自然語言處理 Paddle NLP
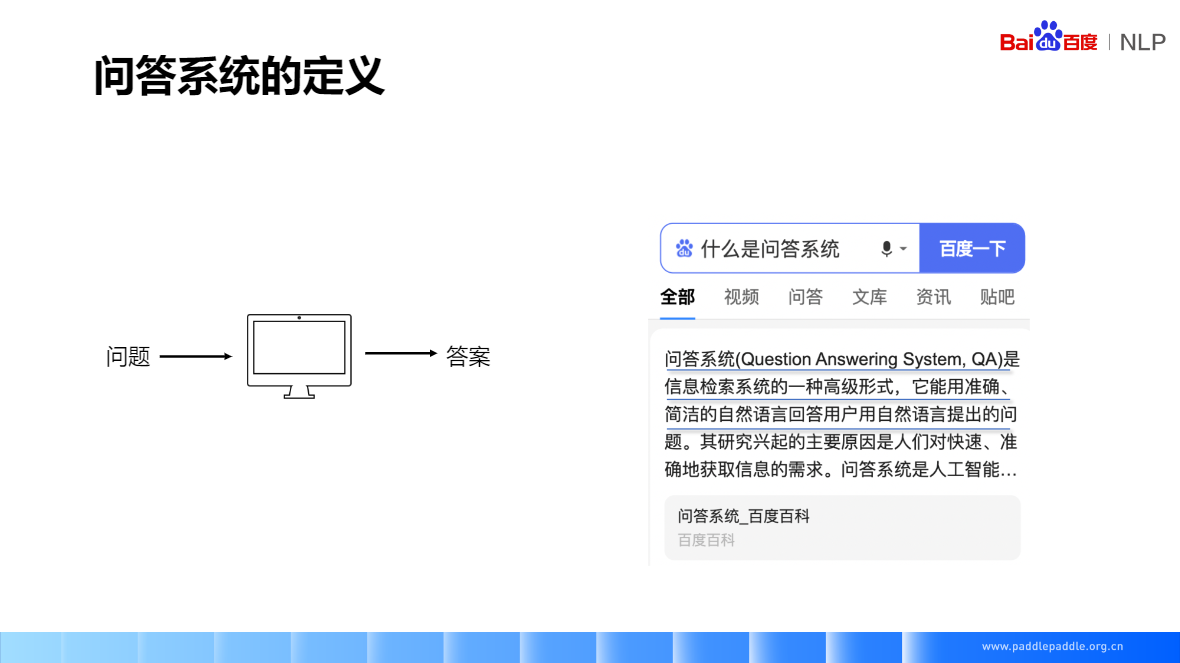
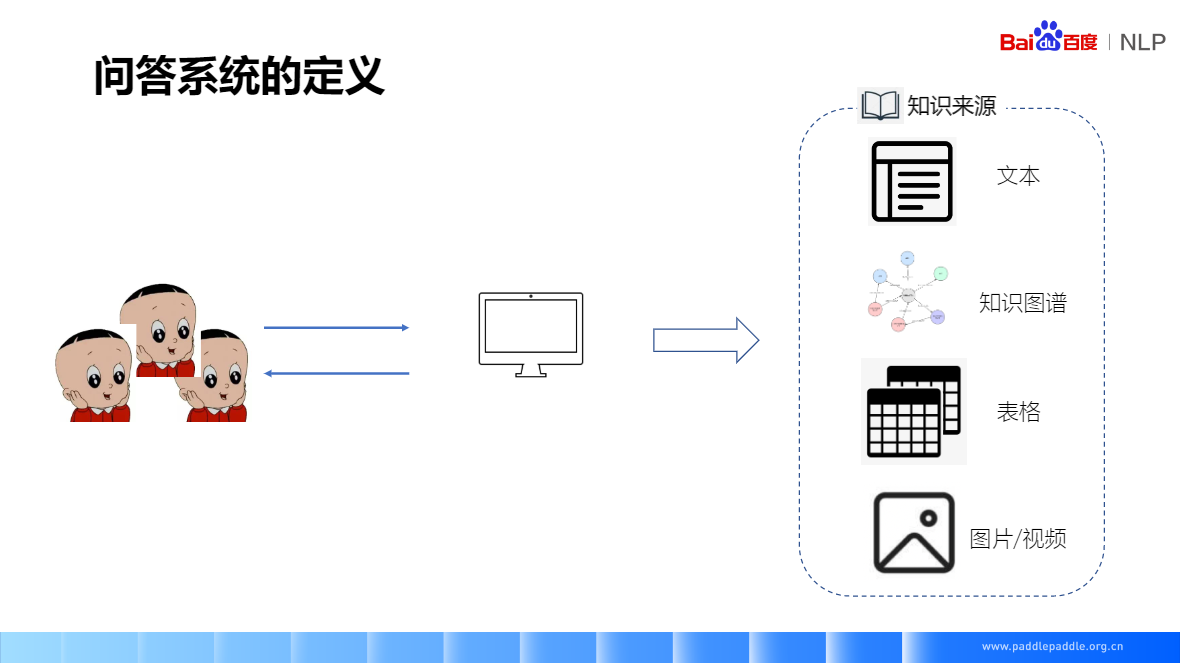
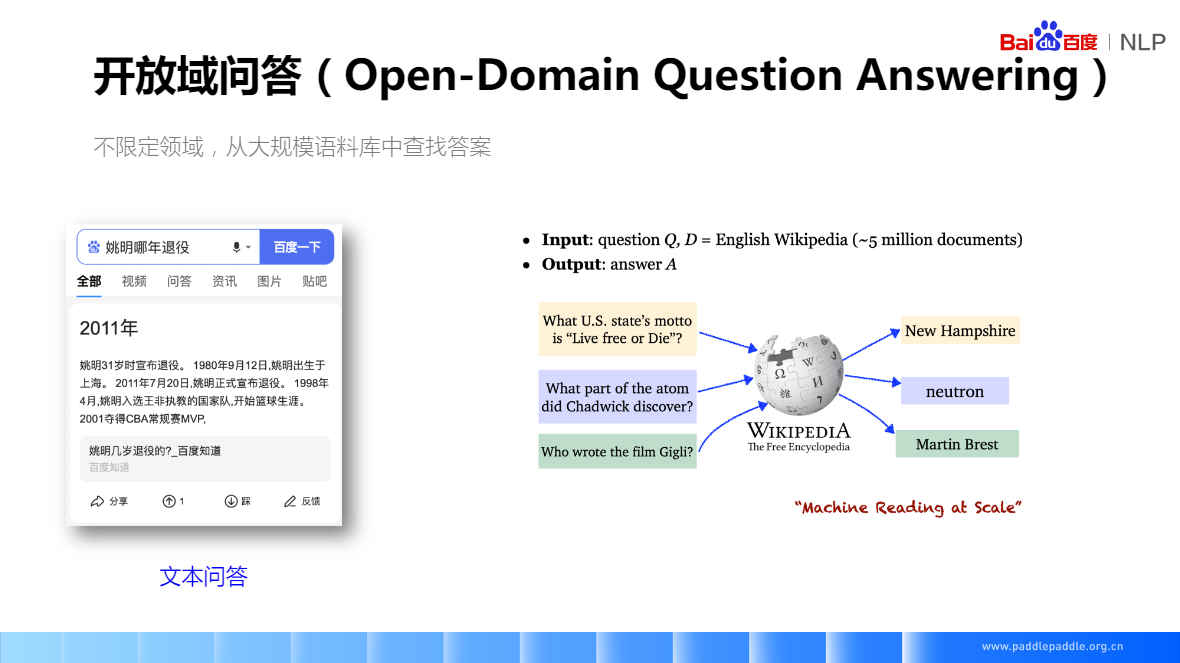
問答系統(Question Answering System,QA) 是資訊檢索系統的一種高階形式,它能用準確、簡潔的自然語言回答使用者用自然語言提出的問題。其研究興起的主要原因是人們對快速、準確地獲取資訊的需求。問答系統是人工智慧.
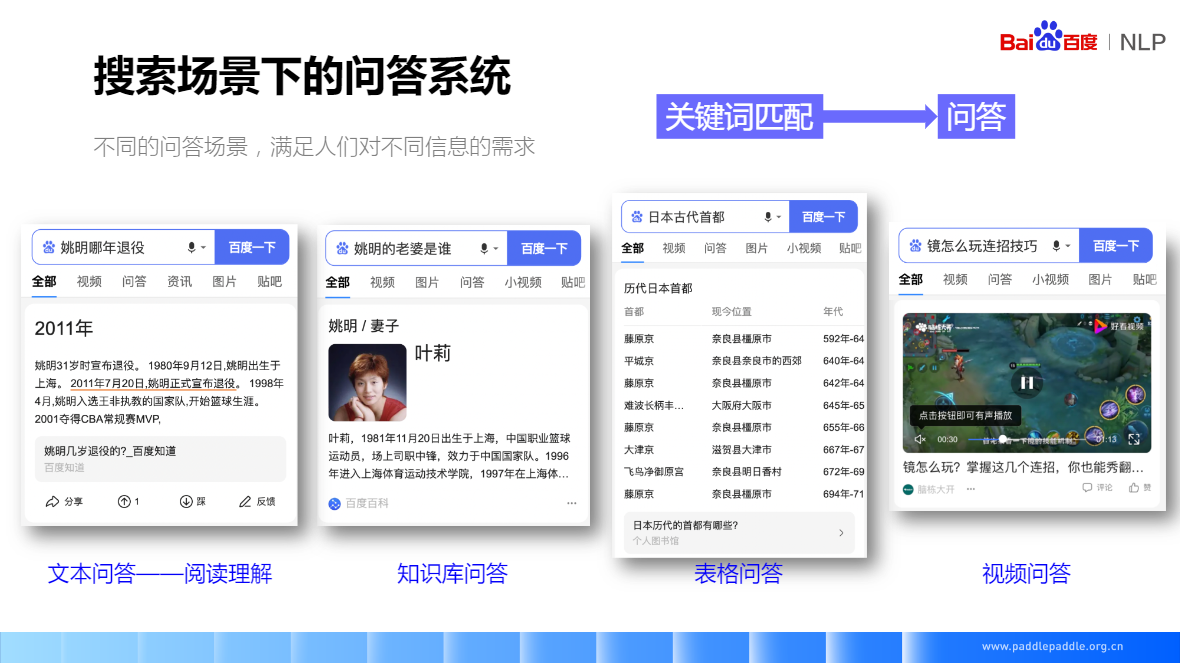
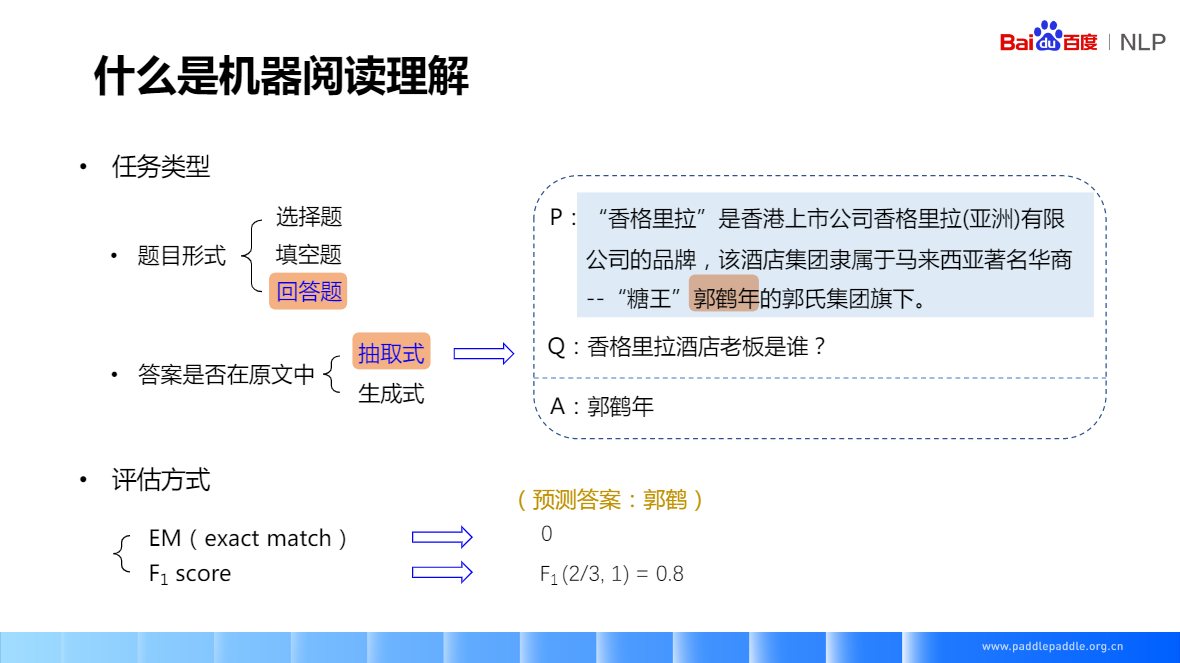
抽取式閱讀理解:它的答案一定是段落裡的一個片段,所以在訓練前,先要找到答案的起始位置和結束位置,模型只需要預測這兩個位置,有點像序列標註的任務,對一段話裡的每個字,都會預測兩個值,預測是開始位置還是結尾位置的概率,相當於對每個字來講,都是一個二分類的任務


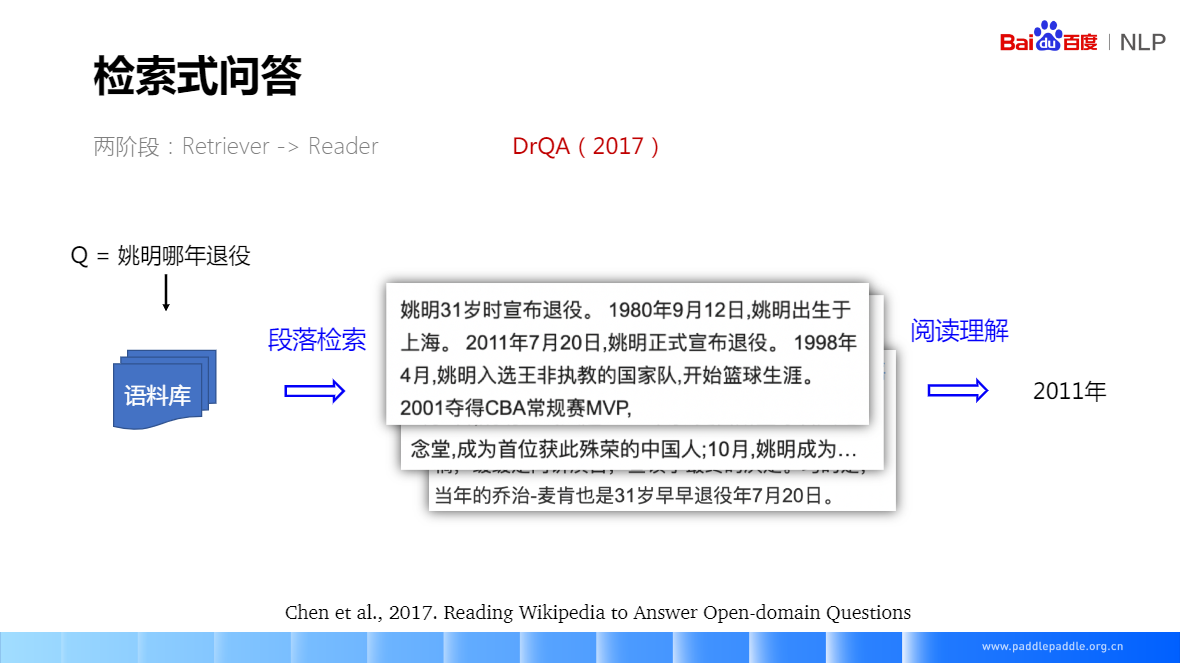
機器閱讀技術:2011年7月20日,姚明正式宣佈退役 => 姚明哪一年退役
500萬的維基百科檔案
檢索式問答:先做段落檢索、再做答案抽取

閱讀理解:

郭鶴年 => 郭鶴,3個字裡面對了2個 => 2/3, 完全匹配 => 1,f1(2/3,1) => 0.8
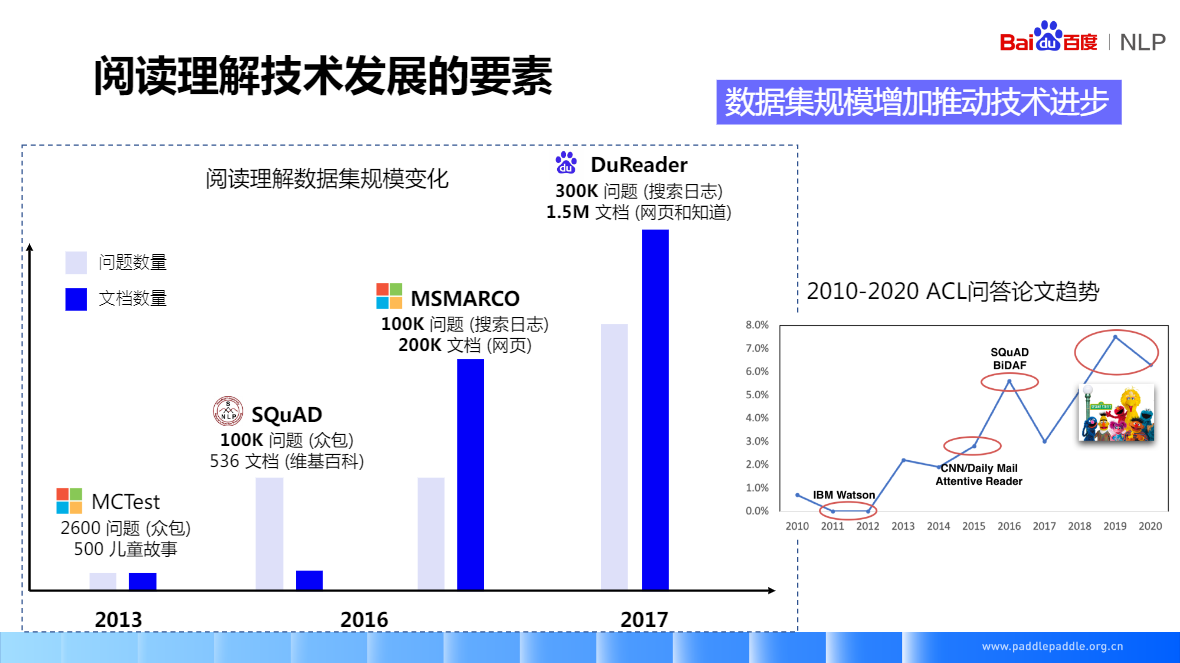
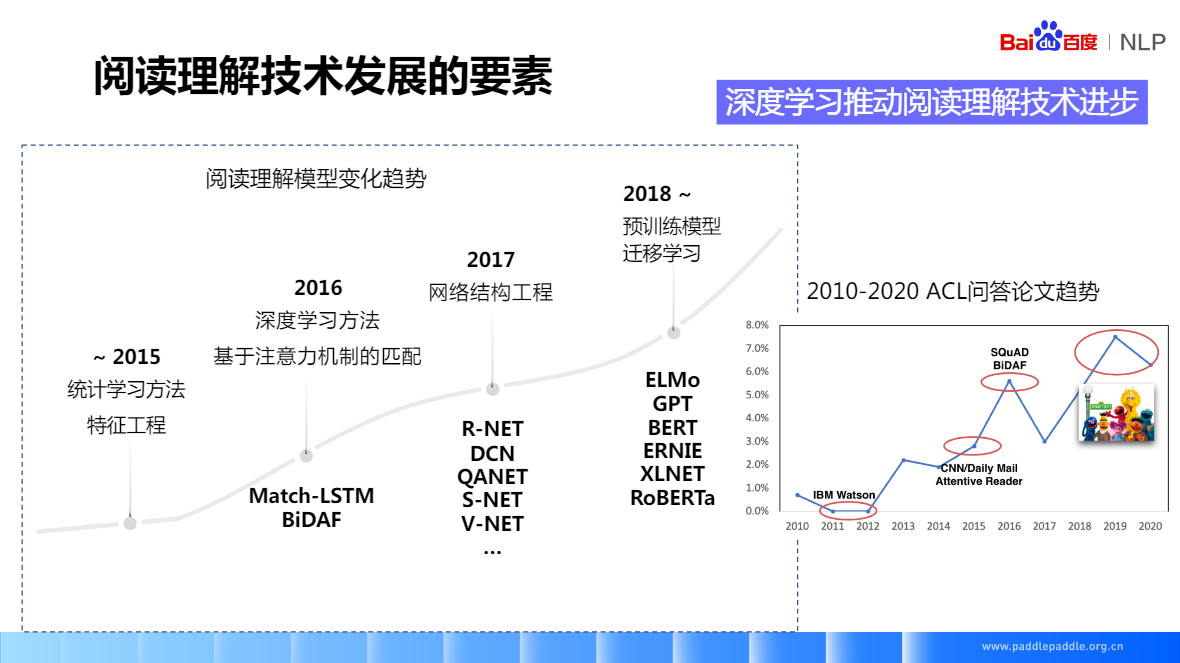
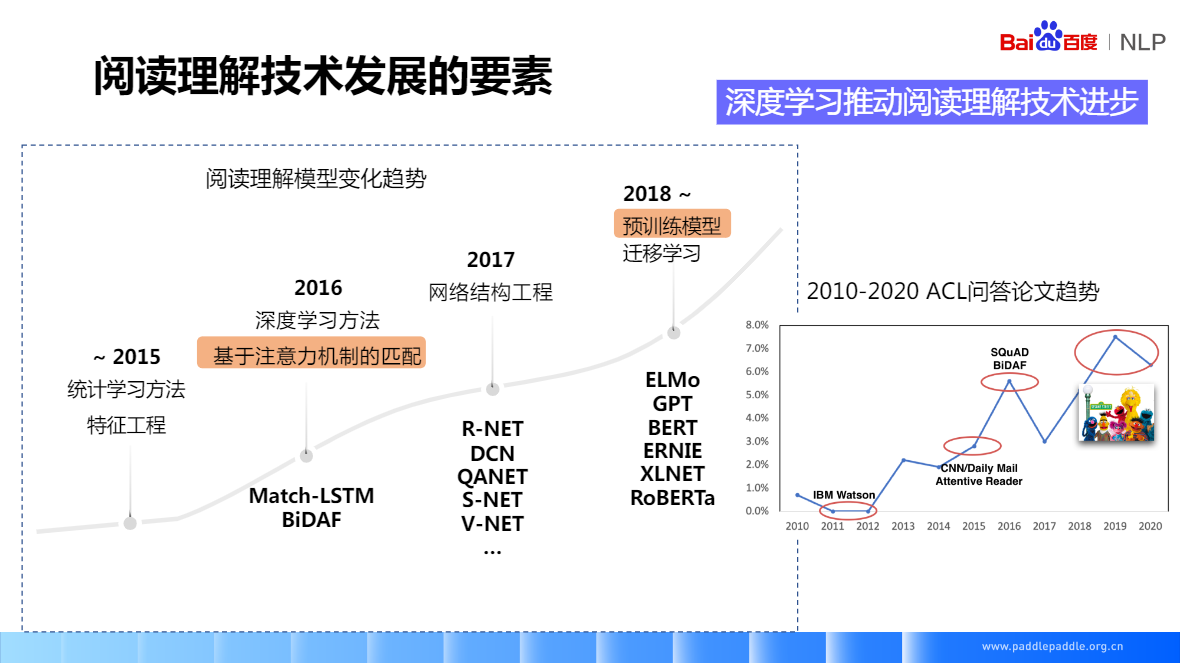
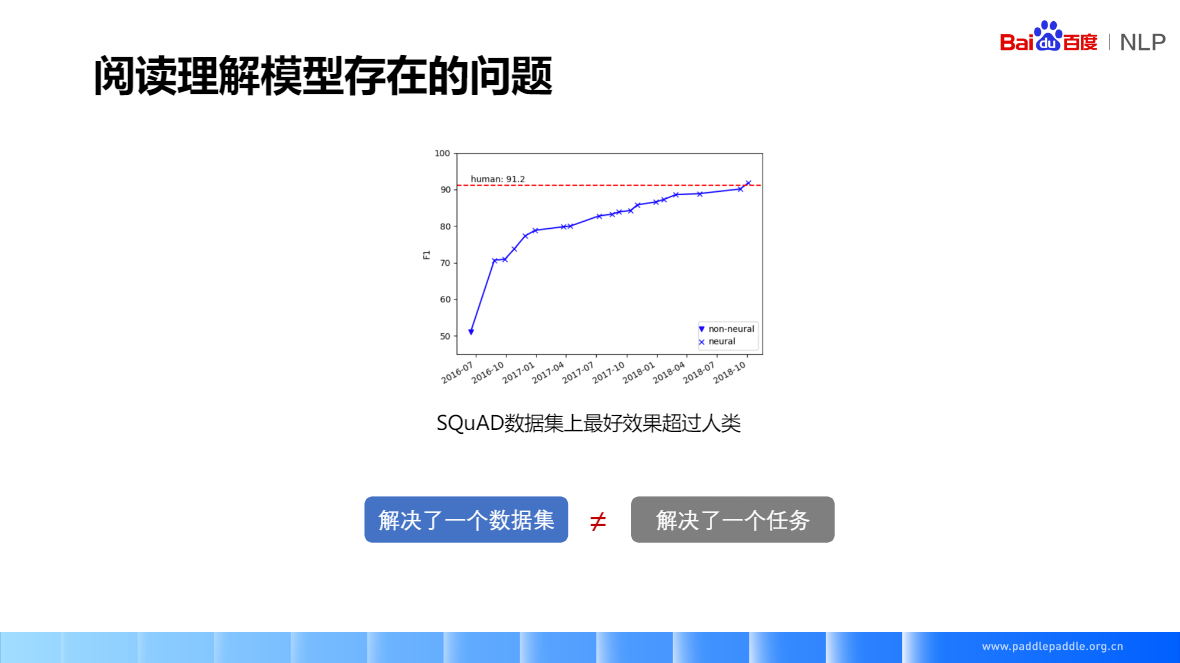
SQuAD(2016) 只能做抽取,資料量是訓練深度神經網路的關鍵要素,資料集有著很大的影響力很多精典的閱讀理解模型,也是基於SQuAD做的

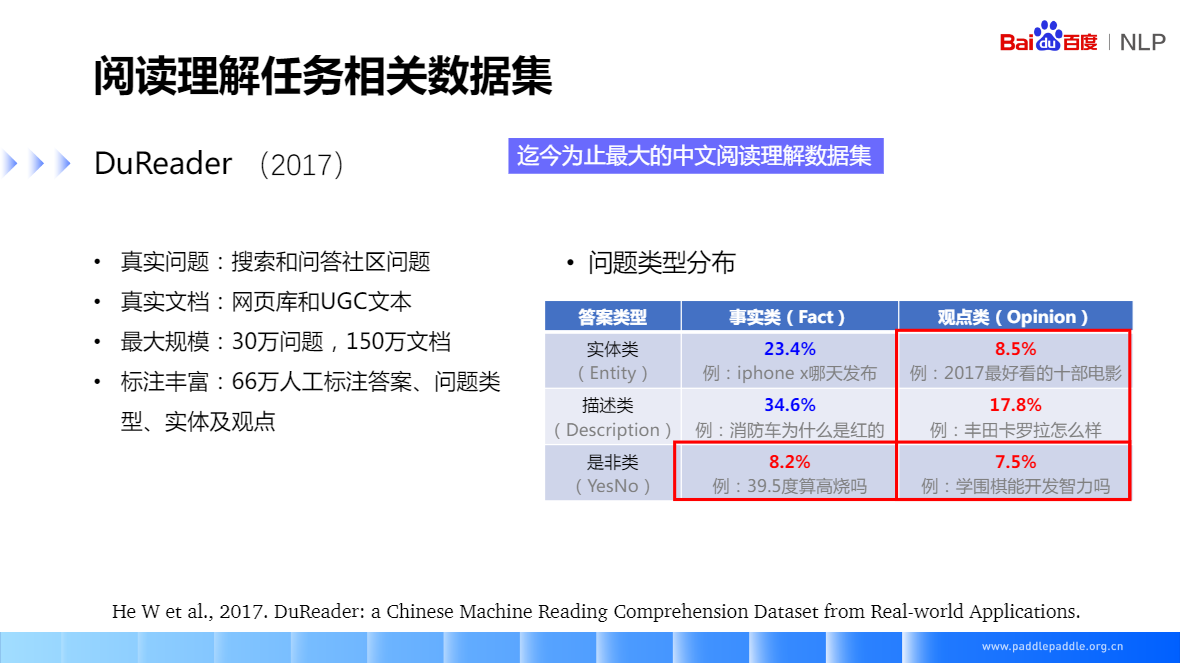
DuReader(2017) 百度2017年釋出的,迄今為止最大的中文閱讀理解資料集,相比較 SQuAD,除了實體類、描述類和事實類的問題,還包含了是非類和觀點類的問題
抽取式閱讀理解,它的答案一定是段落裡的一個片段,所以在訓練前,先要找到答案的起始位置和結束位置,模型只需要預測這兩個位置,有點像序列標註的任務,對一段話裡的每個字,都會預測兩個值,預測是開始位置還是結尾位置的概率,相當於對每個字來講,都是一個二分類的任務

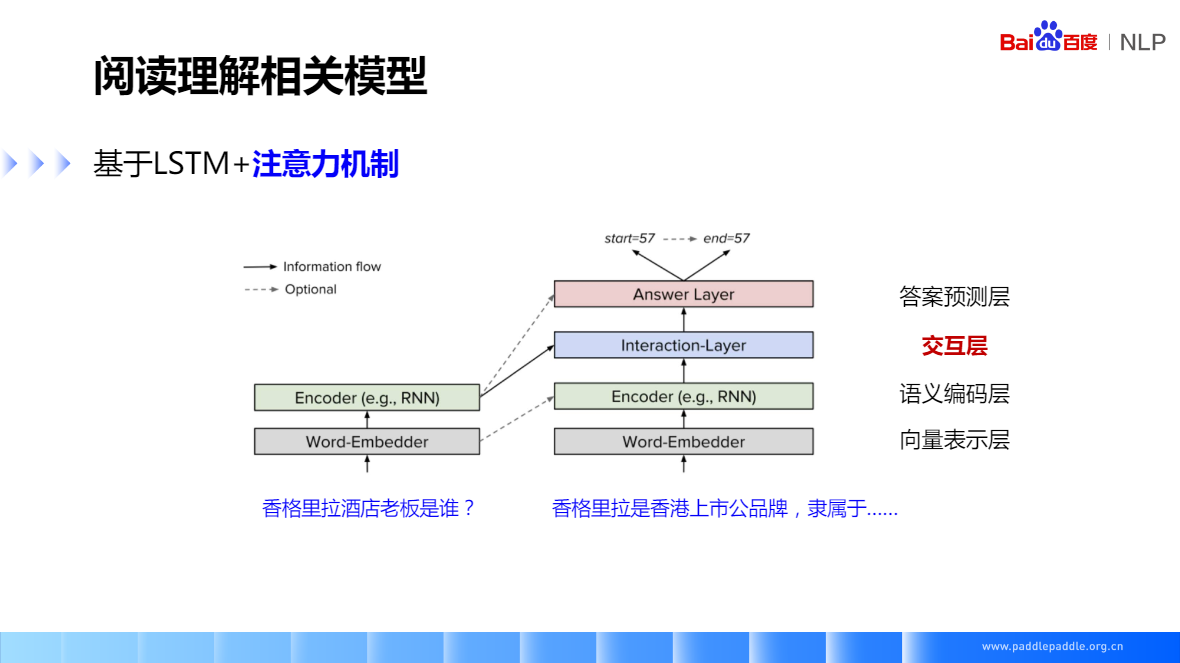
基於LSTM+注意力機制,核心思想就是如何對問題和段落進行互動和語意理解,一般就是在模型裡面加各種 attention,各種複雜的模型結構基本上能總結成圖中的形式,一般分為四層,
- 向量表示層:主要負責把問題和段落裡的token對映成一個向量表示
- 語意編碼層:使用RNN來對問題和段落進行編碼,編碼後,每一個token的向量都包含了上下文的語意資訊
- 互動層:最重要的一層,也是大多數研究工作的一個重點,負責捕捉問題和段落之間的互動資訊,把問題的向量,和段落的向量做各種互動,一般使用各種注意力機制。最後它會輸出一個融合了問題的語意資訊的段落表示。
- 答案預測層:會在段落表示的基本上,預測答案的位置,也就是預測答案的開始位置和結尾位置
LSTM 是一個比較基本的模型結構
注意力機制,來源於影象,在看一張圖片的時候,就會聚焦到圖片上的某些地方,通過圖片上一些重點地方,獲取到主要的資訊。
比如圖片裡是小狗,看到了狗的耳朵、鼻子就能判斷出這是小狗。這時候注意力就集中在狗的臉部上。
對於文字也一樣,文字的問題和段落匹配過程中,也會聚焦到不同的詞上面,比如:香格里拉酒店老闆是誰?段落:香格里拉是香港上市公司品牌隸屬於郭氏集團。
對於問題香格里拉這個詞,在段落文字中更關心香格里拉這個詞,帶著問題讀本文時,所關注點是不一樣的。如:老闆這個詞,關注力在隸屬於上。
如果問題是:香格里拉在哪裡上市的,那麼對於文字的關注點就在「上市公司」上了
注意力機制,就是獲取問題和段落文字互動資訊的一個重要手段
理論形式:給定了一個查詢向量Query,以及一些帶計算的值Value,通過計算查詢向量跟Key的注意力分佈,並把它附加在Value上面,計算出 attention 的值。
- Query 向量是問題,
- Value 對應段落裡面編碼好的語意表示,
- key 是問題向量和文字向量做內積之後做歸一化,代表了每個詞的權重
最後對這些 Value 根據這些權重,做加權求和,最後得到了文字經過attention之後的值
一般會事先定義一個候選庫,也就是大規模語料的來源,然後從這個庫裡面檢索,檢索出一個段落後,再在這個段路上做匹配。

基於預訓練語言模型(eg.BERT)
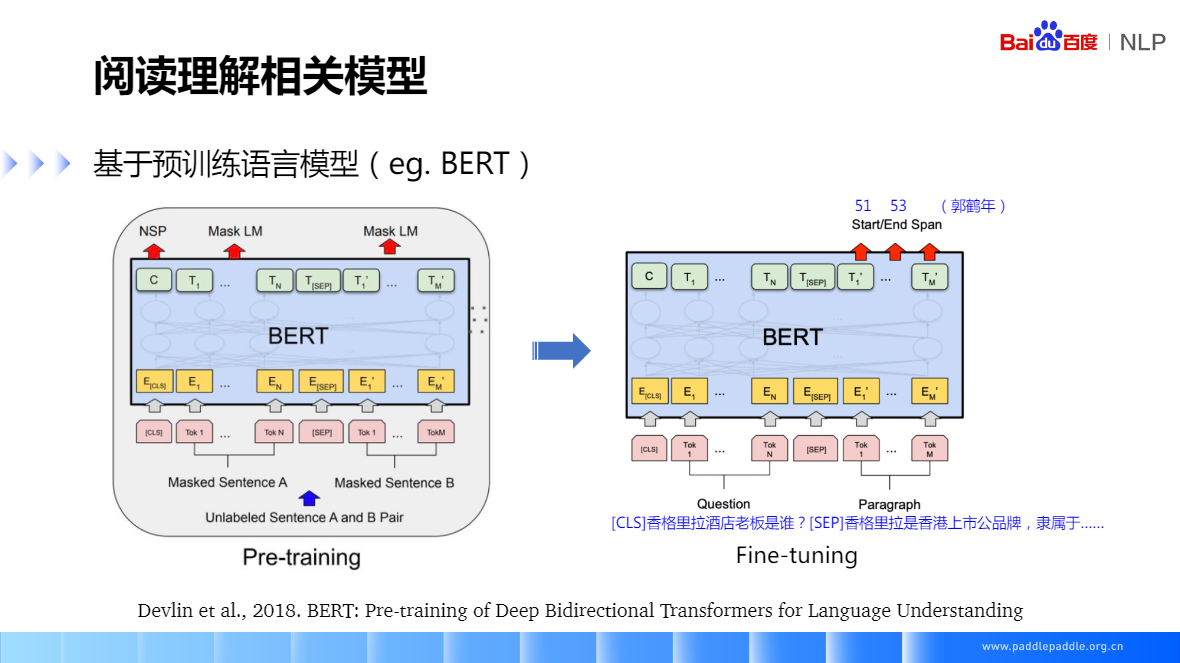
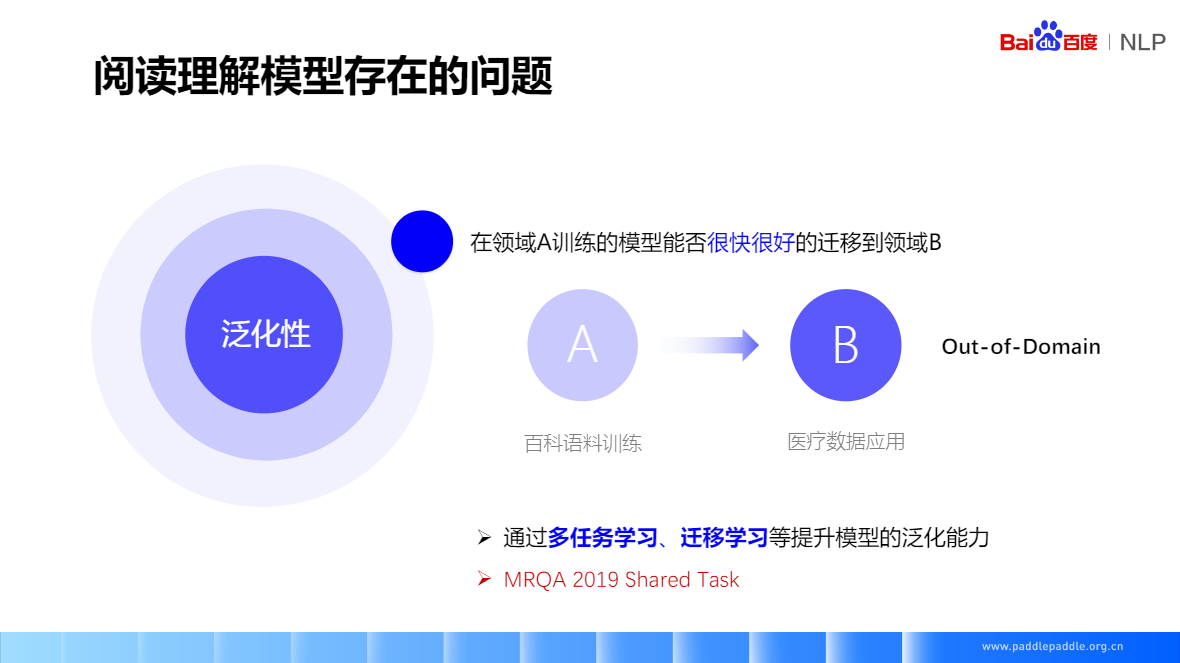
領導A訓練好的模型,在領域B應用
- 通過多任務學習、遷移學習等提升模型的泛化能力
- MRQA 2019 Shared Task
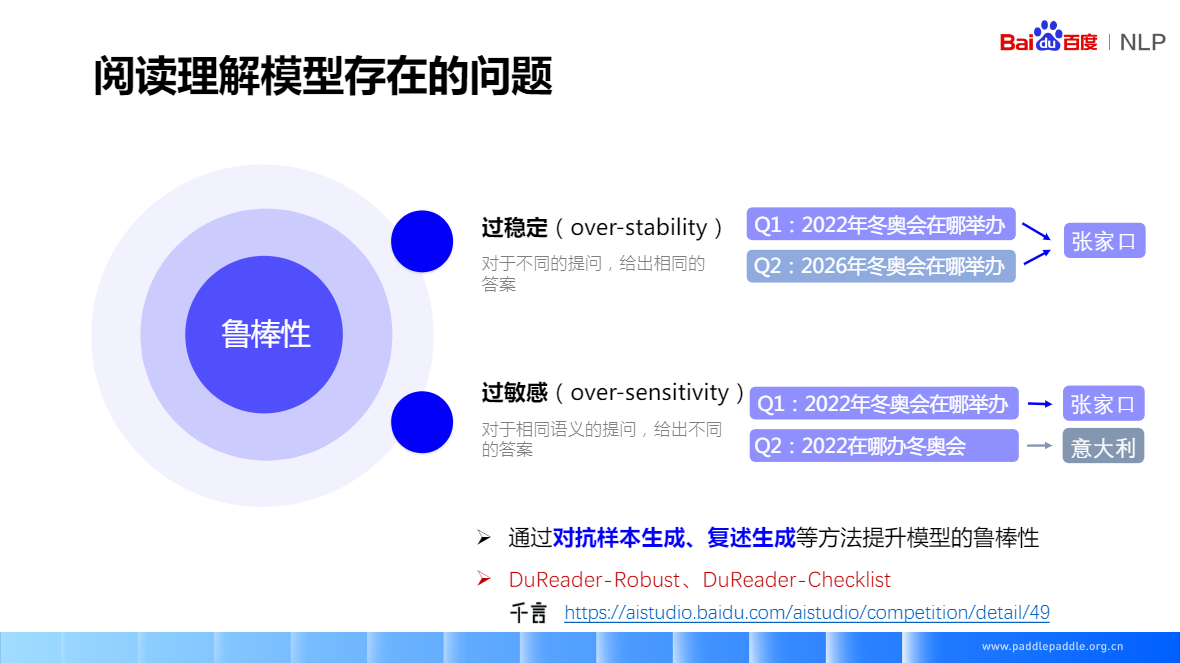
過穩定:對於不同的提問,給出相同的答案
過敏感:對於相同語意的提問,給出不同的答案
提高閱讀模型魯棒性的方法:
- 通過對抗樣本生成、複述生成等方法提升模型的魯棒性
- DuReader-Robust、DuReader-Checklist
千言資料集:https://aistudio.baidu.com/aistudio/competition/detail/49
段落檢索

稀疏向量檢索:雙塔
- 基於詞的稀疏表示
- 匹配能力有限,只能捕捉字面匹配
- 不可學習
把文字表示成 one hot (拼寫可能有錯)的形式,常見的有 TFDF、BM?
文章編碼成向量,向量的長度和詞典的大小一致,比如詞典的大小是3W,稀疏向量表示3W,
每個位置表示這個詞有沒有在問題中出現過,出現過就是1
倒排索引,一般採用稀疏向量方式,只能做字面匹配
稀疏向量,幾百、上千萬的檔案都支援
稠密向量檢索:單塔
- 基於對偶模型結構,進行稠密向量表示
- 能夠建模語意匹配
- 可學習的
把文字表示成稠密向量,也就是 Embedding,需要通過模型,對文字的語意資訊進行建模,然後把資訊記錄在向量裡,這邊的向量長度,一般是128、256、768,相較於稀疏向量檢索小很多,每個位置的數位是浮點數
一般通過對偶模型的結構進行訓練,來獲得建模的語意向量,
例:
Q:王思聰有幾個女朋友
P:國民老公的戀人A、B、C......
如果通過 稀疏向量檢索,可能完全匹配不到
稠密向量檢索,可以學習到,國民老公=>王思聰,戀人=> 女朋友

兩者可以互補,一個字面匹配,一個是語意匹配

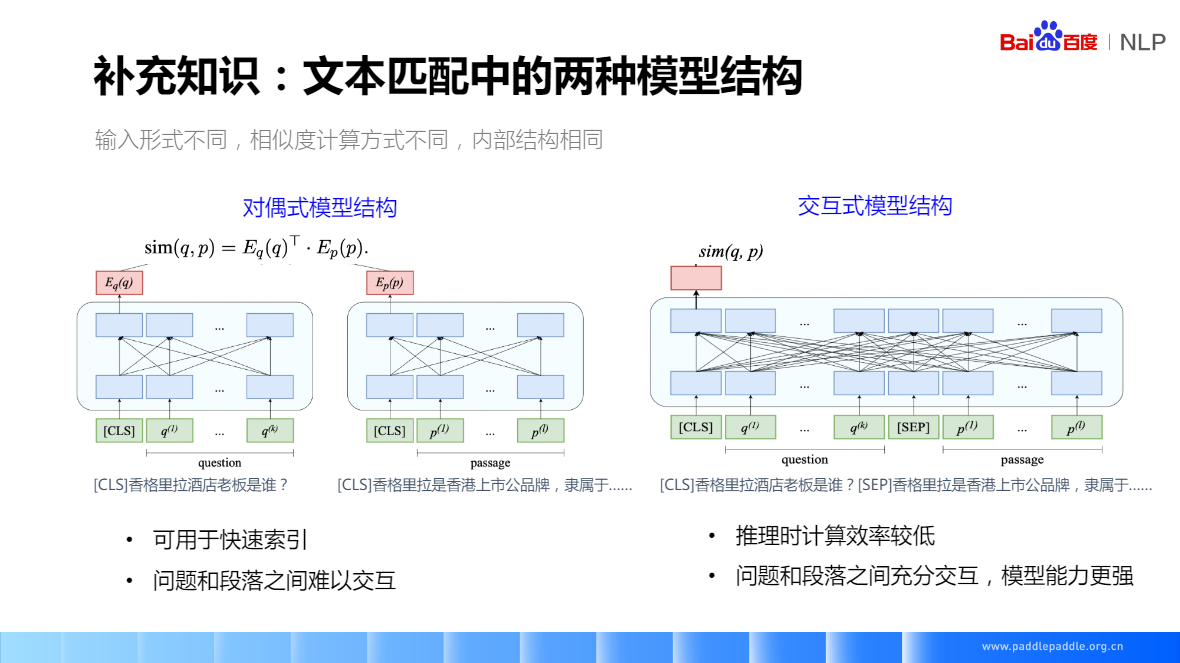
文字匹配中的兩種模型結構
- 對偶式模型結構:問題、段落分別編碼,得到各自的 Embedding,然後通過內積或者 cosin 來計算向量之間的相似度,這個相似度代表了問題和段落之間的匹配程度
問題和段落之間難以互動,因為他們是分別編碼的。底層沒有互動,所以邏輯會弱些
可以快速索引,可以提前把段落向量這邊計算好 - 互動式模型結構:輸入把問題和段落拼一起,在中間互動層問題的文字和段落的文字會有個完全的互動。最後輸出一個來表示問題和段落的匹配程度
對偶模型的引數可以共用,共用引數對字面匹配效果好些,不共用效果也差不了太多
實際應用中,把所有的檔案都計算完,把向量儲存下來。線上計算時,直接去檢索
DPR

正例和強負例 1:1 ,弱負例 越多越好
強負例:和檔案有些關係
弱負例:和檔案內容不相關的。
一般做檢索,不會把正例表得那麼完整,在標註時,也是通過一個query,先去檢索出一些候選的段落,在候選段落裡,去標正例和負例,這樣因為檢索能力的限制,可能沒有檢索回來的一些段落就沒有標註,這樣會導致資料集中漏標,所以實際上在訓練過程中會對這些漏標的資料集進行處理,有些資料集只標了正例,並沒有負例,這時候負例只能通過一些方式去構造

推薦閱讀
- Reading Wikipedia to Answer Open-domain Questions
- Bi-DirectionalAttentionFlowForMachineComprehension
- Machine Comprehension UsingMatch-LSTMand Answer Pointer
- Dense Passage Retrieval for Open-Domain Question Answering
- Latent Retrieval for Weakly Supervised Open Domain Question Answering
- Sparse, Dense, and Attentional Representations for Text Retrieval
- REALM:Retrieval-Augmented Language Model Pre-Training
- RocketQA: An Optimized Training Approach to Dense Passage Retrieval for Open-Domain Question Answering