使用編碼工具
2023-06-25 18:00:53
本文主要介紹了對句子編碼的過程,以及如何使用PyTorch中自帶的編碼工具,包括基本編碼encode()、增強編碼encode_plus()和批次編碼batch_encode_plus()。
一.對一個句子編碼例子
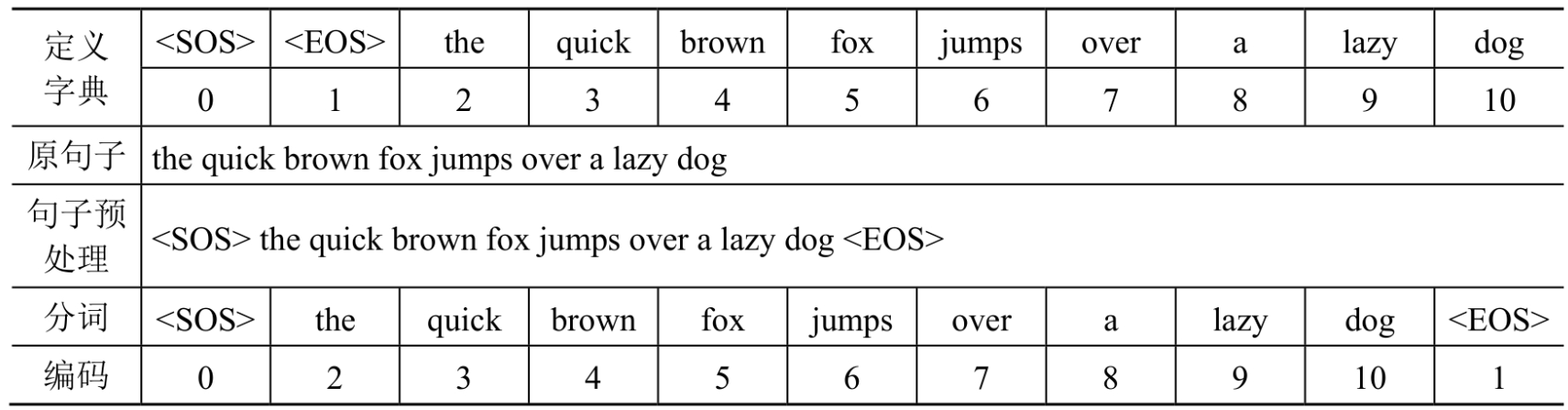
假設想在要對句子'the quick brown fox jumps over a lazy dog'進行編碼,該如何處理呢?簡單理解編碼就是用數位表示單詞,並且用特殊符號代表一個句子的開頭和結束。
vocab表示一個例子字典,在句子的開頭和結束新增
def encode_example_test():
# 字典
vocab = {
'<SOS>': 0,
'<EOS>': 1,
'the': 2,
'quick': 3,
'brown': 4,
'fox': 5,
'jumps': 6,
'over': 7,
'a': 8,
'lazy': 9,
'dog': 10,
}
# 簡單編碼
sent = 'the quick brown fox jumps over a lazy dog'
sent = '<SOS> ' + sent + ' <EOS>'
print(sent)
# 英文分詞
words = sent.split()
print(words)
# 編碼為數位
encode = [vocab[i] for i in words]
print(encode)
可見編碼工作流程包括定義字典、句子預處理、分詞和編碼4個步驟:
二.使用編碼工具
接下來介紹使用HuggingFace提供的編碼工具。
1.基本的編碼函數encode()
def encode_test():
# 第2章/載入編碼工具
from transformers import BertTokenizer
tokenizer = BertTokenizer.from_pretrained(
pretrained_model_name_or_path='bert-base-chinese', # 通常編碼工具和模型名字一致
cache_dir=None, # 編碼工具的快取路徑
force_download=False, # 是否強制下載,當為True時,無論是否有本地快取,都會強制下載
)
# 第2章/準備實驗資料
sents = [
'你站在橋上看風景',
'看風景的人在樓上看你',
'明月裝飾了你的窗子',
'你裝飾了別人的夢',
]
# 第2章/基本的編碼函數
out = tokenizer.encode(
text=sents[0],
text_pair=sents[1], # 如果只想編碼一個句子,可設定text_pair=None
truncation=True, # 當句子長度大於max_length時截斷
padding='max_length', # 一律補PAD,直到max_length長度
add_special_tokens=True, # 需要在句子中新增特殊符號
max_length=25, # 最大長度
return_tensors=None, # 返回的資料型別為list格式,也可以賦值為tf、pt、np,分別表示TensorFlow、PyTorch、NumPy資料格式
)
print(out)
print(tokenizer.decode(out))
輸出結果如下所示:
[101, 872, 4991, 1762, 3441, 677, 4692, 7599, 3250, 102, 4692, 7599, 3250, 4638, 782, 1762, 3517, 677, 4692, 872, 102, 0, 0, 0, 0]
[CLS] 你 站 在 橋 上 看 風 景 [SEP] 看 風 景 的 人 在 樓 上 看 你 [SEP] [PAD] [PAD] [PAD] [PAD]
可見編碼工具把兩個句子前後拼接在一起,中間使用[SEP]符號分隔,在整個句子的頭部新增符號[CLS],在整個句子的尾部新增符號[SEP],因為句子的長度不足max_length,所以又補充了4個[PAD]。
2.進階的編碼函數encode_plus()
def encode_plus_test():
# 第2章/載入編碼工具
from transformers import BertTokenizer
tokenizer = BertTokenizer.from_pretrained(
pretrained_model_name_or_path='bert-base-chinese', # 通常編碼工具和模型名字一致
cache_dir=None, # 編碼工具的快取路徑
force_download=False, # 是否強制下載,當為True時,無論是否有本地快取,都會強制下載
)
# 第2章/準備實驗資料
sents = [
'你站在橋上看風景',
'看風景的人在樓上看你',
'明月裝飾了你的窗子',
'你裝飾了別人的夢',
]
# 第2章/進階的編碼函數
out = tokenizer.encode_plus(
text=sents[0],
text_pair=sents[1],
truncation=True, # 當句子長度大於max_length時截斷
padding='max_length', # 一律補零,直到max_length長度
max_length=25,
add_special_tokens=True,
return_tensors=None, # 可取值tf、pt、np,預設為返回list
return_token_type_ids=True, # 返回token_type_ids
return_attention_mask=True, # 返回attention_mask
return_special_tokens_mask=True, # 返回special_tokens_mask特殊符號標識
return_length=True, # 返回length標識長度
)
# input_ids:編碼後的詞
# token_type_ids:第1個句子和特殊符號的位置是0,第2個句子的位置是1
# special_tokens_mask:特殊符號的位置是1,其他位置是0
# attention_mask:PAD的位置是0,其他位置是1
# length:返回句子長度
for k, v in out.items():
print(k, ':', v)
print(tokenizer.decode(out['input_ids']))
引數return_token_type_ids、return_attention_mask、return_special_tokens_mask、return_length表明需要返回相應的編碼結果,如果指定為False,則不會返回對應的內容。
3.批次的編碼函數batch_encode_plus()
顧名思義就是一次可以編碼多個句子。
def batch_encode_plus_test():
# 第2章/載入編碼工具
from transformers import BertTokenizer
tokenizer = BertTokenizer.from_pretrained(
pretrained_model_name_or_path='bert-base-chinese', # 通常編碼工具和模型名字一致
cache_dir=None, # 編碼工具的快取路徑
force_download=False, # 是否強制下載,當為True時,無論是否有本地快取,都會強制下載
)
# 第2章/準備實驗資料
sents = [
'你站在橋上看風景',
'看風景的人在樓上看你',
'明月裝飾了你的窗子',
'你裝飾了別人的夢',
]
# 第2章/批次編碼成對的句子
out = tokenizer.batch_encode_plus(
batch_text_or_text_pairs=[(sents[0], sents[1]), (sents[2], sents[3])], # 編碼成對的句子,如果只想編碼一個句子,那麼batch_text_or_text_pairs=[sents[0], sents[1]]
add_special_tokens=True, # 需要在句子中新增特殊符號
truncation=True, # 當句子長度大於max_length時截斷
padding='max_length', # 一律補零,直到max_length長度
max_length=25,
return_tensors=None, # 可取值tf、pt、np,預設為返回list
return_token_type_ids=True, # 返回token_type_ids:第1個句子和特殊符號的位置是0,第2個句子的位置是1
return_attention_mask=True, # 返回attention_mask:PAD的位置是0,其他位置是1
return_special_tokens_mask=True, # 返回special_tokens_mask特殊符號標識:特殊符號的位置是1,其他位置是0
# return_offsets_mapping=True, # 返回offsets_mapping標識每個詞的起止位置,這個引數只能BertTokenizerFast使用
return_length=True, # 返回編碼後句子的長度
)
# input_ids:編碼後的詞
# token_type_ids:第1個句子和特殊符號的位置是0,第2個句子的位置是1
# special_tokens_mask:特殊符號的位置是1,其他位置是0
# attention_mask:PAD的位置是0,其他位置是1
# length:返回句子長度
for k, v in out.items():
print(k, ':', v)
tokenizer.decode(out['input_ids'][0])
4.對字典的操作
def dict_test():
# 第2章/載入編碼工具
from transformers import BertTokenizer
tokenizer = BertTokenizer.from_pretrained(
pretrained_model_name_or_path='bert-base-chinese', # 通常編碼工具和模型名字一致
cache_dir=None, # 編碼工具的快取路徑
force_download=False, # 是否強制下載,當為True時,無論是否有本地快取,都會強制下載
)
# 第2章/獲取字典
vocab = tokenizer.get_vocab()
print(type(vocab), len(vocab), '明月' in vocab) # <class 'dict'> 21128 False
# 第2章/新增新詞
tokenizer.add_tokens(new_tokens=['明月', '裝飾', '窗子'])
# 第2章/新增新符號
tokenizer.add_special_tokens({'eos_token': '[EOS]'})
# 第2章/編碼新新增的詞
out = tokenizer.encode(
text='明月裝飾了你的窗子[EOS]',
text_pair=None,
truncation=True, # 當句子長度大於max_length時截斷
padding='max_length', # 一律補PAD,直到max_length長度
add_special_tokens=True, # 需要在句子中新增特殊符號
max_length=10,
return_tensors=None, # 可取值tf、pt、np,預設為返回list
)
print(out)
print(tokenizer.decode(out)) # [CLS] 明月 裝飾 了 你 的 窗子 [EOS] [SEP] [PAD]
可以"明月"、"裝飾"、"窗子"已經被識別為一個詞,而不是兩個詞,新的特殊符號[EOS]也被正確識別。
參考文獻:
[1]《HuggingFace自然語言處理詳解:基於BERT中文模型的任務實戰》