vivo 自研魯班分散式 ID 服務實踐
作者:vivo IT 平臺團隊- An Peng
本文介紹了什麼是分散式ID,分散式ID的業務場景以及9種分散式ID的實現方式,同時基於vivo內部IT的業務場景,介紹了自研魯班分散式ID服務的實踐。
一、方案背景
1.1 分散式ID應用的場景
隨著系統的業務場景複雜化、架構方案的優化演進,我們在克服問題的過程中,也總會延伸出新的技術訴求。分散式ID也是誕生於這樣的IT發展過程中,在不同的關聯模組內,我們需要一個全域性唯一的ID來讓模組既能並行地解耦運轉,也能輕鬆地進行整合處理。以下,首先讓我們一起回顧這些典型的分散式ID場景。
1.1.1 系統分庫分表
隨著系統的持續運作,常規的單庫單表在支撐更高規模的數量級時,無論是在效能或穩定性上都已經難以為繼,需要我們對目標邏輯資料表進行合理的物理拆分,這些同一業務表資料的拆分,需要有一套完整的 ID生成方案來保證拆分後的各物理表中同一業務ID不相沖突,並能在後續的合併分析中可以方便快捷地計算。
以公司的行銷系統的訂單為例,當前不但以分銷與零售的目標組織區別來進行分庫儲存,來實現多租戶的資料隔離,並且會以訂單的業務屬性(訂貨單、退貨單、調拔單等等)來進一步分拆訂單資料。在訂單建立的時候,根據這些規則去構造全域性唯一ID,建立訂單單據並儲存在對應的資料庫中;在通過訂單號查詢時,通過ID的規則,快速路由到對應的庫表中查詢;在BI數倉的統計業務裡,又需要彙總這些訂單資料進行報表分析。
1.1.2 系統多活部署
無論是面對著全球化的各國資料合規訴求,還是針對容災高可用的架構設計,我們都會對同一套系統進行多活部署。多活部署架構的各單元化服務,儲存的單據(如訂單/出入庫單/支付單等)均帶有部署區域屬性的ID結構去構成全域性唯一ID,建立單據並儲存在對應單元的資料庫中,在前端根據單據號查詢的場景,通過ID的規則,可快速路由到對應的單元區域進行查詢。對應多活部署架構的中心化服務,同步各單元的單據資料時,單據的ID是全域性唯一,避免了匯聚資料時的ID衝突。
在公司的系統部署中,公共領域的 BPM 、待辦、行銷領域的系統都大範圍地實施多活部署。
1.1.3 鏈路跟蹤技術
在微服務架構流行的大背景下,此類微服務的應用對比單體應用的呼叫鏈路會更長、更復雜,對問題的排查帶來了挑戰,應對該場景的解決方案,會在流量入口處產生全域性唯一的TraceID,並在各微服務之間進行透傳,進行流量染色與關聯,後續通過該全域性唯一的TraceID,可快速地查詢與關聯全鏈路的呼叫關係與狀態,快速定位根因問題。
在公司的各式各樣的監控系統、灰度管理平臺、跨程序鏈路紀錄檔中,都會伴隨著這麼一個技術元件進行支撐服務。
1.2 分散式ID核心的難點
-
唯一性:保持生成的ID全域性唯一,在任何情況下也不會出現重複的值(如防止時間回拔,時鐘週期問題)。
-
高效能:ID的需求場景多,中心化生成元件後,需要高並行處理,以接近 0ms的響應大規模並行執行。
-
高可用:作為ID的生產源頭,需要100%可用,當接入的業務系統多的時候,很難調整出各方都可接受的停機發布視窗,只能接受無失真釋出。
-
易接入:作為邏輯上簡單的分散式ID要推廣使用,必須強調開箱即用,容易上手。
-
規律性:不同業務場景生成的ID有其特徵,例如有固定的前字尾,固定的位數,這些都需要設定化管理。
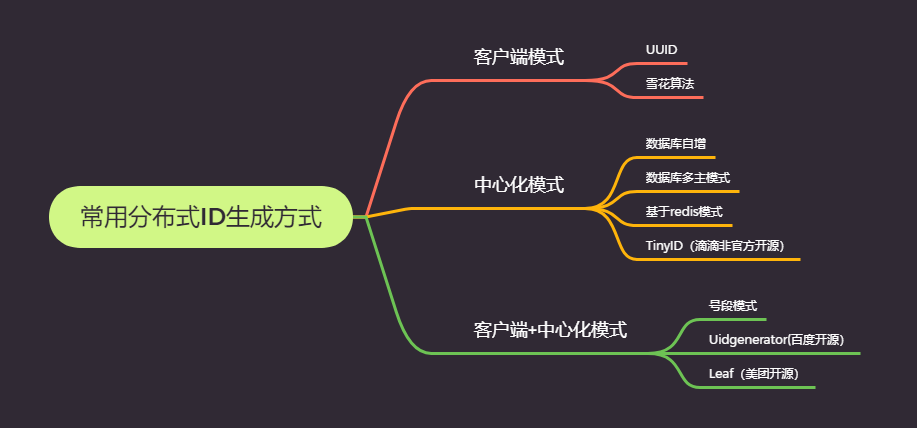
1.3 分散式ID常見的方案
常用系統設計中主要有下圖9種ID生成的方式:

1.4 分散式ID魯班的方案
我們的系統跨越了公共、生產製造、行銷、供應鏈、財經等多個領域。在分散式ID訴求下還有如下的特點:
-
在業務場景上除了常規的Long型別ID,也需要支援「String型別」、「MixId型別」(後詳述)等多種型別的ID生成,每一種型別也需要支援不同的長度的ID。
-
在ID的構成規則上需要涵蓋如操作型別、區域、代理等業務屬性的標識;需要集中式的設定管理。
-
在一些特定的業務上,基於安全的考慮,還需要在尾部加上亂數來保證ID不能被輕易猜測。
綜合參考了業界優秀的開源元件與常用方案均不能滿足,為了統一管理這類基礎技術元件的訴求,我們選擇基於公司業務場景自研一套分散式ID服務:魯班分散式ID服務。
二、系統架構
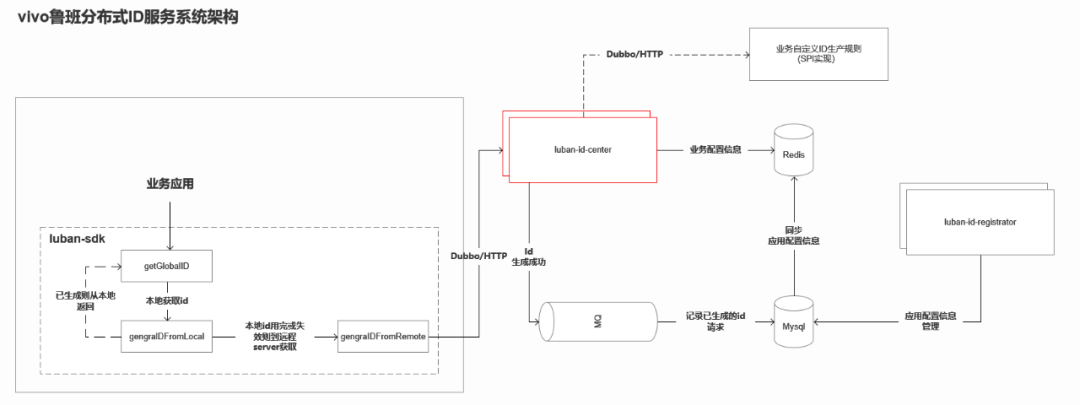
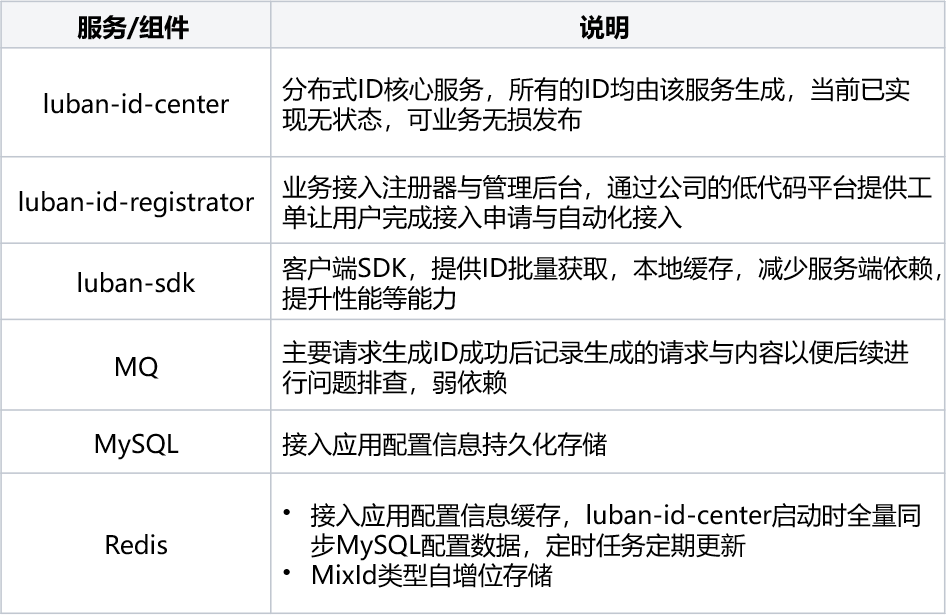
2.1 架構說明
三、 設計要點
3.1 支援多種型別的ID規則
目前魯班分散式ID服務共提供"Long型別"、「String型別」、「MixId型別」等三種主要型別的ID,相關ID構成規則與說明如下:
3.1.1 Long型別
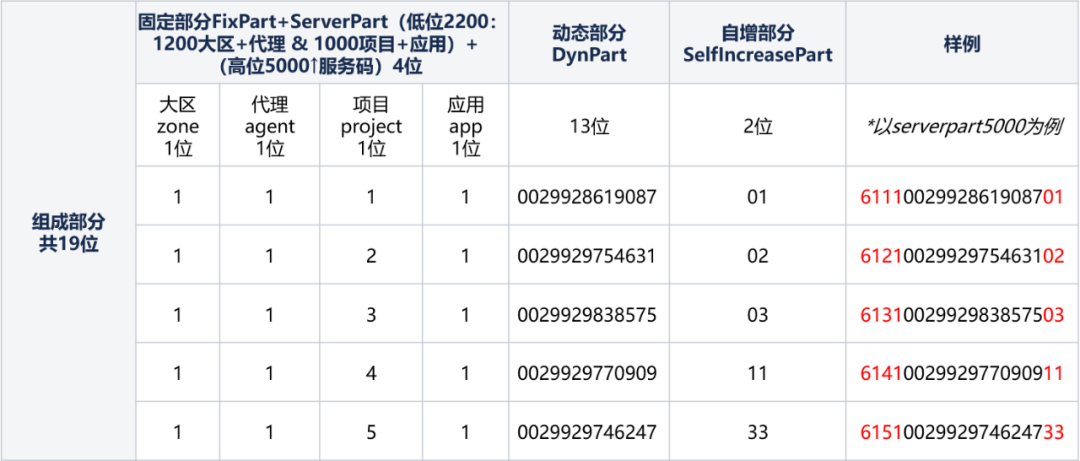
(1)構成規則
靜態結構由以下三部分資料組成,組成部分共19位:
-
固定部分(4位元):由FixPart+ServerPart組成。
① FixPart(4位元):由大區zone 1位/代理 agent 1位/專案 project 1位/應用 app 1位,組成的4位元數位編碼。
② ServerPart(4位元):用於定義產生全域性ID的伺服器標識位,服務節點部署時動態分配。
-
動態部分DynPart(13位):System.currentTimeMillis()-固定設定時間的TimeMillis (可滿足使用100年)。
-
自增部分SelfIncreasePart(2位):用於在全域性ID的使用者端SDK內部自增部分,由使用者端SDK控制,業務接入方無感知。共 2位組成。
(2)降級機制
主要自增部分在伺服器獲取初始值後,由使用者端SDK維護,直到自增99後再次存取伺服器端獲取下一輪新的ID以減少伺服器端互動頻率,提升效能,伺服器端獲取失敗後丟擲異常,接入業務側需介入進行處理。
(3)樣例說明
3.1.2 String型別
(1)構成規則
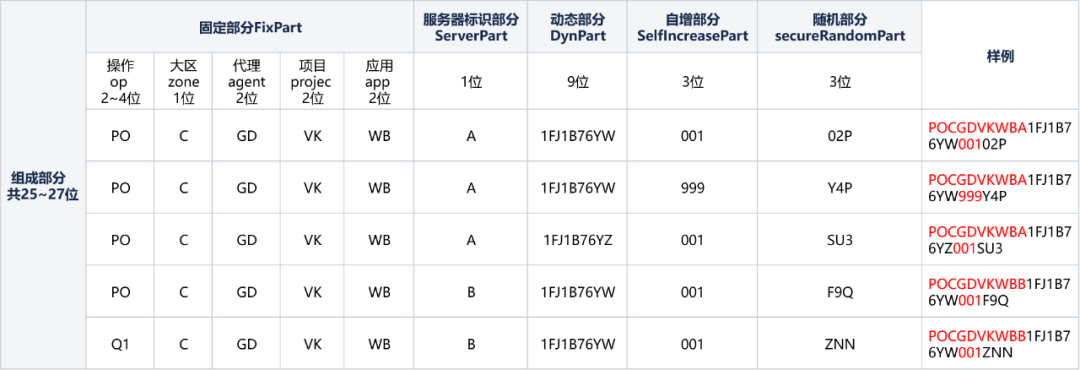
靜態結構由以下五部分資料組成,組成部分共25~27位:
-
固定部分操作位op+FixPart(9~11位):
① 操作位op(2~4位元):2~4位元由業務方傳入的業務型別標識字元。
② FixPart(7位):業務接入時申請獲取,由大區zone 1位,代理 agent 2位,專案 project 2位,應用 app 2位組成。
-
伺服器標識部分 ServerPart(1位): 用於定義產生全域性ID的伺服器標識位,服務節點部署時動態分配A~Z編碼。
-
動態部分DynPart(9位):System.currentTimeMillis()-固定設定時間的TimeMillis ,再轉換為32進位制字串(可滿足使用100年)。
-
自增部分SelfIncreasePart(3位):用於在全域性ID的使用者端SDK內部自增部分,由使用者端SDK控制,業務接入方無感知。
-
隨機部分secureRandomPart(3位):用於在全域性ID的使用者端SDK的隨機部分,由SecureRandom隨機生成3位0-9,A-Z字母數位組合的安全亂數,業務接入方無感知。
(2)降級機制
主要自增部分由使用者端SDK內部維護,一般情況下只使用001–999 共999個全域性ID。也就是每向伺服器請求一次,都在使用者端內可以自動維護999個唯一的全域性ID。特殊情況下在存取伺服器連線出問題的時候,可以使用帶字元的自增來做伺服器降級處理,使用產生00A, 00B... 0A0, 0A1,0A2....ZZZ. 共有36 * 36 * 36 - 1000 (999純數位,000不用)= 45656個降級使用的全域性ID。
(3)樣例說明
3.1.3 MixId型別
(1)構成規則
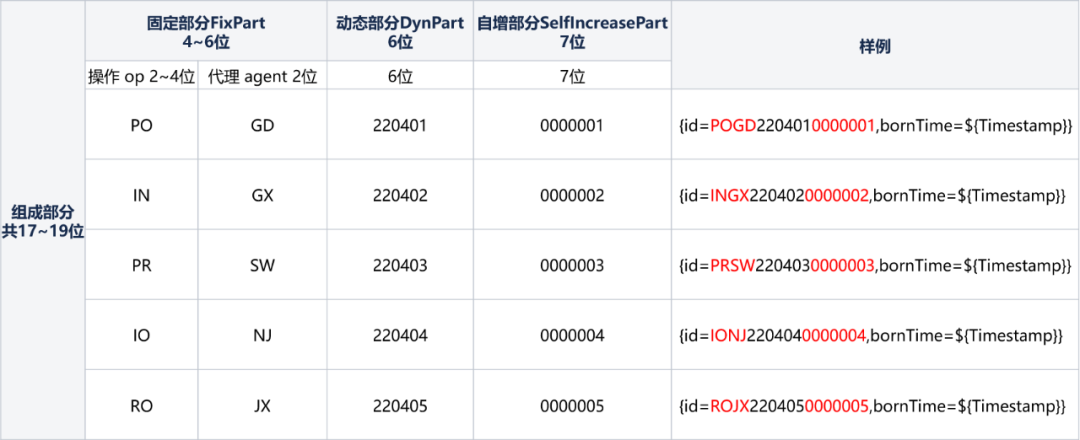
靜態結構由以下三部分資料組成,組成部分共17位:
-
固定部分FixPart(4~6位):
① 操作位op(2~4位元):2~4位元由業務方傳入的業務型別標識字元
② FixPart(2位):業務接入時申請獲取由代理 agent 2位組成。
-
動態部分DynPart(6位): 生成ID的時間,年(2位)月(2位)日(2位)。
-
自增部分SelfIncreasePart(7位):用於在全域性ID的使用者端SDK內部自增部分,由使用者端SDK控制,業務接入方無感知。
(2)降級機制
無,每次ID產生均需到伺服器端請求獲取,伺服器端獲取失敗後丟擲異常,接入業務側需介入進行處理。
(3)樣例說明
3.2 業務自定義ID規則實現
魯班分散式ID服務內建「Long型別」,「String型別」,「MixId型別」等三種長度與規則固定的ID生成演演算法,除以上三種型別的ID生成演演算法外,業務側往往有自定義ID長度與規則的場景訴求,在魯班分散式ID服務內建ID生成演演算法未能滿足業務場景時,為了能在該場景快速支援業務,魯班分散式ID服務提供了業務自定義介面並通過SPI機制在服務執行時動態載入,以實現業務自定義ID生成演演算法場景的支援,相關能力的實現設計與接入流程如下:
(1)ID的構成部分主要分FixPart、DynPart、SelfIncreasePart三個部分。
(2)魯班分散式ID服務的使用者端SDK提供 LuBanGlobalIDClient的介面與getGlobalId(...)/setFixPart(...)/setDynPart(...)/setSelfIncreasePart(...)等四個介面方法。
(3)業務側實現LuBanGlobalIDClient介面內的4個方法,通過SPI機制在業務側服務進行載入,並向外暴露出HTTP或DUBBO協定的介面。
(4)使用者在魯班分散式ID服務管理後臺對自定義ID生成演演算法的型別名稱與服務地址資訊進行設定,並關聯需要使用的AK接入資訊。
(5)業務側使用時呼叫使用者端SDK提供的LuBanGlobalIDClient的介面與getGlobalId方法,並傳入ID生成演演算法型別與IdRequest入參物件,魯班分散式ID服務接收請求後,動態識別與路由到對應ID生產演演算法的實現服務,並構建物件的ID返回給使用者端,完成整個ID生成與獲取的過程。
3.3 保證ID生成不重複方案

3.4 ID服務無狀態無失真管理
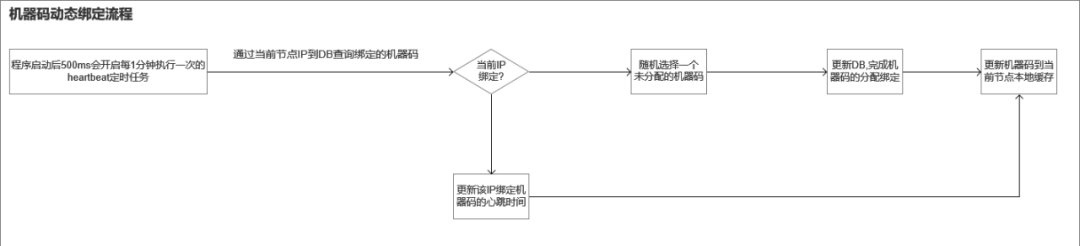
服務部署的環境在虛擬機器器上,ip是固定,常規的做法是在設定表裡設定ip與機器碼的繫結關係(這樣在服務擴縮容的時候就需要人為介入操作,存在一定的遺漏設定風險,也帶來了一定的運維成本),但在容器的部署場景,因為每次部署時IP均是動態變化的,以前通過設定表裡ip與機器碼的對映關係的設定實現方式顯然不能滿足執行在容器場景的訴求,故在伺服器端設計了通過心跳上報實現機器碼動態分配的機制,實現伺服器端節點ip與機器碼動態分配、繫結的能力,達成部署自動化與無失真釋出的目的。
相關流程如下:
【注意】
伺服器端節點可能因為異常,非正常地退出,對於該場景,這裡就需要有一個解綁的過程,當前實現是通過公司平臺團隊的分散式定時任務服務,檢查持續5分鐘(可設定)沒有上報心跳的機器碼分配節點進行資料庫繫結資訊清理的邏輯,重置相關機器碼的位置供後續註冊繫結使用。
3.5 ID使用方接入SDK設計
SDK設計主要以"接入快捷,使用簡單"的原則進行設計。
(1)接入時:
魯班分散式ID服務提供了spring-starter包,應用只需再pom檔案依賴該starter,在啟動類裡新增@EnableGlobalClient,並設定AK/SK等租戶引數即可完成接入。
同時魯班分散式ID服務提供Dubbo & Http的呼叫方式,通過在啟動註解設定accessType為HTTP/DUBBO來確定,SDK自動載入相關依賴。
(2)使用時:
根據"Long"、"String"、"MixId"等三種id型別分別提供GlobalIdLongClient、GlobalIdStringClient、GlobalIdMixIDClient等三個使用者端物件,並封裝了統一的入參RequestDTO物件,業務系統使用時只需構建對應Id型別的RequestDTO物件(支援鏈式構建),並呼叫對應id型別的使用者端物件getGlobalID(GlobalBaseRequestDTO globalBaseRequestDTO)方法,即可完成ID的構建。
Long型別Id獲取程式碼範例:
package com.vivo.it.demo.controller;
import com.vivo.it.platform.luban.id.client.GlobalIdLongClient;
import com.vivo.it.platform.luban.id.dto.GlobalLongIDRequestDTO;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.web.bind.annotation.RequestMapping;
@RequestMapping("/globalId")
public class GlobalIdDemoController {
@Autowired
private GlobalIdLongClient globalIdLongClient;
@RequestMapping("/getLongId")
public String getLongId() {
GlobalLongIDRequestDTO globalLongIDRequestDTO = GlobalLongIDRequestDTO.Builder()
.setAgent("1") //代理,接入申請時確定
.setZone("0") //大區,接入申請時確定
.setApp("8") //應用,接入申請時確定
.setProject("7") //專案,接入申請時確定
.setIdNumber(2); //當次返回的id數量,只對getGlobalIDQueue有效,對getGlobalID(...)無效
long longId = globalIdLongClient.getGlobalID(globalLongIDRequestDTO);
return String.valueOf(longId);
}
}3.6 關鍵執行效能優化場景
3.6.1 記憶體使用優化
在專案上線初時,經常發生FGC,導致服務停頓,獲取ID超時,經過分析,魯班分散式ID服務的伺服器端主要為記憶體敏感的應用,當高並行請求時,過多物件進入老年代從而觸發FGC,經過排查主要是JVM記憶體引數上線時是使用預設的,沒有經過優化設定,JVM初始化的記憶體較少,高並行請求時JVM頻繁觸發記憶體重分配,相關的物件也流程老年代導致最終頻繁傳送FGC。
對於這個場景的優化思路主要是要相關記憶體物件在年輕代時就快速經過YGC回收,儘量少的物件進行老年代而引起FGC。
基於以上的思路主要做了以下的優化:
-
增大JVM初始化記憶體(-Xms,容器場景裡為-XX:InitialRAMPercentage)
-
增大年輕代記憶體(-Xmn)
-
優化程式碼,減少程式碼裡臨時物件的複製與建立
3.6.2 鎖顆粒度優化
使用者端SDK再自增值使用完或一定時間後會向伺服器端請求新的id生成,這個時候需要保證該次請求在多執行緒並行時是隻請求一次,當前設計是基於使用者申請ID的接入設定,組成為key,去獲取對應key的物件鎖,以減少同步程式碼塊鎖的粒度,避免不同接入設定去在並行去遠端獲取新的id時,鎖粒度過大,造成執行緒的阻塞,從而提升在高並行場景下的效能。
四、 業務應用
當前魯班分散式ID服務日均ID生成量億級,平均RT在0~1ms內,單節點可支援 萬級QPS,已全面應用在公司IT內部行銷訂單、支付單據、庫存單據、履約單據、資產管理編碼等多個領域的業務場景。
五、未來規劃
在可用性方面,當前魯班分散式ID服務仍對Redis、Mysql等外部DB元件有一定的依賴(如應用接入設定資訊、MixId型別自增部分ID計數器),規劃在該依賴極端宕機的場景下,魯班分散式ID服務仍能有一些降級策略,為業務提供可用的服務。
同時基於業務場景的訴求,支援標準形式的雪花演演算法等ID型別。
六、 回顧總結
本文通過對分散式ID的3種應用場景,實現難點以及9種分散式ID的實現方式進行介紹,並對結合vivo業務場景特性下自研的魯班分散式id服務從系統架構,ID生成規則與部分實現原始碼進行介紹,希望對本文的閱讀者在分散式ID的方案選型或自研提供參考。