MySQL 中分割區表
MySQL 中的分割區表
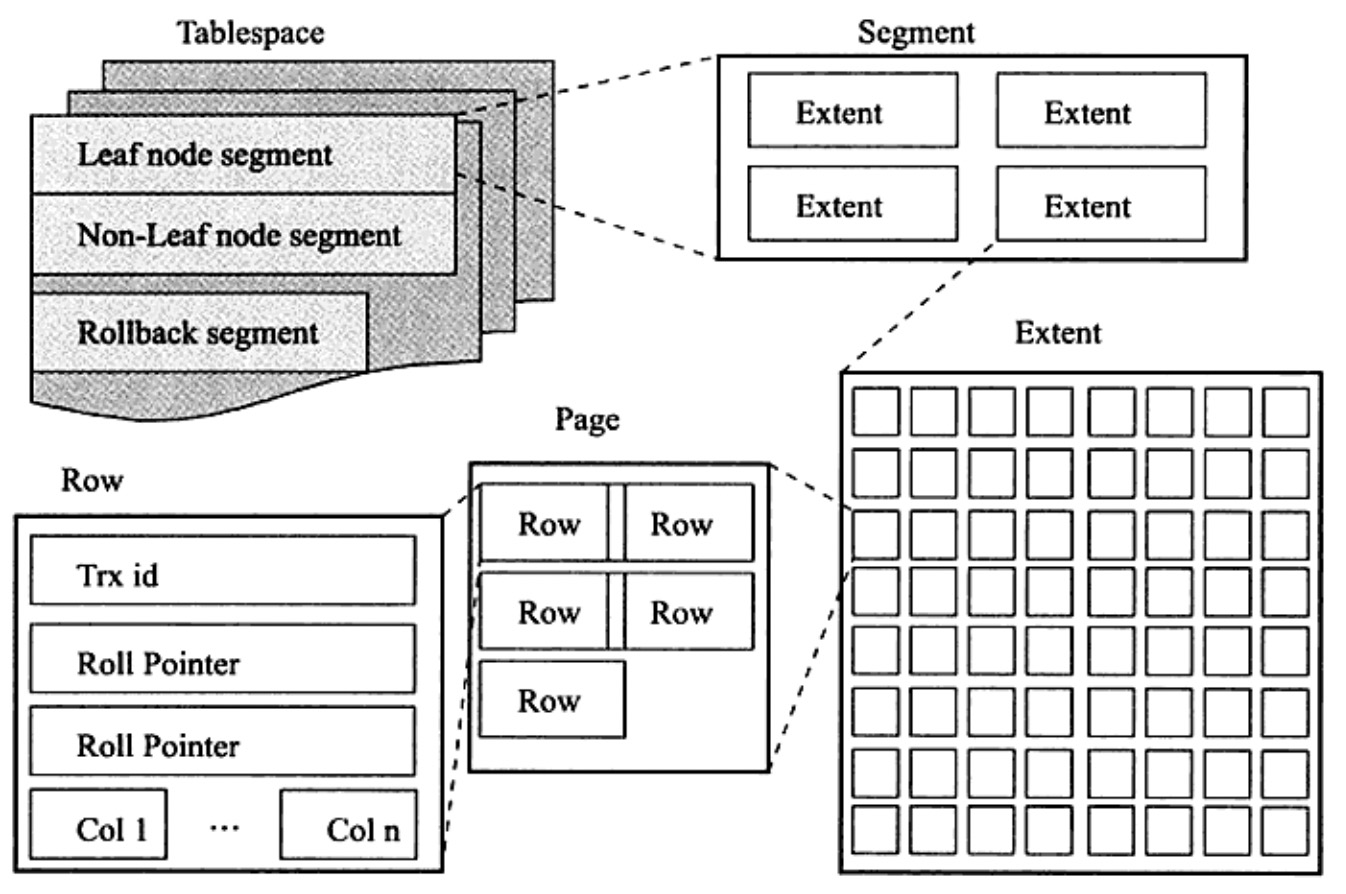
InnoDB 邏輯儲存結構
InnoDB 儲存引擎的儲存邏輯,所有資料都會被邏輯的儲存在一個空間中,這個空間稱為 InnoDB(Tablespace) 表空間,本質上是一個或多個磁碟檔案組成的虛擬檔案系統。InnoDB 表空間不僅僅儲存了表和索引,它還儲存了回滾紀錄檔(redo log)、插入緩衝(insert buffer)、雙寫緩衝(doublewrite buffer)以及其他內部資料結構。
表空間,由段(segment),區(extend),頁(page)組層。頁在一些檔案中也被稱為塊(block)。
表空間 (Tablespace)
表空間可以看做是 InnoDB 儲存引擎邏輯結構的最高層,所有的資料都存放在表空間中。
在預設情況下,InnoDB 儲存引擎有一個共用的表空間 ibdatal 即所有的資料都存放在這個表空間中。如果使用者開啟了 innodb_file_per_table,則每張表內的資料都可以單獨的存放到一個表空間中。
不過即使開啟了 innodb_file_per_table,每張表內的存放的資料只是資料,索引和插入快取 Bitmap 頁,其它類的資料回滾資訊,插入快取頁,系統事務資訊,二次寫緩衝,還是會放在原來的共用表空間中。這也能說明一個問題,及時開始了 innodb_file_per_table,貢獻表空間的資料還是會不斷的增大。
段 (segment)
表空間是由各個段組層的,常見的段由資料段,索引段,回滾段等。
對於 InnoDB 儲存引擎的儲存資料儲存結構 B+ 樹,只有葉子節點儲存資料,其它節點儲存索引資訊。也就是葉子節點儲存的是資料段,非葉子節點儲存的是索引段。
在 InnoDB 儲存引擎中,對段的管理都是由引擎自身所完成的,我們一般不能也沒有必要對其進行操作。
區 (extent)
區是由連續頁組成的空間,在任何情況下每個區的大小都是 1MB,為了保證區中頁的連續性,InnoDB 儲存引擎會一次性的從磁碟申請 4~5 個區。在預設情況下,InnoDB 儲存引擎的大小為 16KB,即一個區中一共有 64 個連續的頁。
InnoDB 1.0.x 版本開始引入了壓縮頁,每個頁的大小可以通過引數 KEY_BLOCK_SIZE 設定為 2K,4K,8K,因此每個區對應的頁的數量就應該為 512,256,128。
InnoDB 1.0.x 版本新增加了引數 innodb_page_size ,通過該引數可以將預設頁的大小設定為 4k,8k,但是頁中的資料庫不會壓縮,這時候區中頁的數量同樣是 256,128。不管頁的大小怎麼變化,區的大小總是1M.
不過需要注意的是,使用者啟動了引數 innodb_file_per_table 設定了單獨的表空間,建立的表預設大小是 96KB。不過一個區中有64個連續的頁,建立的表至少是 1MB 才對?
原因是每個段開始時,會先用32個頁大小的碎片頁來存放資料,在使用完,這些頁之後才是64個連續頁的申請,這樣的目的,對於一些小表,或者 undo 這類的段,可以在開始申請較少的空間,節省磁碟容量的開銷。
頁 (page)
和大多數的資料庫一樣,InnoDB 有頁 (page) 的概念(也稱為塊),頁是 InnoDB 磁碟管理的最小單位。在 InnoDB 儲存引擎中,預設每個頁的大小為 16KB。
從 InnoDB 1.2.x 版本開始,可以通過 innodb_page_size 修改頁的大小,可以設定為 4k,8k,16k。如果修改完成,所有表中頁的大小都是 innodb_page_size,不能對其進行再次修改,除非使用 mysqldump 匯入和匯出操作產生的新的庫。
innoDB儲存引擎中,常見的頁型別有:
1、資料頁(B-tree Node);
2、undo頁(undo Log Page);
3、系統頁 (System Page);
4、事物資料頁 (Transaction System Page);
5、插入緩衝點陣圖頁(Insert Buffer Bitmap);
6、插入緩衝空閒列表頁(Insert Buffer Free List);
7、未壓縮的二進位制大物件頁(Uncompressed BLOB Page);
6、壓縮的二進位制大物件頁 (compressed BLOB Page)。
行 (row)
InnoDB 儲存引擎是按行進行存放的,每個頁存放的資料是有硬性要求的,最多允許存放 16KB/2-200,即7992行記錄。
InnoDB 資料頁結構
頁是 InnoDB 儲存引擎管理資料庫的最小單位,這裡我們再來看下 InnoDB 資料頁的內部結構。
InnoDB 資料頁由下面7部分組層
1、File Header (檔案頭);
2、Page Header (頁頭);
3、Infimum 和 Supremum Records;
4、User Records(使用者記錄,機行記錄);
5、Free Space (空閒空間);
6、Page Directory(頁目錄);
7、File Trailer(檔案結尾資訊)。
其中 File Header,Page Header,File Trailer 用來記錄該頁一些空間,大小是固定的,分別為38,56,8 位元組。
User Records,Free Space,Page Directory 這部分為實際的行記錄儲存空間,大小是動態的。
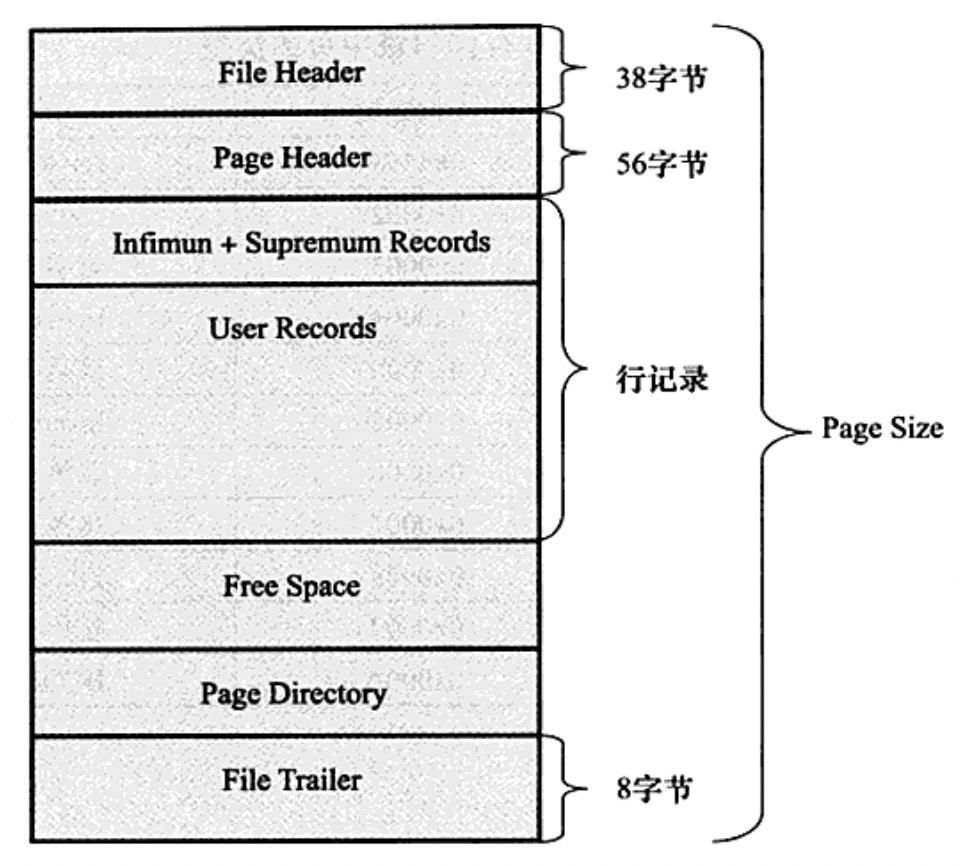
1、File Header:用來記錄頁的一些頭部資訊;
2、Page Header:用來記錄資料頁的狀態資訊;
3、Infimum 和 Supremum Records:在 InnoDB 存引擎中,每個資料頁由連個虛擬的行記錄,用來限定記錄的邊界。Infimum 記錄的是比頁中任何主鍵都要小的值,Supremum 中記錄的是頁中最大值的邊界。這兩個值隨著頁的建立而建立並且永遠都不會被刪除。
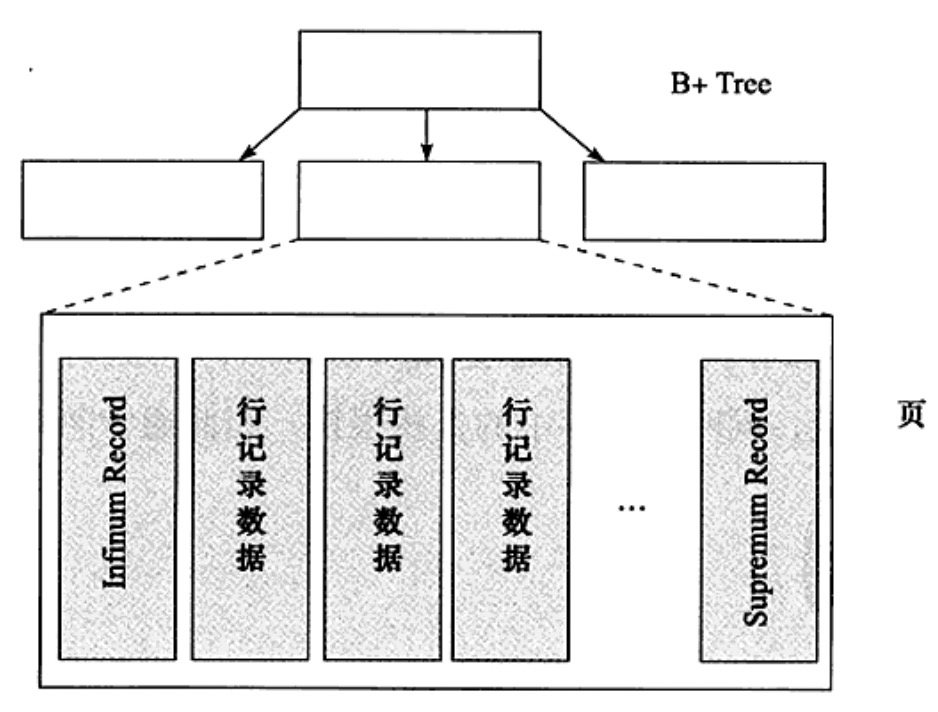
4、User Record 和 Free Space:User Record 儲存的是實際的行記錄,Free Space 指的就是空閒空間,是個連結串列資料結構,在一條資料被刪除後會加入到空閒連結串列中。
5、Page Directory:存放是頁的相對位置,這裡的重點是相對為位置而不是偏移量,有時候也稱為這些記錄指標為 Slots 或者 Directory Slots。
InnoDB 引擎中的槽是一個稀疏目錄,一個槽中可能有多條記錄,當記錄被插入或刪除的時候需要對槽進行分裂或平衡的維護操作。
在 Slots 中記錄按照所索引鍵值順序存放,這樣可以通過二叉查詢迅速找到記錄的指標。所以 B+ 樹索引本省並不能找到具體的一條記錄,能找到的只是該記錄所在的頁。資料把頁載入到記憶體中,然後通過 Page Directory 進行二次查詢,二叉查詢的結果只是一個粗略的結果。只不過二叉查詢的是時間負載度很低,同時在記憶體中查詢很快,因此通常忽略這部分查詢所需要的時間。
6、File Trailer:用於檢測頁是否已經完整當的寫入到磁碟中,在預設設定下 InnoDB 引擎每次從磁碟中讀取一個頁就會檢測頁的完整性,該部分會有一定的開銷,使用者可以通過引數 innodb_checksums 來開啟或者關閉這個頁完整性的檢查。
分割區別表的概念
分割區的過程是將一個表或者索引分為多個更小,更可管理的部分。就存取資料庫的應用來說,從邏輯上講只有一個表或者索引,但是在物理上這個表或者索引可能由數十個物理分割區組成。每個分割區都是獨立的物件,可以獨自處理,也可以作為一個更大物件的一部分進行處理。
資料庫分割區和分表相似,都是按照規則分解表。不同在於分表將大表分解若干個獨立的實體表,而分割區是將資料分段劃分在多個位置存放,分割區後,表還是一張表,但資料雜湊到多個位置了。應用程式讀寫的時候操作還是表名,DB自動去組織分割區的資料。
MySQL 資料庫支援的分割區型別為水平分割區,不支援垂直分割區。MySQL 中資料庫的分割區是區域性分割區索引,一個分割區中即存放了資料又存放了索引。全域性分割區是指,資料存放在各個分割區中,但是所有的資料的索引存放在一個物件中。
MySQL 資料庫支援下面幾種型別的分割區
1、RANGE 分割區:行資料基於一個給定連續區間的列值被放入分割區。MySQL 5.5 開始支援 RANGE COLUMNS 的分割區;
2、LIST 分割區:和 RANGE 分割區類似,只是 LIST 分割區面向的是離散的值。MySQL 5.5 開始支援 LIST COLUMNS 的分割區;
3、HASH 分割區:根據使用者自定義的表達是的返回值來進行分割區,返回值不能為負數;
4、KEY 分割區:根據 MySQL 資料庫提供的雜湊函數來進行分割區。
分割區表的優點
1、可以讓單表儲存更多的資料;
2、分割區表的資料更容易維護,可以通過整個隔斷批次刪除大量資料,也可以增加新的隔斷來支援新插入的資料。此外,還可以優化、檢查、修復一個獨立分割區;
3、有些查詢可以從查詢條件確定只落在少數區域,速度快;
4、分割區表的資料還可以分佈在不同的物理裝置上,從而高效利用多種硬體裝置;
5、可以使用分割區表,避免 InnoDB 單索引的反彈存取、ext3 檔案系統的 inode 鎖定競爭等特殊瓶頸;
6、可備份和恢復單個分割區。
缺點
1、一個表最多隻能有 1024個分割區;
2、如果分割區欄位中有主鍵或者唯一索引的列,那麼所有主鍵列和唯一索引列都必須包含進來;
3、分割區表無法使用外來鍵約束;
4、NULL 值會使分割區過濾無效;
5、所有分割區必須使用相同的儲存引擎。
分割區型別
下面對幾種分割區進行一一實踐下
1、RANGE 分割區
RANGE 是最常用的分割區型別,會根據指定的範圍進行分割區劃分,來個栗子實踐下
CREATE TABLE `t` (
`id` int(11) NOT NULL,
PRIMARY KEY (`id`)
) ENGINE=InnoDB
PARTITION BY RANGE( id ) (
PARTITION p0 VALUES LESS THAN (10),
PARTITION p1 VALUES LESS THAN (20)
);
insert into t values(1),(2),(10),(15);
可以看到,使用 RANGE 分割區型別,通過 id 對資料進行了分割區處理
p0 分割區:id < 10;
p1 分割區:10 <= id < 20;
檢視分割區的資料
$ SELECT * FROM t PARTITION (p0);
+----+
| id |
+----+
| 1 |
| 2 |
$ SELECT * FROM t PARTITION (p1);
+----+
| id |
+----+
| 10 |
| 15 |
+----+
RANGE 分割區是對歷史資料進行分割區的一種方便的方法,RANGE分割區用邊界定義了表或索引中分割區的範圍和分割區間的順序。
RANGE 通常用於日期列的分割區,使用 RANGE 分割區通過時間欄位對資料進行分割區劃分,在查詢特定時間段的資料的時候,假定每個分割區有一個月的資料,這樣查詢某個月的資料的時候,可以通過月份直接定位到該分割區,這樣資料查詢掃描就直接縮小到一個分割區了。
RANGE 也適用於定期載入新資料和清除舊資料的場景。加入資料會保留一個捲動的資料視窗,將過去一年的資料保持線上。使用 RANGE 分割區,只需要在每次新增一個新月份的分割區之後,刪除最後一個月的分割區資料即可。
RANGE 的適用場景:
1、經常在某些列上的按照範圍掃描非常大的表,在這些列上對錶進行分割區可以實現分割區查詢;
2、希望維護資料的捲動視窗;
3、不能在指定的時間內完成大型表的管理操作,例如備份和恢復,但是可以根據分割區範圍列將它們劃分為更小的邏輯塊。
2、LIST 分割區
LIST 和 RANGE 分割區有點類似,只是分割區列是離散的不是連續的,LIST 分割區根據資料的列舉值進行分割區。
來個栗子,必須根據城市對資料進行分割區儲存,不同城市的資料儲存在不同的分割區中。
1、北京;
2、上海;
3、杭州;
4、浙江;
5、洛陽;
6、南寧;
7、鄭州;
8、南京;
9、湖州。
CREATE TABLE `t_city` (
`id` int(11) NOT NULL,
`name` varchar(32) NOT NULL,
`city_code` int(11) NOT NULL
) ENGINE=InnoDB
PARTITION BY LIST (`city_code`)
(PARTITION p1 VALUES IN (1, 2, 3),
PARTITION p2 VALUES IN (4, 5, 6),
PARTITION p3 VALUES IN (7, 8, 9)
);
insert into t_city values(1, "小明", 1),(2, "小白", 3),(10, "小紅", 5),(15, "小李", 7);
檢視分割區資料
$ SELECT * FROM t_city PARTITION (p1);
+----+--------+-----------+
| id | name | city_code |
+----+--------+-----------+
| 1 | 小明 | 1 |
| 2 | 小白 | 3 |
+----+--------+-----------+
LIST 分割區就是根據列舉值進行分割區,每個分割區的值都是離散的。只支援整形,非整形欄位需要通過函數轉換成整形。
在 5.5 版本之後,引入了 LIST COLUMN,可以使用多個列作為分割區鍵,並允許使用非整數型別的資料型別列作為分割區列。可以使用字串型別、DATE 和 DATETIME 列。與使用RANGE COLUMNS進行分割區一樣,不需要在 COLUMNS() 子句中使用表示式將列值轉換為整數。
CREATE TABLE `t_city_v1` (
`id` int(11) NOT NULL,
`name` varchar(32) NOT NULL,
`city` varchar(32) NOT NULL
) ENGINE=InnoDB
PARTITION BY LIST COLUMNS (`city`)
(PARTITION p1 VALUES IN ("北京", "上海", "杭州"),
PARTITION p2 VALUES IN ("浙江", "洛陽", "南寧"),
PARTITION p3 VALUES IN ("鄭州", "南京", "湖州")
);
3、HASH 分割區
HASH 分割區的目的是將資料均勻的分佈到預先定義的各個分割區中,保證各個分割區的資料資料量大致都是一樣的。
在 RANGE 分割區和 LIST 分割區中,必須明確的指定一個給定的列值或列值集合應該儲存在哪個分割區中,在 HASH 分割區中,MySQL 會自動完成這些工作。
使用 HASH 分割區的目的如下:
-
1、使分割區間資料分佈均勻,分割區間可以並行存取;
-
2、根據分割區鍵使用分割區修剪,基於分割區鍵的等值查詢開銷減小;
-
3、隨機分佈資料,以避免I/O瓶頸。
分割區鍵的選擇一般要滿足以下要求:
-
1、選擇唯一或幾乎唯一的列或列的組合;
-
2、為每個2的冪次分割區建立多個分割區和子分割區。例如:2、4、8、16、32、64、128等。
來個栗子
CREATE TABLE `t_hash` (
`custkey` int(11) NOT NULL,
`name` varchar(25) NOT NULL,
PRIMARY KEY (`custkey`)
) ENGINE=InnoDB
PARTITION BY HASH(custkey)
( PARTITION p1,
PARTITION p2,
PARTITION p3,
PARTITION p4
);
insert into t_hash values(1, "小明"),(2, "小白"),(10, "小紅"),(15, "小李");
檢視分割區資料
$ select
partition_name part,
partition_expression expr,
partition_description descr,
table_rows
from information_schema.partitions where
table_schema = schema()
and table_name='t_hash';
+------+-----------+-------+------------+
| part | expr | descr | TABLE_ROWS |
+------+-----------+-------+------------+
| p1 | `custkey` | NULL | 0 |
| p2 | `custkey` | NULL | 1 |
| p3 | `custkey` | NULL | 2 |
| p4 | `custkey` | NULL | 1 |
+------+-----------+-------+------------+
指定 HASH 分割區的數量將自動生成各個分割區的內部名稱。
CREATE TABLE `t_hash_1` (
`custkey` int(11) NOT NULL,
`name` varchar(25) NOT NULL,
PRIMARY KEY (`custkey`)
) ENGINE=InnoDB
PARTITION BY HASH(custkey)
PARTITIONS 8;
檢視分割區資料
$ select
partition_name part,
partition_expression expr,
partition_description descr,
table_rows
from information_schema.partitions where
table_schema = schema()
and table_name='t_hash_1';
+------+-----------+-------+------------+
| part | expr | descr | TABLE_ROWS |
+------+-----------+-------+------------+
| p0 | `custkey` | NULL | 0 |
| p1 | `custkey` | NULL | 0 |
| p2 | `custkey` | NULL | 0 |
| p3 | `custkey` | NULL | 0 |
| p4 | `custkey` | NULL | 0 |
| p5 | `custkey` | NULL | 0 |
| p6 | `custkey` | NULL | 0 |
| p7 | `custkey` | NULL | 0 |
+------+-----------+-------+------------+
4、KEY 分割區
KEY 分割區和 HASH 分割區類似。不同之處,HASH 使用使用者自定義的函數進行分割區,KEY 分割區使用 MYSQL 資料庫提供的函數進行分割區。
KEY 分割區使用 MySQL 伺服器提供的 HASH 函數;KEY 分割區支援使用除 blob 和 text 外其他型別的列作為分割區鍵。
KEY 分割區有如下幾種情況:
1、KEY 分割區可以不指定分割區鍵,預設使用主鍵作為分割區鍵;
2、沒有主鍵時,則選擇非空唯一鍵作為分割區鍵;
3、若無主鍵又無唯一鍵,則必須指定分割區鍵,否則報錯。
CREATE TABLE `t_key` (
`custkey` int(11) NOT NULL,
`name` varchar(25) NOT NULL,
PRIMARY KEY (`custkey`)
) ENGINE=InnoDB
PARTITION BY KEY(custkey)
PARTITIONS 8;
檢視分割區資料
$ select
partition_name part,
partition_expression expr,
partition_description descr,
table_rows
from information_schema.partitions where
table_schema = schema()
and table_name='t_key';
+------+-----------+-------+------------+
| part | expr | descr | TABLE_ROWS |
+------+-----------+-------+------------+
| p0 | `custkey` | NULL | 0 |
| p1 | `custkey` | NULL | 0 |
| p2 | `custkey` | NULL | 0 |
| p3 | `custkey` | NULL | 0 |
| p4 | `custkey` | NULL | 0 |
| p5 | `custkey` | NULL | 0 |
| p6 | `custkey` | NULL | 0 |
| p7 | `custkey` | NULL | 0 |
+------+-----------+-------+------------+
子分割區
子分割區是在分割區的基礎之上在進行分割區,有時也稱這種分割區為複合分割區。MYSQL 從 5.1 開始支援對已經通過 range 和 list 分割區的表在進行子分割區,子分割區可以使用 hash 分割區,也可以使用 key 分割區。
CREATE TABLE `t_hash_5` (
`id` int(11) NOT NULL,
`purchased` date NOT NULL,
`name` varchar(25) NOT NULL,
KEY `purchased` (`purchased`)
) ENGINE=InnoDB
PARTITION BY RANGE(year(purchased))
SUBPARTITION BY HASH (to_days(purchased))
SUBPARTITIONS 4 (
partition p0 values less than (1990),
partition p1 values less than (2000),
partition p2 values less than (MAXVALUE)
);
上面的栗子,可以看到首先進行了 RANGE 分割區,然後又進行了一次 HASH 分割區,分割區的數量就是 3X4 = 12 個,首先建立了 3 個 RANGE 分割區,同時每個 RANGE 分割區又建立了 4 個 HASH 子分割區,一共就是 12 個分割區。
子分割區建立有下面幾個注意的點
1、每個分割區的數量必須相同;
2、要在一個分割區表的任何分割區上使用 SUBPARTITION 來定義子分割區,就需要給所有的分割區定義子分割區;
3、每個 SUBPARTITION 字句必須包含一個分割區的名字;
4、子分割區的名字必須是唯一的。
獲取 MySQL 分割區表的資訊
1、show create table 表名,獲取建立分割區表的時候的建立語句;
show create table t;
+-------+------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------+
| Table | Create Table |
+-------+------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------+
| t | CREATE TABLE `t` (
`id` int(11) NOT NULL,
PRIMARY KEY (`id`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_unicode_ci
/*!50100 PARTITION BY RANGE ( id)
(PARTITION p0 VALUES LESS THAN (10) ENGINE = InnoDB,
PARTITION p1 VALUES LESS THAN (20) ENGINE = InnoDB) */ |
+-------+------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------+
2、show table status 可以檢視表是不是分割區表;
show table status;
+------+--------+---------+------------+------+----------------+-------------+-----------------+--------------+-----------+----------------+---------------------+---------------------+------------+--------------------+----------+----------------+---------+
| Name | Engine | Version | Row_format | Rows | Avg_row_length | Data_length | Max_data_length | Index_length | Data_free | Auto_increment | Create_time | Update_time | Check_time | Collation | Checksum | Create_options | Comment |
+------+--------+---------+------------+------+----------------+-------------+-----------------+--------------+-----------+----------------+---------------------+---------------------+------------+--------------------+----------+----------------+---------+
| t | InnoDB | 10 | Dynamic | 4 | 8192 | 32768 | 0 | 0 | 0 | NULL | 2023-06-08 01:43:39 | 2023-06-08 01:43:39 | NULL | utf8mb4_unicode_ci | NULL | partitioned | |
| user | InnoDB | 10 | Dynamic | 2 | 8192 | 16384 | 0 | 0 | 0 | 4 | 2023-06-07 03:15:28 | NULL | NULL | utf8mb4_unicode_ci | NULL | | |
+------+--------+---------+------------+------+----------------+-------------+-----------------+--------------+-----------+----------------+---------------------+---------------------+------------+--------------------+----------+----------------+---------+
2 rows in set (0.01 sec)
Create_options 是 partitioned 就表示是分割區表。
3、通過 information_schema.partitions 表,可以查詢表具有哪幾個分割區、分割區的方法、分割區中資料的記錄數等資訊;
$ select
partition_name part,
partition_expression expr,
partition_description descr,
table_rows
from information_schema.partitions where
table_schema = schema()
and table_name='t';
+------+------+-------+------------+
| part | expr | descr | table_rows |
+------+------+-------+------------+
| p0 | id | 10 | 2 |
| p1 | id | 20 | 2 |
+------+------+-------+------------+
4、通過 explain 可以檢視查詢預計使用的分割區;
$ explain select * from t where id=10;
+----+-------------+-------+------------+-------+---------------+---------+---------+-------+------+----------+-------------+
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
+----+-------------+-------+------------+-------+---------------+---------+---------+-------+------+----------+-------------+
| 1 | SIMPLE | t | p1 | const | PRIMARY | PRIMARY | 4 | const | 1 | 100.00 | Using index |
+----+-------------+-------+------------+-------+---------------+---------+---------+-------+------+----------+-------------+
可以看到上面的查詢使用到了分割區 p1。
總結
1、InnoDB 儲存引擎的儲存邏輯,所有資料都會被邏輯的儲存在一個空間中,這個空間稱為 InnoDB(Tablespace) 表空間,本質上是一個或多個磁碟檔案組成的虛擬檔案系統。InnoDB 表空間不僅僅儲存了表和索引,它還儲存了回滾紀錄檔(redo log)、插入緩衝(insert buffer)、雙寫緩衝(doublewrite buffer)以及其他內部資料結構。
2、表空間,由段(segment),區(extend),頁(page)組層。頁在一些檔案中也被稱為塊(block)。
3、分割區的過程是將一個表或者索引分為多個更小,更可管理的部分。就存取資料庫的應用來說,從邏輯上講只有一個表或者索引,但是在物理上這個表或者索引可能由數十個物理分割區組成。每個分割區都是獨立的物件,可以獨自處理,也可以作為一個更大物件的一部分進行處理。
4、資料庫分割區和分表相似,都是按照規則分解表。不同在於分表將大表分解若干個獨立的實體表,而分割區是將資料分段劃分在多個位置存放,分割區後,表還是一張表,但資料雜湊到多個位置了。應用程式讀寫的時候操作還是表名,DB自動去組織分割區的資料。
5、MySQL 資料庫支援下面幾種型別的分割區
-
1、RANGE 分割區:行資料基於一個給定連續區間的列值被放入分割區。MySQL 5.5 開始支援
RANGE COLUMNS的分割區; -
2、LIST 分割區:和 RANGE 分割區類似,只是 LIST 分割區面向的是離散的值。MySQL 5.5 開始支援
LIST COLUMNS的分割區; -
3、HASH 分割區:根據使用者自定義的表達是的返回值來進行分割區,返回值不能為負數;
-
4、KEY 分割區:根據 MySQL 資料庫提供的雜湊函數來進行分割區。
參考
【高效能MySQL(第3版)】https://book.douban.com/subject/23008813/
【MySQL 實戰 45 講】https://time.geekbang.org/column/100020801
【MySQL技術內幕】https://book.douban.com/subject/24708143/
【MySQL學習筆記】https://github.com/boilingfrog/Go-POINT/tree/master/mysql
【InnoDB 表空間】https://blog.csdn.net/u010647035/article/details/105009979
【何時選擇LIST分割區】https://help.aliyun.com/document_detail/412383.html?spm=a2c4g.412381.0.0.5bc411405bQXje