萬字長文解析最常見的資料庫恢復演演算法: ARIES
萬字長文解析最常見的資料庫恢復演演算法: ARIES
Introduction
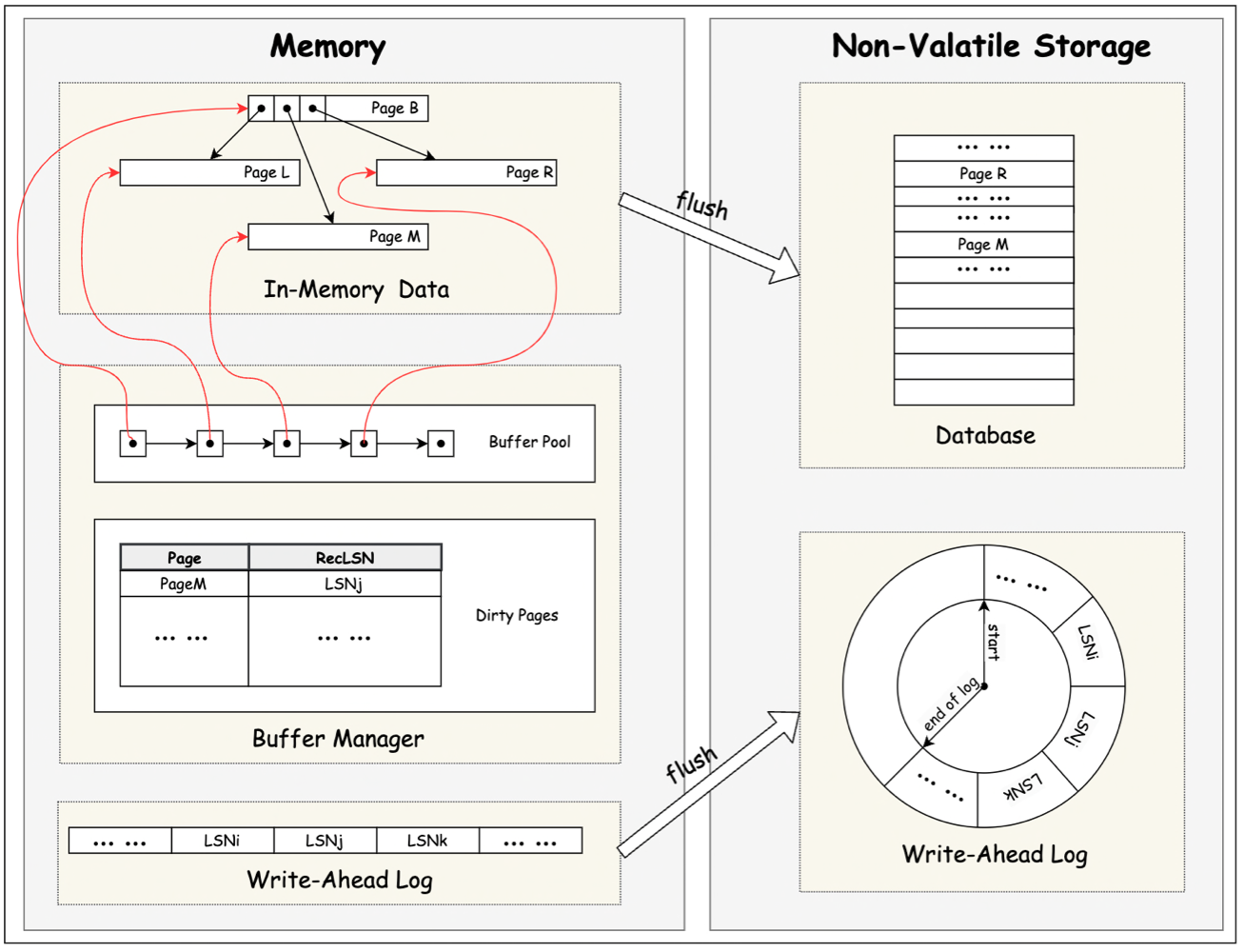
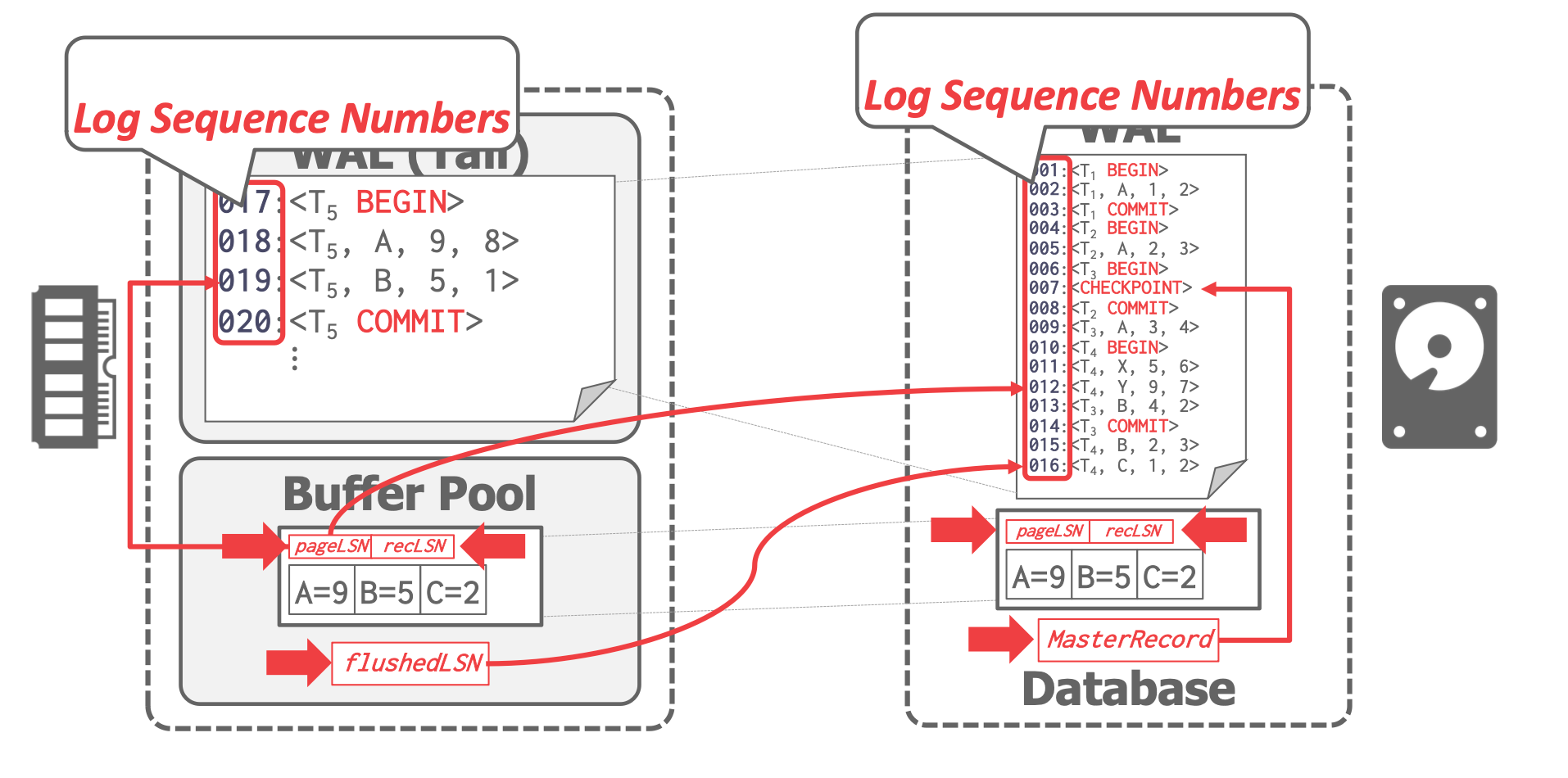
上圖中為基於 WAL 的資料庫的一種可能的架構情況。其中,In-Memory Data 為資料庫資料在記憶體中的組織形式,可以是 B 樹,也可以是 hash table 或者其他可能的資料結構。Non-Valatile Storage 中的 Database 為這些資料重新整理(flush)到持久化儲存之後的組織形式。
Buffer Manager
Buffer Manager(BM) 控制 In-Memory Data 及其持久化資料之間的讀寫邏輯。當用戶存取的資料不在 In-Memory Data 中, BM 會去 Non-Valatile Storage 中讀取磁碟中該資料對應的 Page,並將其交由 Buffer Pool 管理。如果 Memory 中的剩餘空間不足以讀取該 Page,BM 會根據指定的置換演演算法先將 Buffer Pool 中的部分 Page 逐出(evict)然後再讀取。
當我們需要對某個 page 做操作時,需要先將這個 page fix 到 In-Memory Data 中。如果 page 不在記憶體中,fix 操作會將該 page 從磁碟中讀取到記憶體。並且會讓該 page 不會被置換演演算法逐出。當操作完成之後,對該 page 執行 unfix 操作,解除對該 page 的限制。
為了減少 I/O 對效能的影響,使用者對 In-Memory Data 的變更,並不會立刻 flush 到 Non-Valatile Storage , 這會導致 它們中的資料可能會存在版本不一致的情況。BM 會 In-Memory Data 中比 Non-Valatile Storage 資料版本更新的資料由 Dirty Pages 統一維護起來,按照一定的規則統一 flush。(比如後臺程序定期 flush;或是指定節點強制 flush)
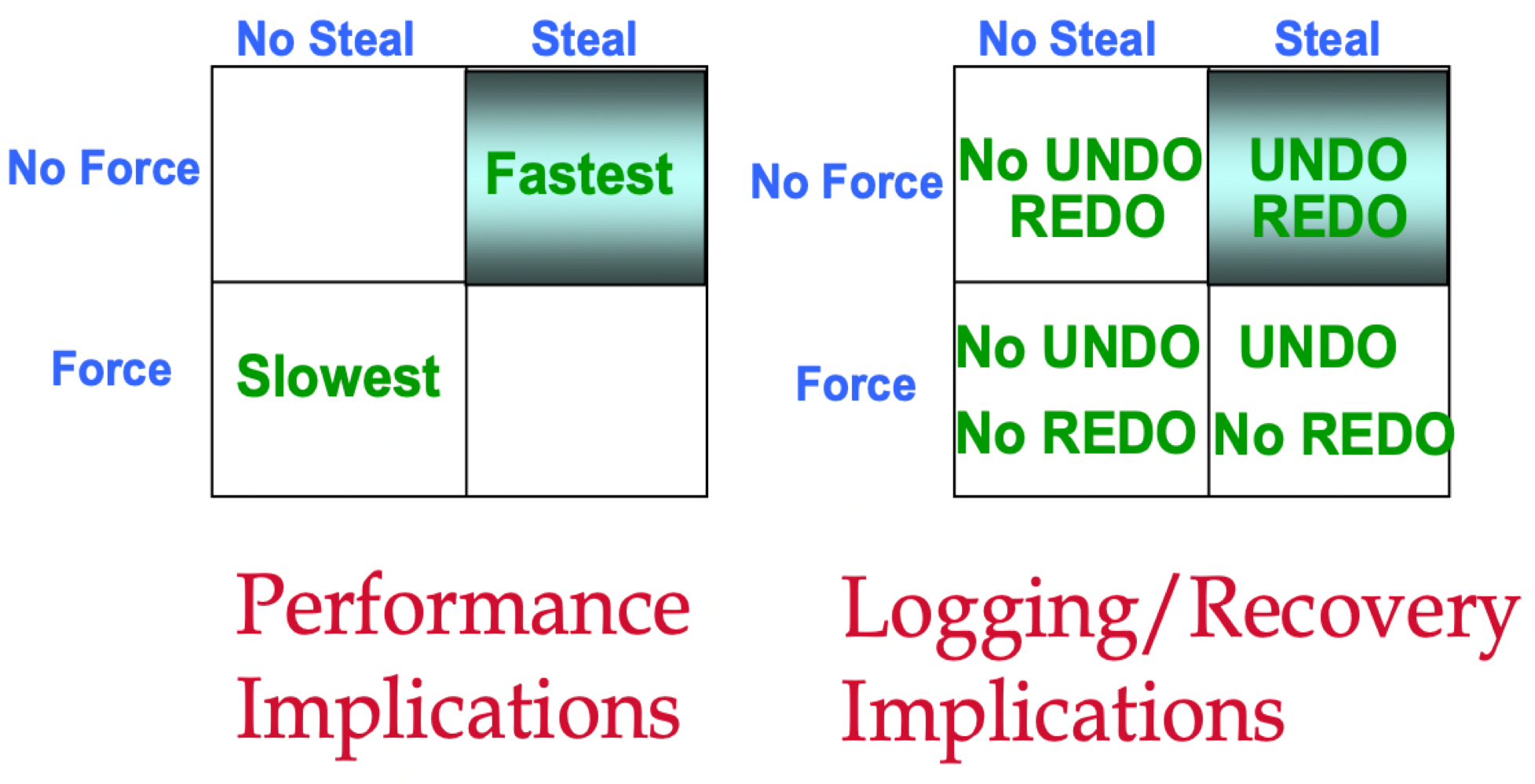
對 Buffer Pool 的管理有兩組策略來控制 flush 邏輯,第一組是 Steal/No-Steal :
- STEAL: 變更中的 page 隨時都可以被 flush 到持久化儲存(即使變更事務還未結束)
- NO-STEAL: 在涉及該 page 變更的事務結束(end of transaction, EOT)之前 ,不允許被 flush 到持久化儲存。
另一組是 Force/No-Force:
- FORCE: 在事務 commit 結束之前,需要確保事務所變更的 page 都已經 flush 到了持久化儲存。
- NO-FORCE: 在事務 commit 結束之前,不強制 flush。
一般來說 No-Force + Steal 因為不用強制刷屏,並且允許非同步程序在任意時刻刷盤,所以效能最好。但是它的代價是需要同時維護 UNDO 和 REDO log 來保證資料的完整性和一致性。ARIES 就採用的是 No-Force + Steal 策略。
WAL(Write-Ahead Log) 紀錄檔
設想一下這個場景:某個請求對 In-Memory Data 的某個 Page X 做了變更。但在 Page X flush 進 Non-Valatile Storage 之前,整個系統因為某種原因重啟了。此時,Page X 未 flush 的變更將會丟失。如果這部分變更之前已經 commit, 使用者將會感知到資料丟失的發生。
為了解決上述問題, 我們需要使用 Write-Ahead Log(WAL),將 Dirty Pages 的變更提前寫入 WAL 紀錄檔。這樣在系統重啟後,我們就可以通過 WAL 紀錄檔將 Dirty Pages 的變更恢復。 WAL 可以同步 flush,也可以較大頻率的定期 flush。只有在某個事務 Txn 對應 WAL 紀錄檔已經全部 flush 成功的情況下,我們才認為事務 Txn commit 成功,可以向用戶做出事務提交成功的響應。
一般來說 WAL log 有一下幾類:
-
REDO LOG: 提供某個變更操作的重做資訊。
-
UNDO LOG: 提供某個變更操作的回滾資訊。
-
UNDO-REDO LOG: 既包含 REDO 資訊又包含 UNDO 資訊的紀錄檔。
-
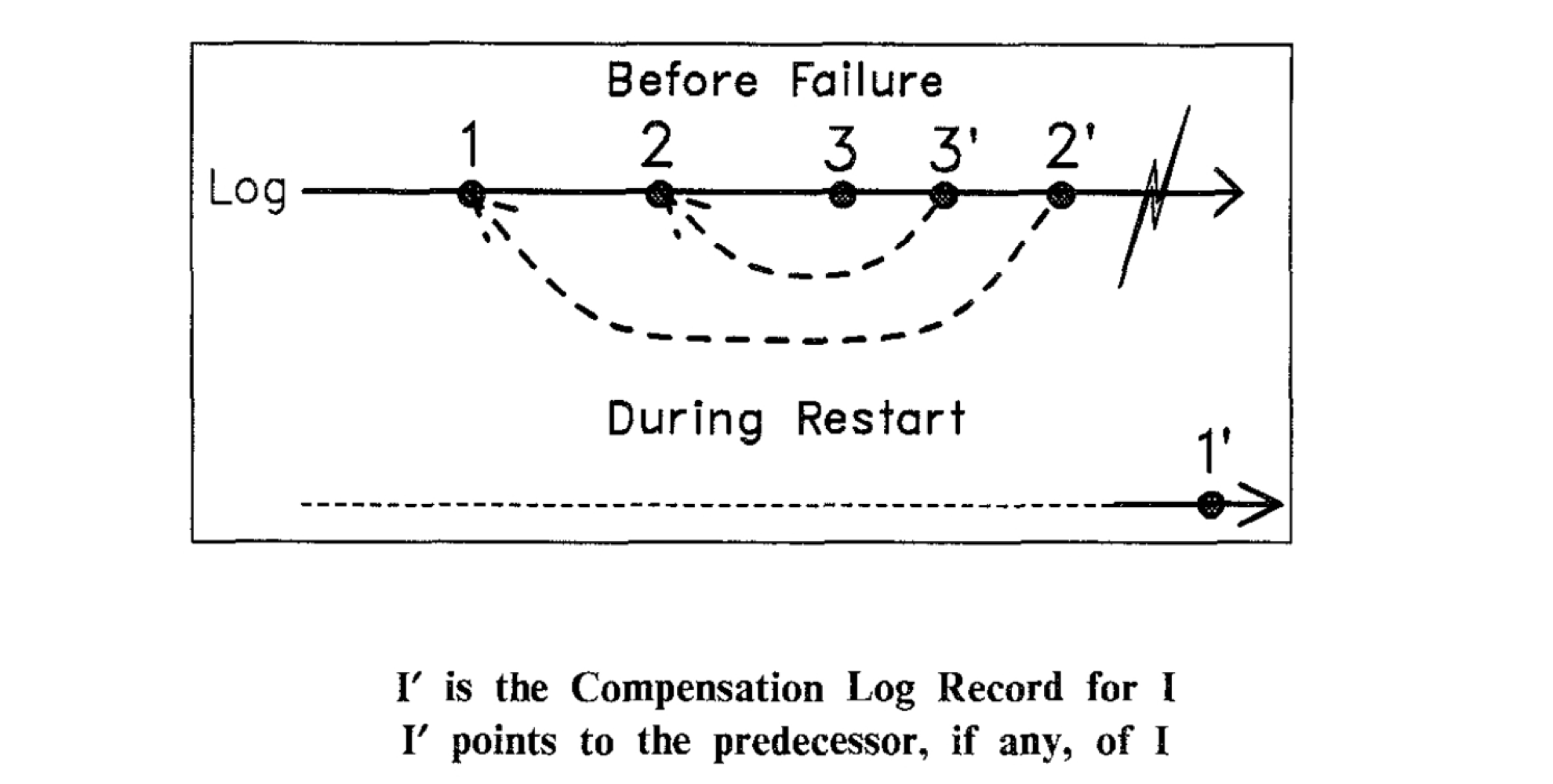
Compensation Log Record(CLR): Undo 操作的 Redo Log。在 ARIES 中, 它是 Redo-only 紀錄檔。由於 UNDO 操作的資訊在之前的被 Undo 的原操作操作對應的 WAL log 已經包含,因此,當我們在記錄這條 UNDO 操作的 WAL log(redo-only) 時,僅需補償指出它要 UNDO 的原操作的前一條操作,以便在 restart 過程中,快速定位到下一個待 UNDO 的原操作。
在下圖中,系統在 Recovery 過程中, 通過 CLR 紀錄檔 2’ 的資訊發現當前應該對 1 進行回滾操作。因此,在 UNDO 階段,對 1 進行回滾操作,並記錄下它的 CLR 紀錄檔 1'。
WAL 協定保證在某個 page 的變更 flush 到持久化儲存之前,它所對應的 WAL 紀錄檔已經寫入持久化儲存。也就是說,至少保證某個變更的 UNDO log 已經 flush,才允許對應的變更 flush,只有這樣,我們才能保證未完成的事務可以順利的 UNDO。同時每個持久化的 page 攜帶有當前 page 上次刷盤對應的變更紀錄檔的 LSN,以便後續 recovery 操作時,定位該 page 的起始 redo log。
ARIES(Algorithms for Recovery and Isolation Exploiting Semantics) 是一種能夠恢復系統狀態並處理系統崩潰帶來的問題的重要技術。該演演算法為處理資料庫中的恢復、並行控制和事務管理問題等提供了全面的解決方案。它將上述的架構系統的整合在一起,提供一種通用化的處理思路。當前市面上絕大多數資料庫的 Recovery 邏輯都是基於 ARIES 優化改造實現的。
本文將詳細介紹 ARIES paper 的細節,完整展現資料庫系統是如何實現 Recovery 的。
ARIES 概覽
WAL 紀錄檔記錄
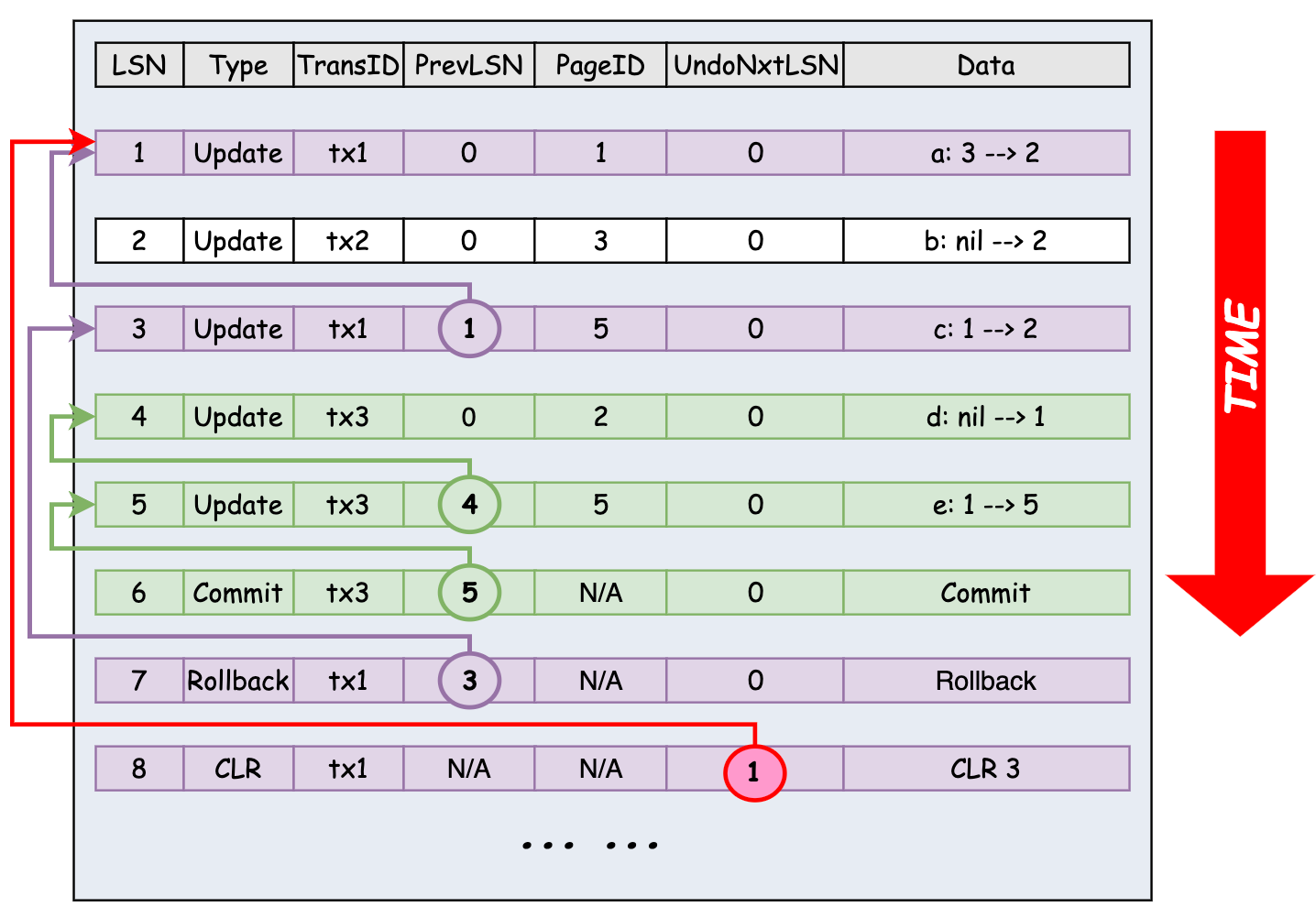
ARIES 的 WAL 紀錄檔記錄結構如下:
- LSN: WAL 紀錄檔記錄的第一個位元組的地址,這是一個單調遞增的值。
- Type: 表示WAL紀錄檔記錄的型別,可以是補償紀錄檔(compensation) 也可以是更新紀錄檔(update)或是其他型別的紀錄檔。
- TransID:如果 WAL 紀錄檔記錄屬於某個事務,則此欄位記錄該事務的 ID。否則,該欄位為空。
- PrevLSN: 記錄同一個事務的前序 WAL 紀錄檔記錄的 LSN。非事務相關或事務第一條紀錄檔記錄的 PrevLSN 為 0(避免顯式記錄 BEGIN_TRANSACTION)。
- PageID: 僅在 Type 為 update 和 compensation 的紀錄檔記錄中出現。標記當前紀錄檔涉及到變更的 Page。
- UndoNxtLSN: 僅在 Type 為 compensation 的紀錄檔記錄(CLR)中出現。記錄當前補償紀錄檔對應的原紀錄檔的 PrevLSN,標記 UNDO 過程中的下一個待處理的紀錄檔記錄的 LSN。如果該事務已經沒有可 UNDO 的紀錄檔,則該欄位為零。
- Data:記錄更新操作的 UNDO/REDO 資訊。
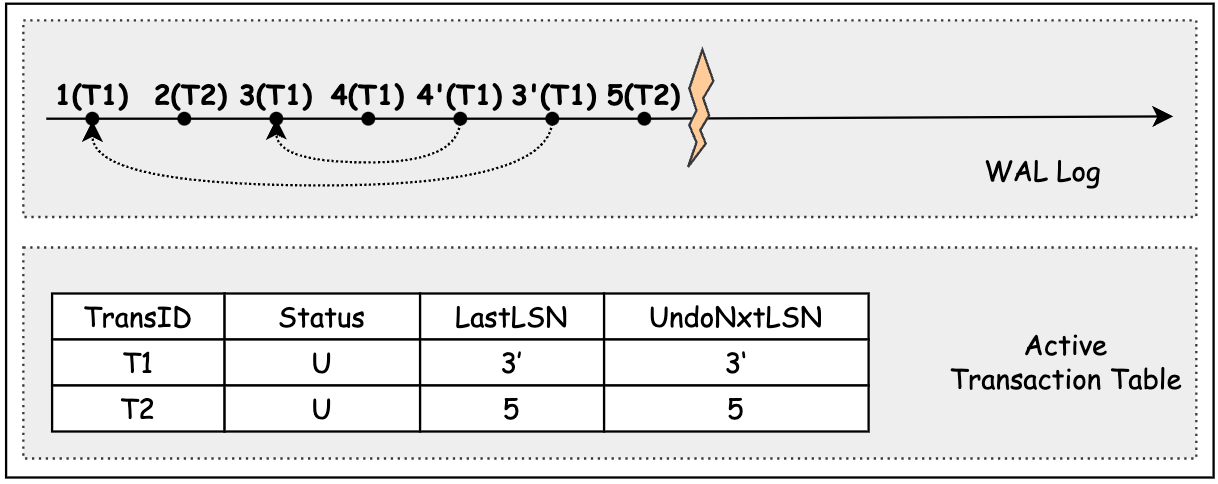
在下圖中,事務 tx1 在 LSN = 7 處回滾,開始執行回滾 LSN=3 的紀錄檔,併為其寫下 LSN = 8 的 CLR log, 該紀錄檔指向下一個待 UNDO 的紀錄檔的 LSN, 即 LSN = 3 的紀錄檔對應的 PrevLSN(1)。
Page 結構
在資料庫 Page 的元資訊中,維護了一個 PageLSN 欄位。該欄位記錄應用到該 Page 的最新的更新操作對應的 WAL 紀錄檔記錄的 LSN。
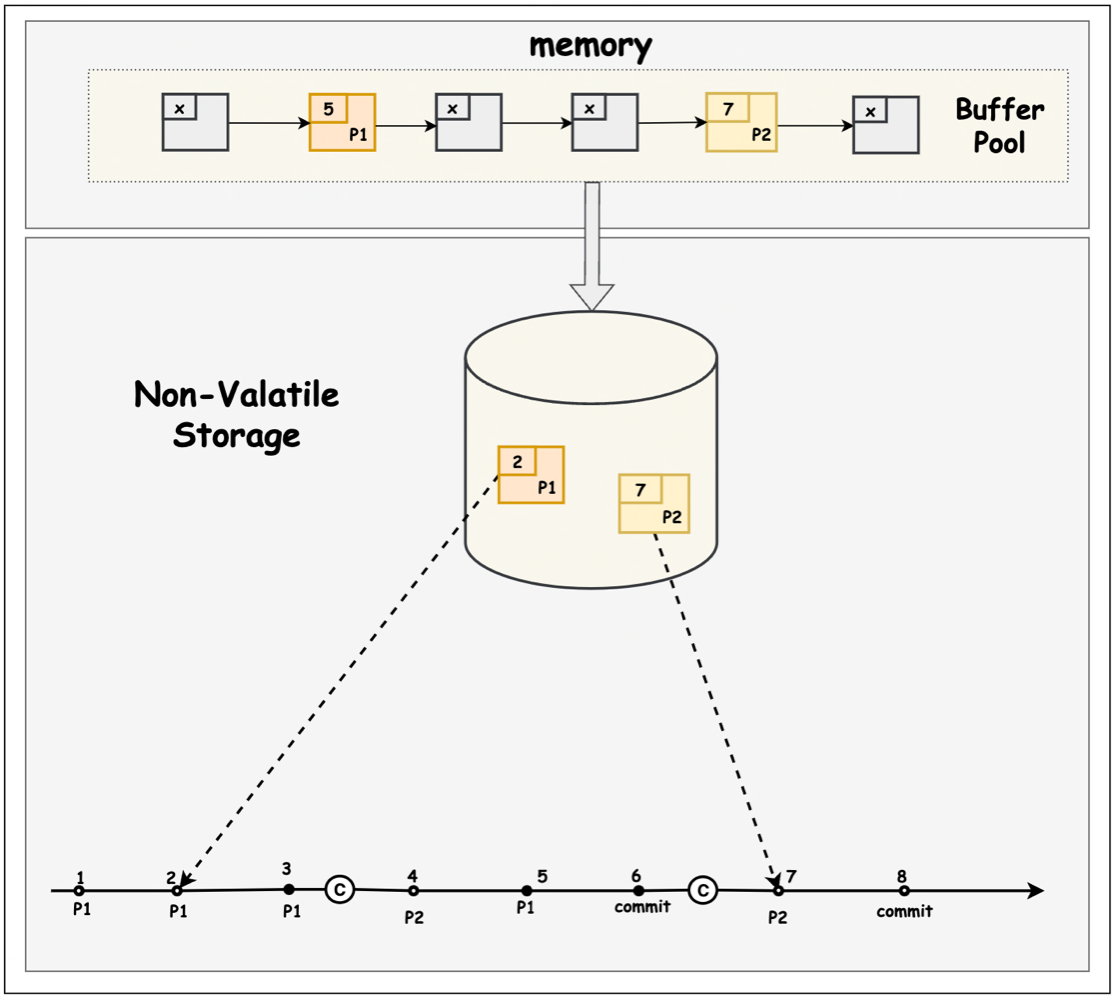
如在下圖中,下面的數軸表示 WAL 紀錄檔,數軸上面的數位表示 WAL 紀錄檔的 LSN。下面的 P1/P2 標記表示當前 WAL 紀錄檔涉及到變更的 Page。虛線箭頭表示 Page flush 的 LSN。
在該圖中, P1 flush 到了 PageLSN=2 處的紀錄檔,但其 buffer pool 中的資料已經變更到 PageLSN=5 處的紀錄檔(如果在當前狀態下 crash,則 P1 需要從 pageLSN = 2 之後開始 recovery)。
活躍事務表(Active Transaction Table, ATT)
ATT 是負責追蹤活躍事務的執行狀態的狀態表,包括以下欄位:
- TransID: 事務ID。
- State: 事務狀態。Prepared(P) 或 Unprepared(U)。
- LastLSN: 本事務已寫的最新的 WAL 紀錄檔記錄的 LSN。
- UndoNxtLSN: Rollback 過程中待處理的下一條 WAL 紀錄檔記錄的 LSN。如果當前事務的最新的 WAL 紀錄檔記錄不為 CLR 的 Undo-able紀錄檔,則該欄位設為 LastLSN。否則該欄位設為該 CLR 紀錄檔的 UndoNxtLSN。
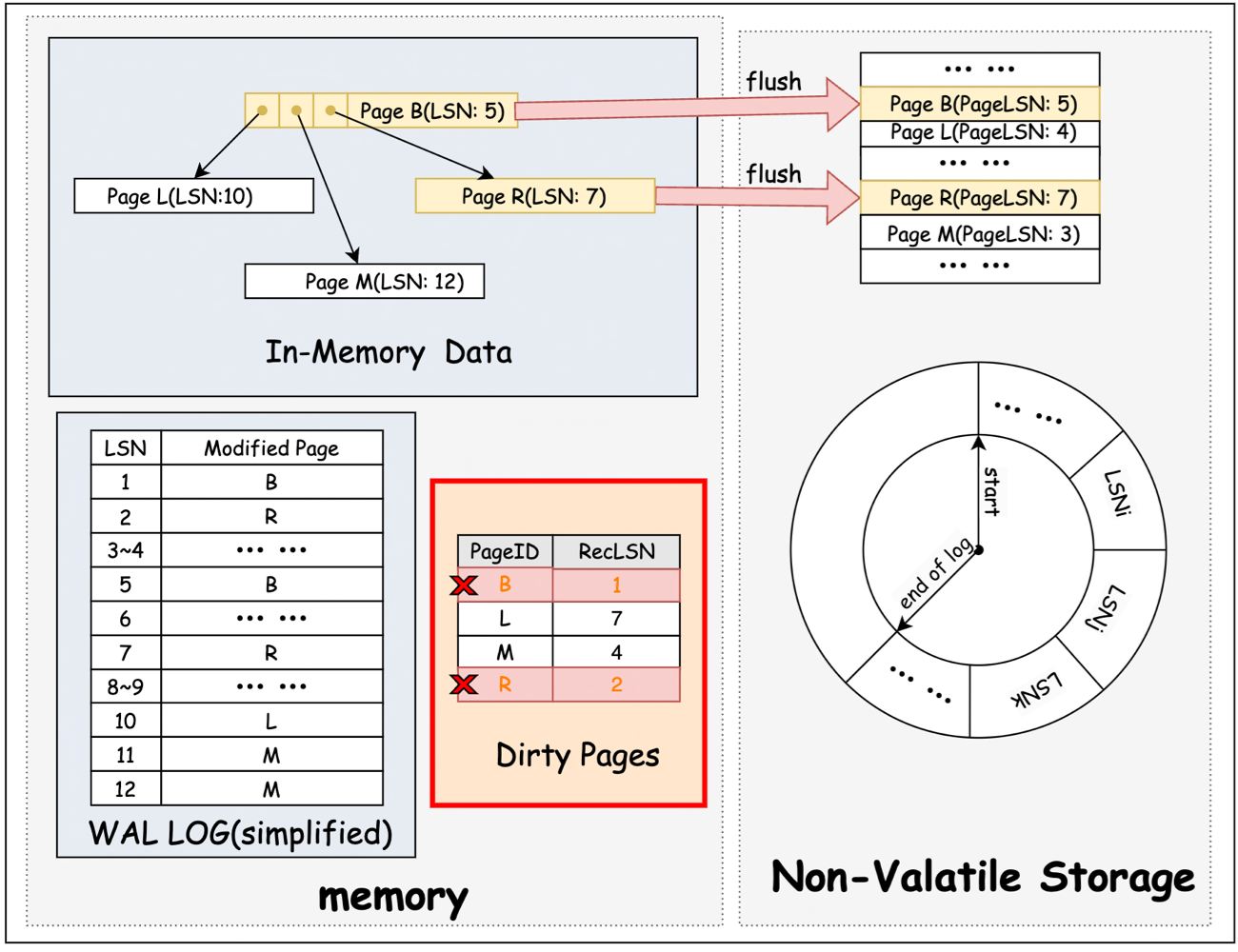
髒頁表(Dirty Page Table, DPT)
DPT 用於記錄資料庫執行過程中 Buffer Pool 中已變更但還未來得及 flush 到持久化儲存的 Page(即緩衝區中與持久化儲存版本不一致的 Page)。包含以下欄位:
- PageID: Dirty Page 的 ID
- RecLSN(Recovery LSN): 某個不在 Buffer Pool中的 Page,在準備變更前會將當前的 WAL 紀錄檔的下一條待寫入紀錄檔的 LSN 記錄為當前的 RecLSN。該 LSN 對應的紀錄檔將可能是該 Page 變更的第一條紀錄檔的寫入點(因為可能有其他並行操作,因此該 Page 也可能是在此 LSN 之後寫入),此時這些 Page 變更還未被 flush 到持久化儲存。當某個 Dirty Page 被 flush 到持久化儲存,該 Page 對應在 DPT 中的記錄將會被刪除。
在下圖中,page L 和 Page M 持久化儲存的資料版本早於記憶體中的資料版本,因此 Dirty Page 記錄了它們對應的 RecLSN。page B 和 Page R flush 最新資料到持久化儲存(記憶體資料和持久化儲存資料版本一致),因此可以從 Dirty Page 中刪除。
ARIES 的流程
-
資料庫正常執行狀態下,後臺任務定時重新整理資料庫執行狀態 checkpoint 到 WAL 紀錄檔中,記錄當前 DPT,ATT 的狀態。同時在持久化儲存的 Master Record 記錄最新的 checkpoint 起始 LSN。
-
事務的 Rollback :
- 從事務的 UndoNxtLSN 開始執行 UNDO 操作, * 如果該紀錄檔為 Undo-able 紀錄檔,則先在 buffer 中的 Page 執行 Undo 操作,然後在 WAL 中寫入補償紀錄檔(原紀錄檔的 PrevLSN 為補償紀錄檔的 UndoNxtLSN ),更新該事務的 LastLSN 為補償紀錄檔的 LSN,UndoNxtLSN 為原紀錄檔的 PrevLSN 。
- 如果該紀錄檔為補償紀錄檔,則將 市紀委 UndoNxtLSN 設為該補償紀錄檔的 UndoNxtLSN。
- 否則, 將事務的 UndoNxtLSN 設為當前紀錄檔的 PrevLSN。
*重複上述操作,知道 RollBack 完成。
- 從事務的 UndoNxtLSN 開始執行 UNDO 操作, * 如果該紀錄檔為 Undo-able 紀錄檔,則先在 buffer 中的 Page 執行 Undo 操作,然後在 WAL 中寫入補償紀錄檔(原紀錄檔的 PrevLSN 為補償紀錄檔的 UndoNxtLSN ),更新該事務的 LastLSN 為補償紀錄檔的 LSN,UndoNxtLSN 為原紀錄檔的 PrevLSN 。
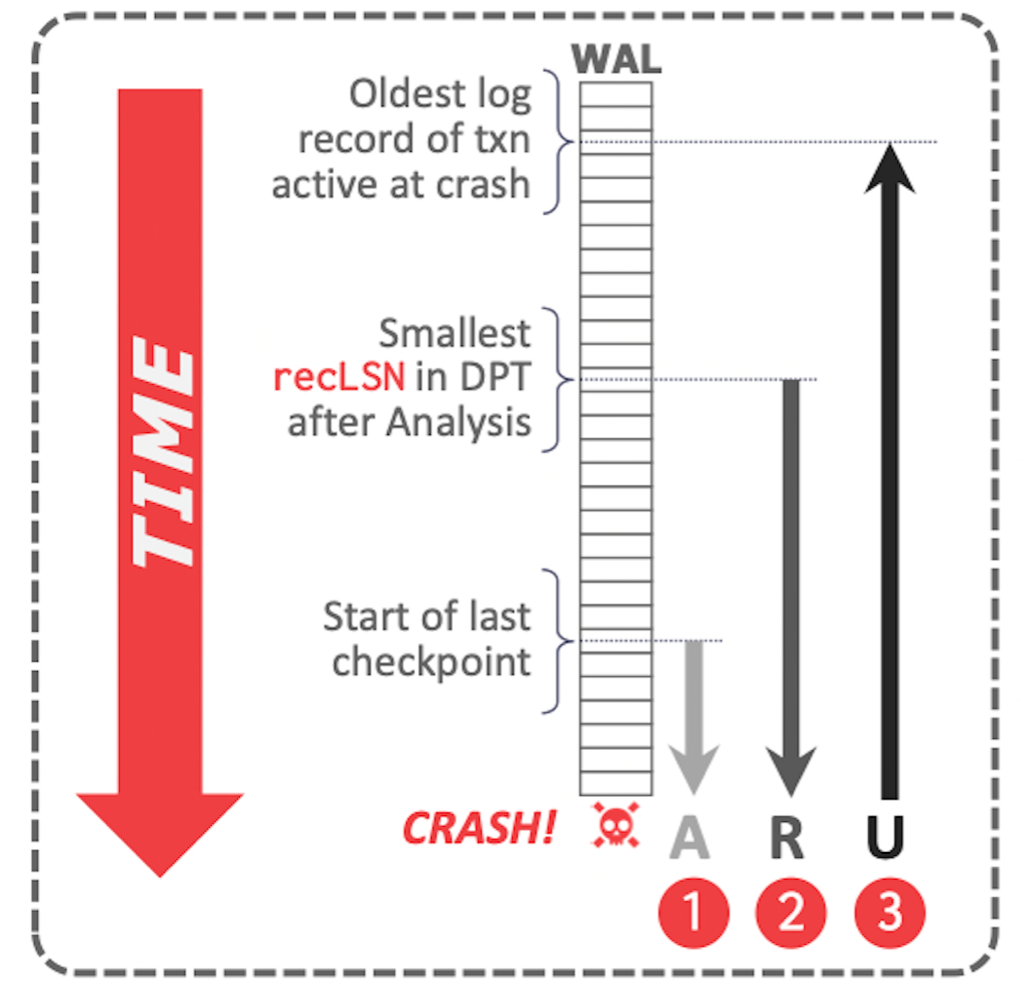
- Restart Recovery 的三個階段
- Analysis Pass: 先通過 Master Record 獲取最新的 checkpoint,並通過 checkpoint 恢復 ATT 和 DPT。然後獲取所有 Dirty Page 的最小 PageLSN 作為 REDO 的起點(RedoLSN)。同時梳理出正在 回滾的事務,在後續 Restart UNDO 階段繼續回滾。
- Redo Pass: 從 Redo LSN 開始順序執行 Redo log,直到 WAL 紀錄檔結尾(end of log)
- Undo Pass: 逆序遍歷處理 Rollback 事務,流程與正常的紀錄檔 Rollback 表現一致。
ARIES Normal Process
Update
ARIES Normal Process 流程如下圖,當服務接收到業務資料更新請求,會現在 BufferPool 中更新對應的 Page,如果它不在 Dirty Page 中,則將它加入 Dirty Page。然後在記憶體中的 WAL 紀錄檔增加本次變更的內容,最後將 WAL flush 到磁碟。當 WAL flush 到磁碟後,該資料更新請求完成,返回業務請求成功。
同時,非同步 flush 程序,定時將 Buffer Pool 中的 Page flush 到磁碟,並將其從 Dirty Page 中移除。
Rollback
為了支援部分回滾(partial rollback), 在事務執行過程中,會在特定時間節點建立 savepoint 記錄當前事務最新寫入的紀錄檔 LSN,記作 SaveLSN。如果當前事務還未寫入紀錄檔,則 SaveLSN 設為 0。
同一個事務可以根據需要維護任意多個 savepoint。當事務需要回滾到某個 savepoint 時, 它會從最新的 WAL 紀錄檔開始執行 UNDO 操作,指定指定 savepoint 對應的 SaveLSN 為止。
事務回滾過程中, SaveLSN 之後申請的 lock 也會被釋放(因為 ARIES 不會 UNDO CLR 紀錄檔, 因此在此場景下不再需要這些鎖)。因此,當系統檢測到出現死鎖問題時,僅需要 partial rollback 到指定 savepoint 即可解決, 而不用 total rollback。
回滾過程中, 會從 ATT 中記錄的 UndoNxtLSN 開始逆序 UNDO 所有可被 UNDO 的紀錄檔記錄,併為其記錄 REDO 紀錄檔(即 CLR 紀錄檔)。該 CLR 紀錄檔的 UndoNxtLSN 為原紀錄檔的 PrevLSN。因為 CLR 紀錄檔為 Redo-Only,因此,當 Rollback 過程中遇到 CLR 紀錄檔時,會直接跳過。
如果當前 UNDO 的原紀錄檔為非 CLR 紀錄檔,則下一個待 UNDO 的紀錄檔為當前原紀錄檔的 PrevLSN。 如果當前 UNDO 的原紀錄檔為 CLR 紀錄檔,則下一個待 UNDO 的紀錄檔為當前紀錄檔的 UndoNxtLSN(這將跳過已經被 UNDO 的紀錄檔)。
RollBack 虛擬碼如下:

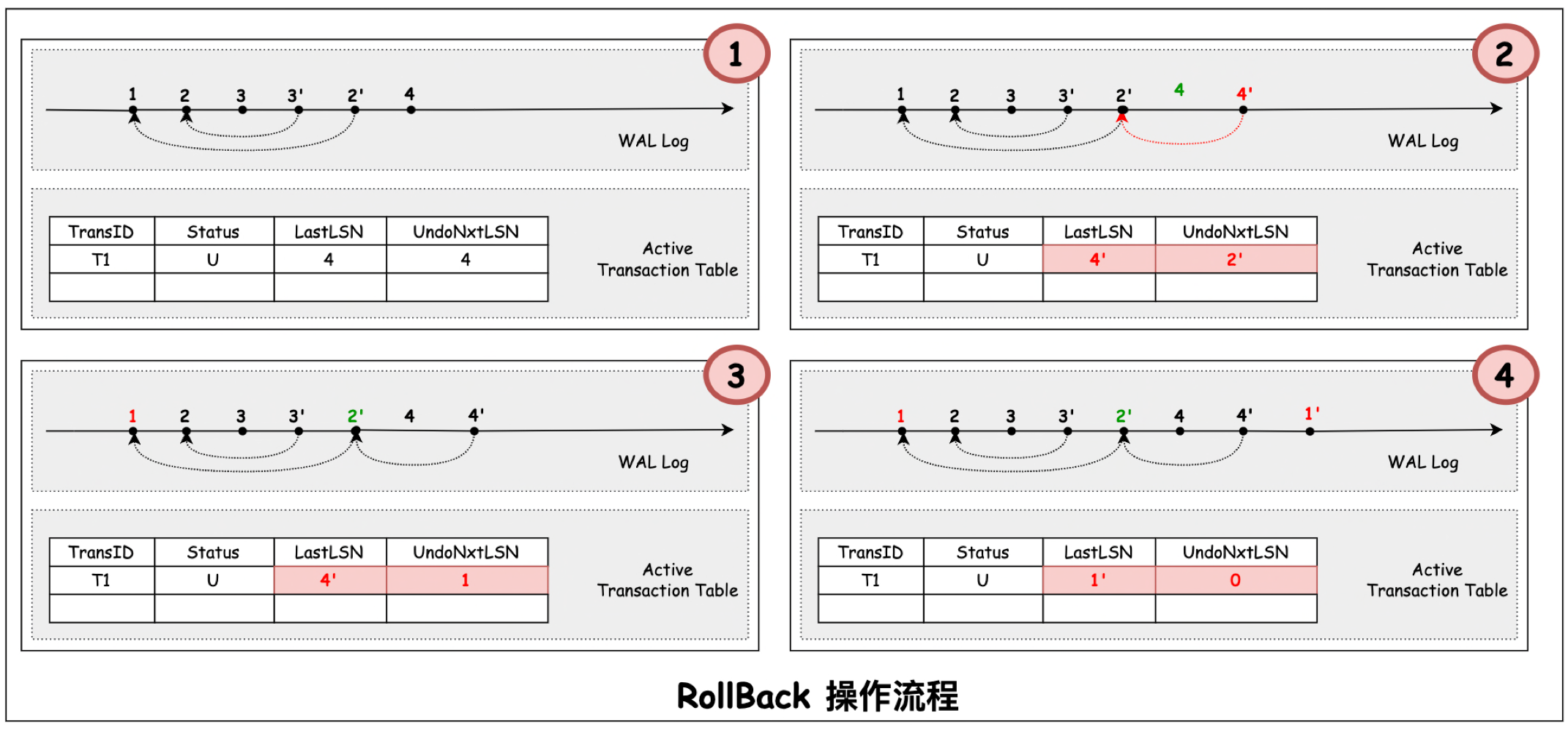
下圖展示了事務在回滾過程中的操作邏輯:
- 事務 T1 的 WAL log 2,3 已經完成 partial rollback,併產生 CLR 紀錄檔 3’和 2’。此時繼續推進事務寫入了 WAL 紀錄檔 4。此時 T1 因為某些原因需要完全 Rollback。
- 從 ATT 中讀取 T1 的 UndoNxtLSN(4)。該紀錄檔為非 CLR 紀錄檔,因此在 Undo 紀錄檔 4 的同時,需要為它寫入 CLR 4’, 4’ 的 UndoNxtLSN 指向事務 T1 中紀錄檔 4 的前驅紀錄檔 2’。同時更新 ATT 中 T1 的 LastLSN 為 4’, UndoNxtLSN 為 2’。
- 由於 2’ 為 CLR 紀錄檔,因此不需要對該紀錄檔做 Undo 操作。更新 ATT 中的 T1 的 UndoNxtLSN 為 2’的 UndoNxtLSN(1)。
- 紀錄檔 1 為非 CLR 紀錄檔,因此在 Undo 紀錄檔 1 的同時,需要為它寫入 CLR 1’。由於事務 T1 中沒有紀錄檔 1 的前驅紀錄檔,因此標記 CLR 1’ 的 UndoNxtLSN 為 0(標識已 Undo 完成)。同時更新 ATT 中 T1 的 LastLSN 為 1’, UndoNxtLSN 為 0。 此時事務 T1 Undo 完成,可以從 ATT 中刪除該事務。
Fuzzy Checkpoint
為了減少重啟恢復過程中需要處理的 WAL 紀錄檔的數量,ARIES 定期在 WAL 紀錄檔中記錄 Checkpoint 資訊。
Checkpoint 紀錄檔以 begin_chkpt 為起點,以 end_chkpt 為結束,記錄當前 ATT, DPT 的資訊,以及當前正在使用的檔案對映資訊等。只有當 end_chkpt 完全寫入的 Checkpoint 才是完整的,否則該 Checkpoint 資訊將會被忽略。
Checkpoint 構建和寫入過程中,並不阻塞其他的事務操作。比如下圖中, Checkpoint 的 begin_chkpt 和 end_chkpt 之間還有其他事務的紀錄檔寫入。既有 begin_chkpt 之前發起的事務 T1 的紀錄檔,也有 begin_chkpt 之後發起的事務 T2 的紀錄檔。它們既可以在 end_chkpt 之前結束(T2),也可以在 end_chkpt 之後結束(T1)。

ARIES 在構建 Checkpoint 過程中,並不需要強制 Dirty Page flush 到可持久化儲存。因為 flush 操作由 Buffer Manager 按照其策略自動執行,而 Checkpoint 只負責將當前時間節點下的 flush 狀態和其他必要資訊記錄下來,以便後續快速恢復。
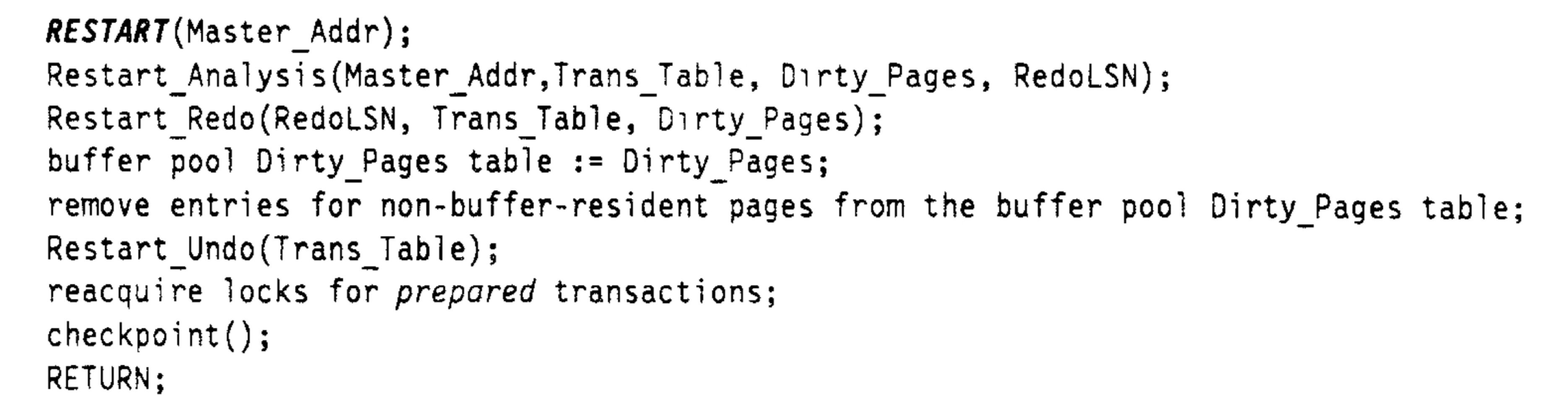
ARIES Restart Processing
當系統重啟,先從 MasterRecord 中讀取到系統終止前最新的完整記錄的 Checkpoint 的起始 LSN,然後依次執行重啟 Analysis 和重啟 Redo 並更新 DPT,接著執行重啟 Undo,併為所有的 prepare 狀態的事務重新獲取 lock。最後記錄新的 Checkpoint 記錄重啟流程的處理結果。虛擬碼如下圖:
Analysis Pass
分析階段會傳入 MasterRecord 的 LSN,並返回恢復後的 DPT 和 ATT,以及 REDO 開始的位置 RedoLSN。
初始化階段,通過 MasterRecord 的 LSN 讀取到 MasterRecord,然後利用 MasterRecord 記錄的最新 Checkpoint 的 begin_chkpt 的位置。然後,從 CheckPoint 的 begin_chkpt 開始分析 WAL 紀錄檔,直到 WAL 紀錄檔結束(end of log)。
在紀錄檔分析過程中,如果遇到 WAL 紀錄檔對應的事務不在 ATT 中,則將其加入 ATT。當分析的紀錄檔為 end_chkpt, 則通過 Checkpoint 紀錄檔記錄的資訊,恢復 ATT 和 DPT 的資料。如下圖虛擬碼所示:
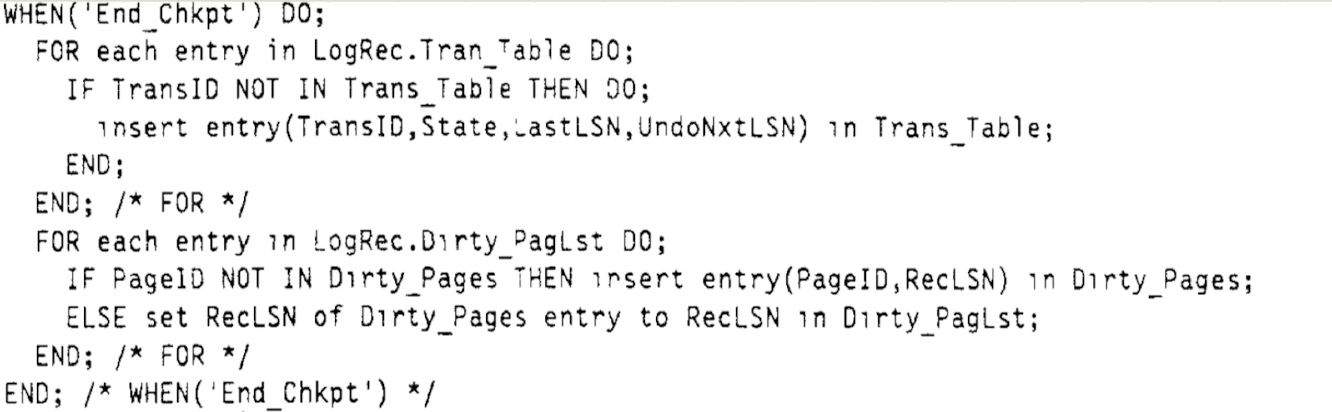
如 Normal Processing 所介紹那樣, Checkpoint 紀錄檔寫入期間,可能會並行存在其他並行寫入事務的紀錄檔。因此,在恢復 DPT 時,如果發現某個 Dirty Page 已經寫入被其他紀錄檔恢復到 DPT, 則只需要更新 DPT 中 該 Dirty Page 的 RecLSN 為 Checkpoint 記錄的 Dirty Page 的 RecLSN。
當分析的紀錄檔為 Update 或 CLR 紀錄檔,則在 Restart Redo 階段需要對它進行 REDO。因此在 DPT 中,如果不存在該紀錄檔對應的 Page,則需要將該紀錄檔對應的 Page 插入 DPT 中(該 Page 將在 Redo 階段變更)。
同時,在 ATT 中更新當前紀錄檔對應事務的 LastLSN 為當前紀錄檔的 LSN(事務最新紀錄檔的 LSN)。如果當前紀錄檔為 Update 且是可 Undo 的,則記錄將 ATT中該事務的 UndoNxtLSN 更新為當前紀錄檔的 LSN。如果當前紀錄檔為 CLR 紀錄檔,則該事務的 UndoNxtLSN 為當前紀錄檔的 UndoNxtLSN。
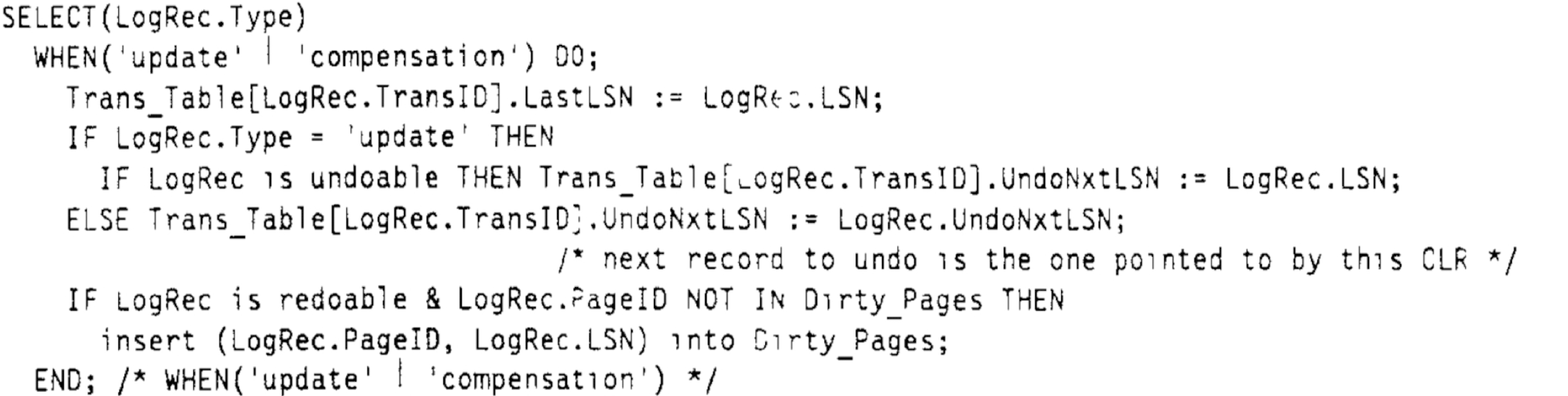
當分析到事務的 Prepare/Rollback 操作紀錄檔時,會將 ATT 表中當前紀錄檔對應事務的 LastLSN 設為當前紀錄檔的 LSN。同時,如果當前紀錄檔為 Prepare,將 ATT 中對應的 State 設為 「P(Prepared)」。 如果當前紀錄檔為 Rollback,則將 ATT 中對應 State 設為 「U(Unprepared)」。在 Undo 階段, 所有處於 「U」 狀態的事務,都將被回滾。
事務的 end 紀錄檔,表示事務已經成功的提交,因此不需要再 ATT 中維護這個事務。因此當分析到 end 紀錄檔時,直接在 ATT 中刪除對應事務。

在分析階段的最後,將 Redo 紀錄檔的起始位置 RedoLSN 設為 DPT 中所有 Dirty Page 的 RecLSN 的最小值。(如果 DPT 為空,則表示沒有需要 Redo 的紀錄檔,可以跳過 Redo 階段)。
完整虛擬碼如下:

Redo Pass
Redo 階段以分析階段生成的 RedoLSN 和 DPT 為輸入,從 RedoLSN 開始掃描處理紀錄檔,直到最後一條紀錄檔。
當遇到Redo 的紀錄檔記錄時,會檢查對應的 Page 是否在 DPT 中存在。如果存在,並且當前紀錄檔的 LSN 大於或等於表中該頁的 RecLSN,那麼該紀錄檔可能需要被 Redo。繼續讀取該頁的 PageLSN, 如果 PageLSN 小於當前紀錄檔的 LSN,則該紀錄檔需要重做。否則忽略該紀錄檔,
為什麼某個 Page 的 PageLSN 可能會不小於它在 DPT 的 RecLSN ?
因為 PageLSN 記錄的事實際 flush 到 Page 的 LSN, 而 RecLSN 記錄的是 Checkpoint 恢復的 Dirty Page 資訊。由於 Page Flush 和 Checkpoint 的 Flush 完全並行,互不影響, 因此可能存在 Checkpoint Flush 之後,再次執行了 Page Flush ,導致恢復的 Checkpoint Dirty Page 資訊延遲與實際 Page Flush 的資訊。因此 DPT 的 RecLSN 小於實際的 PageLSN。
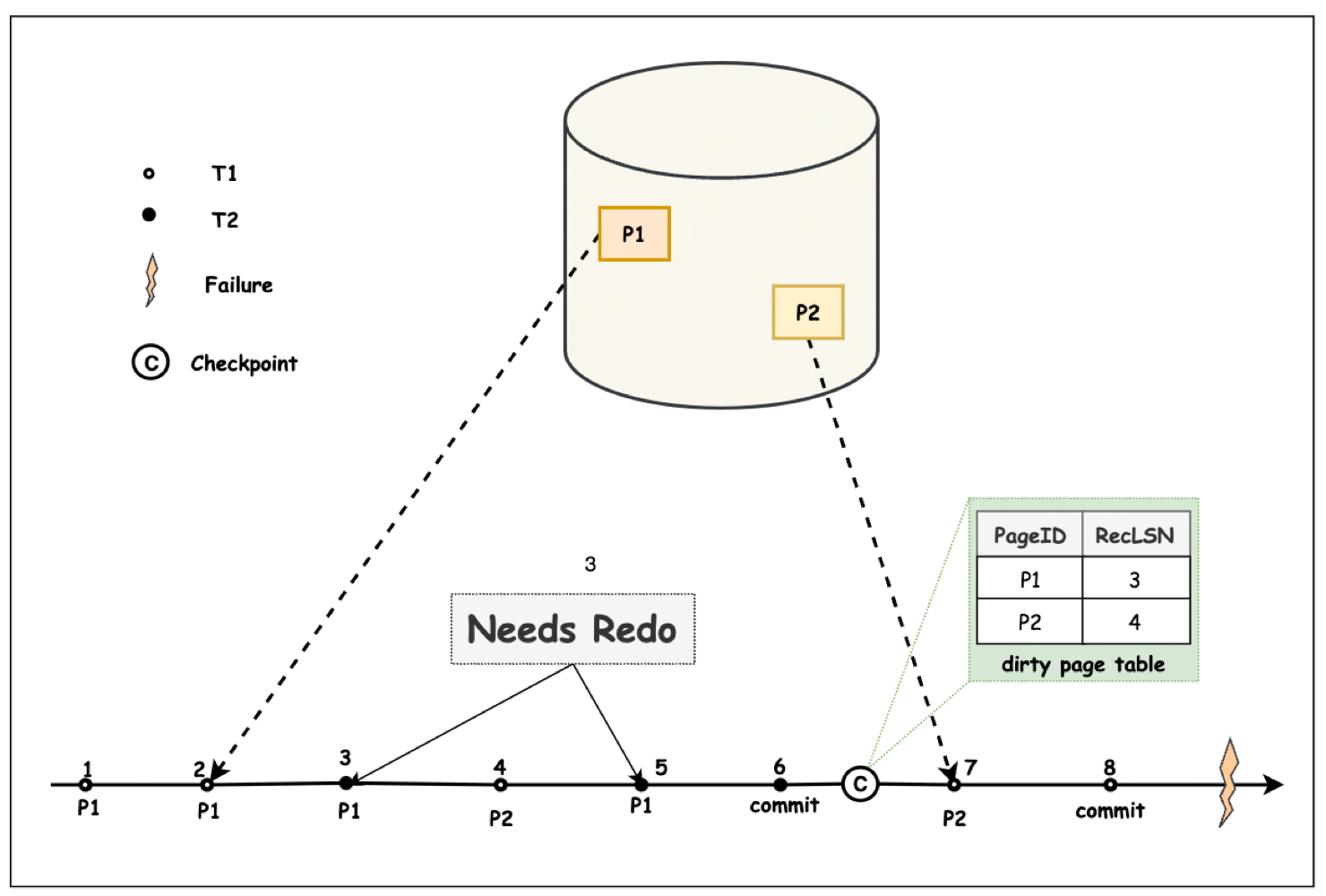
如上圖,空心點表示事務 T1 的 WAL 紀錄檔, 實心點表示 T2 的紀錄檔。虛線箭頭表示持久化儲存中的 P1, P2 當前 flush 的資料對應的最新的 LSN(即,PageLSN)。 可以看到在系統 Failure 時, 持久化儲存中的 P1 的 PageLSN 為 2, P2 的 PageLSN 為 7。
根據分析階段的結果, 在 Redo 時,會從 DPT 中最小的 RecLSN 作為 Redo 操作的起始紀錄檔 RedoLSN。在本例中 RedoLSN=3。
Redo 階段,從 Failure 前最新的 Checkpoint 記錄恢復的 DPT 中,P2 的 RecLSN 為 4(這個 Checkpoint 不知道在 LSN=7 處的紀錄檔已經 flush)。而P2 對應的 PageLSN 實際上為 7。此時的 P2 的 RecLSN <= PageLSN,因此 LSN 為 4 的操作已經被 flush 到持久化儲存,不需要 Redo。同理,也不需要 Redo LSN=7 的紀錄檔。
而 Checkpoint 記錄的 P1 的 RecLSN=3,大於 P1 flush 到 Page 的 LSN(PageLSN = 2)。因此,LSN 為 3, 5 的 WAL 紀錄檔對 P1 的變更還未被 flush 到持久化儲存,需要被 Redo。
在 Redo 階段執行的操作都不會記錄在 WAL log 中,因為它本身就是在 Redo 之前的 Redo Log(即執行的操作已經記錄)。
Redo 的完整虛擬碼如下:

Undo Pass
Undo 階段,以 ATT 作為引數,每次從 ATT 中讀取失敗事務(待回滾)最大的 UndoNxtLSN 處理,直到所有的回滾事務已經處理完成。虛擬碼如下:

Undo 階段對待回滾事務的處理和 Normal Processing 的回滾操作一樣。如果當前 UNDO 的原紀錄檔為非 CLR 紀錄檔,則下一個待 UNDO 的紀錄檔為當前原紀錄檔的 PrevLSN。如果當前紀錄檔為可 Undo 紀錄檔,則為其執行 Undo 操作,並記錄該操作的 CLR 紀錄檔。 如果當前 UNDO 的原紀錄檔為 CLR 紀錄檔,則下一個待 UNDO 的紀錄檔為當前紀錄檔的 UndoNxtLSN(這將跳過已經被 UNDO 的紀錄檔)。
下圖 demo 中,描述了 ARIES 重啟恢復中的單個事務的回滾流程。
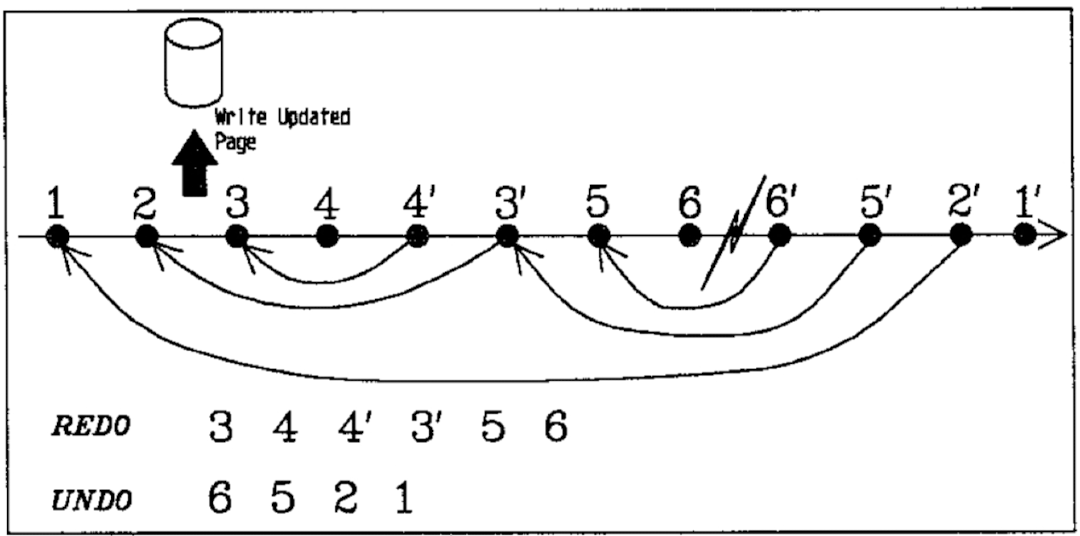
在正常執行狀態下, 事務 partial rollback 對 WAL 紀錄檔 3, 4 執行了 UNDO 操作,產生了 CLR 紀錄檔 4’ 3’。接著繼續推進事務寫入 WAL 紀錄檔 5,6。在 6 寫入持久化儲存之後,系統由於某些原因導致了重啟。此時, 最新記錄的 Checkpoint 的 DPT 中最小 RecLSN 為 2。
ARIES 在 Restart Recovery 時, 會從 3 開始 REDO, 直到紀錄檔的結尾。即,3,4,4’, 3’,5,6。
然後再 Undo 階段, 從 6 開始 undo,產生 CLR 6’。然後是對 5 undo 產生 CLR 5’。 接著在處理 3’ 時,發現它為 CLR 紀錄檔,因此直接跳轉到它的 UndoNxtLSN(2) 繼續處理。依次對 2,1 undo 併產生 CLR 紀錄檔 2’,1’ ,完成 Recovery Restart 流程。
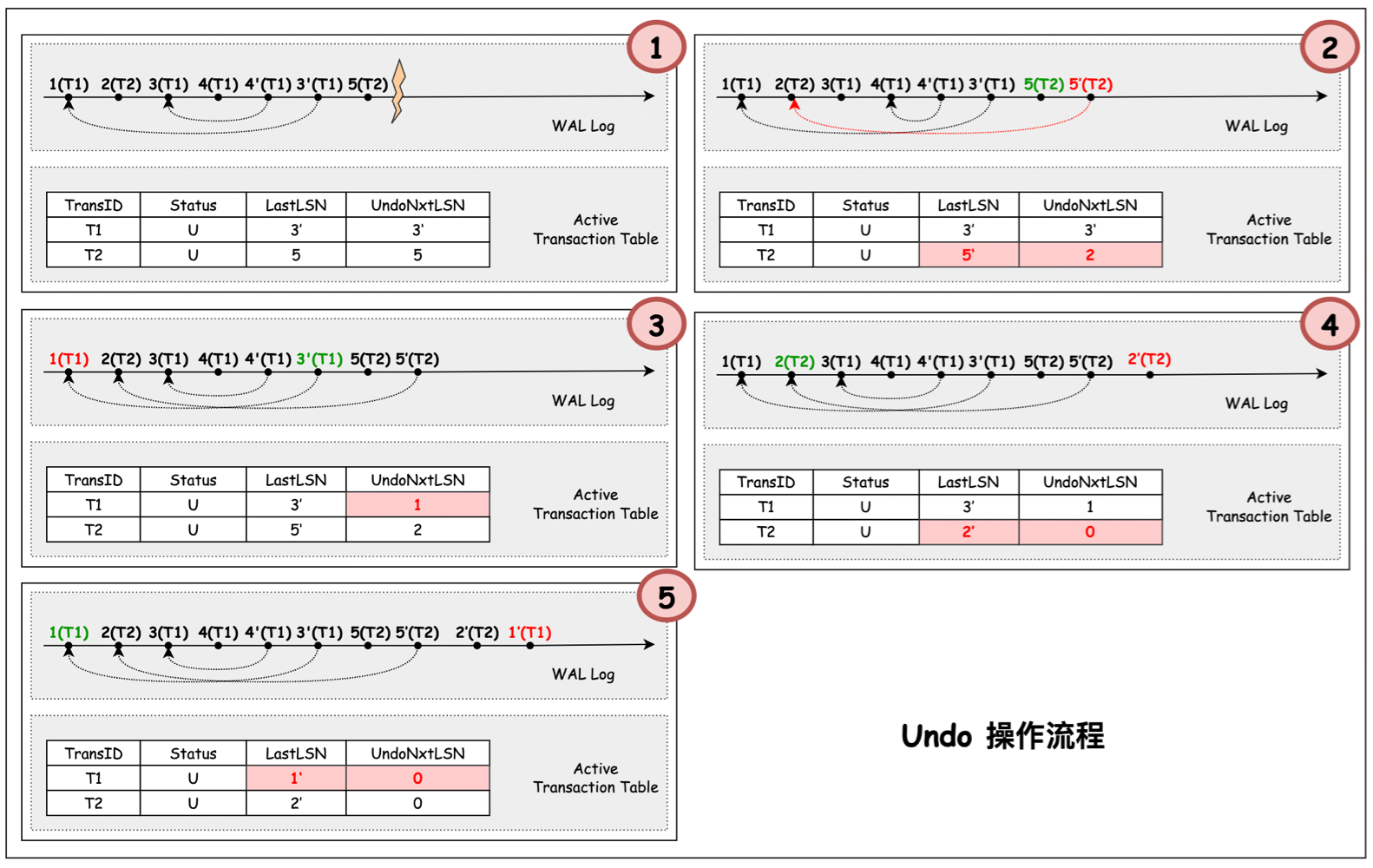
上圖所示,
- 在 restart recovery 的前兩個階段,恢復的 WAL log 和 ATT 的內容如圖所示。
- 讀取到當前 ATT 表中處於 ‘U’狀態事務的 UndoNxtLSN 最大值為 5(T2)。該紀錄檔為非 CLR 紀錄檔,因此可以在 Undo 該紀錄檔之後,為該紀錄檔寫入 CLR 紀錄檔 5’,該 CLR 紀錄檔的 UndoNxtLSN 指向事務 T2 下一個待 Undo 的紀錄檔 2。同時更新 ATT 表中 T2 的 LastLSN 為 5’, UndoNxtLSN 為 2。
- 讀取到當前 ATT 表中處於 ‘U’狀態事務的 UndoNxtLSN 最大值為 3’(T1)。該紀錄檔為 CLR 紀錄檔,因此不需要對該紀錄檔做 Undo 操作。直接將 ATT 表中 T1 的 UndoNxtLSN 設為 3’ 的 UndoNxtLSN(1)。
- 讀取到當前 ATT 表中處於 ‘U’狀態事務的 UndoNxtLSN 最大值為 2(T2)。該紀錄檔為非 CLR 紀錄檔,因此可以在 Undo 該紀錄檔之後,為該紀錄檔寫入 CLR 紀錄檔 2’。由於原紀錄檔 2 沒有當前事務的前序紀錄檔。因此將該 CLR 紀錄檔的 UndoNxtLSN 設為 0(表示事務 T2 回滾完成)。同時更新 ATT 表中 T2 的 LastLSN 為 2’, UndoNxtLSN 為 0。(ATT 表中的這一項可以被移除)
- 讀取到當前 ATT 表中處於 ‘U’狀態事務的 UndoNxtLSN 最大值為 1(T1)。該紀錄檔為非 CLR 紀錄檔,因此可以在 Undo 該紀錄檔之後,為該紀錄檔寫入 CLR 紀錄檔 1’。由於原紀錄檔 1 沒有當前事務的前序紀錄檔。因此將該 CLR 紀錄檔的 UndoNxtLSN 設為 0(表示事務 T2 回滾完成)。同時更新 ATT 表中 T2 的 LastLSN 為 1’, UndoNxtLSN 為 0(ATT 表中的這一項可以被移除)。至此,recovery restart 的 Undo 流程執行完成。
參考文獻
- Principles of Transaction-Oriented Database Recovery
- Compensation Log Records (CLR) in UNDO-Phase of Database Recovery
- ARIES: A Transaction Recovery Method Supporting Fine-Granularity Locking and Partial Rollbacks Using Write-Ahead Logging