面試官:講講MySql索引失效的幾種情況
2023-06-29 15:00:22
索引失效
準備資料:
CREATE TABLE `dept` (
`id` INT(11) NOT NULL AUTO_INCREMENT,
`deptName` VARCHAR(30) DEFAULT NULL,
`address` VARCHAR(40) DEFAULT NULL,
ceo INT NULL ,
PRIMARY KEY (`id`)
) ENGINE=INNODB AUTO_INCREMENT=1;
CREATE TABLE `emp` (
`id` INT(11) NOT NULL AUTO_INCREMENT,
`empno` INT NOT NULL ,
`name` VARCHAR(20) DEFAULT NULL,
`age` INT(3) DEFAULT NULL,
`deptId` INT(11) DEFAULT NULL,
PRIMARY KEY (`id`)
#CONSTRAINT `fk_dept_id` FOREIGN KEY (`deptId`) REFERENCES `t_dept` (`id`)
) ENGINE=INNODB AUTO_INCREMENT=1;
1、計算、函數導致索引失效
-- 顯示查詢分析
EXPLAIN SELECT * FROM emp WHERE emp.name LIKE 'abc%';
EXPLAIN SELECT * FROM emp WHERE LEFT(emp.name,3) = 'abc'; --索引失效
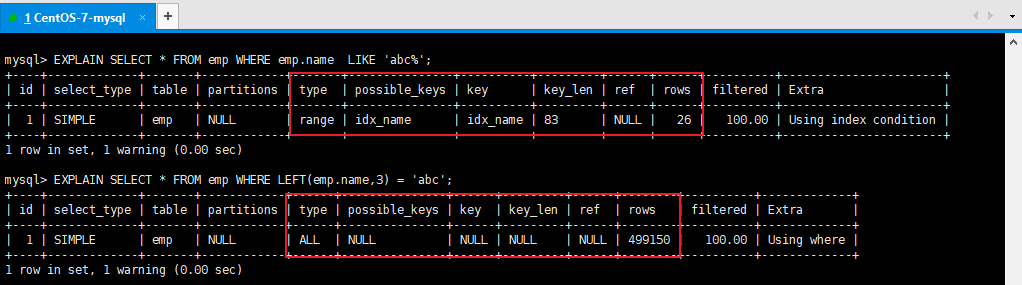
2、LIKE以%開頭索引失效
EXPLAIN SELECT * FROM emp WHERE name LIKE '%ab%'; --索引失效

拓展:Alibaba《Java開發手冊》
【強制】頁面搜尋嚴禁左模糊或者全模糊,如果需要請走搜尋引擎來解決。
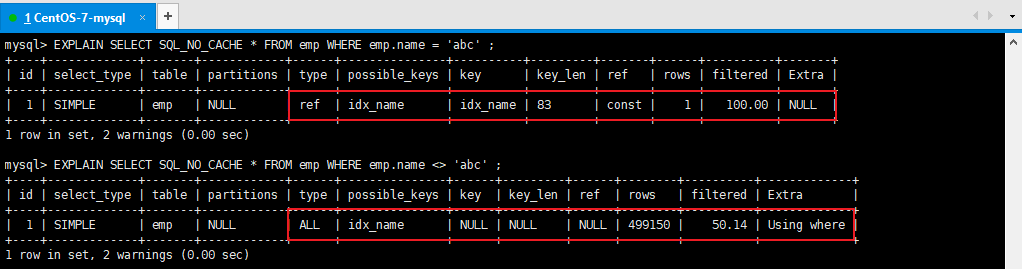
3、不等於(!= 或者<>)索引失效
EXPLAIN SELECT * FROM emp WHERE emp.name = 'abc' ;
EXPLAIN SELECT * FROM emp WHERE emp.name <> 'abc' ; --索引失效
4、IS NOT NULL 和 IS NULL
EXPLAIN SELECT * FROM emp WHERE emp.name IS NULL;
EXPLAIN SELECT * FROM emp WHERE emp.name IS NOT NULL; --索引失效
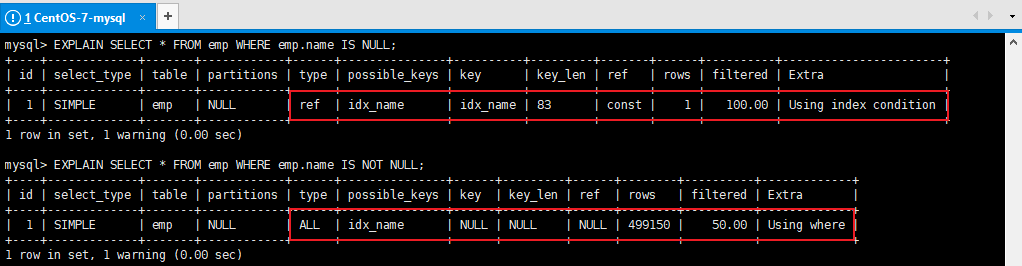
注意:當資料庫中的資料的索引列的NULL值達到比較高的比例的時候,即使在IS NOT NULL 的情況下 MySQL的查詢優化器會選擇使用索引,此時type的值是range(範圍查詢)
-- 將 id>20000 的資料的 name 值改為 NULL
UPDATE emp SET `name` = NULL WHERE `id` > 20000;
-- 執行查詢分析,可以發現 IS NOT NULL 使用了索引
-- 具體多少條記錄的值為NULL可以使索引在IS NOT NULL的情況下生效,由查詢優化器的演演算法決定
EXPLAIN SELECT * FROM emp WHERE emp.name IS NOT NULL;

測試完將name的值改回來
UPDATE emp SET `name` = rand_string(6) WHERE `id` > 20000;
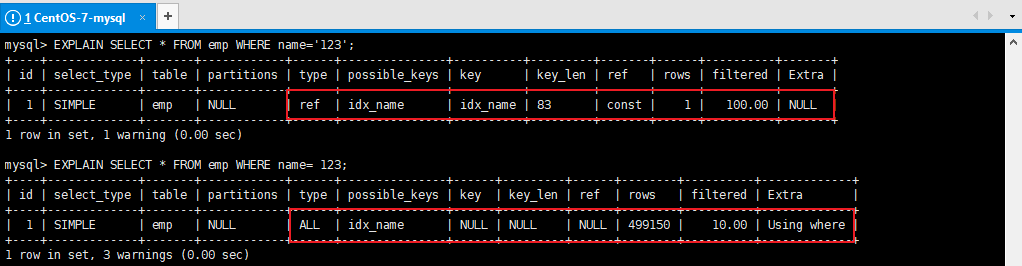
5、型別轉換導致索引失效
EXPLAIN SELECT * FROM emp WHERE name='123';
EXPLAIN SELECT * FROM emp WHERE name= 123; --索引失效
6、全值匹配我最愛
準備:
-- 首先刪除之前建立的索引
CALL proc_drop_index("atguigudb","emp");
問題:為以下查詢語句建立哪種索引效率最高
-- 查詢分析
EXPLAIN SELECT * FROM emp WHERE emp.age = 30 and deptid = 4 AND emp.name = 'abcd';
-- 執行SQL
SELECT * FROM emp WHERE emp.age = 30 and deptid = 4 AND emp.name = 'abcd';
-- 檢視執行時間
SHOW PROFILES;
建立索引並重新執行以上測試:
-- 建立索引:分別建立以下三種索引的一種,並分別進行以上查詢分析
CREATE INDEX idx_age ON emp(age);
CREATE INDEX idx_age_deptid ON emp(age,deptid);
CREATE INDEX idx_age_deptid_name ON emp(age,deptid,`name`);
結論:可以發現最高效的查詢應用了聯合索引 idx_age_deptid_name

7、最佳左字首法則
準備:
-- 首先刪除之前建立的索引
CALL proc_drop_index("atguigudb","emp");
-- 建立索引
CREATE INDEX idx_age_deptid_name ON emp(age,deptid,`name`);
問題:以下這些SQL語句能否命中 idx_age_deptid_name 索引,可以匹配多少個索引欄位
測試:
- 如果索引了多列,要遵守最左字首法則。即查詢從
索引的最左前列開始並且不跳過索引中的列。 - 過濾條件要使用索引,必須按照
索引建立時的順序,依次滿足,一旦跳過某個欄位,索引後面的欄位都無法被使用。
EXPLAIN SELECT * FROM emp WHERE emp.age=30 AND emp.name = 'abcd' ;
-- EXPLAIN結果:
-- key_len:5 只使用了age索引
-- 索引查詢的順序為 age、deptid、name,查詢條件中不包含deptid,無法使用deptid和name索引
EXPLAIN SELECT * FROM emp WHERE emp.deptid=1 AND emp.name = 'abcd';
-- EXPLAIN結果:
-- type: ALL, 執行了全表掃描
-- key_len: NULL, 索引失效
-- 索引查詢的順序為 age、deptid、name,查詢條件中不包含age,無法使用整個索引
EXPLAIN SELECT * FROM emp WHERE emp.age = 30 AND emp.deptid=1 AND emp.name = 'abcd';
-- EXPLAIN結果:
-- 索引查詢的順序為 age、deptid、name,匹配所有索引欄位
EXPLAIN SELECT * FROM emp WHERE emp.deptid=1 AND emp.name = 'abcd' AND emp.age = 30;
-- EXPLAIN結果:
-- 索引查詢的順序為 age、deptid、name,匹配所有索引欄位
8、索引中範圍條件右邊的列失效
準備:
-- 首先刪除之前建立的索引
CALL proc_drop_index("atguigudb","emp");
問題:為以下查詢語句建立哪種索引效率最高
EXPLAIN SELECT * FROM emp WHERE emp.age=30 AND emp.deptId>1000 AND emp.name = 'abc';
測試1:
-- 建立索引並執行以上SQL語句的EXPLAIN
CREATE INDEX idx_age_deptid_name ON emp(age,deptid,`name`);
-- key_len:10, 只是用了 age 和 deptid索引,name失效
注意:當我們修改deptId的範圍條件的時候,例如deptId>100,那麼整個索引失效,MySQL的優化器基於成本計算後認為沒必要使用索引了,所以就進行了全表掃描。(注意:因為表中的資料是隨機生成的,因此實際測試中根據具體資料的不同測試的結果也會不一樣,最終是否使用索引由優化器決定)

測試2:
-- 建立索引並執行以上SQL語句的EXPLAIN(將deptid索引的放在最後)
CREATE INDEX idx_age_name_deptid ON emp(age,`name`,deptid);
-- 使用了完整的索引
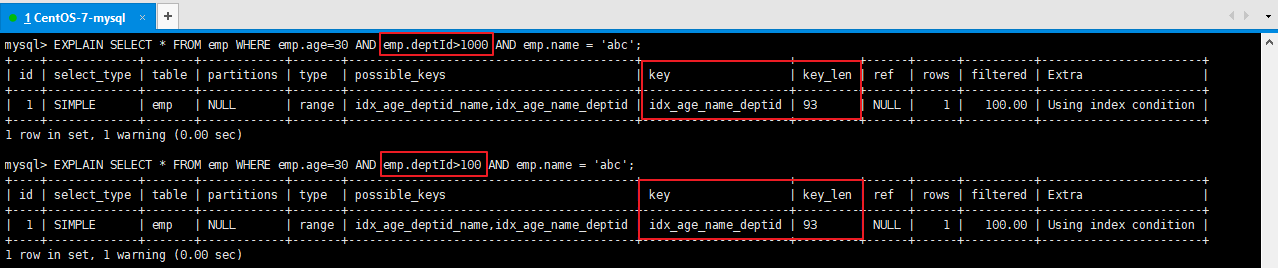
補充:以上兩個索引都存在的時候,MySQL優化器會自動選擇最好的方案
本文來自部落格園,作者:自律即自由-,轉載請註明原文連結:https://www.cnblogs.com/deyo/p/17514052.html