從零開始初識機器學習
本篇文章中我們將對機器學習做全面的瞭解與介紹,其中第一章 初識機器學習分為上下兩個小章節,對機器學習是什麼、機器學習由來以及機器學習的理論等展開說明。目的是能讓即便完全沒接觸過機器學習的人也能在短時間對機器學習有一個全面瞭解。後續將推出機器學習的進階內容,包括經典基礎篇(線性模型、決策樹、整合學習、聚類等),實戰進階篇(特徵工程、模型訓練與驗證、融合與部署等)。本篇為第一章 初識機器學習(上),我們從這裡開始,開啟一個全新的學習旅程。
1 機器學習描述
1.1 機器學習是什麼?
機器學習(Machine Learning,ML)是使用統計(或數學)技術從觀察到的資料中構建模型(或系統)的一個電腦科學領域。機器學習用計算機程式模擬人的學習能力,從樣本資料中學習得到知識和規律,然後用於實際的推斷和決策。
從廣義上來說,機器學習能夠賦予「機器」學習的能力,使其實現直接程式設計無法完成的工作。但從實踐意義上來說,機器學習是利用資料訓練出模型,並使用模型進行預測的一種方法。「訓練」與「預測」是機器學習的兩個過程,「模型」則是過程中間的輸出結果,「訓練」產生「模型」,「模型」指導 「預測」。接下來我們把機器學習的過程與人類對歷史經驗歸納演繹的過程做個比對。

機器學習中的「訓練」與「預測」過程可以對應到人類的「歸納」和「演繹」過程。通過這樣的對應,我們可以發現,機器學習的思想並不複雜,僅僅是對人類在生活中學習成長的一個模擬。由於機器學習不是基於程式設計形成的結果,因此它的處理過程不是因果的邏輯,而是通過歸納思想得出的相關性結論。
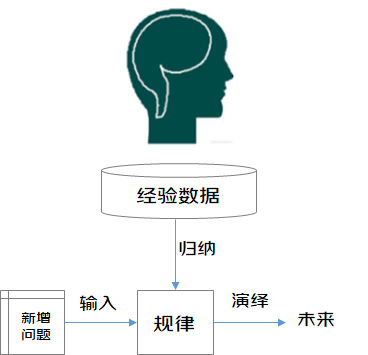
人類對歷史經驗歸納過程
人類在成長、生活過程中積累了很多的歷史與經驗。人類定期地對這些經驗進行「歸納」,獲得了生活的「規律」。當人類遇到未知的問題或者需要對未來進行「推測」的時候,人類將使用這些「規律」,對未知問題與未來進行「演繹」,從而指導自己的生活和工作。
1.2 機器學習的應用範圍
機器學習應用廣泛,在各方面都有其施展的空間,包括:資料分析與挖掘、圖形識別、虛擬助手和交通預測等。從行業來看,在金融領域(檢測信用卡欺詐、證券市場分析等)、網際網路領域(自然語言處理、語音識別、搜尋引擎等)、醫學領域、自動化及機器人領域(無人駕駛、訊號處理等)、遊戲領域、刑偵領域等也都有所涉及。
1.2.1 資料分析與挖掘
「資料探勘」和」資料分析」通常被相提並論,但無論是資料分析還是資料探勘,都是在幫助人們收集與分析資料,使之成為資訊並做出推測與判斷。因此可以將這兩項合稱為資料分析與挖掘。資料分析與挖掘是機器學習技術和巨量資料儲存技術結合的產物,利用機器學習手段分析海量資料,同時利用資料儲存機制實現資料的高效讀寫。機器學習在資料分析與挖掘領域中擁有無可取代的地位,2012年Hadoop進軍機器學習領域就是一個很好的例子。
1.2.2 圖形識別
圖形識別的應用領域廣泛,包括計算機視覺、醫學影象分析、光學文字識別、自然語言處理、語音識別、手寫識別、生物特徵識別、檔案分類、搜尋引擎等,而這些領域也正是機器學習大展身手的舞臺,因此圖形識別與機器學習的關係越來越密切。



1.2.3 虛擬助手
Siri,Alexa,Google Now都是虛擬助手。在互動過程中,虛擬助手會協助查詢資訊,搜尋相關歷史行為,或向其他資源(如電話應用程式)傳送命令收集更多資訊,以滿足人們提出的需求。
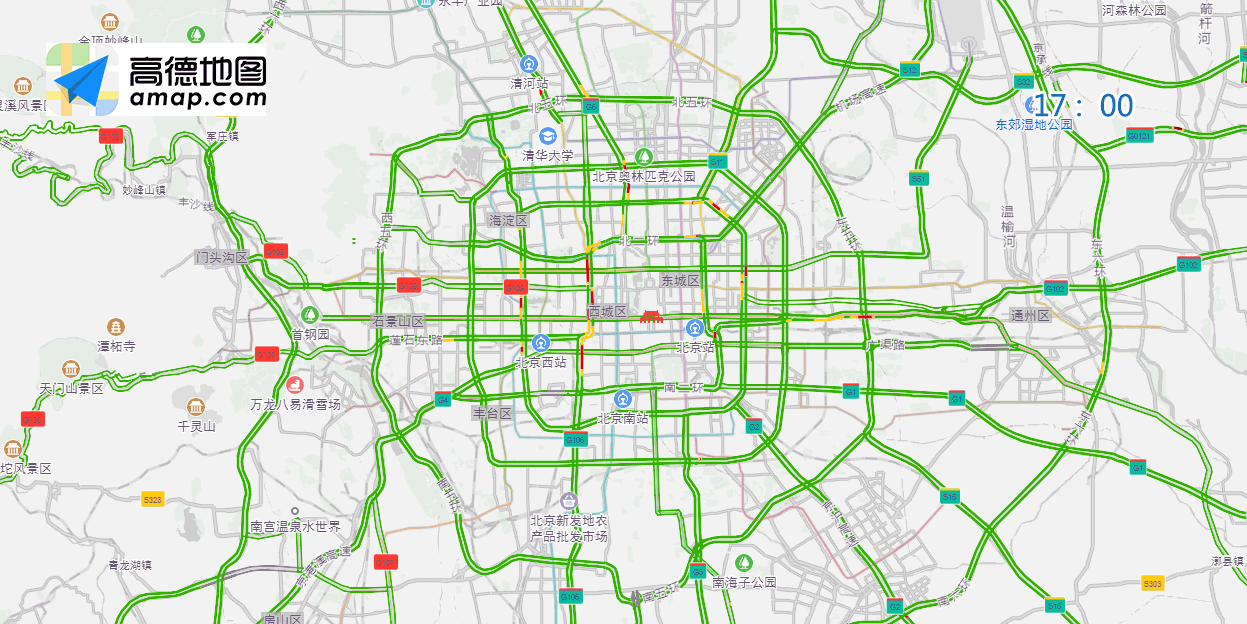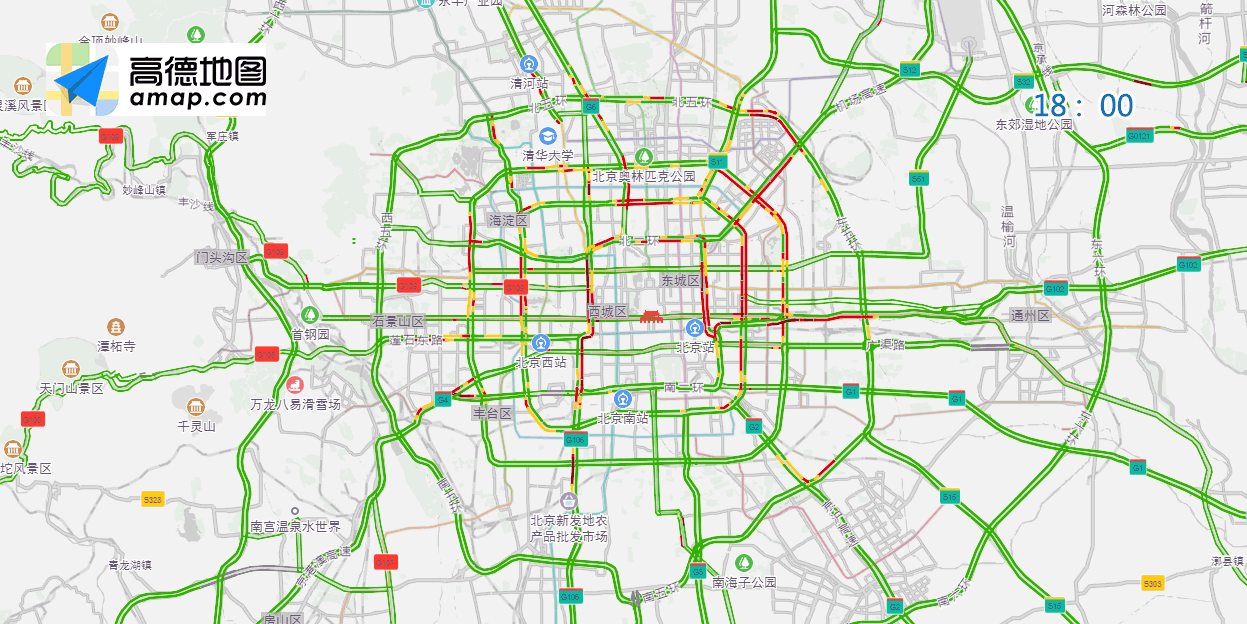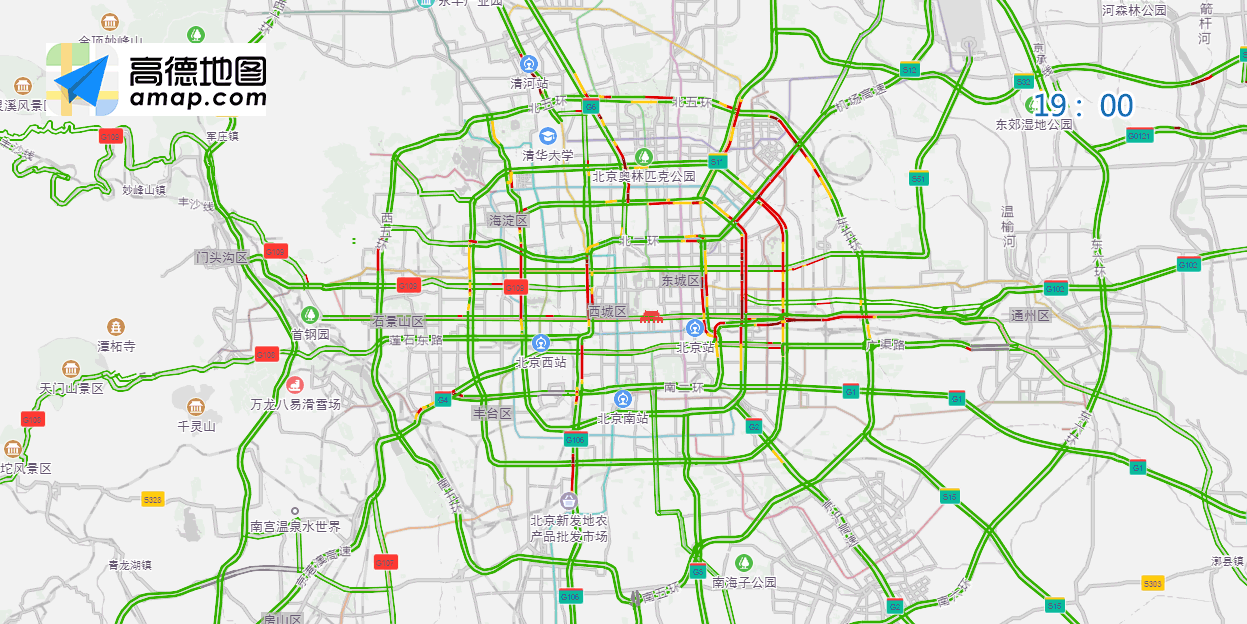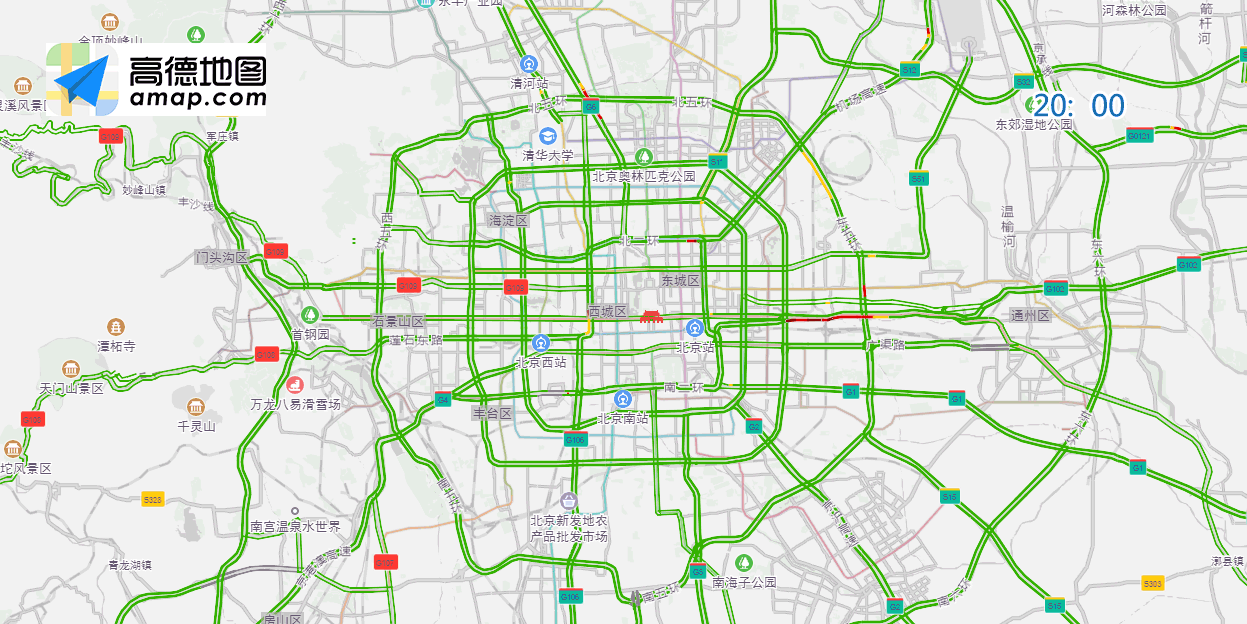
1.2.4 交通預測
生活中我們經常使用GPS導航服務,機器學習能夠幫助我們預測交通堵塞。當前高德地圖,騰訊地圖等都應用了機器學習技術,識別擁擠路段,規劃最優路線。
2 機器學習發展史
2.1 淺層學習階段
- 1957年,Rosenblatt發明了感知機(Perceptron),是神經網路的雛形,同時也是支援向量機的基礎,在當時引起了不小的轟動。
- 1959年,IBM的寫出了可以學習的西洋棋程式,並在 IBM Journal of Research and Development期刊上發表了一篇名為《Some Studies in Machine Learning Using the Game of Checkers》的論文中,定義並解釋了一個新詞——機器學習(Machine Learning,ML)。將機器學習非正式定義為「在不直接針對問題進行程式設計的情況下,賦予計算機學習能力的一個研究領域」。
- 1960年,Widrow發明了Delta學習規則,即如今的最小二乘問題,立刻被應用到感知機中,並且得到了一個極好的線性分類器。
- 1970年,Seppo Linnainmaa首次完整地敘述了自動鏈式求導方法(Automatic Differentiation,AD),是著名的反向傳播演演算法(Back Propagation,BP)的雛形,但在當時並沒有引起重視。
- 1974年,Werbos首次提出把BP演演算法的思想應用到神經網路,也就是多層感知機(Multilayer Perception,MLP),並在1982年實現,就是現在通用的BP演演算法,促成了第二次神經網路大發展。
- 1985-1986年,Rumelhart,Hinton等許多神經網路學者成功實現了實用的BP演演算法來訓練神經網路,並在很長一段時間內BP都作為神經網路訓練的專用演演算法。
- 1986年,J.R.Quinlan提出了另一個同樣著名的ML演演算法—決策樹演演算法(Iterative Dichotomiser 3,ID3),決策樹作為一個預測模型,代表的是物件屬性與物件值之間的一種對映關係,而且緊隨其後湧現出了很多類似或者改進演演算法,如ID4,迴歸樹,CART等。
- 1995年,Yan LeCun提出了折積神經網路(Convolution Neural Network,CNN),受生物視覺模型的啟發,通常有至少兩個非線性可訓練的折積層,兩個非線性的固定折積層,模擬視覺皮層中的V1,V2,Simple cell和Complex cell,在手寫字識別等小規模問題上,取得了當時世界最好結果,但是在大規模問題上表現不佳。
- 1995年,Vapnik和Cortes提出了強大的支援向量機(Support Vector Machine,SVM),主要思想是用一個分類超平面將樣本分開從而達到分類效果,具有很強的理論論證和實驗結果。至此,ML分為NN和SVM兩派。
- 1997年,Freund和Schapire提出了另一個堅實的ML模型AdaBoost,該演演算法最大的特點在於組合弱分類器形成強分類器,可以形象地表述為:「三個臭皮匠賽過諸葛亮」,分類效果比其它強分類器更好。
- 2001年,隨著核方法的提出,SVM大佔上風,它的主要思想就是通過將低維資料對映到高維,從而實現線性可分。至此,SVM在很多領域超過了NN模型。除此之外,SVM還發展了一系列針對NN模型的基礎理論,包括凸優化、範化間隔理論和核方法。
- 2001年,Breiman提出了一個可以將多個決策樹組合起來的模型隨機森林(Random Forest,RF),它可以處理大量的輸入變數,有很高的準確度,學習過程很快,不會產生過擬合問題,具有很好的魯棒性。
- 2001年,Hochreiter發現使用BP演演算法時,在NN單元飽和之後會發生梯度損失(梯度擴散)。簡單來說就是訓練NN模型時,超過一定的迭代次數後,容易過擬合。NN的發展一度陷入停滯狀態。
2.2 深度學習階段
二十一世紀初,學界掀起了以「深度學習」為名的熱潮。所謂深度學習?狹義地說就是「很多層」的神經網路。在若干測試和競賽上,尤其是涉及語音、影象等複雜物件的應用中,深度學習技術取得了優越效能。以往機器學習技術在應用中要取得好效能,對使用者的要求較高;而深度學習技術涉及的模型複雜度非常高,以至於只要下工夫「調參」,只要把引數調節好,效能往往就好。因此,深度學習雖缺乏嚴格的理論基礎,但它顯著降低了機器學習應用者的門檻,為機器學習技術走向工程實踐帶來了便利。那麼它為什麼此時才熱起來呢?有兩個原因,一是資料量增大了,二是計算能力強了。深度學習模型擁有大量引數,若資料樣本少,則很容易「過擬合」。如此複雜的模型、如此大的資料樣本,若缺乏強力計算裝置,根本無法求解。恰恰人類進入了巨量資料時代,資料儲量與計算裝置都有了大發展,才使得深度學習技術又煥發一春。
- 2006年,Hinton和他的學生在《Nature》上發表了一篇深度置信網路(Deep Belief Network,DBN)的文章,從此開啟了深度學習(Deep Learning,DL)階段,掀起了深度神經網路即深度學習的浪潮。
- 2009年,微軟研究院和Hinton合作研究基於深度神經網路的語音識別,歷時兩年取得成果,徹底改變了傳統的語音識別技術框架,使得相對誤識別率降低25%。
- 2012年,Hinton又帶領學生在目前最大的影象資料庫ImageNet上,基於深度神經網路對圖分類問題取得了驚人的結果,將Top5錯誤率由26%大幅降低至15%。(ImageNet 是一個計算機視覺系統識別專案,是目前世界上影象識別最大的資料庫。是美國斯坦福的電腦科學家,模擬人類的識別系統建立的。能夠從圖片識別物體。)
- 2012年,由人工智慧和機器學習頂級學者Andrew Ng和分散式系統頂級專家Jeff Dean領銜的夢幻陣容,開始打造Google Brain專案,用包含16000個CPU核的平行計算平臺訓練超過10億個神經元的深度神經網路,在語音識別和影象識別等領域取得了突破性的進展。該系統通過分析YouTube上選取的視訊,採用無監督的方式訓練深度神經網路,可將影象自動聚類。在系統中輸入「cat」後,結果在沒有外界干涉的條件下,識別出了貓臉。
- 2012年,微軟首席研究官Rick Rashid在21世紀的計算大會上演示了一套自動同聲傳譯系統,將他的英文演講實時轉換成與他音色相近、字正腔圓的中文演講。同聲傳譯需要經歷語音識別、機器翻譯、語音合成三個步驟。該系統一氣呵成,流暢的效果贏得了一致認可,深度學習則是這一系統中的關鍵技術。
- 2013年,Google收購了一家叫DNN Research的神經網路初創公司,這家公司只有三個人,Geoffrey Hinton和他的兩個學生。這次收購併不涉及任何產品和服務,只是希望Hinton可以將深度學習打造為支援Google未來的核心技術。同年,紐約大學教授,深度學習專家Yann LeCun加盟Facebook,出任人工智慧實驗室主任,負責深度學習的研發工作,利用深度學習探尋使用者圖片等資訊中蘊含的海量資訊,希望在未來能給使用者提供更智慧化的產品使用體驗。
- 2013年,百度成立了百度研究院及下屬的深度學習研究所(Institute of Deep Learning,IDL),將深度學習應用於語音識別和影象識別、檢索,以及廣告CTR預估(Click-Through-Rate Prediction,CTR),其中圖片檢索達到了國際領先水平。
- 2014年,谷歌宣佈其首款成型的無人駕駛原型車製造完畢,將會在2015年正式進行路測。
- 2016年,谷歌旗下DeepMind公司開發的人工智慧程式AlphaGo擊敗圍棋職業九段選手李世石。
- 2017年,DeepMind團隊公佈了最強版AlphaGo,代號AlphaGo Zero,它能在無任何人類輸入的條件下,從空白狀態學起,自我訓練的時間僅為3天,自我對弈的棋局數量為490萬盤,能以100:0的戰績擊敗前輩。
3 易混淆領域梳理
3.1 機器學習與人工智慧
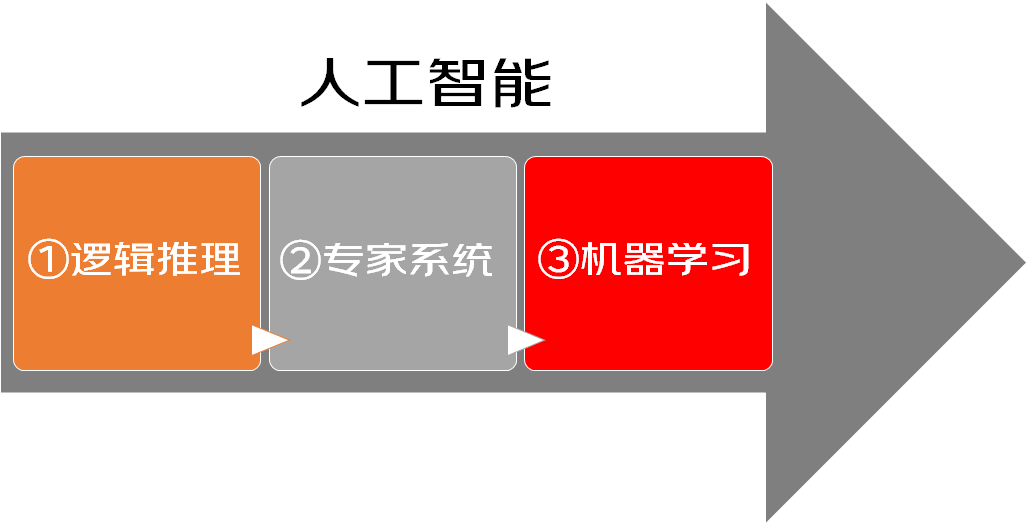
人工智慧(Artificial Intelligence,AI)是電腦科學的一個分支,它企圖瞭解智慧的本質,生產出一種能比肩人類,並做出智慧反應的機器。我們都知道機器學習是人工智慧最重要的一種實現方法,但機器學習並不是人工智慧一開始就採用的方法。人工智慧的發展主要經歷了邏輯推理,專家系統,機器學習三個階段。
- 第一階段的重點是邏輯推理,例如數學定理的證明,這類方法採用符號邏輯來模擬人類智慧。
- 第二階段的重點是專家系統,這類方法為各個領域的問題建立專家知識庫,利用這些知識來完成推理和決策。比如將醫生的診斷經驗轉化成一個知識庫,然後用這些知識對病人進行診斷。
- 第三階段的重點即為機器學習,如今的人工智慧主要依賴的不再是邏輯推理和專家系統,而是建立在機器學習的基礎上解決複雜問題。無論是基於數學的機器學習模型,還是基於神經網路的深度學習模型,都活躍在如今大多數人工智慧應用程式之中。
3.2 機器學習與深度學習
深度學習(Deep Learning,DL)是機器學習的一個重要分支,深度學習和機器學習的關係屬於繼承和發展的關係。在很多人工智慧問題上,深度學習的方法加上巨量資料的出現以及計算機執行速度的提高,更突出了人工智慧的前景。比如,自動駕駛汽車,足以徹底改變我們的出行方式,它的實現就需要深度學習的影象識別技術,需要用到折積神經網路(Convolutional Neural Networks, CNN)來識別馬路上的行人、紅綠燈等。
為了更清晰的認識深度學習,我們首先介紹神經網路(Neural Networks, NN),顧名思義,它是一種模仿動物神經網路行為特徵,進行分散式並行資訊處理的演演算法數學模型。神經網路有輸入層、隱藏層(中間層)以及輸出層,其中輸入層負責神經網路的輸入,輸出層負責產生輸入的對映。機器學習中的邏輯迴歸,可以看作是一層的神經網路,即除了輸入層、輸出層之外只有一個隱藏層。
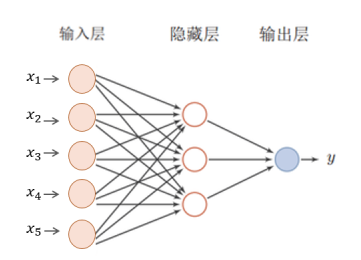
而深度學習,就是指神經網路使用了很多隱藏層。
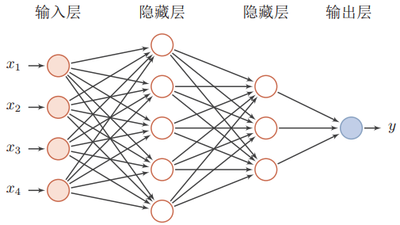
那麼深度學習的每一層都在學什麼??
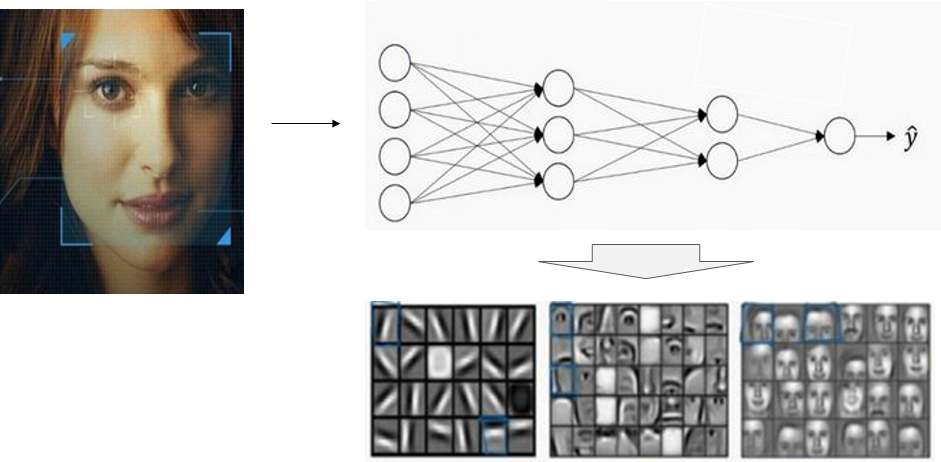
當你輸入一張臉部的照片時,神經網路的第一中間層,可以看成是一個特徵探測器或者邊緣探測器,它會去找這張照片的各個邊緣(第一張圖片);第二中間層又把照片裡組成邊緣的畫素們放在一起看,然後它可以把被探測到的邊緣組合成面部的不同部分(第二張圖片),有眼睛、鼻子等;最後再把這些部分放在一起,比如鼻子眼睛嘴巴,就可以識別或者探測不同的人臉(第三張圖片)。
3.3 機器學習與資料探勘
資料探勘(Data Mining,DM)是指從大量的資料中搜尋隱藏於其中資訊的過程。機器學習是資料探勘的重要工具之一,但資料探勘不僅僅要研究、拓展、應用一些機器學習方法,還要通過許多非機器學習技術解決大規模資料與資料噪音等實際問題。大體上看,資料探勘可以視為機器學習和巨量資料的交叉,它主要利用機器學習提供的技術來分析海量資料,利用巨量資料技術來管理海量資料。

3.4 機器學習與統計學
1.統計學簡述
統計學(Statistics)是基於資料構建概率統計模型並運用模型對資料進行分析與預測的一門學科。統計學依託背後的數學理論,在遠早於機器學習大爆發的幾十年,率先從解釋因果的角度,努力尋找最優函數(或模型)。統計學裡最重要的兩個部分是迴歸分析和假設檢驗。其他的方法或者技術在統計學這個大框架下,最終也是為了這兩者服務的。迴歸分析提供瞭解釋因果的武器,假設檢驗則給這項武器裝上了彈藥。單純的線性迴歸用最小二乘法求解逼近事實的真相,再使用顯著性檢驗,檢測變數的顯著性、模型的顯著性、模型的擬合精度。當然是否屬於線性,也可以使用假設檢驗的方法檢測。非線性迴歸的問題,使用極大似然估計或者偏最小二乘迴歸求解模型,後續的顯著性檢驗仍然是一樣的思路。
2.機器學習與統計學對比
統計學是個與機器學習高度重疊的學科,統計學近似等於機器學習。但是在某種程度上兩者是有分別的,這個分別在於:統計學是理論驅動,對資料分佈進行假設,以強大的數學理論解釋因果,注重引數推斷,側重統計模型的發展與優化;機器學習是資料驅動,依賴於巨量資料規模預測未來,弱化了收斂性問題,注重模型預測,側重解決問題。
3.5 機器學習演演算法與「普通」演演算法的異同
這裡我們以《演演算法導論》中所詮釋的演演算法作為機器學習演演算法的比較物件。其相同點,兩者的目的都是通過制定目標,增加約束,求得最優的模型。不同點是《演演算法導論》裡的「演演算法」,本質上是如何更有效率地求解具有精確解的問題。效率,可以是計算時間更短,也可以是計算過程所需要的空間更少。而機器學習演演算法要解決的問題一般沒有精確解,也不能用窮舉或遍歷這種步驟明確的方法求解。這裡需要強調的是「學習」這個屬性,即希望演演算法本身能夠根據給定的資料或變化的計算環境而動態地發現新的規律,甚至改變機器學習演演算法的邏輯和行為。
作者:京東物流 星火團隊
來源:京東雲開發者社群