售和電子商務行業:應用資料倉儲平臺完成銷售分析、供應鏈分析、客戶行為分析等,幫助零售商瞭解產品銷售情況、優化庫存策略、提升客戶滿意度,並進行個性化推薦和行銷活動。
- 市場行銷和廣告行業:應用資料倉儲平臺整合不同渠道的市場資料和客戶行為資料,幫助企業瞭解客戶需求,支援目標市場分析、廣告效果評估、客戶細分等工作。

基於以上原因,我們也希望能夠與時俱進地去考察市場上的資料倉儲產品的特性,並以此支撐公司技術選型工作。技術選型是一項系統且嚴謹的工作內容,需要從功能、效能、成熟度、可控性、成本等多個方面進行考慮,本文則主要關注在效能方面,嘗試探討一種可複用的效能測試方案,包括:效能指標、方法論和工具集這 3 個方面的內容。
資料倉儲效能測試案例
效能指標
資料倉儲的效能指標需要根據具體的應用場景來設定,但通常的會包括以下幾個方面:
- 讀寫效能:衡量資料倉儲在讀取和寫入資料方面的效能表現。包括:吞吐量(每秒處理的請求數量)、延遲(請求的響應時間)、並行性(同時處理的請求數量)等。
- 水平擴充套件性:衡量資料倉儲在大規模系統中的水平擴充套件能力,能夠隨著使用者端的並行增長而進行彈性擴充套件,並獲得線性的效能提升。
- 資料一致性:測試資料倉儲在分散式環境中的資料一致性保證程度。根據應用場景的不同,對資料強一致性、弱一致性、最終一致性會有不同的側重。
- 故障恢復和高可用性:測試資料倉儲在面對故障時的恢復能力和高可用性。可以模擬節點故障或網路分割區等場景,評估資料倉儲的故障轉移和資料恢復效能。
- 資料安全性:評估資料倉儲在資料保護方面的效能。包括:資料的備份和恢復速度、資料加密和存取控制等。
- 叢集管理和資源利用率:評估資料倉儲在叢集管理和資源利用方面的效能。包括:節點的動態擴縮容、負載均衡、資源利用率等。
- 資料庫管理工具效能:評估資料倉儲管理工具在設定、監控、診斷和優化等方面的效能表現。
在本文中主要關注讀寫效能方面的操作實踐。
測試方案
為了進一步完善測試流程,以及對國產資料倉儲大趨勢的傾向性,所以本文采用了相對方便獲取且同樣都是採用了 Hadoop 作為底層分散式檔案系統支撐的兩款國產資料倉儲產品進行測試:
- Cloudwave 4.0(2023 年 5 月發版)是一款由北京翰雲時代資料技術有限公司推出的國產商業雲原生資料倉儲產品。
- StarRocks 3.0(2023 年 4 月發版)是一款使用 Elastic License 2.0 協定的國產開源資料倉儲產品,
另外,這兩款產品的安裝部署和操作手冊的檔案都非常詳盡,請大家自行查閱,下文中主要記錄了測試操作步驟,並不贅述基本安裝部署的步驟。
- Cloudwave:https://github.com/CloudwaveDatabase/cloudwave
- StarRocks:https://github.com/StarRocks/starrocks
測試場景
在本文中首先關注應用場景更加廣泛的結構化資料的 SQL 讀寫場景。
測試資料集
測試資料集則採用了常見的 SSB1000 國際標準測試資料集,該資料集的主要內容如下表所示:
| 表名 | 錶行數(單位:行) | 描述 |
|---|---|---|
| lineorder | 60 億 | SSB 商品訂單表 |
| customer | 3000 萬 | SSB 客戶表 |
| part | 200 萬 | SSB 零部件表 |
| supplier | 200 萬 | SSB 供應商表 |
| dates | 2556 | 日期表 |
測試用例
- TestCase 1. 執行 13 條標準 SQL 測試語句。
use ssb1000;
# 1
select sum(lo_revenue) as revenue from lineorder,dates where lo_orderdate = d_datekey and d_year = 1993 and lo_discount between 1 and 3 and lo_quantity < 25;
# 2
select sum(lo_revenue) as revenue from lineorder,dates where lo_orderdate = d_datekey and d_yearmonthnum = 199401 and lo_discount between 4 and 6 and lo_quantity between 26 and 35;
# 3
select sum(lo_revenue) as revenue from lineorder,dates where lo_orderdate = d_datekey and d_weeknuminyear = 6 and d_year = 1994 and lo_discount between 5 and 7 and lo_quantity between 26 and 35;
# 4
select sum(lo_revenue) as lo_revenue, d_year, p_brand from lineorder ,dates,part,supplier where lo_orderdate = d_datekey and lo_partkey = p_partkey and lo_suppkey = s_suppkey and p_category = 'MFGR#12' and s_region = 'AMERICA' group by d_year, p_brand order by d_year, p_brand;
# 5
select sum(lo_revenue) as lo_revenue, d_year, p_brand from lineorder,dates,part,supplier where lo_orderdate = d_datekey and lo_partkey = p_partkey and lo_suppkey = s_suppkey and p_brand between 'MFGR#2221' and 'MFGR#2228' and s_region = 'ASIA' group by d_year, p_brand order by d_year, p_brand;
# 6
select sum(lo_revenue) as lo_revenue, d_year, p_brand from lineorder,dates,part,supplier where lo_orderdate = d_datekey and lo_partkey = p_partkey and lo_suppkey = s_suppkey and p_brand = 'MFGR#2239' and s_region = 'EUROPE' group by d_year, p_brand order by d_year, p_brand;
# 7
select c_nation, s_nation, d_year, sum(lo_revenue) as lo_revenue from lineorder,dates,customer,supplier where lo_orderdate = d_datekey and lo_custkey = c_custkey and lo_suppkey = s_suppkey and c_region = 'ASIA' and s_region = 'ASIA'and d_year >= 1992 and d_year <= 1997 group by c_nation, s_nation, d_year order by d_year asc, lo_revenue desc;
# 8
select c_city, s_city, d_year, sum(lo_revenue) as lo_revenue from lineorder,dates,customer,supplier where lo_orderdate = d_datekey and lo_custkey = c_custkey and lo_suppkey = s_suppkey and c_nation = 'UNITED STATES' and s_nation = 'UNITED STATES' and d_year >= 1992 and d_year <= 1997 group by c_city, s_city, d_year order by d_year asc, lo_revenue desc;
# 9
select c_city, s_city, d_year, sum(lo_revenue) as lo_revenue from lineorder,dates,customer,supplier where lo_orderdate = d_datekey and lo_custkey = c_custkey and lo_suppkey = s_suppkey and (c_city='UNITED KI1' or c_city='UNITED KI5') and (s_city='UNITED KI1' or s_city='UNITED KI5') and d_year >= 1992 and d_year <= 1997 group by c_city, s_city, d_year order by d_year asc, lo_revenue desc;
# 10
select c_city, s_city, d_year, sum(lo_revenue) as lo_revenue from lineorder,dates,customer,supplier where lo_orderdate = d_datekey and lo_custkey = c_custkey and lo_suppkey = s_suppkey and (c_city='UNITED KI1' or c_city='UNITED KI5') and (s_city='UNITED KI1' or s_city='UNITED KI5') and d_yearmonth = 'Dec1997' group by c_city, s_city, d_year order by d_year asc, lo_revenue desc;
# 11
select d_year, c_nation, sum(lo_revenue) - sum(lo_supplycost) as profit from lineorder,dates,customer,supplier,part where lo_orderdate = d_datekey and lo_custkey = c_custkey and lo_suppkey = s_suppkey and lo_partkey = p_partkey and c_region = 'AMERICA' and s_region = 'AMERICA' and (p_mfgr = 'MFGR#1' or p_mfgr = 'MFGR#2') group by d_year, c_nation order by d_year, c_nation;
# 12
select d_year, s_nation, p_category, sum(lo_revenue) - sum(lo_supplycost) as profit from lineorder,dates,customer,supplier,part where lo_orderdate = d_datekey and lo_custkey = c_custkey and lo_suppkey = s_suppkey and lo_partkey = p_partkey and c_region = 'AMERICA'and s_region = 'AMERICA' and (d_year = 1997 or d_year = 1998) and (p_mfgr = 'MFGR#1' or p_mfgr = 'MFGR#2') group by d_year, s_nation, p_category order by d_year, s_nation, p_category;
# 13
select d_year, s_city, p_brand, sum(lo_revenue) - sum(lo_supplycost) as profit from lineorder,dates,customer,supplier,part where lo_orderdate = d_datekey and lo_custkey = c_custkey and lo_suppkey = s_suppkey and lo_partkey = p_partkey and c_region = 'AMERICA'and s_nation = 'UNITED STATES' and (d_year = 1997 or d_year = 1998) and p_category = 'MFGR#14' group by d_year, s_city, p_brand order by d_year, s_city, p_brand;
- TestCase 2. 執行多表聯合 join 拓展 SQL1 測試語句。
select count(*) from lineorder,customer where lo_custkey = c_custkey;
- TestCase 3. 執行多表聯合 join 拓展 SQL2 測試語句。
select count(*) from lineorder,customer,supplier where lo_custkey = c_custkey and lo_suppkey = s_suppkey;
效能指標
這裡設定 2 個最常見的效能指標:
- 最大 CPU 資源佔用資料;
- 最大 TestCase 執行耗時資料。
並且為了對測試結果進行 「去噪「,每個 TestCases 都會執行 19 輪 SQL 測試指令碼。值得注意的是,還需要額外的去除掉第 1 輪的測試資料,因為第 1 次查詢效能資料會收到系統 I/O 的變數因素影響。所以應該對餘下的 18 輪測試資料做平均計算,以此獲得更加準確的 SQL 執行平均耗時資料。
測試指令碼工具
- Cloudwave 測試指令碼:
#!/bin/bash
# Program:
# test ssb
# History:
# 2023/03/17 [email protected] version:0.0.1
rm -rf ./n*txt
for ((i=1; i<20; i++))
do
cat sql_ssb.sql |./cplus.sh > n${i}.txt
done
- StarRocks 測試指令碼:
#!/bin/bash
# Program:
# test ssb
# History:
# 2023/03/17 [email protected] version:0.0.1
rm -rf ./n*txt
for ((i=1; i<20; i++))
do
cat sql_ssb.sql | mysql -uroot -P 9030 -h 127.0.0.1 -v -vv -vvv >n${i}.txt
done
- 結果分析指令碼:
#!/bin/bash
# Program:
# analysis cloudwave/starrocks logs of base compute
# History:
# 2023/02/20 [email protected] version:0.0.1
path=/bin:/sbin:/usr/bin:/usr/sbin:/usr/local/sbin:/usr/local/bin:~/bin
export path
suff="(s)#####"
if [ -z "${1}" ]
then
echo "Please input database'name"
exit -1
fi
if [ -z "$2" ]
then
echo "Please input times of scanner"
exit -f
fi
if [ -n "${3}" ]
then
suff=${3}
fi
for current in ${2}
do
result_time=""
if [ "${1}" == "starrocks" ]
then
for time in $( cat ${current} | grep sec | awk -F '(' '{print $2}' | awk -F ' ' '{print $1}' )
do
result_time="${result_time}${time}${suff}"
done
elif [ "${1}" == "cloudwave" ]
then
for time in $( cat ${current} | grep Elapsed | awk '{print $2}'| sed 's/:/*60+/g'| sed 's/+00\*60//g ; s/+0\*60//g ; s/^0\*60+//g' )
do
result_time="${result_time}${time}${suff}"
done
fi
echo ${result_time%${suff}*}
done
exit 0
- sql_ssb.sql 檔案:用於儲存不同 TestCases 中的 SQL 測試語句,然後被測試指令碼讀取。
基準環境準備
硬體環境
為了方便測試環境的準備和節省成本,同時儘量靠近分散式的常規部署方式。所以測試的硬體環境採用了阿里雲上的 4 臺 64 Core 和 256G Memory 的雲主機來組成分散式叢集,同時為了進一步避免磁碟 I/O 成為了效能瓶頸,所以也都掛載了 ESSD pl1 高效能雲盤。

軟體環境
-
JDK 19:Cloudwave 4.0 依賴
-
JDK 8:StarRocks 3.0 依賴
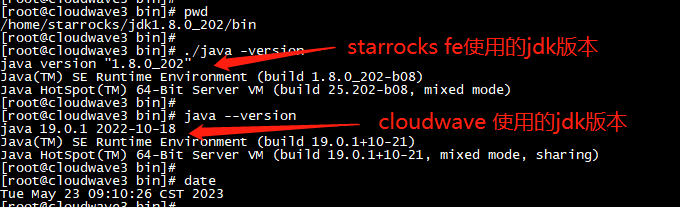
-
MySQL 8:作為 StarRocks FE(前端)

-
Hadoop 3.2.2:作為 Cloudwave 和 StarRocks 的分散式儲存,並設定檔案副本數為 2。

測試操作步驟
Cloudwave 執行步驟
匯入資料集
- 檢視為 Hadoop 準備的儲存空間。
$ ./sync_scripts.sh 'df -h' | grep home

- 格式化 Hadoop 儲存空間。
$ hdfs namenode -format
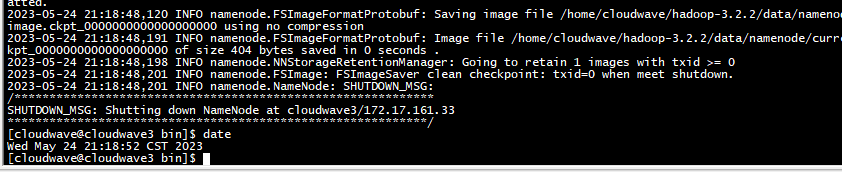
- 啟動 HDFS,並檢視服務狀態。
$ start-dfs.sh
$ ./sync_scripts.sh 'jps'
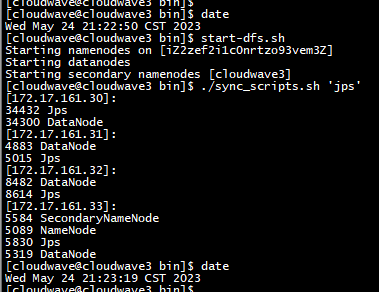
- 建立 SSB1000 資料集的上傳目錄。
$ hdfs dfs -mkdir /cloudwave
$ hdfs dfs -mkdir /cloudwave/uploads
$ hdfs dfs -put ssb1000 /cloudwave/uploads/

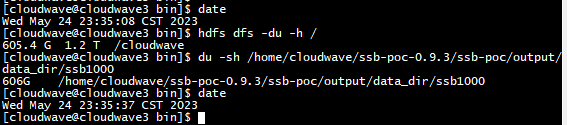
- 檢查資料上傳結果,可以看到 SSB1000 資料集,佔用了 606GB 的儲存空間。
$ hdfs dfs -du -h /
$ du -sh /home/cloudwave/ssb-poc-0.9.3/ssb-poc/output/data_dir/ssb1000
- 啟動 Cloudwave。
$ ./start-all-server.sh
- 匯入 SSB1000 資料集。
$ ./cplus_go.bin -s 'loaddata ssb1000'
-
因為資料集非常大所以匯入的時間較長,大概 58 分鐘。
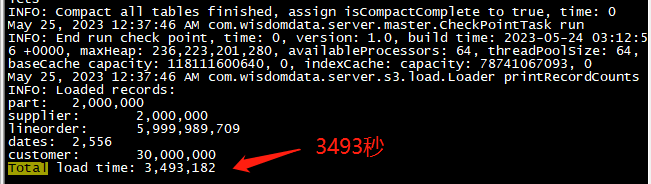
-
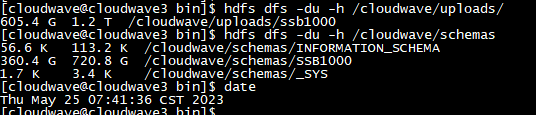
通過執行 HDFS 的命令,可以看到 Cloudwave 對資料集同步進行了資料壓縮,這也是 Cloudwave 的特性功能之一。SSB1000 的原始大小是 606G,匯入後被壓縮到到了 360G。下圖中的 720G 表示 HDFS 中 2 個資料副本的總大小,壓縮比達到了可觀的 59%。
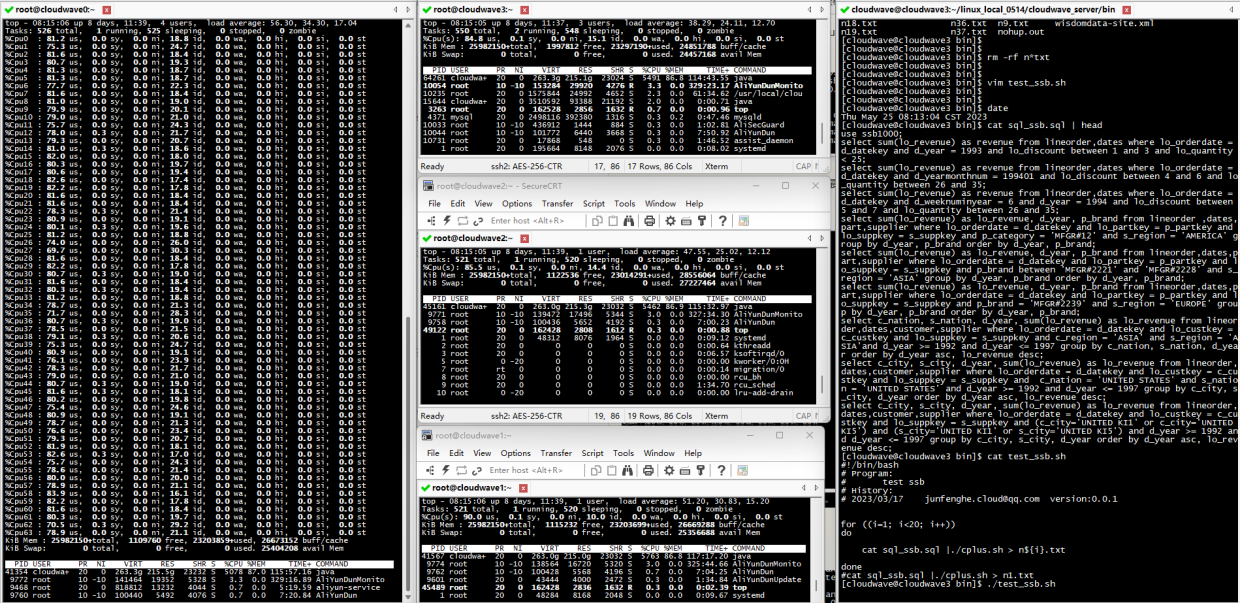
TestCase 1. 執行 13 條標準 SQL 測試語句
將 TestCase 1 的 13 條標準 SQL 測試語句寫入到 sql_ssb.sql 檔案中,然後執行 Cloudwave 測試指令碼,同時監控記錄 CPU 資源的使用率資料。
$ ./test_ssb.sh
結果如下圖所示。在 TestCase 1 中,4 節點的 Cloudwave 叢集的最大 CPU 使用率平均為 5763% / 6400% = 90%(注:64 Core CPU 總量為 6400%)。
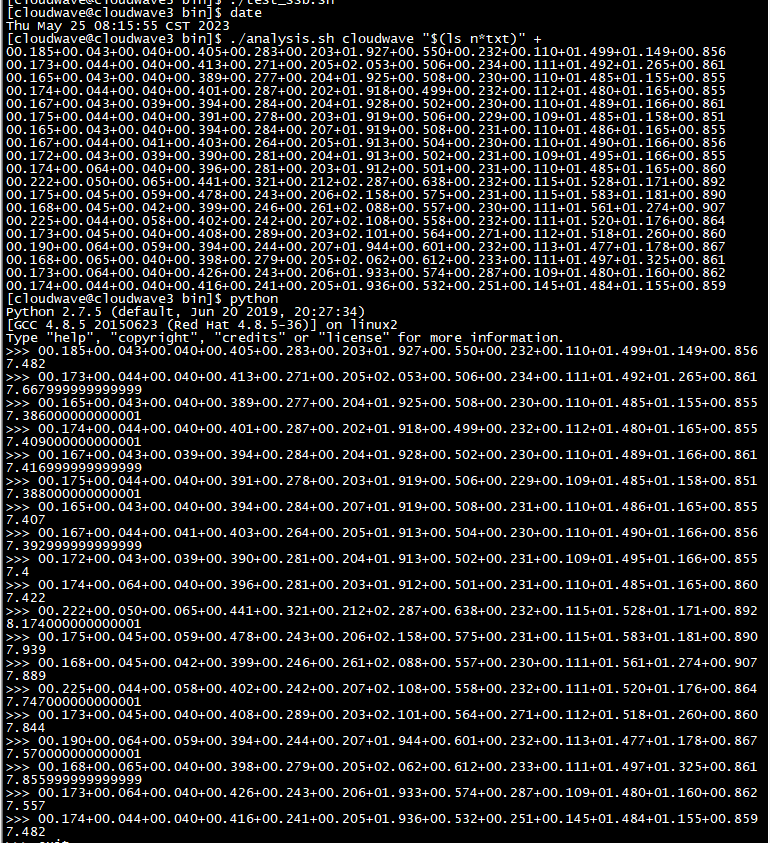
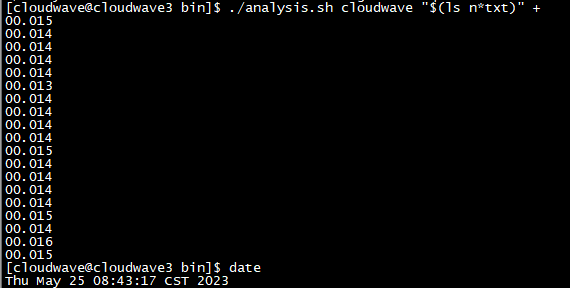
如下圖所示,執行分析指令碼程式來計算 TestCase 1 的平均耗時為 7.6s。
$ ./analysis.sh cloudwave "$(ls n*txt)" +
TestCase 2. 執行多表聯合 join 拓展 SQL1 測試語句
將 TestCase 2 的 多表聯合 join 拓展 SQL1 測試語句寫入到 sql_ssb.sql 檔案中,然後執行 Cloudwave 測試指令碼,同時監控記錄 CPU 資源的使用率資料。
$ ./test_ex.sh
結果如下圖所示。在 TestCase 2 中,4 節點的 Cloudwave 叢集的最大 CPU 使用率平均為 0.0935%(6% / 6400%)。
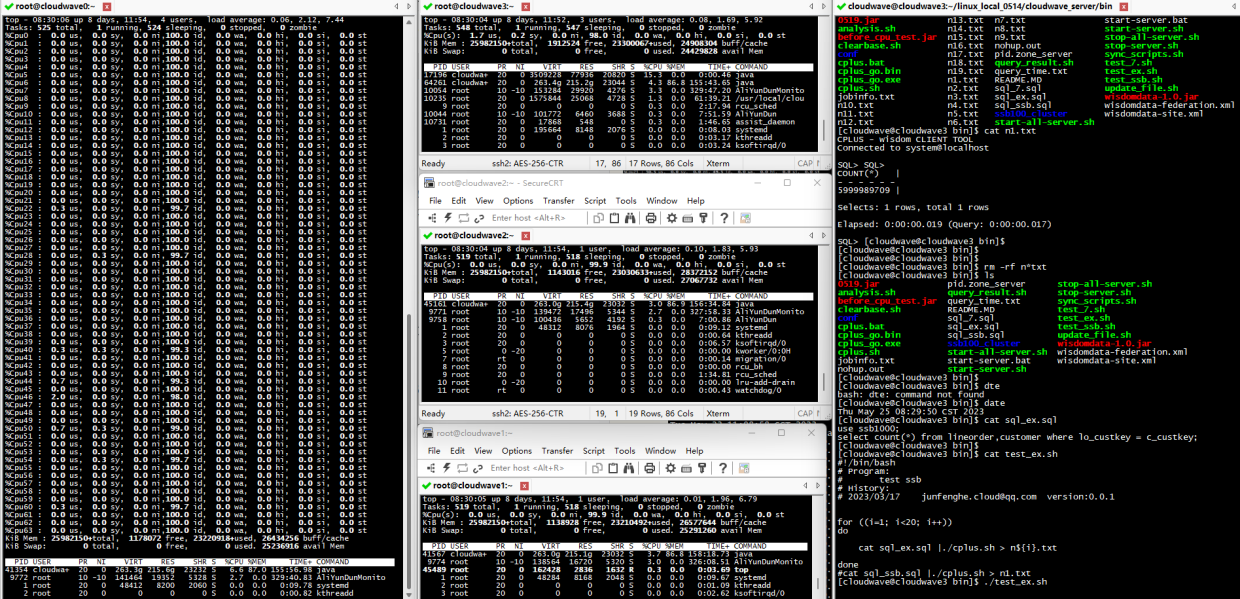
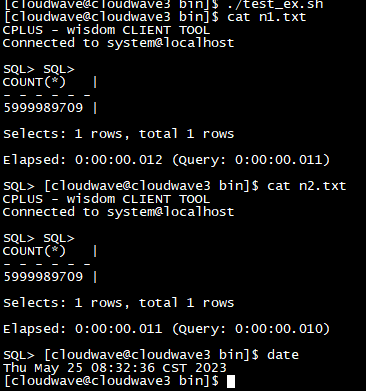
如下圖所示,執行分析指令碼程式來計算 TestCase 2 的平均耗時為 12ms。
$ ./analysis.sh cloudwave "$(ls n*txt)" +
TestCase 3. 執行多表聯合 join 拓展 SQL2 測試語句
將 TestCase 2 的 多表聯合 join 拓展 SQL2 測試語句寫入到 sql_ssb.sql 檔案中,然後執行 Cloudwave 測試指令碼,同時監控記錄 CPU 資源的使用率資料。
$ ./test_ex.sh
結果如下圖所示。在 TestCase 2 中,4 節點的 Cloudwave 叢集的最大 CPU 使用率平均為 0.118%(7.6% / 6400%)。
如下圖所示,執行分析指令碼程式來計算 TestCase 3 的平均耗時為 14ms。
$ ./analysis.sh cloudwave "$(ls n*txt)" +
StarRocks 執行步驟
匯入資料集
- 清空 HDFS 儲存。
$ hdfs dfs -rm -r /cloudwave
$ hdfs dfs -ls /
- 啟動 StarRocks FE(前端)守護行程。
$ ./fe/bin/start_fe.sh --daemon

- 新增 StarRocks BE(後端)單元。
$ mysql -uroot -h127.0.0.1 -P9030
$ ALTER SYSTEM ADD BACKEND "172.17.161.33:9050";
$ ALTER SYSTEM ADD BACKEND "172.17.161.32:9050";
$ ALTER SYSTEM ADD BACKEND "172.17.161.31:9050";
$ ALTER SYSTEM ADD BACKEND "172.17.161.30:9050";
- 啟動 StarRocks BE 守護行程。
$ ./sync_scripts.sh "cd $(pwd)/be/bin && ./start_be.sh --daemon &&ps -ef | grep starrocks_be"
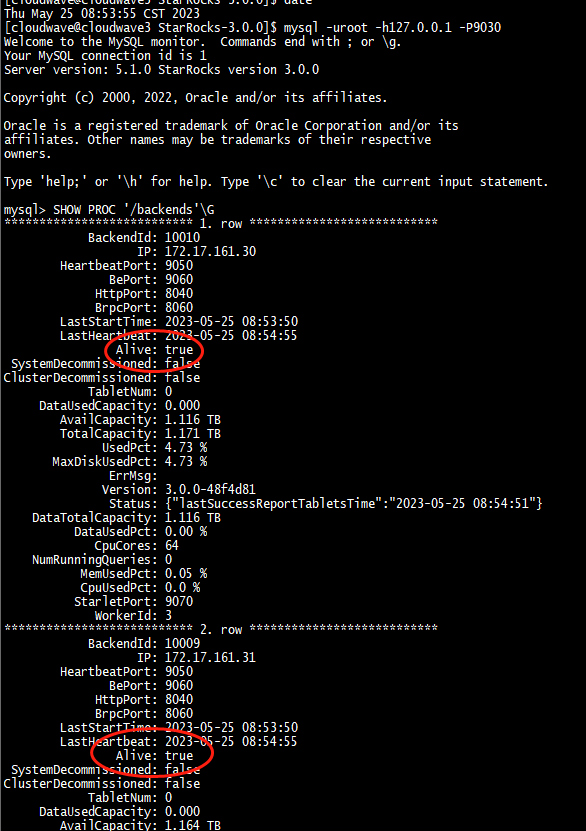
-
驗證 StarRocks 叢集狀態,依次檢視 4 個節點都 Alive=true 了。
-
建立表。

-
開始匯入資料,SSB1000 的匯入時間總計為 112 分鐘。
$ date && ./bin/stream_load.sh data_dir/ssb100 && date
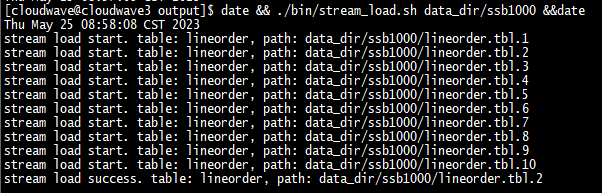
匯入過程中可以發現雖然設定了 HDFS 的副本數為 2,但 StarRocks 將副本數自動修改為了 3。
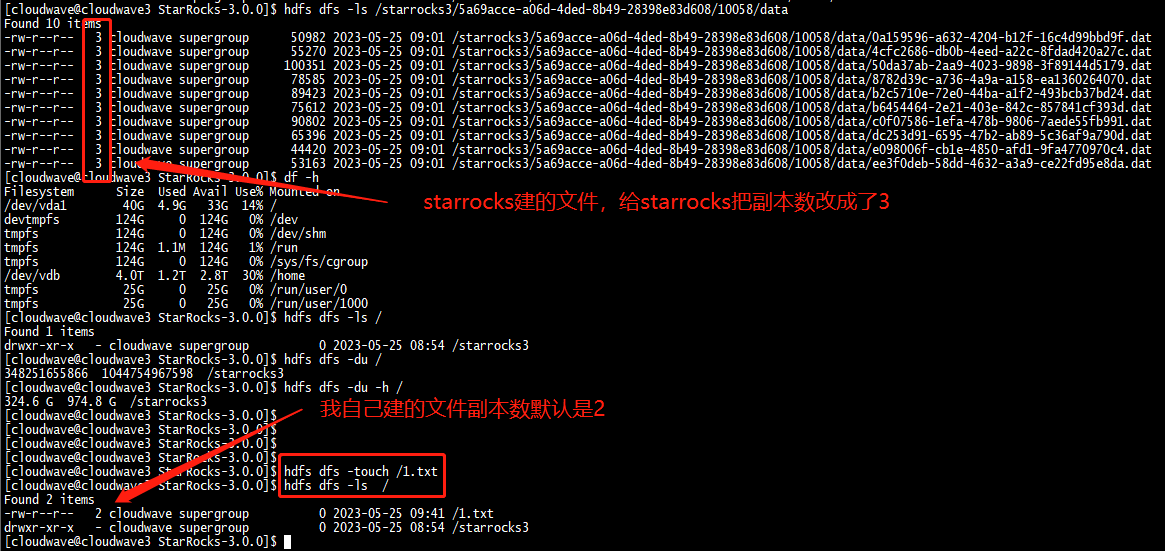
另外在匯入資料集時,發現 StarRocks 似乎沒有進行資料壓縮,佔用了 1T 的儲存空間,所以匯入時間也相應的變得更長。

TestCase 1. 執行 13 條標準 SQL 測試語句
將 TestCase 1 的 13 條標準 SQL 測試語句寫入到 sql_ssb.sql 檔案中,然後執行 StarRocks 測試指令碼,同時監控記錄 CPU 資源的使用率資料。
$ ./test_ssb.sh
結果如下圖所示。在 TestCase 1 中,4 節點的 StarRocks 叢集的最大 CPU 使用率平均為 67%(4266% / 6400%)。
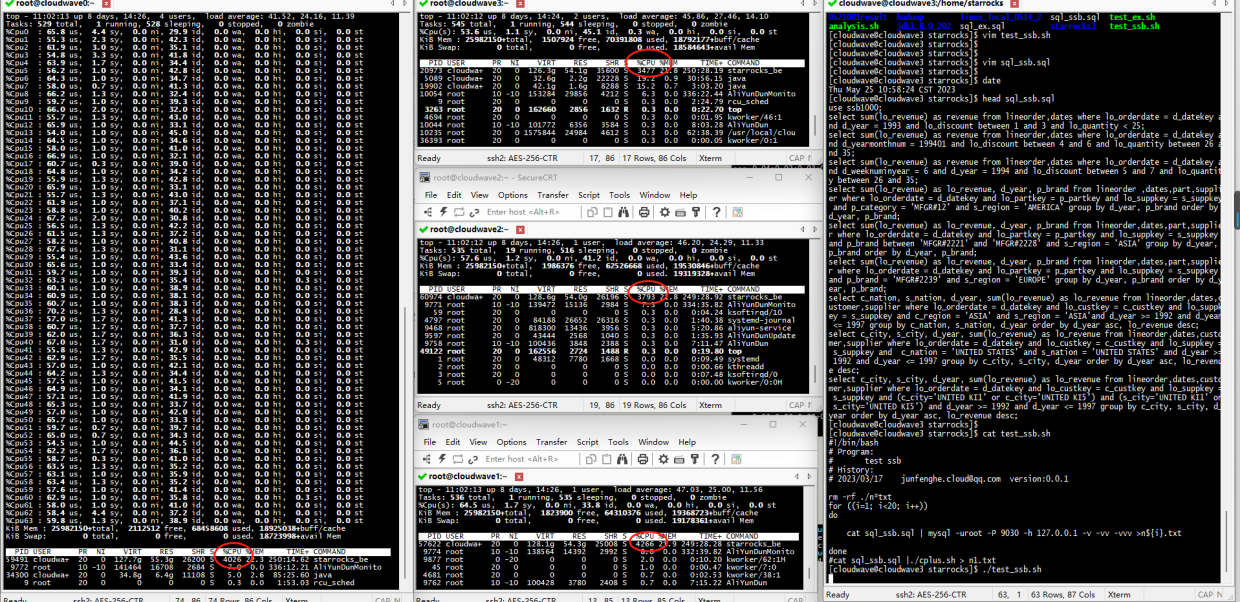
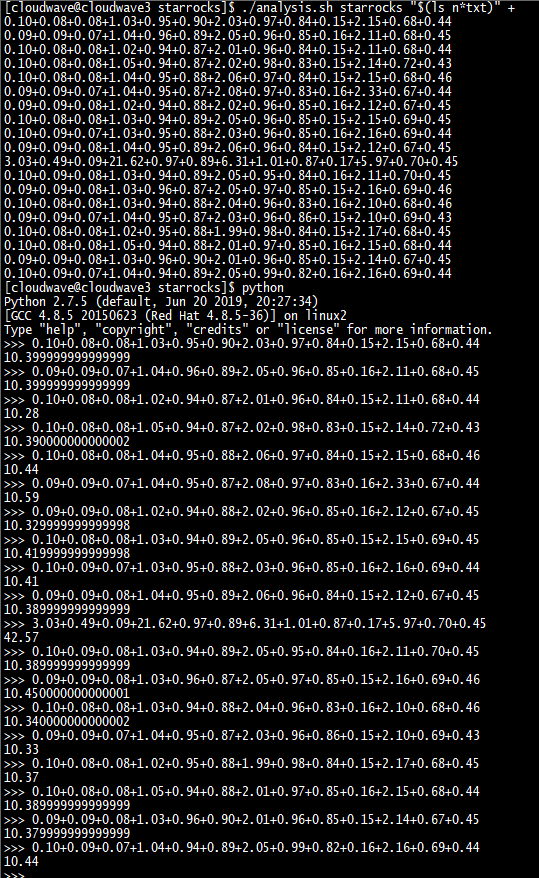
如下圖所示,執行分析指令碼程式來計算 TestCase 1 的平均耗時為 10.39s。
$ ./analysis.sh cloudwave "$(ls n*txt)" +
TestCase 2. 執行多表聯合 join 拓展 SQL1 測試語句
將 TestCase 2 的 多表聯合 join 拓展 SQL1 測試語句寫入到 sql_ssb.sql 檔案中,然後執行 StarRocks 測試指令碼,同時監控記錄 CPU 資源的使用率資料。
$ ./test_ex.sh
結果如下圖所示。在 TestCase 2 中,4 節點的 StarRocks 叢集的最大 CPU 使用率平均為 78.7%(5037% / 6400%)。
如下圖所示,執行分析指令碼程式來計算 TestCase 2 的平均耗時為 2.79s。
$ ./analysis.sh cloudwave "$(ls n*txt)" +
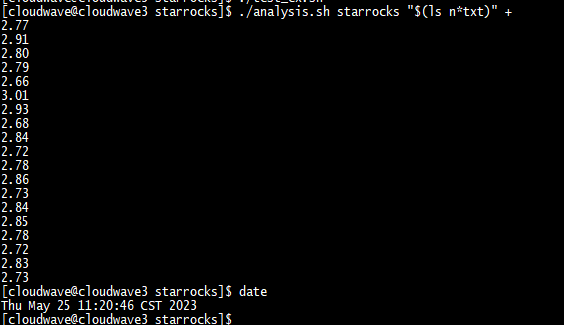
TestCase 3. 執行多表聯合 join 拓展 SQL2 測試語句
將 TestCase 2 的 多表聯合 join 拓展 SQL2 測試語句寫入到 sql_ssb.sql 檔案中,然後執行 StarRocks 測試指令碼,同時監控記錄 CPU 資源的使用率資料。
$ ./test_ex.sh
結果如下圖所示。在 TestCase 2 中,4 節點的 Cloudwave 叢集的最大 CPU 使用率平均為 90.5%(5797% / 6400%)。
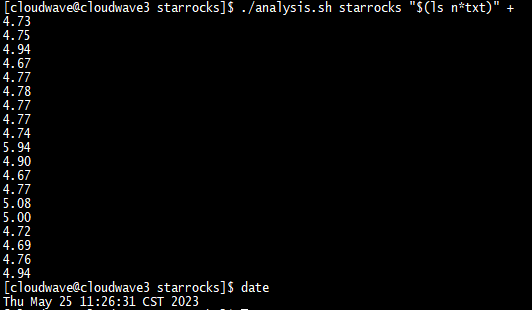
如下圖所示,執行分析指令碼程式來計算 TestCase 3 的平均耗時為 4.8s。
$ ./analysis.sh cloudwave "$(ls n*txt)" +
測試結果分析
- 13 條標準 SQL 測試語句結果統計:
| 資料倉儲 | 資料集 | 響應時間(s) | CPU 最大佔用率 | 儲存壓縮比 | 資料匯入時間 |
|---|---|---|---|---|---|
| Cloudwave 4.0 | ssb1000 | 7.602 | 90%(5763%/6400%) | 59%(360G/606G) | 58分鐘 |
| StarRocks 3.0 | ssb1000 | 10.397 | 66.6%(4266%/6400%) | 169%(1024G/606G) | 112分鐘 |
- 2 條多表聯合 join 擴充套件 SQL 測試語句結果統計:
| 資料倉儲 | 資料集 | 拓展SQL1響應時間(s) | 拓展SQL1 CPU 最大佔用率 | 拓展SQL2響應時間(s) | 拓展SQL2 CPU 最大佔用率 |
|---|---|---|---|---|---|
| Cloudwave 4.0 | ssb1000 | 0.012 | 0.0935%(6%/6400) | 0.014 | 0.118%(7.6%/6400) |
| StarRocks 3.0 | ssb1000 | 2.79 | 78.7%(5037%/6400) | 4.8 | 90.5%(5797%/6400) |
從上述測試結果中可以看出 Cloudwave 雲原生資料倉儲的效能表現是非常突出的,尤其在在多表聯合 join 擴充套件 SQL 場景下,Cloudwave 4.0版本的 CPU 資源佔有率非常低的同時執行速度也非常快。
當然,資料倉儲效能優化和測試是一門複雜的系統工程,由於檔案篇幅的限制上文中也只是選取了比較有限的測試場景和效能指標,主要是為了學習研究和交流之用,實際上還有很多值得優化和擴充套件的細節。
從資料倉儲到雲原生資料倉儲
最後在記錄下一些學習心得。從前提到資料庫(Database)我會認為它們單純就是一個用於存放結構化資料或非結構化資料的 DBMS(Database Management System)應用軟體。但隨著資料探勘的價值體系被越來越多使用者所認可,以及越來越多的使用者需求將資料應用於提升實際的生產效率上。使得單純面向資料儲存的資料庫逐漸被堆疊了越來越多的業務應用功能,進而演變成一個面向資料分析的資料倉儲(Data Warehouse)。
以基於雲原生架構的 Cloudwave 4.0 資料倉儲的為例,從下圖的產品架構可以看出,Cloudwave 除了支援常規的結構化資料和非結構化資料儲存功能之外,還具有面向頂層應用程式的資料服務層,以多樣化的 SDK 驅動程式嚮應用程式提供資料儲存、資料管理、平臺管理、服務接入外掛等能力。
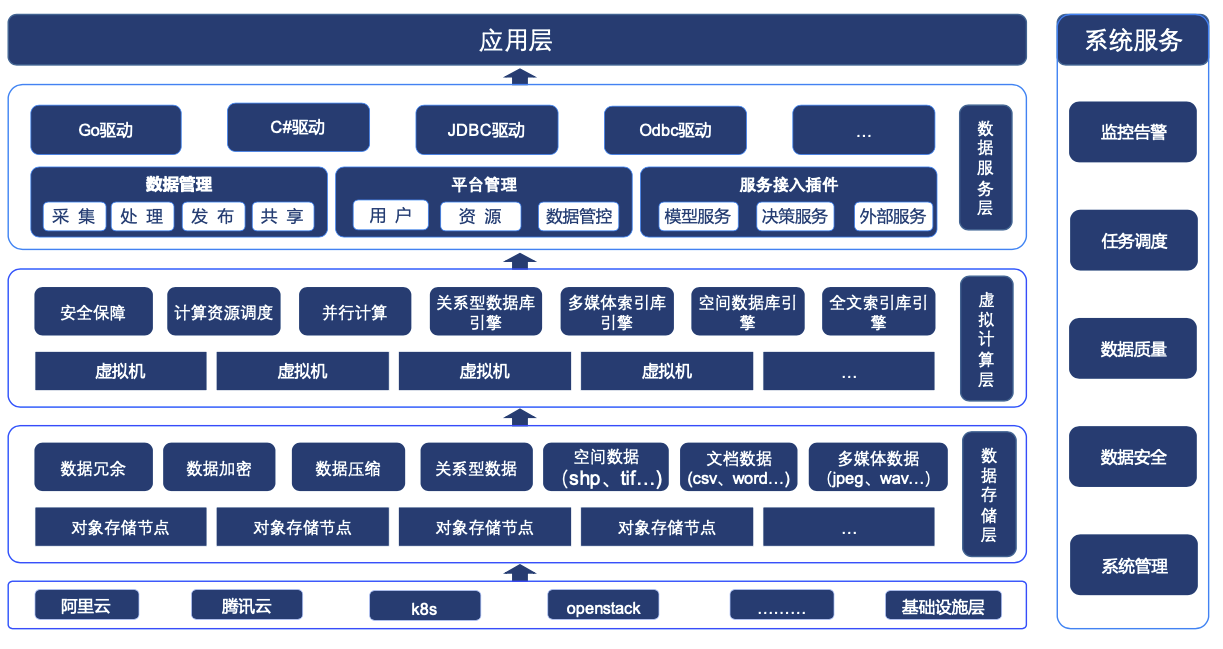
尤其是 Cloudwave 所支援的並行全文檢索功能令我印象深刻,這個功能在文字資訊處理場景中非常必要。下面參照了《翰雲資料庫技術白皮書》中的一段介紹。更多的技術細節也推薦閱讀這本技術白皮書。
Cloudwave 能夠對 CLOB 大文字欄位以及 Bfile 檔案(e.g. 常用的 PDF、Word、 Excel、PPT、Txt 以及 Html 等)實現全文索引功能,實現了基於 HDFS 的 Lucene 索引儲存,保證了索引資料的安全性,並對 Lucene 索引資料進行自動分段,由多伺服器均衡管理。全文檢索時,多伺服器對索引段並行檢索,這樣就提高了查詢效率。處理 Bfile 型別的檔案時,利用現有的解析類庫,從不同格式的檔案中偵測和提取出後設資料和結構化內容。
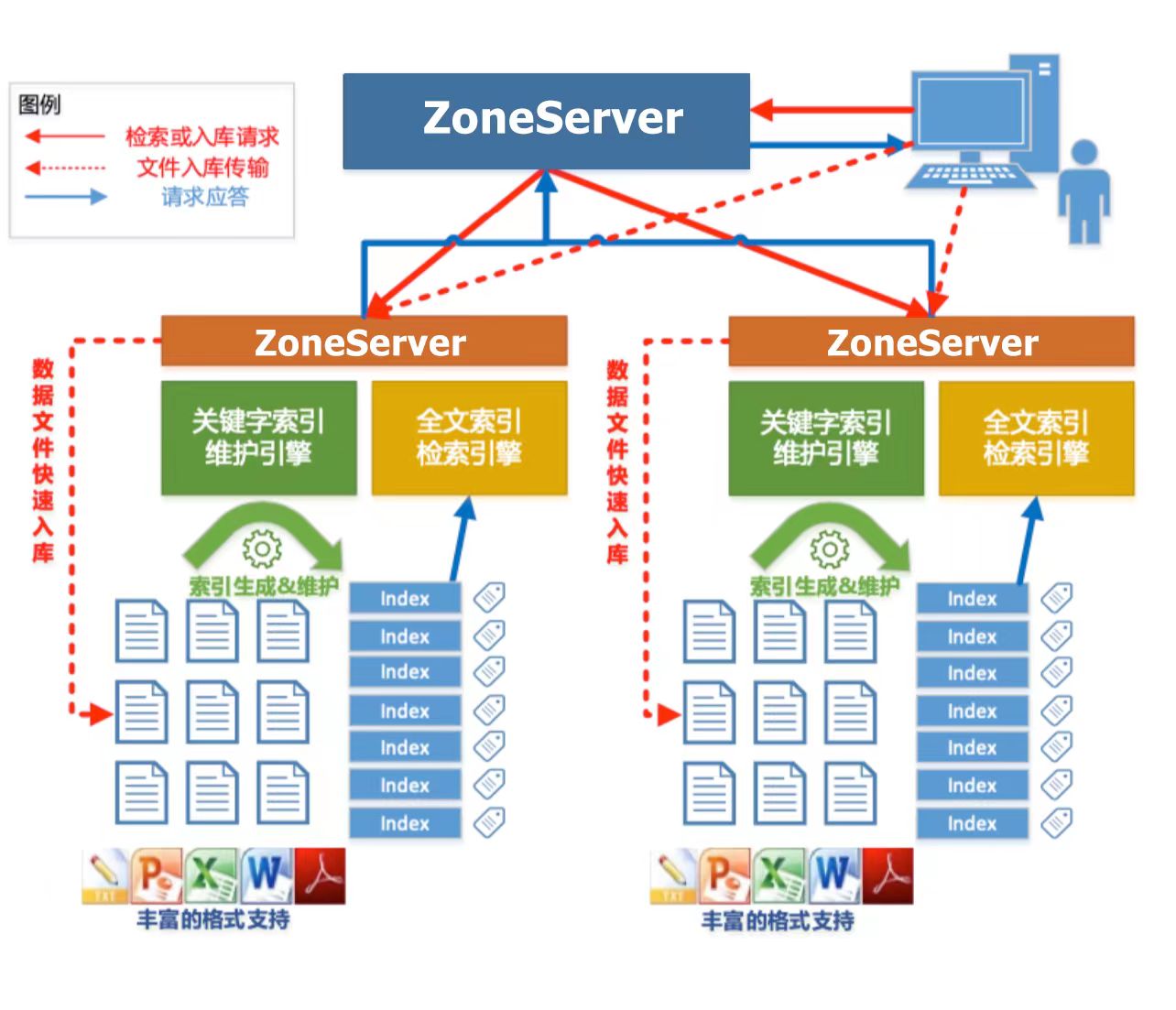
此外,Cloudwave 雲原生資料倉儲還整合了雲原生架構技術體系,帶來了更多的叢集化管理優勢,例如:
- 彈性擴充套件性:支援根據需求進行彈性擴充套件,根據資料量和工作負載的變化自動調整資源。這使得資料倉儲能夠處理大規模資料集和高並行查詢,並滿足不斷增長的業務需求。
- 靈活性和敏捷性:可以快速適應業務變化和新的資料分析需求,支援與多種雲原生平臺上多種分析工具和技術的無縫整合。
- 強大的生態系統支援:便於與其他雲服務和工具進行整合,例如:機器學習平臺、視覺化平臺等等。它與雲提供商的生態系統緊密結合,能夠快速獲取最新的技術和功能更新,並獲得強大的支援和服務。