記一次etcd全域性鎖使用不當導致的事故
1、背景介紹
前兩天,現場的同事使用開發的程式測試時,發現紀錄檔中報etcdserver: mvcc: database space exceeded,導致 etcd 無法連線。很奇怪,我們開發的程式只用到了 etcd 做程式的主備,並沒有往 etcd 中寫入大量的資料,為什麼會造成 etcd 空間不足呢?趕緊叫現場的同事查了下 etcd 儲存資料的目錄以及 etcd 的狀態,看看是什麼情況。

檢視 etcd 狀態:
./etcdctl endpoint status --write-out=table --endpoints=localhost:12380

看到這裡就很奇怪了,為什麼 RAFT APPLYEND INDEX 會這麼大呢?這完全是不正常的。
想到程式中有主備,程式啟動時,會去 etcd 中 trylock 相應的鎖,獲取不到時,則會定期去 trylock,會不會是這裡的備節點 定期去 trylock 導致 RAFT APPLYEND INDEX 持續增長從而導致 etcd 空間不足呢?
後面測試了一下,不啟動備節點時,RAFT APPLYEND INDEX 是不會增大的。那麼問題的原因找到了,問題也就比較好解決。
雖然 etcd 提供了 compact 的能力,但是對於我們這個現象,是治標不治本的,所以最好還是從源頭解決問題比較好。當然也可以使用 compact 來壓縮 etcd 的 歷史資料,但是需要注意的是 compact 時,etcd 的效能是會收到影響的。
2、場景復現
etcd client 版本
go.etcd.io/etcd/client/v3 v3.5.5
etcd server 版本
etcd-v3.5.8-linux-amd64
模擬程式碼如下:
package main
import (
"context"
"fmt"
clientv3 "go.etcd.io/etcd/client/v3"
"go.etcd.io/etcd/client/v3/concurrency"
"time"
)
var TTL = 5
var lockName = "/TEST/LOCKER"
func main() {
config := clientv3.Config{
Endpoints: []string{"192.168.91.66:12379"},
DialTimeout: 5 * time.Second,
}
// 建立連線
client, err := clientv3.New(config)
if err != nil {
fmt.Println(err)
return
}
session, err := concurrency.NewSession(client, concurrency.WithTTL(TTL))
if err != nil {
fmt.Println("concurrency.NewSession failed, err:", err)
return
}
gMutex := concurrency.NewMutex(session, lockName)
ctx, _ := context.WithCancel(context.Background())
if err = gMutex.TryLock(ctx); err == nil {
fmt.Println("gMutex.TryLock success")
} else {
if err = watchLock(gMutex, ctx); err != nil {
fmt.Println("get etcd global key failed")
return
}
}
// 啟動成功,做具體的業務邏輯處理
fmt.Println("todo ..............")
select {}
}
func watchLock(gMutex *concurrency.Mutex, ctx context.Context) (err error) {
ticker := time.NewTicker(time.Second * time.Duration(TTL))
for {
if err = gMutex.TryLock(ctx); err == nil {
// 獲取到鎖
return nil
}
select {
case <-ctx.Done():
return ctx.Err()
case <-ticker.C:
continue
}
}
}
將上述程式碼編譯成可執行檔案 main.exe、main1.exe 後,先後執行上面兩個可執行檔案,然後通過下面的命令檢視 etcd 中的 RAFT APPLYEND INDEX ,會發現,RAFT APPLYEND INDEX 每隔五秒鐘就會增長,長時間執行就會出現 etcdserver: mvcc: database space exceeded。
3、如何解決
上面我們已經復現了RAFT APPLYEND INDEX,其實解決起來也比較簡單,主要思路就是不要在 for 迴圈中 使用 trylock 方法。具體程式碼如下:
package main
import (
"context"
"fmt"
clientv3 "go.etcd.io/etcd/client/v3"
"go.etcd.io/etcd/client/v3/concurrency"
"time"
)
var TTL = 5
var lockName = "/TEST/LOCKER"
func main() {
config := clientv3.Config{
Endpoints: []string{"192.168.91.66:12379"},
DialTimeout: 5 * time.Second,
}
// 建立連線
client, err := clientv3.New(config)
if err != nil {
fmt.Println(err)
return
}
session, err := concurrency.NewSession(client, concurrency.WithTTL(TTL))
if err != nil {
fmt.Println("concurrency.NewSession failed, err:", err)
return
}
gMutex := concurrency.NewMutex(session, lockName)
ctx, _ := context.WithCancel(context.Background())
if err = gMutex.TryLock(ctx); err == nil {
fmt.Println("gMutex.TryLock success")
} else {
if err = watchLock(client, gMutex, ctx); err != nil {
fmt.Println("get etcd global key failed")
return
}
}
// 啟動成功,做具體的業務邏輯處理
fmt.Println("todo ..............")
select {}
}
func watchLock(client *clientv3.Client, gMutex *concurrency.Mutex, ctx context.Context) (err error) {
watchCh := client.Watch(ctx, lockName, clientv3.WithPrefix())
for {
select {
case <-ctx.Done():
return ctx.Err()
case <-watchCh:
if err = gMutex.TryLock(ctx); err == nil {
// 獲取到鎖
return nil
}
}
}
}
將上述程式碼編譯成可執行檔案 main.exe、main1.exe 後,先後執行上面兩個可執行檔案,然後通過下面的命令檢視 etcd 中的 RAFT APPLYEND INDEX ,不會出現RAFT APPLYEND INDEX 持續增長的現象,也就是從源頭解決了問題。
4、TryLock 原始碼分析
以下是自己的理解,如果有不對的地方,請不吝賜教,十分感謝
那下面一起看看 TryLock 方法裡面做了什麼操作,會導致 RAFT APPLYEND INDEX 持續增長呢。
TryLock 方法原始碼如下:
func (m *Mutex) TryLock(ctx context.Context) error {
resp, err := m.tryAcquire(ctx)
if err != nil {
return err
}
// if no key on prefix / the minimum rev is key, already hold the lock
ownerKey := resp.Responses[1].GetResponseRange().Kvs
if len(ownerKey) == 0 || ownerKey[0].CreateRevision == m.myRev {
m.hdr = resp.Header
return nil
}
client := m.s.Client()
// Cannot lock, so delete the key
// 這裡的 client.Delete 會走到 raft 模組,從而使 etcd 的 raft applyed index 增加 1
if _, err := client.Delete(ctx, m.myKey); err != nil {
return err
}
m.myKey = "\x00"
m.myRev = -1
return ErrLocked
}
tryAcquire 方法原始碼如下:
// 下面主要是使用到了 etcd 中的事務,
func (m *Mutex) tryAcquire(ctx context.Context) (*v3.TxnResponse, error) {
s := m.s
client := m.s.Client()
// m.myKey = /TEST/LOCKER/326989110b4e9304
m.myKey = fmt.Sprintf("%s%x", m.pfx, s.Lease())
// 這裡就是定義一個判斷語句,建立 myKey 時的版本號是否 等於 0
cmp := v3.Compare(v3.CreateRevision(m.myKey), "=", 0)
// put self in lock waiters via myKey; oldest waiter holds lock
// 往 etcd 中寫入 myKey
put := v3.OpPut(m.myKey, "", v3.WithLease(s.Lease()))
// reuse key in case this session already holds the lock
// 查詢 myKey
get := v3.OpGet(m.myKey)
// fetch current holder to complete uncontended path with only one RPC
getOwner := v3.OpGet(m.pfx, v3.WithFirstCreate()...)
// 這裡是重點,判斷 cmp 中的條件是否成立,成立則執行 Then 中的語句,否則執行 Else 中的語句
// 這裡的語句肯定是成功的,因為我們測試的環境是執行兩個不同的 session
// 簡單的可以理解為兩個不同的程式,實際上是 兩個不同的對談就會不同
// 所以我們這裡的場景是 會執行 v3.OpPut 操作。所以這裡會增加一次 revision
// 即 etcd 的 raft applyed index 會增加 1
resp, err := client.Txn(ctx).If(cmp).Then(put, getOwner).Else(get, getOwner).Commit()
if err != nil {
return nil, err
}
m.myRev = resp.Header.Revision
if !resp.Succeeded {
m.myRev = resp.Responses[0].GetResponseRange().Kvs[0].CreateRevision
}
return resp, nil
}
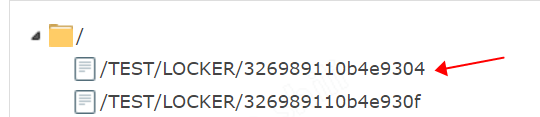
下面這張圖是 debug 時,先啟動一個可執行檔案,然後使用 debug 方式啟動的程式,程式執行完 tryAcquire 方法後,擷取的一張圖,這也作證了上面的分析。304 這個 key 是之前啟動程式就存在的 key,下面 30f 的 key 是 debug 期間生成的 key。
大家如果有不清楚的地方,親自去偵錯下,看看程式碼,就會明白上面說的內容了。
5、思考
其實,這並不是難以考慮到的問題,程式碼中出現這個問題,主要是自己對 etcd 的瞭解程度不夠,不清楚 TryLock 的原理,以為像簡單的查詢Get那樣,不會導致 revision 的增長,但實際上並不是這樣。而是生產中出現了問題才去看為什麼會這樣,然後再去解決問題,這是一種不太好的方式,希望以後在編碼的時候,儘量多考慮考慮,減少問題出現。
想起來前幾天看到一篇問題,也是 for 迴圈中的出現的問題,原文連結,感謝可以去看看 Go坑:time.After可能導致的記憶體洩露問題分析