Paimon讀取流程
查詢模式
先來看看官閘道器於Paimon查詢模式的說明

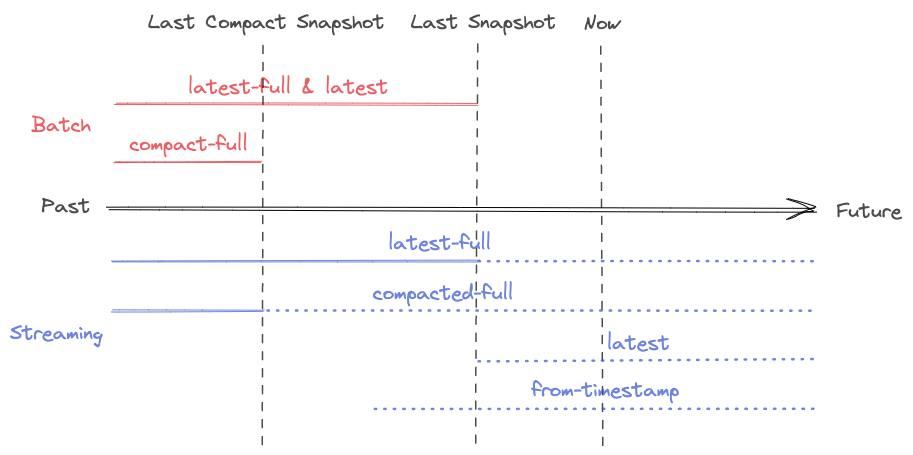
可以看到查詢模式圍繞snapshot展開, 而snapshot分了兩種一種是Last compact snapshot和 last snapshot. 直接讀last snapshot的話應該是需要merge on read. 而last compact snapshot 應該有點類似於hudi裡面的Read Optimized Queries
Change log producer
上表中流讀都提到需要讀取變更流的資料.因此,Paimon表要有產生變更流的資料的能力. 內建了幾種不同的changelog producer.
Changelog producer的含義是這張Paimon表的change log producer. 也就是使用者寫入資料後,如果對於這張表產生正確的change log. 這樣下游才可以基於這個變更流進行增量的處理.
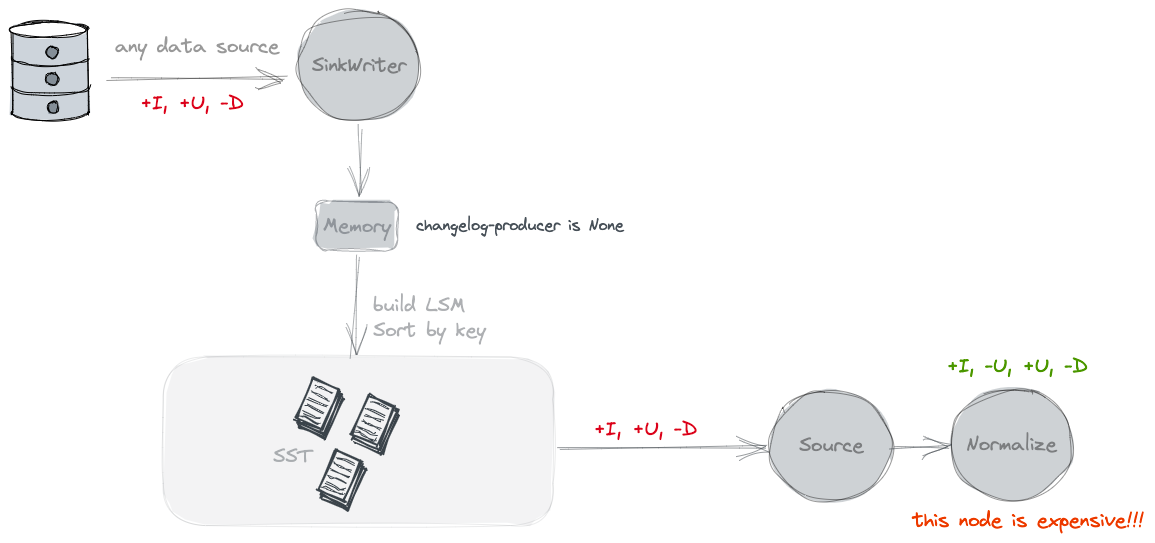
None
不單獨產生Changelog檔案. 按照官網的說法是隻能看到snapshot之間的變化. 但是沒有old value.
Paimon source can only see the merged changes across snapshots, like what keys are removed and what are the new values of some keys.
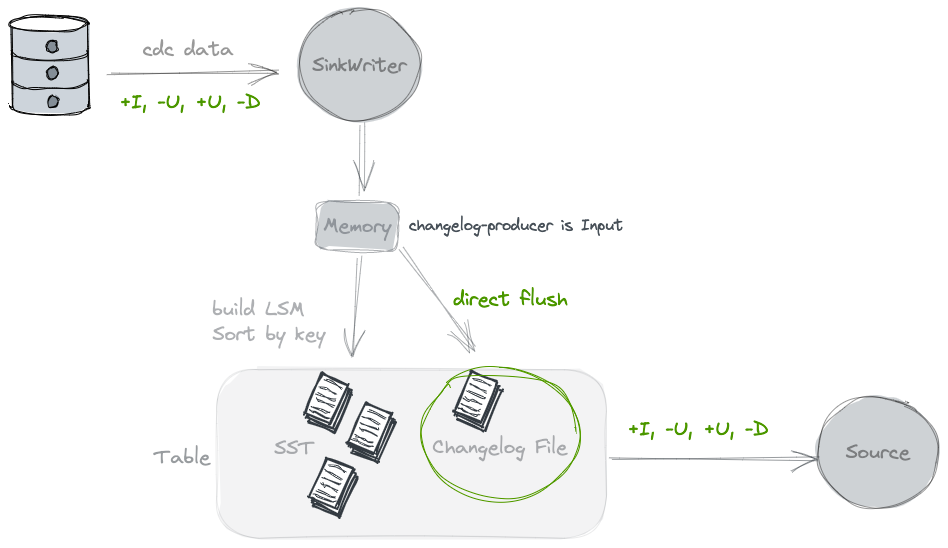
Input
在刷寫資料的時候,會同時寫一份Changelog的檔案,提供給下游消費. 相當於為了流式能消費到變更流的檢視, 需要將上游的變更流資料另外儲存一份.
使用這種型別的clp的前提是, 基於輸入資料已經能完全反應這張表的Changelog, 例如由CDC同步進來的資料,是可以的. 但是對於partial update 是不行的
// 如果設定了ChangelogProducer.INPUT 那麼再刷寫WriteBuffer的時候會同時將原始資料寫入到changelog裡面
final RollingFileWriter<KeyValue, DataFileMeta> changelogWriter =
changelogProducer == ChangelogProducer.INPUT
? writerFactory.createRollingChangelogFileWriter(0)
: null;
final RollingFileWriter<KeyValue, DataFileMeta> dataWriter =
writerFactory.createRollingMergeTreeFileWriter(0);
try {
// forEach會對原始資料的基於key的有序遍歷
writeBuffer.forEach(
keyComparator,
mergeFunction,
changelogWriter == null ? null : changelogWriter::write,
dataWriter::write); // 最終使用的Orc/Parquet Writer來將資料寫出
} finally {
if (changelogWriter != null) {
changelogWriter.close();
}
dataWriter.close();
}
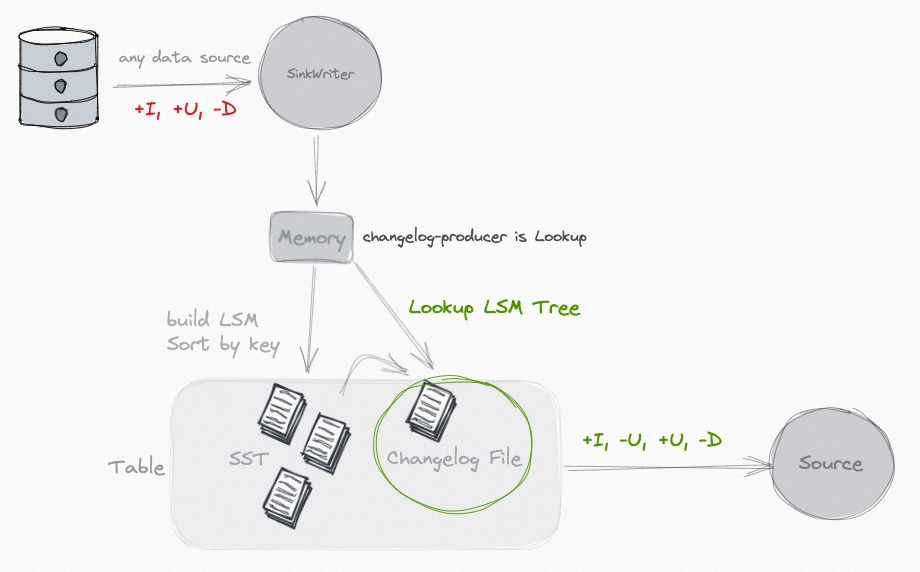
Lookup
當input無法形成一個完整的changelog, 比如partial update的場景中, 每個單獨的input是沒法產生changelog流的, changelog的過程實際和Compaction的merge過程相關
// 針對lookup的changelog producer 需要
// 1. 使用LookupCompaction CompactionStrategy
// 2. 使用LookupMergeTreeCompactRewriter
// 3. 使用LookupMergeFunction
LOOKUP(
"lookup",
"Generate changelog files through 'lookup' before committing the data writing.");
KeyValue result = mergeFunction.getResult();
checkArgument(result != null);
KeyValue highLevel = mergeFunction.highLevel;
boolean containLevel0 = mergeFunction.containLevel0;
// 1. No level 0, just return
// 沒有level 0的資料, 意味著沒有新資料產生
// 那麼沒有changelog檔案產生, 只是高層檔案的合併
if (!containLevel0) {
return reusedResult.setResult(result);
}
// 2. With level 0, with the latest high level, return changelog
// 先前的value也在此次的Compaction列表裡面,直接就可以得出change log了
if (highLevel != null) {
setChangelog(highLevel, result);
return reusedResult.setResult(result);
}
// 3. Lookup to find the latest high level record
// 向更高level中查詢這個key先前的資料, 為了產生變更流代價還是挺高的
// org.apache.paimon.mergetree.LookupLevels#lookup
highLevel = lookup.apply(result.key());
if (highLevel != null) {
mergeFunction2.reset();
mergeFunction2.add(highLevel);
mergeFunction2.add(result);
result = mergeFunction2.getResult();
setChangelog(highLevel, result);
} else {
setChangelog(null, result);
}
return reusedResult.setResult(result);
大致過程就是在Compaction的過程中會向高層的檔案中查詢該key的資料, 並根據查詢結果來構建change log stream.
因為高層檔案的key是有序的, 所以會通過二分法來過濾檔案meta,快速定位到屬於哪個檔案. 但是因為這個檔案是Parquet/Orc的列存檔案, 無法直接根據key去高效查詢的. 所以會先將原始資料讀出,並重新成一個新的格式的檔案,用於lookup探查, 主要是構建key的索引, 用於. HashLookupStoreWriter HashLookupStoreReader 主體邏輯可以參看
Full-compaction

從上面的過程分析可以看出lookup的clp開銷還是很大的,需要重讀某個key的資料, 然後重新構建file cache, 再寫出. 這裡還提供了 full-compaction的方式.同lookup一樣,這個也是在compaction階段來產生的, 不過是full Compaction階段.
Full compaction changelog producer can produce complete changelog for any type of source. However it is not as efficient as the input changelog producer and the latency to produce changelog might be high.
他可以支援任意型別的input,但是時延會比較高. 10min 往上
實現類 FullChangelogMergeTreeCompactRewriter 和 FullChangelogMergeFunctionWrapper
full compaction的時候不會產生delete的change log訊息(大概是因為並不知道誰被delete了?)
在Full compaction階段最後資料都會寫到top level. 然後將最後合併後的資料和topLevel比較, 然後得出一個變更訊息寫到change log檔案中.
對於離線場景的一般delete訊息的需求
昨天新增今天刪,昨天日增量分割區有,今天增量分割區沒有 (也就是change log中並沒有delete訊息).昨天的日全量有,今天的日全量沒有
今天新增今天刪,今天的日增量分割區沒有,今天的日全量也沒有
批讀
| 批模式 | 流模式 | |
|---|---|---|
| latest-full | 讀取最新的snapshot. 獲取的是最近一次的snapshot | 先讀取最新的snapshot, 然後持續讀取變更流 |
| compacted-full | 讀取最近一次Compaction之後的snapshot. | |
| 獲取的snapshot是最近一次compaction的. 理論上這樣讀取階段就不需要Merge On Read了 | 先讀取最近一次Compaction之後的snapshot, 然後持續讀取變更流 | |
| latest | 和latest-full一樣 | 唯讀取最新變化的資料, 沒有讀取snapshot |
| from-timestamp | 讀取一個早於或等於 scan.timestamp-millis指定時間戳的snapshot |
讀取某個時間之後的資料, 不讀取snapshot |
| from-snapshot | 讀取scan.snapshot-id指定的某個snapshot id |
讀取某個snapshot之後的資料, 不讀取snapshot |
| from-snapshot-full | 讀取scan.snapshot-id指定的某個snapshot id |
先讀取某個snapshot, 然後持續讀取其後的變化資料 |
PK表
StaticFileStoreSource
org.apache.paimon.table.source.AbstractInnerTableScan#createStartingScanner
InnerTable#newScan#plan (返回的Splits列表)
org.apache.paimon.table.AbstractFileStoreTable#newScan
org.apache.paimon.KeyValueFileStore#newScan()
org.apache.paimon.table.source.snapshot.SnapshotSplitReaderImpl#splits
org.apache.paimon.operation.AbstractFileStoreScan#plan 通過snapshot, 讀取到相應的ManifestEntry 過濾出所有要讀的檔案
org.apache.paimon.table.source.snapshot.SnapshotSplitReaderImpl#generateSplits 對檔案列表建立splits
org.apache.paimon.table.source.MergeTreeSplitGenerator#split 每個bucket內部進行splits切分, 提高讀取的並行度
org.apache.paimon.flink.source.FileStoreSourceSplitReader
org.apache.paimon.table.source.KeyValueTableRead#createReader
org.apache.paimon.operation.KeyValueFileStoreRead#createReaderWithoutOuterProjection Merge On Read
Append 表
大體上和上面一樣. 除了切分split的時候和建立reader的時候
org.apache.paimon.table.source.AppendOnlySplitGenerator#split
org.apache.paimon.operation.AppendOnlyFileStoreRead#createReader
流讀
org.apache.paimon.table.AbstractFileStoreTable#newStreamScan
org.apache.paimon.table.source.AbstractInnerTableScan#createStartingScanner 建立一個初始的scan 這個和批模式很類似. 但是大部分流讀都不會去讀取Snapshot, 這個部分只是生成一個next Snapshot的id
org.apache.paimon.table.source.InnerStreamTableScanImpl#createFollowUpScanner 建立一個變更流的scan
變更流就和上面的Changelog producer息息相關, 每一種clp都有一個對應的變更流的planner. 用於根據Snapshot返回splits
- DeltaFollowUpScanner
- InputChangelogFollowUpScanner
- CompactionChangelogFollowUpScanner
- CompactionChangelogFollowUpScanner
並且也可以看到變更流的消費是跟著Snapshot走的, 在Stream 的 Source中會定期去獲取splits, 就會觸發定期Plan的獲取, Plan的獲取依賴於Snapshot. 所以讀取的時延實際上Snapshot息息相關, 而Snapshot的產生又和上游的Checkpoint頻率息息相關.
對於Append表 changelog 應該是delta 的資料, 是不是Append表應該只有DeltaFollowUpScanner 呢?
Lookup Join
Paimon還支援維表關聯. 維表關聯只支援all的模式. 會將資料全部load到本地(會有一些過濾下推), 並儲存到Rocksdb中. 不會在關聯的過程中直接去查詢檔案, 從上面的lookup changelog producer實現中也可以看出 kv的查詢開銷還是很大的.
參考
changelog-producer: https://paimon.apache.org/docs/master/concepts/primary-key-table/
本文來自部落格園,作者:Aitozi,轉載請註明原文連結:https://www.cnblogs.com/Aitozi/p/17503793.html