基於GPT搭建私有知識庫聊天機器人(一)實現原理
1、成品演示
- 支援微信聊天
- 支援網頁聊天
- 支援微信語音對話
- 支援私有知識檔案訓練,並針對檔案提問
步驟1:準備本地檔案a.txt,支援pdf、txt、markdown、ppt等
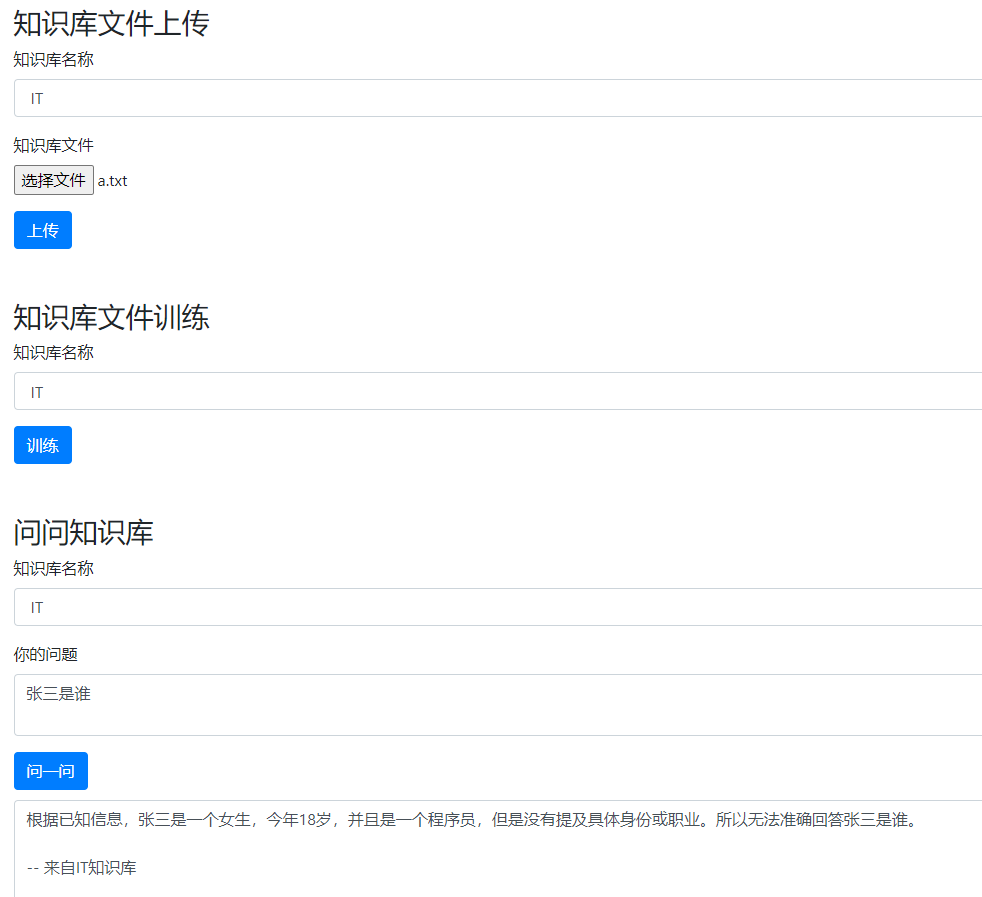
步驟2:上傳a.txt,並選擇要儲存的在哪個知識庫
步驟3:對上傳的a.txt檔案進行訓練
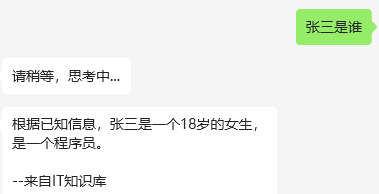
步驟4:進行提問(網頁和微信)

2、實現原理
目前很多企業希望將ChatGPT的能力應用到企業內部當中,但ChatGPT是個預訓練模型,其所能回答的知識主要來源於網際網路上公開的通用知識庫,對於部分垂直領域和企業內部的私有知識庫的問答無法起到很好的效果,因此,針對這類場景,企業可以基於OpenAI提供的模型服務以及相關生態工具(比如langchain、huggingFace等),構建企業自己特有的知識庫問答系統,並在內部知識庫問答系統之上,再搭建客服問答系統以及其他的企業助手工具。
總體流程如下:
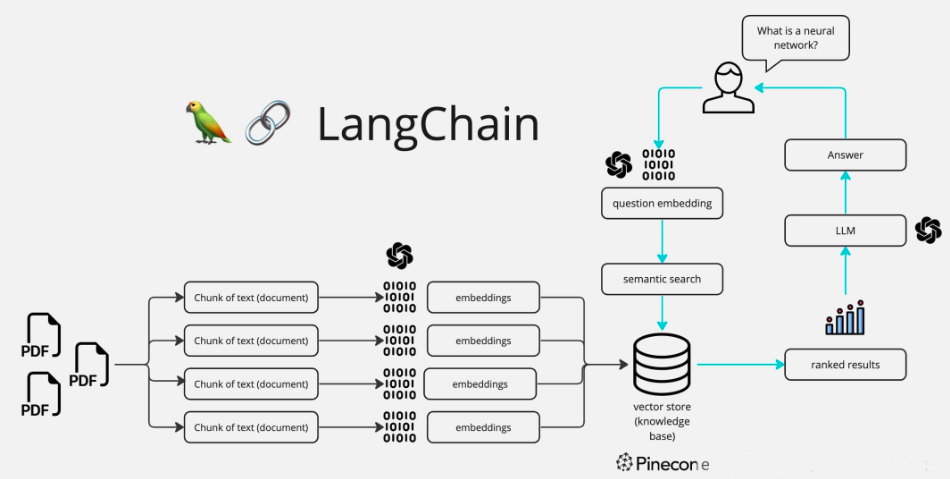
1、將垂直行業領域的知識庫檔案進行Embedding向量化處理,並將處理後的語意向量Vectors存入向量資料庫Vector Database中(這個步驟中還包括對非結構化資料先轉化成文字資料,並對長文字進行Splitter分割處理)
2、將使用者的問題進行向量化Embedding處理,轉化為Vector search
3、將使用者問題Vector search 和向量資料庫進行查詢匹配,返回相似度最高的TopN條知識文字
4、將匹配出的文字和使用者的問題上下文一起提交給 LLM,根據Prompt生成最終的回答
3、Embedding(嵌入)
嵌入(Embedding)是一種將文字或物件轉換為向量表示的技術,將詞語、句子或其他文字形式轉換為固定長度的向量表示。嵌入向量是由一系列浮點數構成的向量。通過計算兩個嵌入向量之間的距離,可以衡量它們之間的相關性。距離較小的嵌入向量表示文字之間具有較高的相關性,而距離較大的嵌入向量表示文字之間相關性較低。
Embedding模型在許多應用場景中都有廣泛的應用。在OpenAI中,文字嵌入技術主要用於衡量文字字串之間的相關性。
以下是一些常見的應用場景:
- 搜尋(Search):根據與查詢字串的相關性對搜尋結果進行排序。
- 聚類(Clustering):將文字字串按照相似性進行分組。
- 推薦(Recommendations):推薦與給定文字字串相關的專案。
- 異常檢測(Anomaly Detection):識別與其他文字字串相關性較低的異常值。
- 多樣性測量(Diversity Measurement):分析文字字串之間相似性的分佈。
- 分類(Classification):根據文字字串與各標籤的相似性進行分類。
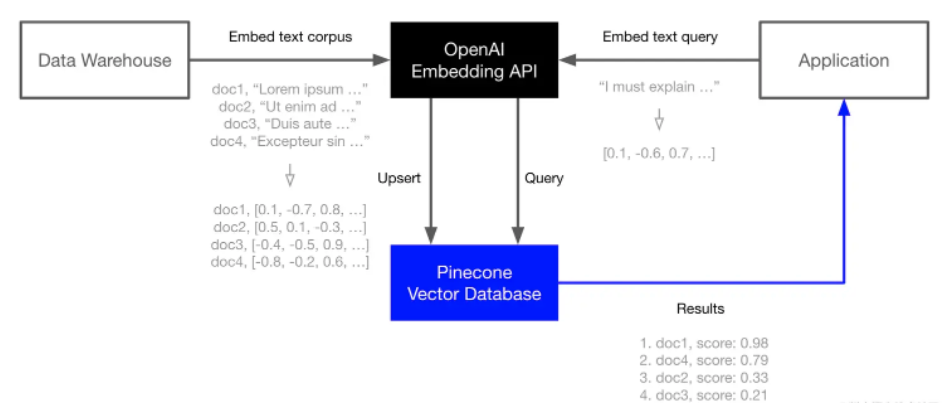
下面是本次的應用場景,將知識資料通過嵌入模型查詢出向量,並對映儲存,然後在應用時將問題也轉換成嵌入式,通過相似度演演算法(比如餘弦相似度)對比前期儲存的向量,找出TopN的資料,即得到與問題最關聯的內容。
4、Embedding Models(嵌入模型)
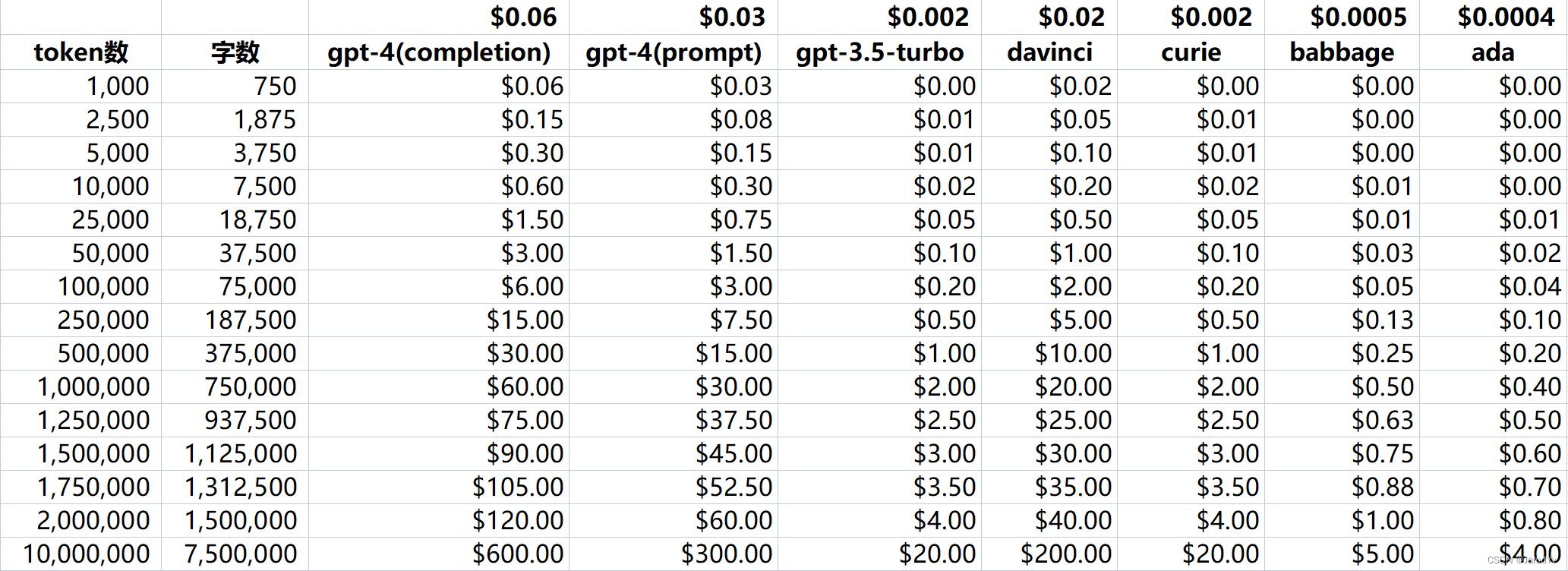
OpenAI提供一個第二代嵌入(Embeddings)模型(模型ID中用-002表示),以及16個第一代模型(模型ID中用-001表示)。
建議在幾乎所有情況下使用text-embedding-ada-002。它更好、更便宜、更簡單易用。
使用價格按輸入令牌計價,每1000個token價格為$0.0004,或約為每美元約3,000頁(假設每頁約有800個token):
| 模型(Model) | 一美元頁數(Rough pages per dollar) | BEIR評分 |
|---|---|---|
| text-embedding-ada-002 | 3000 | 53.9 |
| -davinci--001 | 6 | 52.8 |
| -curie--001 | 60 | 50.9 |
| -babbage--001 | 240 | 50.4 |
| -ada--001 | 300 | 49.0 |
5、Completion(補全)
Completions是我們API的核心,提供了一個非常靈活和強大的簡單介面。您將一些文字作為提示(Prompt)輸入,API將返回一個文字補全(Completion),試圖匹配您給它的任何指令或上下文。
Prompt
為一個冰淇淋店寫一個標語。
Completion
我們每勺都掌握微笑!
您可以把它想象成一種非常先進的自動完成——模型處理您的文字提示並嘗試預測最有可能出現的內容。
6、Temperature(溫度)
溫度(temperature)是一個介於0和1之間的值,它本質上能讓你控制模型在做出這些預測時的信心程度。降低溫度(temperature)意味著它將採取更少的風險,補全將更準確和確定性。增加溫度(temperature)將產生更多樣化的完成度。
即,可以簡單理解通過此引數可調整回答的隨機性,數值越小隨機性越小,反之亦然。
7、Tokens(令牌)
langchain預設模型使用了text-davinci-003。建議使用gpt-3.5-turbo,因為它們會產生更好的結果。目前最好的模型是gpt-4,但需要申請許可權。
對於英文文字,1個token約=0.75個單詞(token可以短至一個字元或長至一個單詞,比如:字串"ChatGPT is great!"被編碼為六個標記:["Chat", "G", "PT", " is", " great", "!"])。
在使用 API 時,您將被計費的 token 數是包括了請求和響應中的所有 token 數量。
8、向量資料庫
8.1 向量資料的結構
向量資料的典型結構是一個一維陣列,其中的元素是數值(通常是浮點數)。這些數值表示物件或資料點在多維空間中的位置、特徵或屬性。向量資料的長度取決於所表示的特徵維度。下面是一個簡單的例子:
假設我們有三個水果:蘋果、香蕉和葡萄。我們想用向量資料表示它們的顏色和大小特徵。我們可以將顏色分為紅、綠、藍三個通道,將大小分為小、中、大三個類別。因此,我們可以用一個包含 6 個數值的向量表示每個水果的特徵。
蘋果(紅色,中等大小):[1, 0, 0, 0, 1, 0]
香蕉(黃色,大):[0, 1, 0, 0, 0, 1]
葡萄(紫色,小):[0.5, 0, 0.5, 1, 0, 0]
在這個例子中,每個水果都被表示為一個 6 維向量。前三個數值表示顏色資訊(紅、綠、藍通道),後三個數值表示大小資訊(小、中、大)。
細心的你可能會發現,紫色的向量表示是 [0.5, 0, 0.5],沒錯,這代表紫色是由紅色和藍色組成。
這種陣列結構是典型的向量資料表示。
在推薦系統中,使用者和物品可以用向量表示,以捕捉其特徵和屬性。例如,使用者可能對電影型別、導演、演員等方面有偏好,這些偏好可以用一個數值向量表示。通過計算使用者向量與物品向量之間的相似度,可以實現個性化的推薦。
在自然語言處理中,詞嵌入是一種將文字資料轉換為向量資料的方法。例如,使用 Word2Vec 或 GloVe 演演算法,可以將單詞表示為一個包含多個數值的向量。這些數值捕捉了單詞的語意特徵,使得相似含義的單詞在向量空間中彼此靠近。
8.2 向量資料的計算
有了向量資料,怎麼用呢?這裡面有沒有一些通用的計算模式?
向量資料的結構非常簡單,但針對不同的場景,衍生出了多種計算方法。
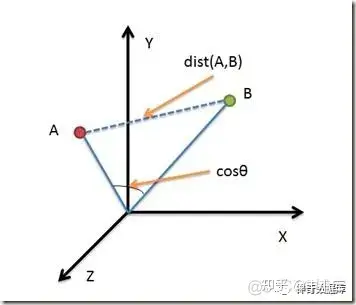
比如最常見的有向量相似度計算:衡量兩個向量之間的相似程度。常用的相似度度量方法包括餘弦相似度(openai推薦)、歐幾里得距離、曼哈頓距離等。
作者:伊力程式設計
掃描左側的二維條碼可以聯絡到我