JavaCV臉部辨識三部曲之三:識別和預覽
歡迎存取我的GitHub
這裡分類和彙總了欣宸的全部原創(含配套原始碼):https://github.com/zq2599/blog_demos
《JavaCV臉部辨識三部曲》連結
本篇概覽
-
作為《JavaCV臉部辨識三部曲》的終篇,今天咱們要開發一個實用的功能:有人出現在攝像頭中時,應用程式在預覽視窗標註出此人的身份,效果如下圖所示:

-
簡單來說,本篇要做的事情如下:
- 理解重點概念:confidence
- 理解重點概念:threshold
- 編碼
- 驗證
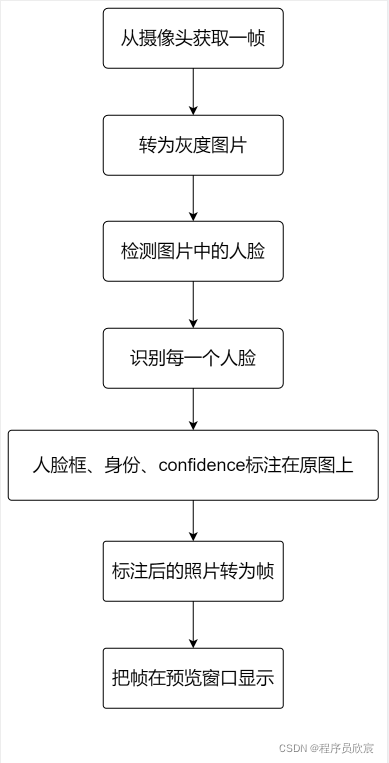
- 今天編寫的程式碼,主要功能如下圖所示:
理解重點概念:confidence
-
confidence和threshold是OpenCV的臉部辨識中非常重要的兩個概念,咱們先把這兩個概念搞清楚,再去編碼就非常容易了
-
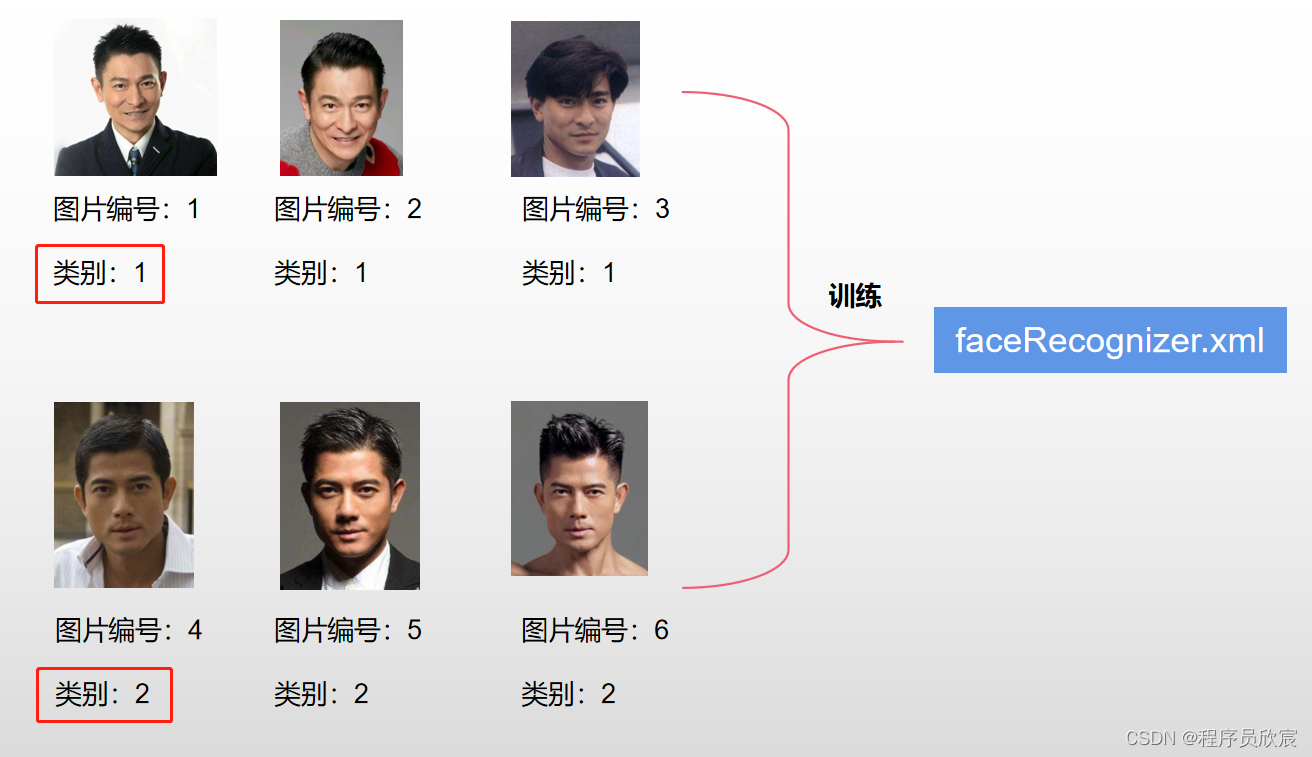
假設,咱們用下面六張照片訓練出包含兩個類別的模型:
-
用一張新的照片去訓練好的模型中做識別,如下圖,識別結果有兩部分內容:label和confidence

-
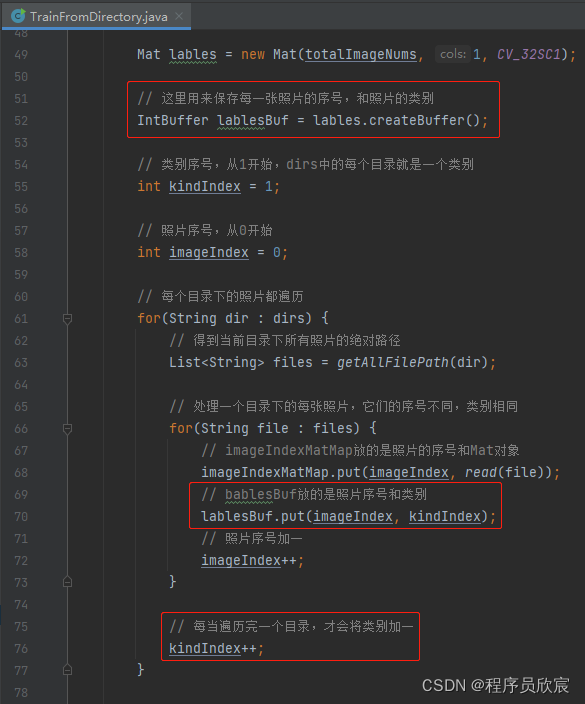
先說lable,這個好理解,與訓練時的lable一致(回顧上一篇的程式碼,lable如下圖紅框所示),前面圖中lable等於2,表示被判定為郭富城:
-
按照上面的說法,lable等於2就能確定照片中的人像是郭富城嗎?
-
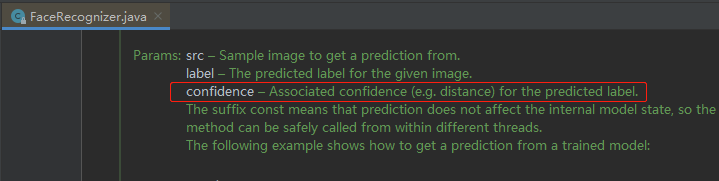
當然不能!!!此時confidence欄位就非常重要了,先看JavaCV原始碼中對confidence的解釋,如下圖紅框所示,我的理解是:與lable值相關聯的置信度,或者說這張臉是郭富城的可能性:
-
如果理解為可能性,那麼問題來了,這是個double型的值,這個值越大,表示可能性越大還是越小?
-
上圖並沒有明說,但是那一句e.g. distance,讓我想起了機器學習中的K-means,此時我腦海中的畫面如下:
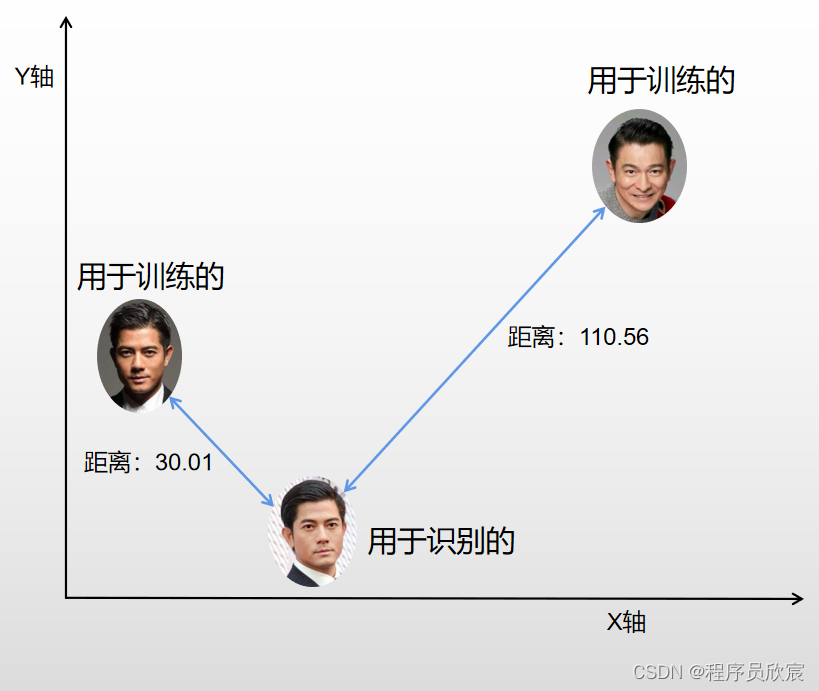
-若真如上圖所示,那麼顯然confidence越小,是郭富城的可能性就越大了,接下來再去找一些權威的說法: -
OpenCV的官方論壇有個貼文的說法如下圖:程式碼中的confidence變數屬於命名不當,其含義不是可信度,而是與模型中的類別的距離:
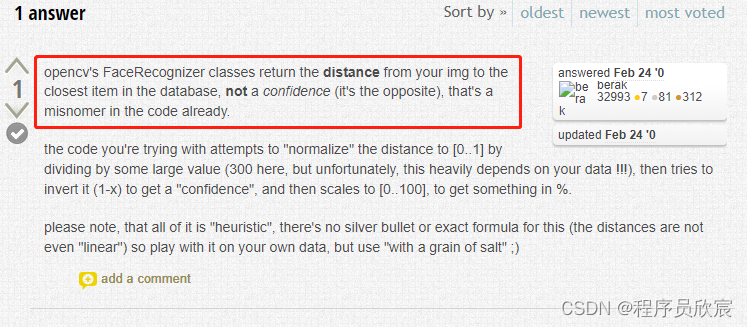
-
再看第二個解釋,如下圖紅框,說得很清楚了,值越小,與模型中類別的相似度越高,0表示完全匹配:
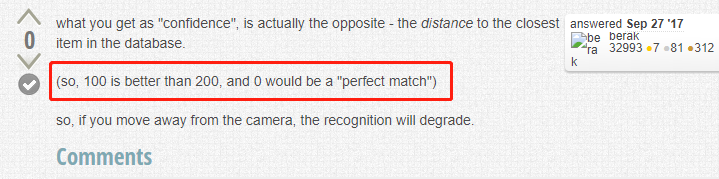
-
再看一個Stack Overflow的解釋:

-
至此,相信您對confidence已經足夠理解了,lable等於2,confidence=30.01,意思是:被識別照片與郭富城最相似,距離為30.01,距離越小,是郭富城的可能性越大
理解重點概念:threshold
- 在聊threshold之前,咱們先看一個場景,還是劉德華郭富城的模型,這次咱們拿喜洋洋的照片給模型識別,識別結果如下:
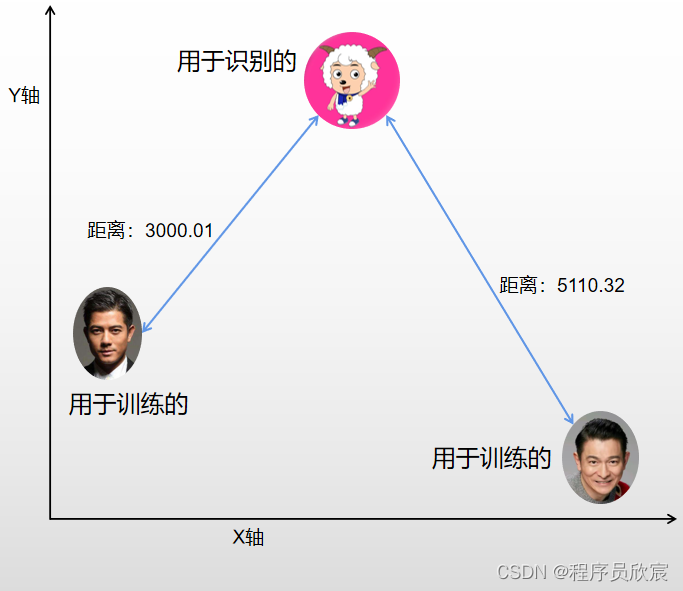
- 顯然,模型不會告訴你照片裡是誰,只會告訴你:和郭富城的距離是3000.01
- 看到這裡,聰明的您可能會這麼想:那我就寫一段程式碼吧,識別結果的confidence如果太大(例如超過100),就判定用於識別的人不屬於訓練模型的任何一個類別
- 上述功能,OpenCV已經幫咱們想到了,那就是:threshold,翻譯過來即門限,如果咱們設定了threshold等於100,那麼,一旦距離超過100,OpenCV的lable返回值就是-1
- 理解了confidence和threshold,接下來可以寫臉部辨識的程式碼了,感謝咱們的充分準備,接下來是絲般順滑的編碼過程...
原始碼下載
- 《JavaCV臉部辨識三部曲》的完整原始碼可在GitHub下載到,地址和連結資訊如下表所示(https://github.com/zq2599/blog_demos):
| 名稱 | 連結 | 備註 |
|---|---|---|
| 專案主頁 | https://github.com/zq2599/blog_demos | 該專案在GitHub上的主頁 |
| git倉庫地址(https) | https://github.com/zq2599/blog_demos.git | 該專案原始碼的倉庫地址,https協定 |
| git倉庫地址(ssh) | [email protected]:zq2599/blog_demos.git | 該專案原始碼的倉庫地址,ssh協定 |
- 這個git專案中有多個資料夾,本篇的原始碼在javacv-tutorials資料夾下,如下圖紅框所示:
- javacv-tutorials裡面有多個子工程,《JavaCV臉部辨識三部曲》系列的程式碼在simple-grab-push工程下:
編碼:臉部辨識服務
- 開始正式編碼,今天咱們不會新建工程,而是繼續使用《JavaCV的攝像頭實戰之一:基礎》中建立的simple-grab-push工程
- 先定義一個Bean類PredictRlt.java,用來儲存識別結果(lable和confidence欄位):
package com.bolingcavalry.grabpush.extend;
import lombok.Data;
@Data
public class PredictRlt {
private int lable;
private double confidence;
}
- 然後把臉部辨識有關的服務集中在RecognizeService.java中,方便主程式使用,程式碼如下,有幾處要注意的地方稍後提到:
package com.bolingcavalry.grabpush.extend;
import com.bolingcavalry.grabpush.Constants;
import org.bytedeco.opencv.global.opencv_imgcodecs;
import org.bytedeco.opencv.opencv_core.Mat;
import org.bytedeco.opencv.opencv_core.Size;
import org.bytedeco.opencv.opencv_face.FaceRecognizer;
import org.bytedeco.opencv.opencv_face.FisherFaceRecognizer;
import static org.bytedeco.opencv.global.opencv_imgcodecs.IMREAD_GRAYSCALE;
import static org.bytedeco.opencv.global.opencv_imgproc.resize;
/**
* @author willzhao
* @version 1.0
* @description 把臉部辨識的服務集中在這裡
* @date 2021/12/12 21:32
*/
public class RecognizeService {
private FaceRecognizer faceRecognizer;
// 推理結果的標籤
private int[] plabel;
// 推理結果的置信度
private double[] pconfidence;
// 推理結果
private PredictRlt predictRlt;
// 用於推理的圖片尺寸,要和訓練時的尺寸保持一致
private Size size= new Size(Constants.RESIZE_WIDTH, Constants.RESIZE_HEIGHT);
public RecognizeService(String modelPath) {
plabel = new int[1];
pconfidence = new double[1];
predictRlt = new PredictRlt();
// 識別類的範例化,與訓練時相同
faceRecognizer = FisherFaceRecognizer.create();
// 載入的是訓練時生成的模型
faceRecognizer.read(modelPath);
// 設定門限,這個可以根據您自身的情況不斷調整
faceRecognizer.setThreshold(Constants.MAX_CONFIDENCE);
}
/**
* 將Mat範例給模型去推理
* @param mat
* @return
*/
public PredictRlt predict(Mat mat) {
// 調整到和訓練一致的尺寸
resize(mat, mat, size);
boolean isFinish = false;
try {
// 推理(這一行可能丟擲RuntimeException異常,因此要補貨,否則會導致程式退出)
faceRecognizer.predict(mat, plabel, pconfidence);
isFinish = true;
} catch (RuntimeException runtimeException) {
runtimeException.printStackTrace();
}
// 如果發生過異常,就提前返回
if (!isFinish) {
return null;
}
// 將推理結果寫入返回物件中
predictRlt.setLable(plabel[0]);
predictRlt.setConfidence(pconfidence[0]);
return predictRlt;
}
}
- 上述程式碼有以下幾處需要注意:
- 構造方法中,通過faceRecognizer.setThreshold設定門限,我在實際使用中發現50比較合適,您可以根據自己的情況不斷調整
- predict方法中,用於識別的圖片要用resize方法調整大小,尺寸要和訓練時的尺寸一致
- 實測發現,在一張照片中出現多個人臉時,faceRecognizer.predict可能丟擲RuntimeException異常,因此這裡要捕獲異常,避免程式崩潰退出
編碼:檢測和識別
- 檢測有關的介面DetectService.java,如下,和《JavaCV臉部辨識三部曲之一:視訊中的人臉儲存為圖片》中的完全一致:
package com.bolingcavalry.grabpush.extend;
import com.bolingcavalry.grabpush.Constants;
import org.bytedeco.javacv.Frame;
import org.bytedeco.javacv.OpenCVFrameConverter;
import org.bytedeco.opencv.opencv_core.*;
import org.bytedeco.opencv.opencv_objdetect.CascadeClassifier;
import static org.bytedeco.opencv.global.opencv_core.CV_8UC1;
import static org.bytedeco.opencv.global.opencv_imgcodecs.imwrite;
import static org.bytedeco.opencv.global.opencv_imgproc.*;
/**
* @author willzhao
* @version 1.0
* @description 檢測工具的通用介面
* @date 2021/12/5 10:57
*/
public interface DetectService {
/**
* 根據傳入的MAT構造相同尺寸的MAT,存放灰度圖片用於以後的檢測
* @param src 原始圖片的MAT物件
* @return 相同尺寸的灰度圖片的MAT物件
*/
static Mat buildGrayImage(Mat src) {
return new Mat(src.rows(), src.cols(), CV_8UC1);
}
/**
* 初始化操作,例如模型下載
* @throws Exception
*/
void init() throws Exception;
/**
* 得到原始幀,做識別,新增框選
* @param frame
* @return
*/
Frame convert(Frame frame);
/**
* 釋放資源
*/
void releaseOutputResource();
}
- 然後就是DetectService的實現類DetectAndRecognizeService .java,功能是用攝像頭的一幀圖片檢測人臉,再拿檢測到的人臉給RecognizeService做識別,完整程式碼如下,有幾處要注意的地方稍後提到:
package com.bolingcavalry.grabpush.extend;
import lombok.extern.slf4j.Slf4j;
import org.bytedeco.javacpp.Loader;
import org.bytedeco.javacv.Frame;
import org.bytedeco.javacv.OpenCVFrameConverter;
import org.bytedeco.opencv.opencv_core.*;
import org.bytedeco.opencv.opencv_objdetect.CascadeClassifier;
import java.io.File;
import java.net.URL;
import java.util.Map;
import static org.bytedeco.opencv.global.opencv_imgproc.*;
/**
* @author willzhao
* @version 1.0
* @description 音訊相關的服務
* @date 2021/12/3 8:09
*/
@Slf4j
public class DetectAndRecognizeService implements DetectService {
/**
* 每一幀原始圖片的物件
*/
private Mat grabbedImage = null;
/**
* 原始圖片對應的灰度圖片物件
*/
private Mat grayImage = null;
/**
* 分類器
*/
private CascadeClassifier classifier;
/**
* 轉換器
*/
private OpenCVFrameConverter.ToMat converter = new OpenCVFrameConverter.ToMat();
/**
* 檢測模型檔案的下載地址
*/
private String detectModelFileUrl;
/**
* 處理每一幀的服務
*/
private RecognizeService recognizeService;
/**
* 為了顯示的時候更加友好,給每個分類對應一個名稱
*/
private Map<Integer, String> kindNameMap;
/**
* 構造方法
* @param detectModelFileUrl
* @param recognizeModelFilePath
* @param kindNameMap
*/
public DetectAndRecognizeService(String detectModelFileUrl, String recognizeModelFilePath, Map<Integer, String> kindNameMap) {
this.detectModelFileUrl = detectModelFileUrl;
this.recognizeService = new RecognizeService(recognizeModelFilePath);
this.kindNameMap = kindNameMap;
}
/**
* 音訊取樣物件的初始化
* @throws Exception
*/
@Override
public void init() throws Exception {
// 下載模型檔案
URL url = new URL(detectModelFileUrl);
File file = Loader.cacheResource(url);
// 模型檔案下載後的完整地址
String classifierName = file.getAbsolutePath();
// 根據模型檔案範例化分類器
classifier = new CascadeClassifier(classifierName);
if (classifier == null) {
log.error("Error loading classifier file [{}]", classifierName);
System.exit(1);
}
}
@Override
public Frame convert(Frame frame) {
// 由幀轉為Mat
grabbedImage = converter.convert(frame);
// 灰度Mat,用於檢測
if (null==grayImage) {
grayImage = DetectService.buildGrayImage(grabbedImage);
}
// 進行臉部辨識,根據結果做處理得到預覽視窗顯示的幀
return detectAndRecoginze(classifier, converter, frame, grabbedImage, grayImage, recognizeService, kindNameMap);
}
/**
* 程式結束前,釋放臉部辨識的資源
*/
@Override
public void releaseOutputResource() {
if (null!=grabbedImage) {
grabbedImage.release();
}
if (null!=grayImage) {
grayImage.release();
}
if (null==classifier) {
classifier.close();
}
}
/**
* 檢測圖片,將檢測結果用矩形標註在原始圖片上
* @param classifier 分類器
* @param converter Frame和mat的轉換器
* @param rawFrame 原始視訊幀
* @param grabbedImage 原始視訊幀對應的mat
* @param grayImage 存放灰度圖片的mat
* @param kindNameMap 每個分類編號對應的名稱
* @return 標註了識別結果的視訊幀
*/
static Frame detectAndRecoginze(CascadeClassifier classifier,
OpenCVFrameConverter.ToMat converter,
Frame rawFrame,
Mat grabbedImage,
Mat grayImage,
RecognizeService recognizeService,
Map<Integer, String> kindNameMap) {
// 當前圖片轉為灰度圖片
cvtColor(grabbedImage, grayImage, CV_BGR2GRAY);
// 存放檢測結果的容器
RectVector objects = new RectVector();
// 開始檢測
classifier.detectMultiScale(grayImage, objects);
// 檢測結果總數
long total = objects.size();
// 如果沒有檢測到結果,就用原始幀返回
if (total<1) {
return rawFrame;
}
PredictRlt predictRlt;
int pos_x;
int pos_y;
int lable;
double confidence;
String content;
// 如果有檢測結果,就根據結果的資料構造矩形框,畫在原圖上
for (long i = 0; i < total; i++) {
Rect r = objects.get(i);
// 核心程式碼,把檢測到的人臉拿去識別
predictRlt = recognizeService.predict(new Mat(grayImage, r));
// 如果返回為空,表示出現過異常,就執行下一個
if (null==predictRlt) {
System.out.println("return null");
continue;
}
// 分類的編號(訓練時只有1和2,這裡只有有三個值,1和2與訓練的分類一致,還有個-1表示沒有匹配上)
lable = predictRlt.getLable();
// 與模型中的分類的距離,值越小表示相似度越高
confidence = predictRlt.getConfidence();
// 得到分類編號後,從map中取得名字,用來顯示
if (kindNameMap.containsKey(predictRlt.getLable())) {
content = String.format("%s, confidence : %.4f", kindNameMap.get(lable), confidence);
} else {
// 取不到名字的時候,就顯示unknown
content = "unknown(" + predictRlt.getLable() + ")";
System.out.println(content);
}
int x = r.x(), y = r.y(), w = r.width(), h = r.height();
rectangle(grabbedImage, new Point(x, y), new Point(x + w, y + h), Scalar.RED, 1, CV_AA, 0);
pos_x = Math.max(r.tl().x()-10, 0);
pos_y = Math.max(r.tl().y()-10, 0);
putText(grabbedImage, content, new Point(pos_x, pos_y), FONT_HERSHEY_PLAIN, 1.5, new Scalar(0,255,0,2.0));
}
// 釋放檢測結果資源
objects.close();
// 將標註過的圖片轉為幀,返回
return converter.convert(grabbedImage);
}
}
- 上述程式碼有幾處要注意:
- 重點關注detectAndRecoginze方法,這裡面先呼叫classifier.detectMultiScale檢測出當前照片所有的人臉,然後把每一張人臉交個recognizeService進行識別,
- 識別結果的lable是個int型的,看起來不夠友好,因此從kindNameMap中根據lable找出對應的名稱來
- 最終給每個頭像新增矩形框,還在左上角新增識別結果,以及confidence的值
- 處理完畢後轉為Frame物件返回,這樣的幀顯示在預覽頁面,效果就是視訊中每個人被框選出來,並帶有身份
- 現在核心程式碼已經寫完,需要再寫一些程式碼來使用DetectAndRecognizeService
編碼:執行框架
- 《JavaCV的攝像頭實戰之一:基礎》建立的simple-grab-push工程中已經準備好了父類別AbstractCameraApplication,所以本篇繼續使用該工程,建立子類實現那些抽象方法即可
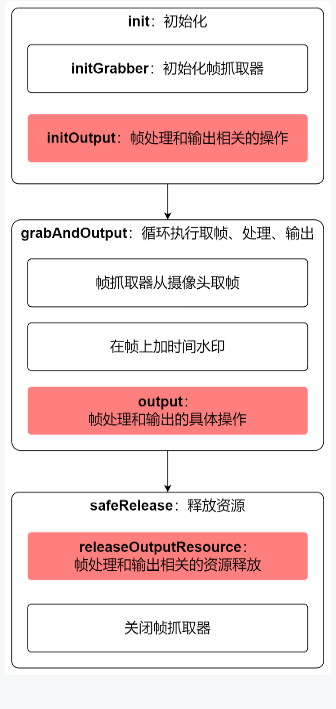
- 編碼前先回顧父類別的基礎結構,如下圖,粗體是父類別定義的各個方法,紅色塊都是需要子類來實現抽象方法,所以接下來,咱們以本地視窗預覽為目標實現這三個紅色方法即可:
- 新建檔案PreviewCameraWithIdentify.java,這是AbstractCameraApplication的子類,其程式碼很簡單,接下來按上圖順序依次說明
- 先定義CanvasFrame型別的成員變數previewCanvas,這是展示視訊幀的本地視窗:
protected CanvasFrame previewCanvas
- 把前面建立的DetectService作為成員變數,後面檢測的時候會用到:
/**
* 檢測工具介面
*/
private DetectService detectService;
- PreviewCameraWithIdentify的構造方法,接受DetectService的範例:
/**
* 不同的檢測工具,可以通過構造方法傳入
* @param detectService
*/
public PreviewCameraWithIdentify(DetectService detectService) {
this.detectService = detectService;
}
- 然後是初始化操作,可見是previewCanvas的範例化和引數設定,還有檢測、識別的初始化操作:
@Override
protected void initOutput() throws Exception {
previewCanvas = new CanvasFrame("攝像頭預覽和身份識別", CanvasFrame.getDefaultGamma() / grabber.getGamma());
previewCanvas.setDefaultCloseOperation(JFrame.EXIT_ON_CLOSE);
previewCanvas.setAlwaysOnTop(true);
// 檢測服務的初始化操作
detectService.init();
}
- 接下來是output方法,定義了拿到每一幀視訊資料後做什麼事情,這裡呼叫了detectService.convert檢測人臉並儲存圖片,然後在本地視窗顯示:
@Override
protected void output(Frame frame) {
// 原始幀先交給檢測服務處理,這個處理包括物體檢測,再將檢測結果標註在原始圖片上,
// 然後轉換為幀返回
Frame detectedFrame = detectService.convert(frame);
// 預覽視窗上顯示的幀是標註了檢測結果的幀
previewCanvas.showImage(detectedFrame);
}
- 最後是處理視訊的迴圈結束後,程式退出前要做的事情,先關閉本地視窗,再釋放檢測服務的資源:
@Override
protected void releaseOutputResource() {
if (null!= previewCanvas) {
previewCanvas.dispose();
}
// 檢測工具也要釋放資源
detectService.releaseOutputResource();
}
- 由於檢測有些耗時,所以兩幀之間的間隔時間要低於普通預覽:
@Override
protected int getInterval() {
return super.getInterval()/8;
}
- 至此,功能已開發完成,再寫上main方法,程式碼如下,有幾處要注意的地方稍後說明:
public static void main(String[] args) {
String modelFileUrl = "https://raw.github.com/opencv/opencv/master/data/haarcascades/haarcascade_frontalface_alt.xml";
String recognizeModelFilePath = "E:\\temp\\202112\\18\\001\\faceRecognizer.xml";
// 這裡分類編號的身份的對應關係,和之前訓練時候的設定要保持一致
Map<Integer, String> kindNameMap = new HashMap();
kindNameMap.put(1, "Man");
kindNameMap.put(2, "Woman");
// 檢測服務
DetectService detectService = new DetectAndRecognizeService(modelFileUrl,recognizeModelFilePath, kindNameMap);
// 開始檢測
new PreviewCameraWithIdentify(detectService).action(1000);
}
- 上述main方法中,有以下幾處需要注意:
- kindNameMap是個HashMap,裡面放這每個分類編號對應的名稱,我訓練的模型中包含了兩位群眾演員的頭像,給他們分別起名Man和Woman
- modelFileUrl是人臉檢測時用到的模型地址
- recognizeModelFilePath是臉部辨識時用到的模型地址,這個模型是《JavaCV臉部辨識三部曲之二:訓練》一文中訓練的模型
- 至此,臉部辨識的程式碼已經寫完,執行main方法,請幾位群眾演員來到攝像頭前面,驗證效果吧
驗證
-
程式執行起來後,請名為Man的群眾演員A站在攝像頭前面,如下圖,識別成功:

-
接下來,請名為Woman的群眾演員B過來,和群眾演員A同框,如下圖,同時識別成功,不過偶爾會識別錯誤,提示成unknown(-1):

-
再請一個沒有參與訓練的小群眾演員過來,與A同框,此刻的識別也是準確的,小演員被標註為unknown(-1):

-
去看程式的控制檯,發現FaceRecognizer.predict方法會丟擲異常,幸好程式捕獲了異常,不會把整個程序中斷退出:

-
至此,整個《JavaCV臉部辨識三部曲》全部完成,如果您是位java程式設計師,正在尋找臉部辨識相關的方案,希望本系列能給您一些參考
-
另外《JavaCV臉部辨識三部曲》是《JavaCV的攝像頭實戰》系列的分支,作為主幹的《JavaCV的攝像頭實戰》依然在持續更新中,欣宸原創會繼續與您一路相伴,學習、實戰、提升