FTL沒有對映管理,跟上班沒有錢有什麼區別
大家好,我是五月。
前言
FTL(Flash Translation Layer),即快閃記憶體轉換層,是各種儲存裝置的核心演演算法,作用是將Host傳下來的邏輯地址轉換成實體地址,也就是對映。
可以說,地址對映是FTL最原始最基本的功能。

為什麼需要對映
NAND Flash最大的問題就是不能像記憶體一樣隨意寫入。
根據Flash的特效能知道,寫入page之前需要先將所在的Block擦除。
按照這種準則,市面上出現的Flash根本不能使用,其一,效能會很差,瓶頸限制在塊擦除上,其二,持續不斷對同一Block擦除,會導致Block在短時間內磨損,很容易造成儲存資料丟失。
對映的觀念出來後,資料不會直愣愣的寫入原來的page頁/Block塊,而是重新對映到新的page頁/Block塊中,按照這個思路引導,Flash中所有的儲存空間都可以按照這種page/Block對映方式進行管理。
使用者肉眼看到的,是連續的邏輯地址組成的空間,實際在Flash當中,一段資料的儲存很有可能是不連續的。
對映種類
首先要知道,對映種類有仨:
1. 塊對映
2. 頁對映
3. 混合對映(塊對映+頁對映)
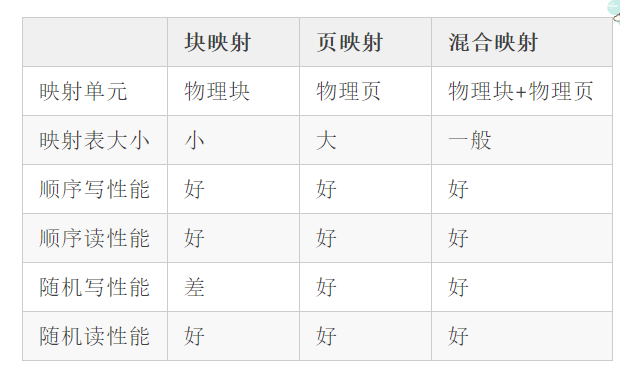
塊對映
以Block為對映單位,一個邏輯塊可以對映到任何的物理塊上,所以塊內每一頁的偏移不變。
還需要對映表來記錄邏輯塊和物理塊之間的對映關係。
優點:因為對映表只需要塊的對映,所以對映表所佔空間小。
缺點:效能差。如果使用者要操作一個邏輯頁的話,就需要把整個塊的資料讀取出來,再修改邏輯頁,再寫入flash當中,所以小尺寸資料寫效能極差。
頁對映
以page為對映粒度,一個邏輯頁可以對映到任何的物理頁上,所以塊內每一頁的偏移變化多端。
需要對映表來記錄每一邏輯頁與物理頁之間的對映關係。
優點:使用者可隨時操作某一邏輯頁,直接將資料寫進對應物理頁,方便快捷,效能極好。
缺點:由於每一邏輯頁與物理頁都有一張對映表,並且頁的數量遠遠要比塊的數量多得多,所以對映表所佔空間極大。
用個例子就很好理解了:
假設有個256G的Flash,page大小為4KB,那麼一共就有64M(256G/4KB)個page,也就是說需要64M個對映表,假設每個對映表佔用4個位元組,那麼整個對映表大小就為64M*4 = 256M。
一般來說,整個對映表的大小不宜超過Flash容量的千分之一。
混合對映
混合對映是塊對映和頁對映的混合產物,外面經常說的Hybird level mapping就是說的它。
一個邏輯塊可以對映到任何的物理塊上,塊內採用頁對映方式,塊內邏輯頁可以對映到對應物理塊內任何物理頁上。
市面上大部分用的對映方式都是Hybird對映方式。
HyBird的對映操分為兩級:
第一級是data_log,資料以page的維度寫入log,這個log一般是SLC;
第一級是data_Block,當data_log寫滿後,資料會合併到data_Block中。
data_log由於數量有限,可以採用頁對映的方式寫入資料,data_Block容量比較大,所以採用塊對映的方式寫入。
所以在效能和所佔空間都介於塊對映和頁對映之間。
以下是不同對映之間的比較:
對映原理
Host是通過傳送邏輯地址 LBA 來存取Flash的,每一個LBA大小為 1Sec。
每一個Sec大小各有不同,有512B、4KB、8KB,業內常稱為一包資料,大部分情況下都是512B。
因為PC端操作磁碟的方式,都是以Sec的方式傳送命令的,操作其他儲存裝置比如U盤,SD卡也是一樣,不會改變。
寫過程
Flash是以page為單位進行寫的,所以Host傳送的 LAB+資料並不會立馬就寫進入,而是會先在Dbuf快取起來,直到湊成了1page的資料量,才會寫進Flash中。
使用者每寫入1page資料,FTL會先去找對映,看看LBA有沒有對應的對映關係,如果沒有找到,就會找一個物理頁吧使用者資料寫入,同時新建一條對映。
那麼,使用者邏輯地址和實體地址的一條對映就生成了。
每寫入一個邏輯頁,就會有一條對映表產生或者更新。
讀過程
使用者讀取某一個區域,傳送LBA進行存取時,FTL就會先在對映表池裡找呀找,找到與LBA對應的對映表,FTL就知道要在Flash的哪個物理頁把資料讀出來了。
如果讀過程沒有找到對映表,那麼讀取過程失敗。
對映表位置
DRAM
大多數儲存裝置都有板載DRAM,對映表就能儲存在DRAM上
作用:可以快速存取對映表,快速讀寫
缺點:隨著對映表越來越多,所佔DRAM就會越來越大,提高了成本和功耗。

Flash
後來的主流是對映表大部分被存在於Flash中,當下要用的小部分對映表存於DRAM中。
作用:降低成本和功耗,還可以避免掉電帶來的對映資訊損失,另外Flash空間很大,對映表想放多少放多少。
Host傳送LBA的時候,FTL會先在DRAM中尋找,如果沒有找到對應的對映表,就會去Flash中讀取對映表,再根據對映關係操作對應的物理頁。
缺點:需要讀取兩次Flash,一次對映表,一次使用者資料,底層頻寬減小了,對於隨機操作來說,就顯得效率低了一點。

對映表更新
隨著對映表的增加、刪除、覆蓋,到了某個時刻就要把對映表寫進Flash儲存起來,避免掉電時發生大量對映表丟失。
時不時將對映表寫進Flash,就算髮生了突然的異常掉電,丟失的也只是小部分映關係,後面還能通過重建對映表恢復回來。
對映表的寫入時刻
1. 新生的對映表數量積累到一定的閾值
2. 使用者寫入的資料量積累到一定的閾值
3. 空閒快閃記憶體塊的剩餘數量達到一定的閾值
寫入策略
1. 全部更新
將所有的對映表,無論是新產生的還是原先就有的,全部一股腦寫入Flash中。
優點:韌體實現簡單,不用去考慮哪些對映表是新的,哪些是原本就有的。
缺點:寫入資料量多,影響效能和延時,還會增加寫入放大。
2. 增量更新
只把新產生的對映表寫入Flash中。
優點:新增寫入的資料量少,效能好,時效高。
缺點:韌體實現複雜,還得區分那麼那麼些是新增的對映表,哪些是被覆蓋的。
選擇哪種寫入決策,應根據硬體架構,結合實際情況考慮。
好了,這次先寫到這兒,祝各位生活愉快。
