從2PC和容錯共識演演算法討論zookeeper中的Create請求
最近在讀《資料密集型應用系統設計》,其中談到了zookeeper對容錯共識演演算法的應用。這讓我想到之前參考的zookeeper學習資料中,誤將容錯共識演演算法寫成了2PC(兩階段提交協定),所以準備以此文對共識演演算法和2PC做梳理和區分,也希望它能幫助像我一樣對這兩者有誤解的同學。
1. 2PC(兩階段提交協定)
兩階段提交 (two-phase commit) 協定是一種用於實現 跨多個節點的原子事務(分散式事務)提交 的演演算法。它能確保所有節點提交或所有節點中止,並在某些資料庫內部使用,也以 XA事務 的形式在分散式服務中使用。
在 Java EE 中,XA事務使用 JTA(Java Transaction API) 實現。
2PC的實現
2PC包含 準備階段 和 提交階段 兩個階段,需要藉助 協調者(事務管理器,如阿里巴巴的Seata) 來實現,參與分散式事務的資料庫節點為 參與者。當分散式服務中的節點準備提交時,協調者開始 準備階段:傳送一個 準備請求 到每個節點,詢問它們是否能夠提交,然後協調者會跟蹤參與者的響應
- 如果所有參與者都回答"是",表示它們已經準備好提交,那麼協調者在 提交階段 發出 提交請求,分散式事務提交
- 如果任意一個參與者回答"否",則協調者在 提交階段 中向所有節點傳送 中止請求,分散式事務回滾
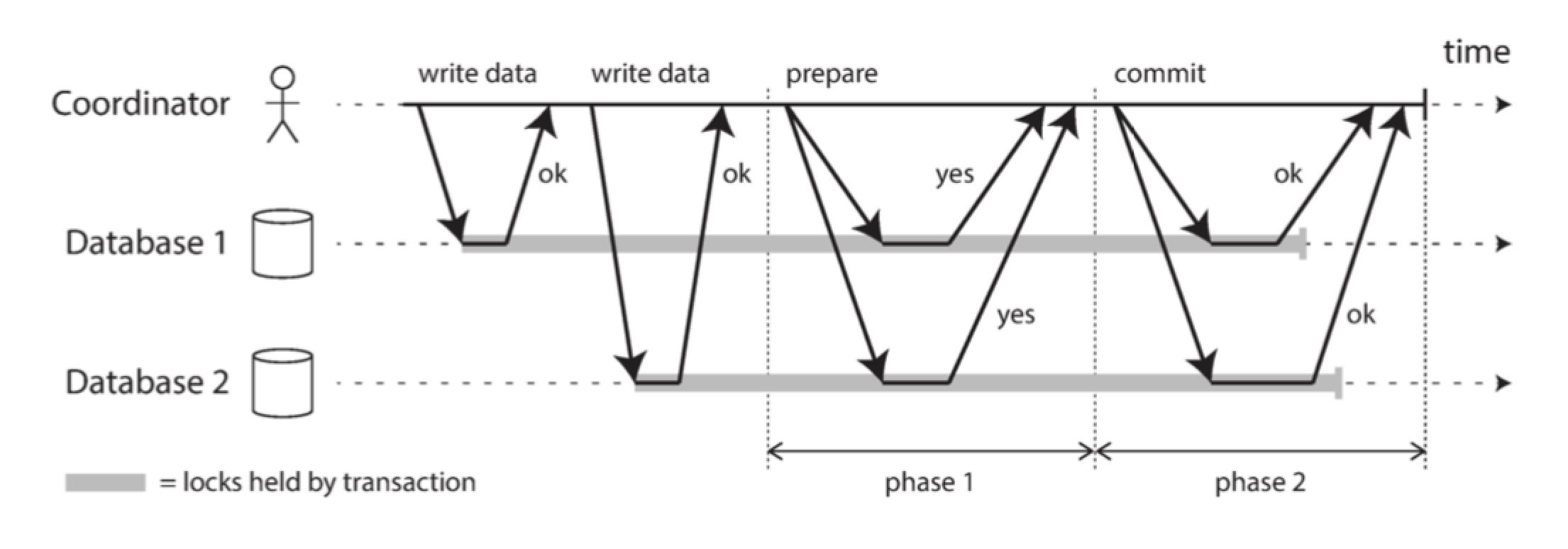
上圖是2PC提交成功的情況,我們來詳述下過程:
- 當服務啟動一個分散式事務時,它會向協調者請求一個事務ID,此事務ID是全域性唯一的
- 在每個參與者上啟動單節點事務,每個單節點事務會持有這個全域性事務 ID。所有的讀寫都是在這些單節點事務中各自完成的。如果在這個階段出現任何問題(節點崩潰或請求超時),則協調者或任何參與者都可以中止
- 當應用準備提交時,對應準備階段:協調者向所有參與者傳送一個 準備請求,同樣也持有全域性事務 ID 。如果任意一個請求失敗或超時,則協調者向所有參與者傳送針對該事務 ID 的 中止請求,即2PC提交中止的情況
- 參與者收到 準備請求 時,需要確保在任意情況下都可以提交事務。這包括將所有事務資料寫入磁碟(出現故障,電源故障,或硬碟空間不足都不能是稍後拒絕提交的理由)以及檢查是否存在任何衝突或違反約束。通過向協調者回答 「是」,節點承諾這個事務一定可以不出差錯地提交。也就是說:參與者沒有實際提交,同時放棄了中止事務的權利
- 當協調者收到所有 準備請求 的答覆時,會就 提交或中止事務 作出明確的決定(只有在 所有參與者 投贊成票的情況下才會提交),這裡對應提交階段。協調者必須把這個提交或中止事務的決定 寫到磁碟上的事務紀錄檔中,記錄為 提交點(commit point) 。如果它隨後崩潰,能通過提交點進行恢復
- 一旦協調者的決定已經儲存在事務紀錄檔中,提交或中止請求會傳送給所有參與者。如果這個請求失敗或超時,協調者 必須永遠保持重試,直到成功為止,對於已經做出的決定,協調者不管需要多少次重試它都必須被執行
2PC協定中有兩個關鍵的 不歸路 需要注意:
- 一旦協調者做出決定,這一決定是不可復原的
- 參與者投票 「是」 時,它承諾它稍後肯定能夠提交(儘管協調者可能仍然選擇放棄),即使參與者在此期間崩潰,事務也需要在其恢復後提交,而且由於參與者投了贊成,它不能在恢復後拒絕提交
這些承諾保證了2PC的 原子性。
協調者失效的情況
如果 協調者失效 並且所有參與者都收到了準備請求並投了是,那麼參與者什麼都做不了只能等待,而且這種情況 解決方案 是等待協調者恢復或資料庫管理員介入操作來提交或回滾事務,當然如果在生產期間這需要承擔運維壓力。
所以,協調者在向參與者傳送提交或中止請求 之前,將其提交或中止決定寫入磁碟上的事務紀錄檔(提交點)。這樣就能在協調者發生崩潰恢復後,通過讀取其事務紀錄檔來確定所有 存疑事務 的狀態,任何在協調者事務紀錄檔中沒有提交記錄的事務都會被終止。因此兩階段提交在第二階段(提交階段)存在阻塞等待協調者恢復的情況,所以兩階段提交又被稱為 阻塞原子提交協定。
番外:3PC
三階段提交協定也是應用在分散式事務提交中的演演算法,它的提出是為了解決兩階段提交協定中存在的阻塞問題。它分為 CanCommit階段、PreCommit階段 和 DoCommit階段,通過引入 參與者超時判斷機制 來解決2PC中存在的參與者依賴協調者的提交請求而阻塞導致的資源佔用等問題。
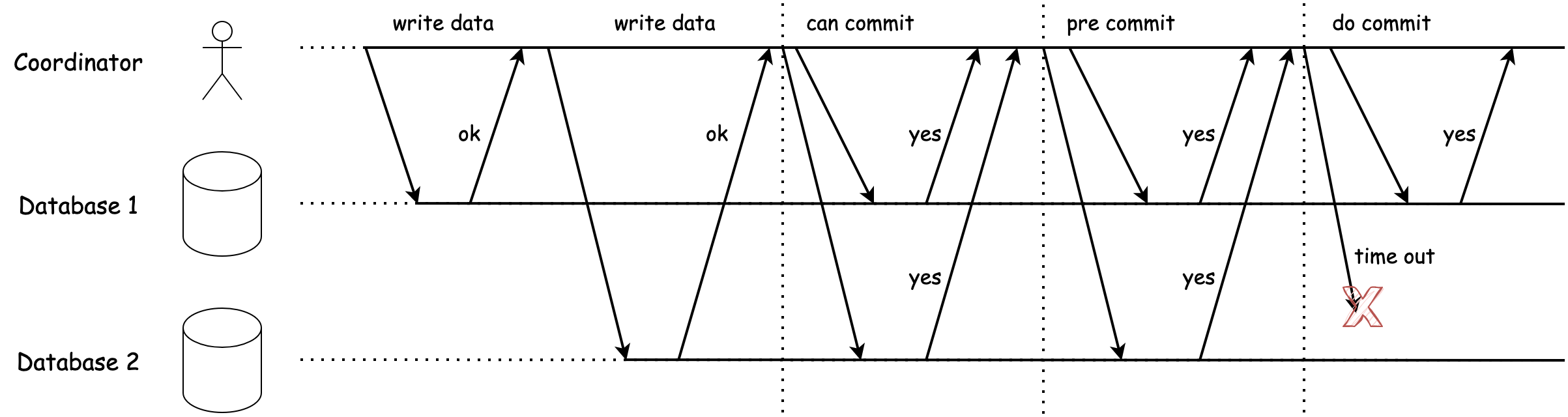
上圖為在DoCommit階段,參與者判斷 DoCommit請求 超時情況的流程圖,我們詳述下它的避免阻塞的流程
- 服務在每個參與者上啟動單節點事務,當參與者準備提交時,對應CanCommit階段,協調者會向所有參與者傳送 CanCommit請求,如果任意一個請求失敗或超時,則協調者會向所有參與者傳送針對該事務的 中止請求,執行事務回滾
- 當協調者收到所有CanCommit請求的答覆時,如果全是「是」那麼則進入PreCommit階段,否則傳送中止請求,執行事務回滾
- 進入PreCommit階段後,協調者會向所有參與者傳送 PreCommit請求,同樣還是如果存在請求失敗或超時,會傳送中止請求執行事務回滾
- 協調者收到所有PreCommit請求的答覆時,如果全是「是」那麼則進入DoCommit階段,否則傳送中止請求,執行事務回滾
- 進入DoCommit階段後,協調者會向所有參與者傳送 DoCommit請求,注意這裡,如果某個參與者沒有收到該請求,它預設認為協調者會傳送提交請求,那麼便本地執行提交事務,從而避免阻塞
3PC雖然解決了2PC中存在的阻塞問題,但是也引入了新的問題:
- 如果協調者在DoCommit階段回覆的是中止請求,那麼超時節點自顧自地提交事務就會發生資料不一致的情況
- 通訊次數增加和實現相對複雜
3PC使原子提交協定變成非阻塞的,但是3PC 假定網路延遲和節點響應時間有限,在大多數具有無限網路延遲和程序暫停的實際系統中,它 並不能保證原子性。非阻塞原子提交需要一個 完美的故障檢測器 來以可靠的機制判斷一個節點是否已經崩潰,而在無限延遲的網路中,超時並不是一種可靠的故障檢測機制,因為即使節點沒有崩潰也會因為網路延遲而超時,出於這個原因,2PC仍然被使用,儘管存在協調者故障的問題。
2. 容錯共識演演算法
容錯共識演演算法用於 節點間資料同步,保證各個副本間資料的一致性和叢集的高可用。它的通常形式是一個或多個節點可以 提議(propose) 某些值,而共識演演算法 決定(decides) 採用其中的某個值,並讓這些節點就提議達成一致。共識演演算法必須具備如下性質:
- 一致同意:沒有兩個節點的決定不同
- 完整性:沒有節點決定兩次
- 有效性:如果節點決定了
v值,那麼v由該節點所提議 - 終止性:由所有未崩潰的節點來最終決定值
終止性實質上是說:容錯共識演演算法不能簡單地永遠閒坐著等待,而是需要根據大多數節點來達成一項決定,因此終止屬性也暗含著 不超過一半的節點崩潰或不可達 的資訊。
一致同意和完整性是共識的 核心思想,即所有節點決定了相同的結果並且決定後不能改變主意。
容錯共識演演算法在節點叢集內部都以某種形式使用一個領導者,並定義了一個 紀元編號(epoch number) 來確保在每個時代中,領導者都是唯一的。每當現任領導宕機時,節點間會開始一場投票,來選出一個新的領導,每次選舉被賦予一個新的紀元編號(全序且單調遞增),如果有兩個不同時代的領導者之間出現衝突(腦裂問題),那麼帶有更高紀元編號的領導者說了算。領導者每想要做出的每一個決定,都必須將提議值傳送給其他節點,並等待 法定人數 的節點響應並贊成提案。法定人數通常(但不總是)由多數節點組成(一般為過半),只有在沒有發現任何帶有更高紀元編號的領導者的情況下,一個節點才會投票贊成提議。
容錯共識演演算法的侷限性
- 節點在做出決定之前對提議進行投票的過程是一種同步複製
- 共識系統總是需要有 法定人數 的節點存活來保證運轉
- 大多數共識演演算法假定參與投票的節點是固定的集合,這意味著你不能簡單的在叢集中新增或刪除節點
- 共識系統通常依靠 超時 來檢測失效的節點,在網路延遲高度變化的環境中,特別是在地理上散佈的系統,經常發生一個節點由於暫時的網路問題,錯誤地認為領導者已經失效。雖然這種錯誤不會損害安全屬性,但頻繁的領導者選舉會導致糟糕的效能表現,所以共識演演算法對網路問題比較敏感,而在面對不可靠的網路相關的共識演演算法研究仍在進展中
3. 2PC和容錯共識演演算法的區別
- 負責解決的問題不同:2PC解決的是分散式事務的一致性,各個節點儲存的資料各有不同,目標側重於保證事務的ACID;容錯共識演演算法解決的是節點副本間資料的一致性和保證叢集的高可用,節點間儲存的資料完全一致,目標側重於資料的複製和同步
- 每個提議通過要求的參與節點數不同:2PC要求 所有的參與者表決成功 才通過;容錯共識演演算法只需要 遵循基於法定人數的表決 即可,這也是容錯共識演演算法 終止屬性(由所有未崩潰的節點來決定最終值) 的體現
- 叢集的高可用保證:2PC的協調者不是通過選舉產生的,而是單獨部署並人為指定的元件,所以它沒有選主機制,不具備高可用性;應用容錯共識演演算法的叢集領導者是通過選舉機制來指定的,並且在發生異常情況時(主節點宕機)能夠選出新的領導者,並進入一致的狀態,以此來保證叢集的高可用
4. zookeeper中的一次Create請求
一些資料中會提到zookeeper在執行CRUD請求時,使用的是2PC,而 實際上它使用的是容錯共識演演算法。我們以Create請求的流程為例(如下圖),來加深和記憶這一知識
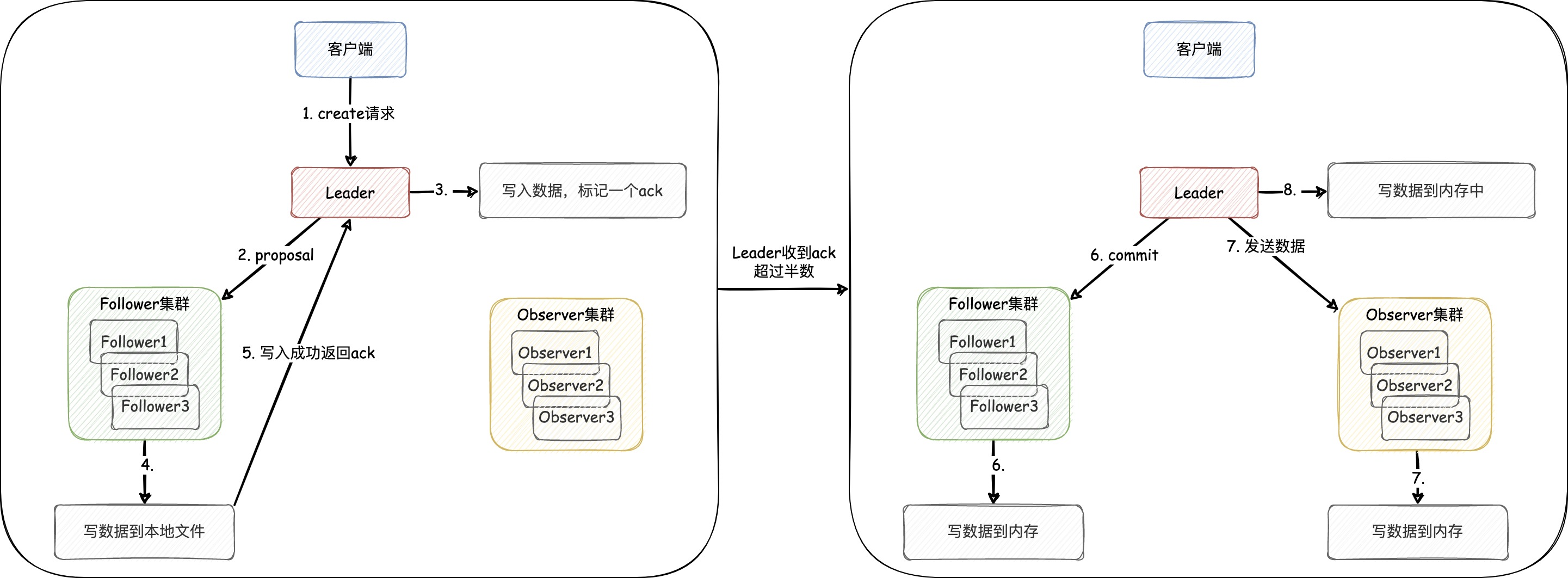
- 使用者端發
create請求到 Leader,即使請求沒落到 Leader 上,那麼其他節點也會將寫請求轉發到 Leader - Leader 會先發一個 提議(proposal)請求給各個 Follower,且自己將資料寫到本地檔案
- Follower 叢集收到 proposal 請求後會將資料寫到本地檔案,寫成功後返回給 Leader 一個 ack回覆
- Leader 發現收到 ack 回覆的數量為 法定人數(過半,包含當前 Leader 節點)時,則提交一個 commit 請求給各個 Follower 節點。傳送 commit 請求就代表該資料在叢集內同步情況沒有問題,並且 可以對外提供存取 了,此時Leader會把資料寫到記憶體中
- Follower 收到 commit 請求後也會將資料寫到各自節點的記憶體中,同時Leader會將資料發給 Observer叢集,通知 Observer叢集 將資料寫到記憶體
巨人的肩膀
- 《資料密集型應用系統設計》第九章:分散式事務與共識
- 百度百科:三階段提交
- 淺談分散式一致性協定之3PC
- 分散式事務(2PC) vs 共識協定(Paxos/raft)
- 《深度剖析zookeeper核心原理》
- 原文收錄:GitHub-Enthusiasm
作者:京東物流 王奕龍
內容來源:京東雲開發者社群