圖書搜尋領域重大突破!用Apache SeaTunnel、Milvus和OpenAI提高書名相似度搜尋精準度和效率

作者 | 劉廣東,Apache SeaTunnel Committer
背景
目前,現有的圖書搜尋解決方案(例如公共圖書館使用的解決方案)十分依賴於關鍵詞匹配,而不是對書名實際內容的語意理解。因此會導致搜尋結果並不能很好地滿足我們的需求,甚至與我們期待的結果大相徑庭。這是因為僅僅依靠關鍵詞匹配是不夠的,因為它無法實現語意理解,也就無法理解搜尋者真正的意圖。
那麼,有更好的方法可以讓我們更加準確、高效地進行圖書搜尋嗎?答案是有!本文中,我將介紹如何結合使用Apache SeaTunnel、Milvus和OpenAI進行相似度搜尋,實現對整個書名的語意理解,從而讓搜尋結果更加精準。
使用訓練有素的模型來表示輸入資料被稱為語意搜尋,這種方法可以擴充套件到各種不同的基於文字的用例,包括異常檢測和檔案搜尋。因此,本文所介紹的技術可以為圖書搜尋領域帶來重大的突破和影響。
接下來我來簡單介紹幾個與本文相關的概念和用到的工具/平臺,便於大家更好地理解本文。
什麼是Apache SeaTunnel
Apache SeaTunnel是一個開源的、高效能的、分散式的資料管理和計算平臺。它是由Apache基金會支援的一個頂級專案,能夠處理海量資料、提供實時的資料查詢和計算,並支援多種資料來源和格式。SeaTunnel的目標是提供一個可延伸的、面向企業的資料管理和整合平臺,以滿足各種大規模資料處理需求。
什麼是Milvus
Milvus是一個開源的類似向量搜尋引擎,它支援海量向量的儲存、檢索和相似度搜尋,是一個針對大規模向量資料的高效能、低成本的解決方案。Milvus可以在多種場景下使用,如推薦系統、影象搜尋、音樂推薦和自然語言處理等。
什麼是OpenAI
ChatGPT是一種基於GPT(Generative Pre-trained Transformer)模型的對話生成系統,是由OpenAI開發的。該系統主要使用了自然語言處理、深度學習等技術,可以生成與人類對話相似的自然語言文字。ChatGPT的應用範圍很廣,可以用於開發智慧客服、聊天機器人、智慧助手等應用程式,也可以用於語言模型的研究和開發。近年來,ChatGPT已經成為了自然語言處理領域的研究熱點之一。
什麼是LLM(Large Language Model)
大語言模型(Large Language Model)是一種基於深度學習技術的自然語言處理模型,它可以對一段給定的文字進行分析和理解,並生成與之相關的文字內容。大語言模型通常使用深度神經網路來學習自然語言的語法和語意規則,並將文字資料轉換為連續向量空間中的向量表示。在訓練過程中,大語言模型利用大量的文字資料來學習語言模式和統計規律,從而可以生成高質量的文字內容,如文章、新聞、對話等。大語言模型的應用領域非常廣泛,包括機器翻譯、文字生成、問答系統、語音識別等。目前,許多開放原始碼深度學習框架都提供了大語言模型的實現,如TensorFlow、PyTorch等。
教學
重點來了!我將展示如何將Apache SeaTunnel、OpenAI的Embedding API與我們的向量資料庫結合使用,來通過語意搜尋整個書名。
準備步驟
在實驗之前,我們需要去官網獲取一個OpenAI的token,然後在去部署一個Milvus的實驗環境。我們還需要準備好將用於這個例子的資料。你可以從這裡下載資料。
通過SeaTunnel將資料匯入Milvus
首先,將book.csv放到/tmp/milvus_test/book下,然後設定任務設定為milvus.conf並放到config下。請參考快速使用指南。
env {
# You can set engine configuration here
execution.parallelism = 1
job.mode = "BATCH"
checkpoint.interval = 5000
#execution.checkpoint.data-uri = "hdfs://localhost:9000/checkpoint"
}
source {
# This is a example source plugin **only for test and demonstrate the feature source plugin**
LocalFile {
schema {
fields {
bookID = string
title_1 = string
title_2 = string
}
}
path = "/tmp/milvus_test/book"
file_format_type = "csv"
}
}
transform {
}
sink {
Milvus {
milvus_host = localhost
milvus_port = 19530
username = root
password = Milvus
collection_name = title_db
openai_engine = text-embedding-ada-002
openai_api_key = sk-xxxx
embeddings_fields = title_2
}
}
執行如下命令:
./bin/SeaTunnel.sh --config ./config/milvus.conf -e local
檢視資料庫中資料,可以看到已經有資料寫入進去。
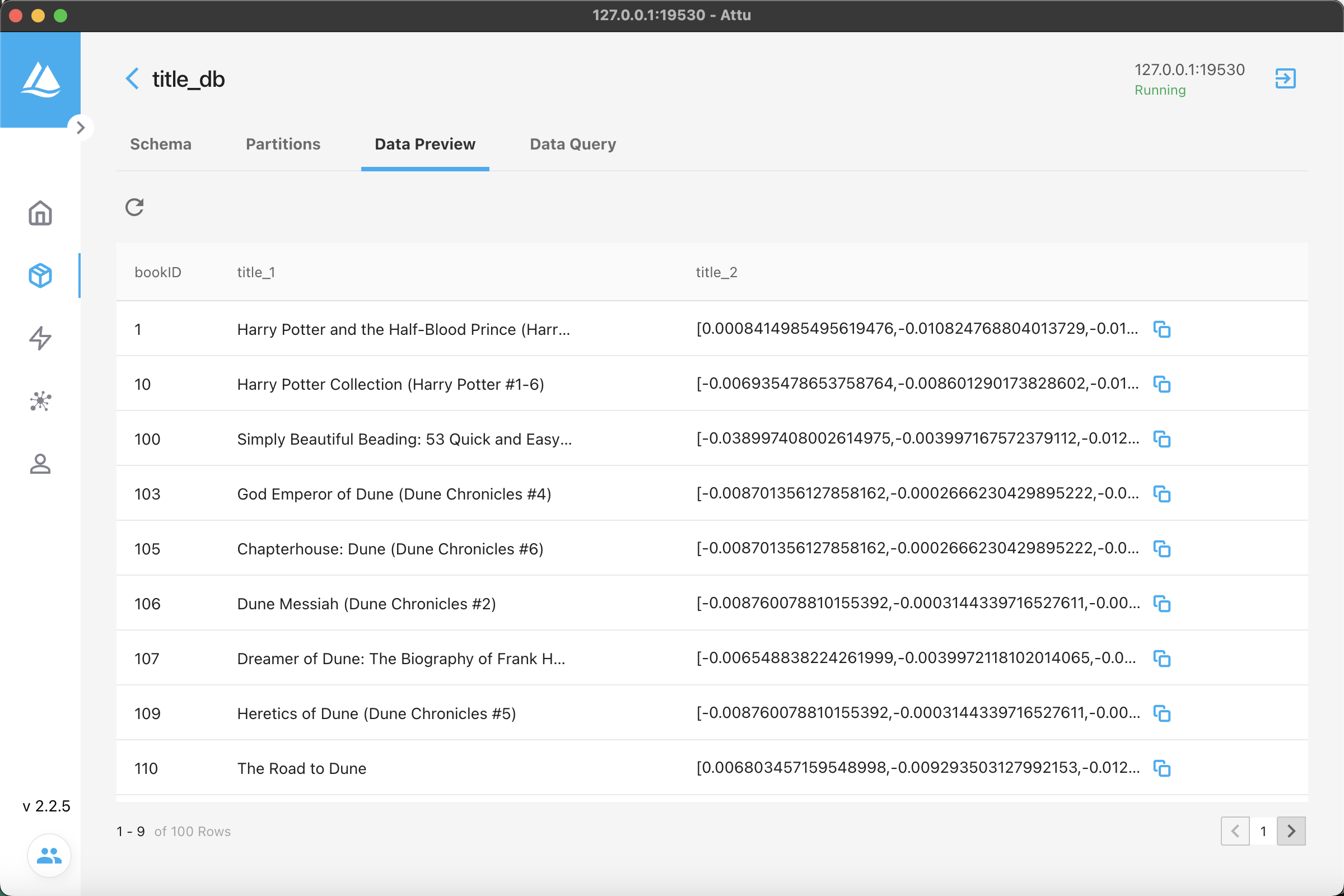
然後使用如下程式碼通過語意搜尋書名:
import json
import random
import openai
import time
from pymilvus import connections, FieldSchema, CollectionSchema, DataType, Collection, utility
COLLECTION_NAME = 'title_db' # Collection name
DIMENSION = 1536 # Embeddings size
COUNT = 100 # How many titles to embed and insert.
MILVUS_HOST = 'localhost' # Milvus server URI
MILVUS_PORT = '19530'
OPENAI_ENGINE = 'text-embedding-ada-002' # Which engine to use
openai.api_key = 'sk-******' # Use your own Open AI API Key here
connections.connect(host=MILVUS_HOST, port=MILVUS_PORT)
collection = Collection(name=COLLECTION_NAME)
collection.load()
def embed(text):
return openai.Embedding.create(
input=text,
engine=OPENAI_ENGINE)["data"][0]["embedding"]
def search(text):
# Search parameters for the index
search_params={
"metric_type": "L2"
}
results=collection.search(
data=[embed(text)], # Embeded search value
anns_field="title_2", # Search across embeddings
param=search_params,
limit=5, # Limit to five results per search
output_fields=['title_1'] # Include title field in result
)
ret=[]
for hit in results[0]:
row=[]
row.extend([hit.id, hit.score, hit.entity.get('title_1')]) # Get the id, distance, and title for the results
ret.append(row)
return ret
search_terms=['self-improvement', 'landscape']
for x in search_terms:
print('Search term:', x)
for result in search(x):
print(result)
print()
搜尋結果如下:
Search term: self-improvement
[96, 0.4079835116863251, "The Dance of Intimacy: A Woman's Guide to Courageous Acts of Change in Key Relationships"]
[56, 0.41880303621292114, 'Nicomachean Ethics']
[76, 0.4309804439544678, 'Possession']
[19, 0.43588975071907043, 'Vanity Fair']
[7, 0.4423919916152954, 'Knowledge Is Power (The Amazing Days of Abby Hayes: #15)']
Search term: landscape
[9, 0.3023473024368286, 'The Lay of the Land']
[1, 0.3906732499599457, 'The Angry Hills']
[78, 0.392495334148407, 'Cloud Atlas']
[95, 0.39346450567245483, 'Alien']
[94, 0.399422287940979, 'The Known World']
如果我們按照之前的老方法——關鍵詞搜尋,書名中必須包含自我提升、提升等關鍵詞;但是提供大模型進行語意級別的理解,則可以檢索到更加符合我們需求的書名。比如在上面的例子中,我們搜尋的關鍵詞為self-improvement(自我提升),展示的書名《關係之舞:既親密又獨立的相處藝術》、《尼各馬可倫理學》等雖然不包含相關關鍵詞,卻很明顯更加符合我們的要求。
可見,我們利用Apache SeaTunnel、Milvus和OpenAI,通過大語言模型的方法,可以實現更加精準的書名相似度搜素,為圖書搜尋領域帶來重大的技術突破,同時對於語意理解也提供了有價值的參考,希望可以給大家帶來一些啟發。
相關連結
本文由 白鯨開源 提供釋出支援!