我試圖給你分享一種自適應的負載均衡。
你好呀,我是歪歪。
這篇文章帶大家來盤一個有點意思的負載均衡演演算法:
https://cn.dubbo.apache.org/zh-cn/overview/core-features/load-balance/

自適應負載均衡,雖然這個演演算法我是在 Dubbo 的原始碼裡面看到的。但是這並不算是 Dubbo 的專屬,而是一種演演算法思想,只不過你可以在 Dubbo 裡面找到其對應的 Java 實現。
同樣的,在 go-zero 裡面,你也可以找到其對應的 Go 語言的實現。
關於這幾種負載均衡策略,官方給了兩個示意圖。
https://cn.dubbo.apache.org/zh-cn/overview/reference/proposals/heuristic-flow-control
當服務提供端的機器設定比較均衡時,既每臺機器的處理能力都差不多,甚至時一樣的時候,可以看到 p2c 演演算法的吞吐量,遙遙領先:

而當服務提供端的機器設定參差不齊的時候,也就是有的機器處理能力牛逼,有的又很拉跨的時候,adaptive 策略就比較出色了:
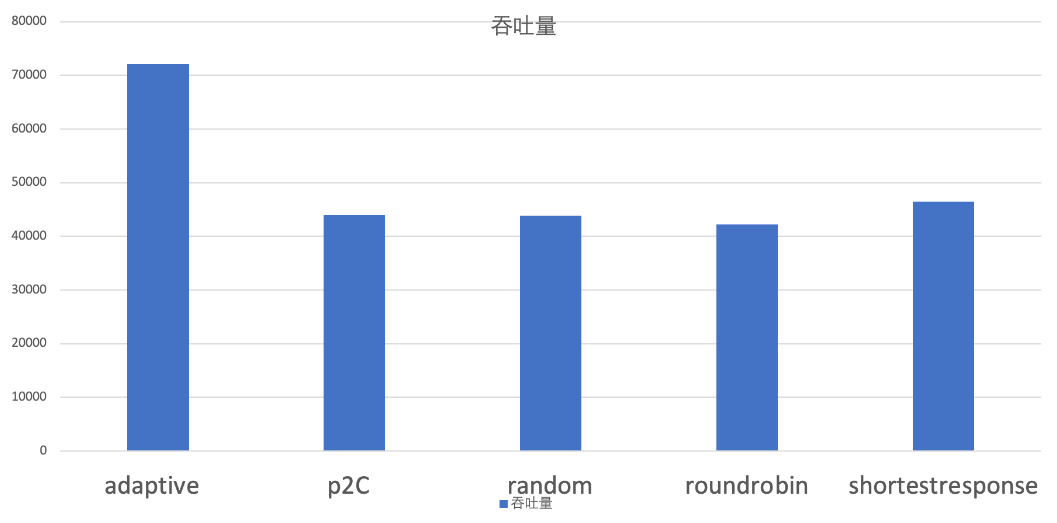
本文主要就帶大家盤一下 adaptive 策略。
Demo
首先,還是不要偷懶,我們搞個 Demo 出來。
在 Dubbo 的官網上,不知道什麼時候冒出來一個 Initializer 模組:

我體驗了一下,利用這個搭建 Demo,和以前自己和 SpringBoot 搞融合的方式比起來,就一個字:非常的快!
關於這個 Initializer 模組的詳細介紹,如果感興趣可以自己去玩玩,我這裡就不擴充套件了。
注意 Dubbo 版本選擇 3.2.0 就行,因為我們要研究的自適應負載均衡策略是在這個版本中才開始支援的。
我建立的是一個 Single Module 專案,程式碼下載下來之後,結構是這樣的:
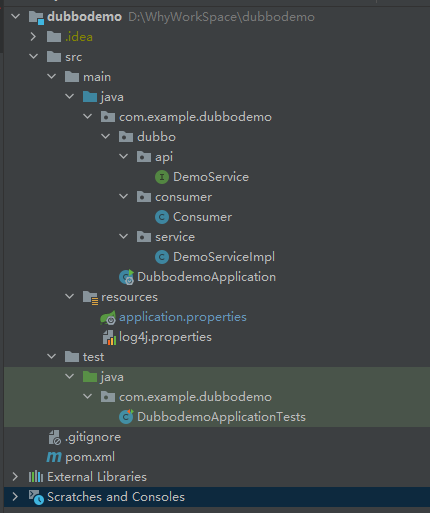
一個提供者,一個消費者。消費者繼承了 CommandLineRunner 介面,在服務啟動完成之後會自動去觸發一次服務呼叫:
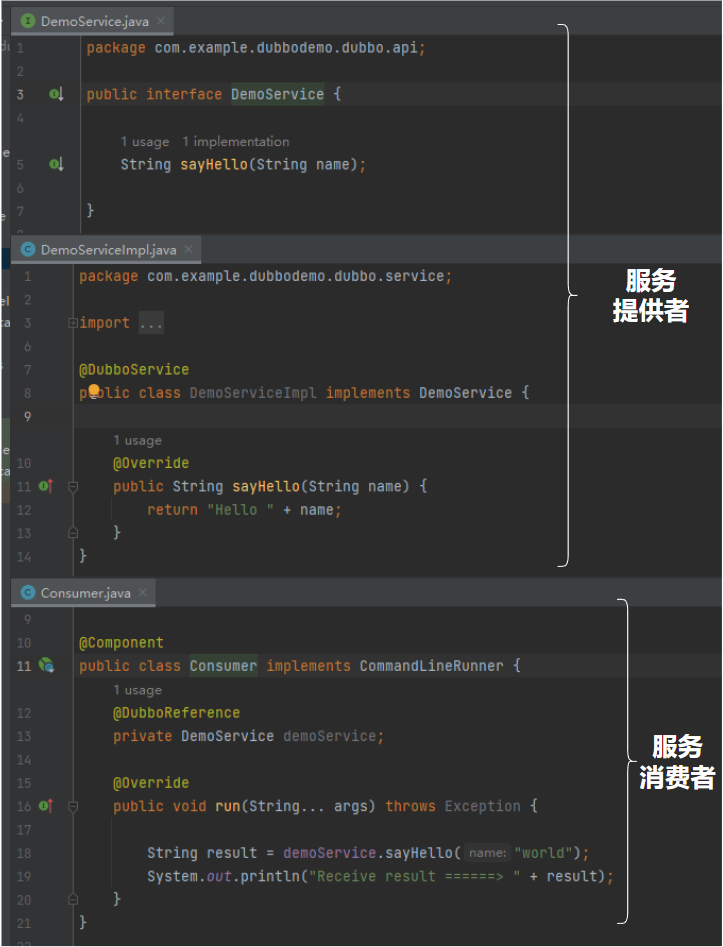
所以在專案開啟,依賴拉取完畢之後,啥也不用管,我們先把專案啟動起來,看看啥情況:
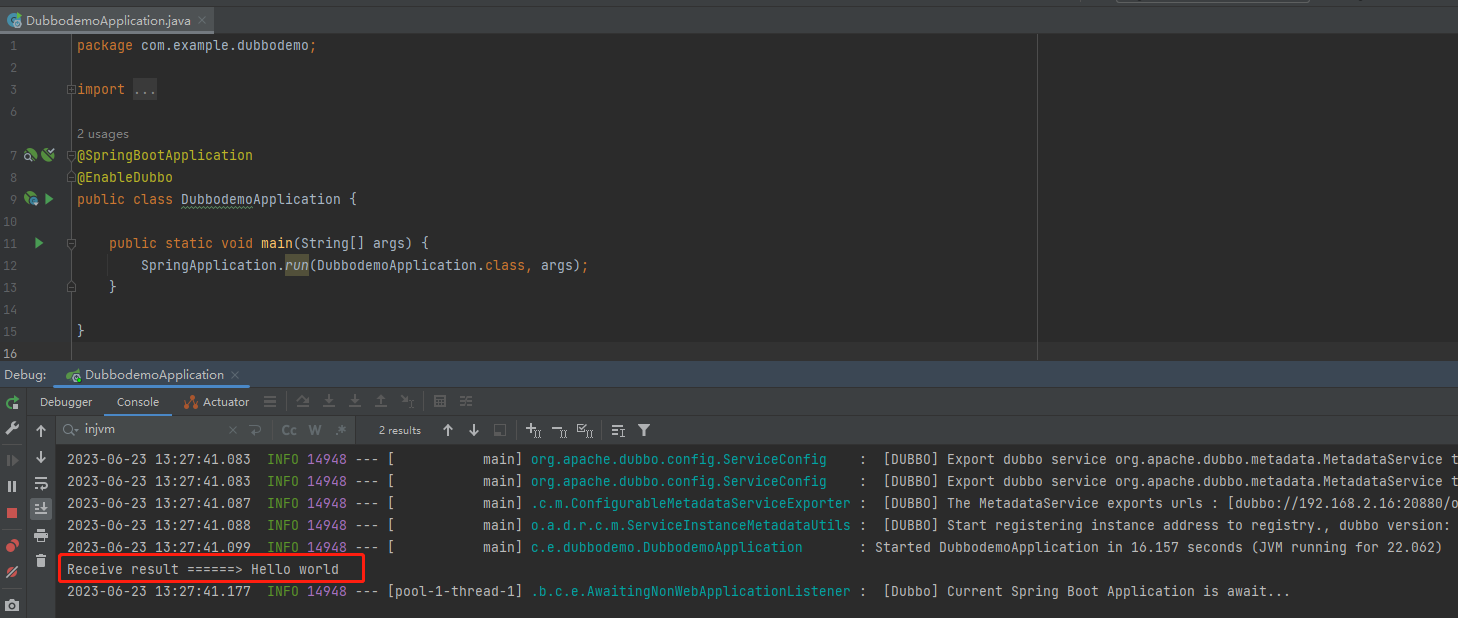
控制檯輸出了 Consumer 類中的內容,這樣就算是完成了一次 Dubbo 呼叫,就這麼簡單。
如果你想要了解 Dubbo 服務的呼叫過程,那麼你基本上就可以用這個 Demo 去進行偵錯了。
在服務提供者的實現類中打上斷點,拿到呼叫棧,玩去吧:
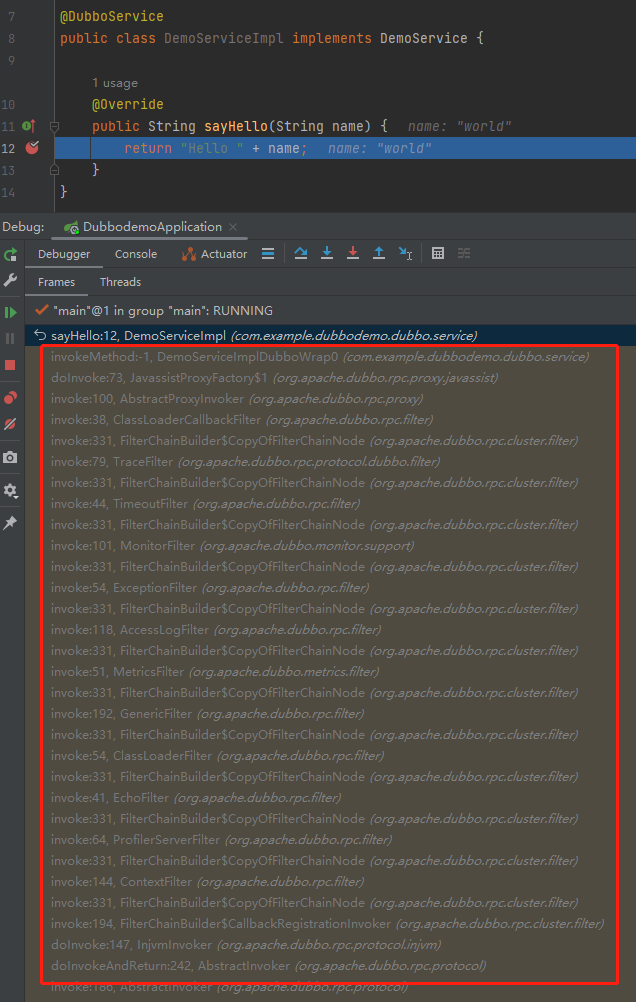
但是,你有沒有感覺到一絲絲奇怪?
我們甚至都沒有啟動一個註冊中心,就完成了一次 Dubbo 呼叫?
因為在 Demo 裡面使用的是 injvm 協定,也就是本地呼叫:

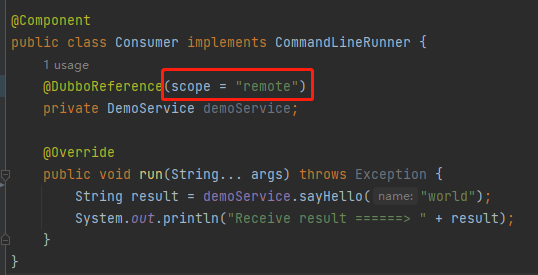
所以,我們還需要對這個 Demo 進行一點改造,本次要偵錯的部分是負載均衡策略,需要使用遠端呼叫才行。
因此需要在服務參照的地方,加上 scope="remote" 設定:
然後在組態檔中設定註冊中心:
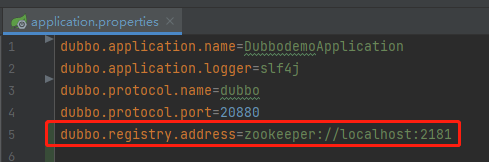
同時在自己本地啟動一個 zookeeper。
通過 ZooInspector 工具,可以看到在 20880 埠有一個服務提供者了:
類似的,我們在 20881 和 20882 再搞一個服務提供者,一共三個。
有同學可能就要問了:為什麼至少要三個呢?
如果只有一個服務提供者,也不需要進行負載均衡。
如果只有兩個服務提供者,也用不上自適應負載均衡。
為什麼?
我們再看一下關於它的描述。
自適應負載均衡:在 P2C 演演算法基礎上,選擇二者中 load 最小的那個節點
P2C 演演算法,是要隨機選擇兩個節點。
如果你只有兩個節點,還選個啥啊。
所以,如果我們要盤一下自適應負載均衡,服務提供方節點當然是越多越好,但是至少也需要 3 個節點。
原始碼
如果要啟用自適應負載均衡演演算法,需要在服務參照的地方進行指定:
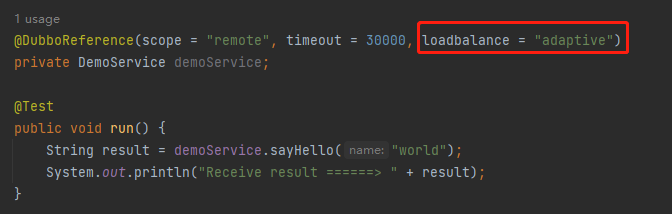
然後在對應的位置打上斷點:
org.apache.dubbo.rpc.cluster.loadbalance.AdaptiveLoadBalance#doSelect
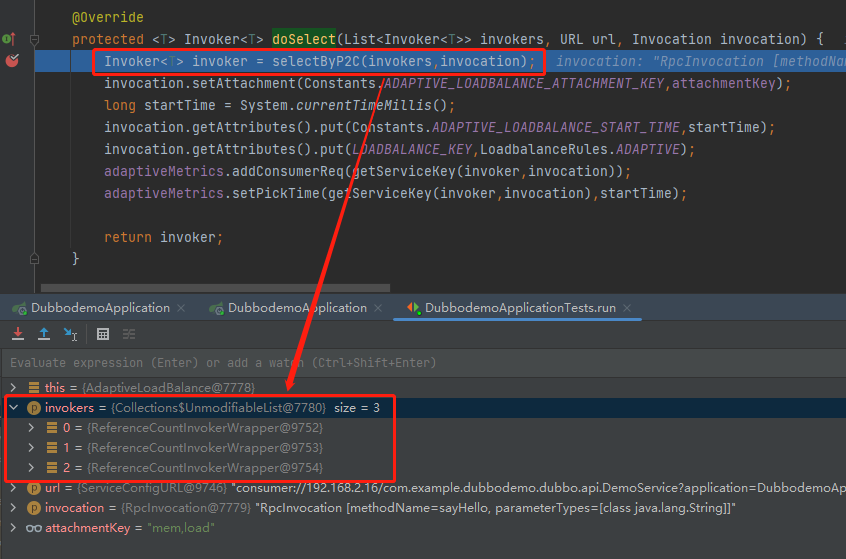
進入斷點處,既 doSelect 方法的第一行的方法,就是叫做 selectByP2C,主打的就是一個開門見山。
可以看到這個方法的入參 invokers 的大小就是 3,它就是代表我們在 20880、20881、20882 埠啟動的三個服務提供方。
進入 doSelect 方法,核心邏輯就兩部分:
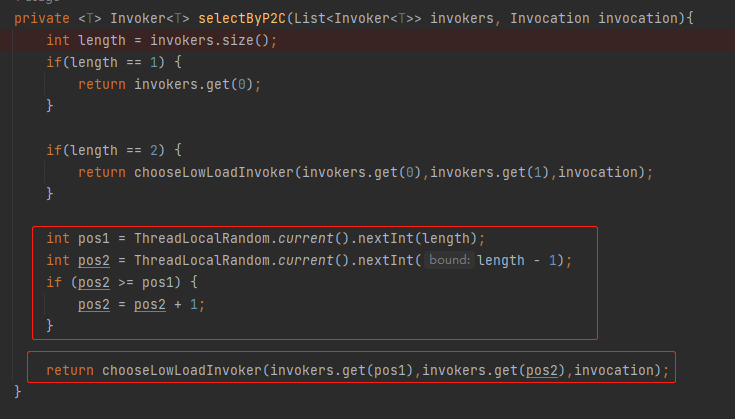
第一部分是這樣的:
int pos1 = ThreadLocalRandom.current().nextInt(length);
int pos2 = ThreadLocalRandom.current().nextInt(length - 1);
if (pos2 >= pos1) {
pos2 = pos2 + 1;
}
你說這是在幹啥?
雖然只有簡單的四行程式碼,但是我還是給你縷一縷,因為我總感覺這個地方有 BUG。
首先,在我們的 Demo 中 length 就是 invokers 的大小,既為 3。
然後 pos1、pos2 代表的是 invokers 這個 List 的下標。
所以,
第一次隨機,pos1 就是從 [0,3) 之間的正數。
第二次隨機,pos2 就是從 [0,2) 之間的正數。
沒問題對吧?
那麼問題就來了:如果第一次沒有隨機出 2,即最後一個下標。那麼第二次隨機的時候由於執行了減一操作,所以最後一個下標根本就不可能被隨機到。
所以,我認為這個隨機演演算法對於 invokers 集合中的最後一個元素是不公平的,因為它少了一次參與隨機的機會。
然後,它還有這樣的兩行程式碼:
if (pos2 >= pos1) {
pos2 = pos2 + 1;
}
目的是為了解決當 pos2 和 pos1 隨機出一樣的值的時候,把 pos2 進行加一處理。
首先, pos2 和 pos1 隨機出一樣的值,這個是完全有可能的。
其次,為什麼不是 pos1 + 1 呢?或者說能不能是 pos1 + 1 呢?
不能。
因為,假設 pos1 是最後一個下標,再加一的話那麼就越界了呀。
只能是 pos2 進行加一,因為 pos2 的最大值也只能是倒數第二個元素。
整個演演算法從邏輯上來說,完全是沒有問題的,可以實現隨機選擇兩個元素出來的邏輯。
但是,我總感覺對於最後一個元素,即 List 中最後一個服務提供者來說,確實是不太友好。它被選中的概率比其他的元素少了一半。
萬一最後一個服務提供者,又恰好是一個效能牛逼的伺服器呢?
這個地方不知道是不是我想錯了,反正我之前寫 P2C 的時候,是這樣寫的:
Object invoker1 = invokerList.remove(ThreadLocalRandom.current().nextInt(invokerList.size()-1));
Object invoker2 = invokerList.remove(ThreadLocalRandom.current().nextInt(invokerList.size()-1));
關於 Dubbo 原始碼這裡為什麼是這樣的寫法,我也不太明白。我看了 go-zero 對應部分的原始碼,也是和 Dubbo 一樣的寫法。不知道是不是我把自己給繞進去了。
算了,問題不大:

前面講的程式碼,就是 P2C 思想的實現,是不是非常簡單?
在我們的 Demo 中,選出來的就是 2,1 這兩個 invokers:
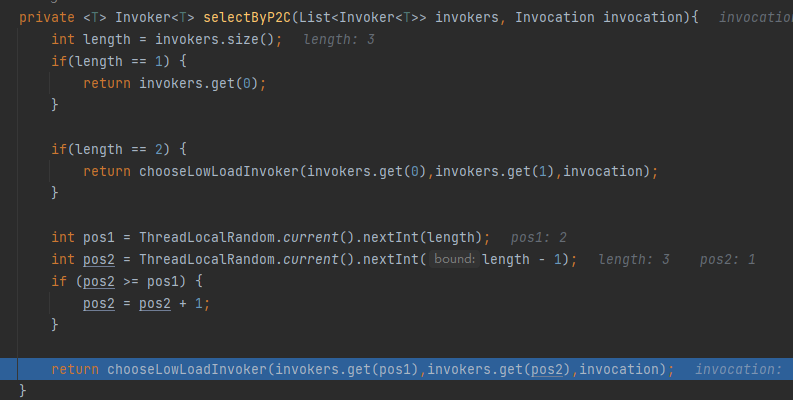
現在我們已經隨機選擇出了兩個 invoker 了,那麼應該由哪個 invoker 來執行這次的請求呢?
邏輯就來到了 chooseLowLoadInvoker 方法裡面。從方法名可以知道,是要選擇負載比較低的那個。
在這個方法裡面,有兩個關鍵變數,load1 和 load2:
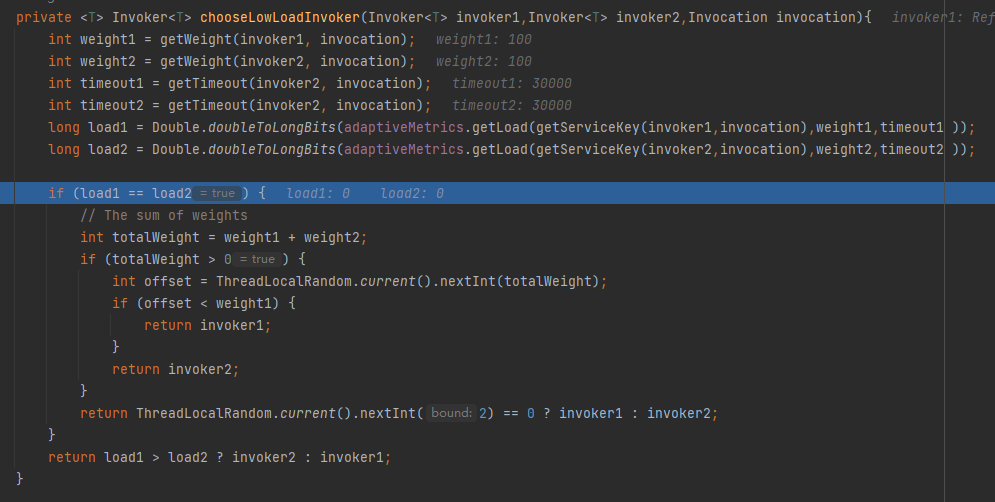
它們是經過某個公式計算出來的。
我們先看簡單的情況,當 load1 和 load2 一樣的時候,也就是說這兩個 invoker 都可以使用,則按照權重選擇一個。
當 load1 和 load2 不一樣的時候,則選 load 值比較小的。
所以接下來的問題就變成了:如何計算 load 的值?
原始碼都在這個方法裡面:
org.apache.dubbo.rpc.AdaptiveMetrics#getLoad
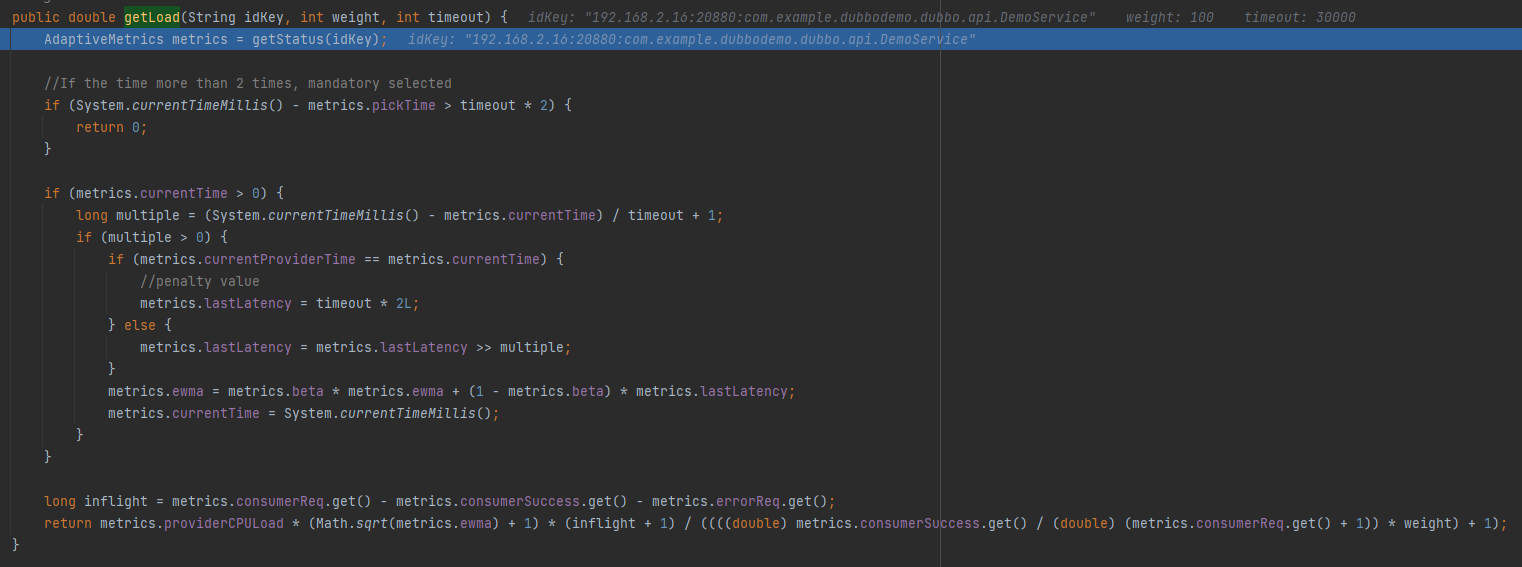
首先 getStatus 方法是獲取一個 AdaptiveMetrics 物件。這個物件裡面有一個 ConcurrentHashMap,內容是這樣的:

以「ip:埠:方法」為 key, value 裡面放了很多計算負載相關的欄位:
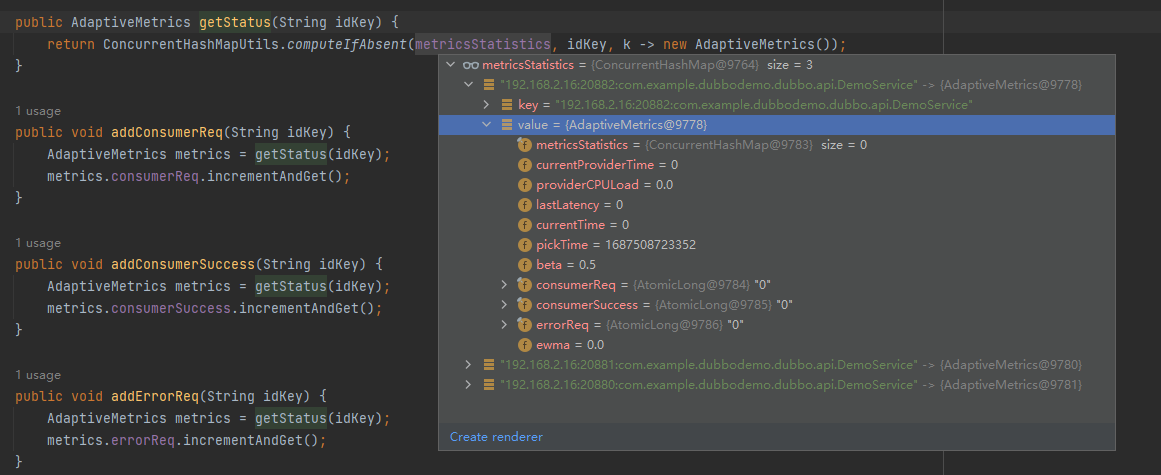
比如其中的 pickTime 欄位,在計算負載的時候,第一個用到的就是它:
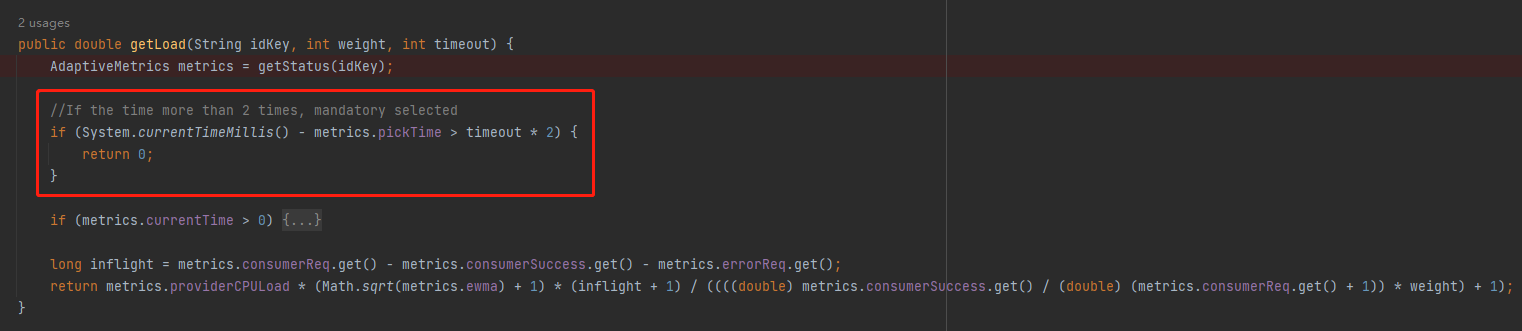
當前時間減去 pickTime 時間,如果差值超過超時時間的兩倍,則直接選中它。
假設超時時間是 5s,那麼當這個伺服器端距離上次被選中的時間超過 10s,則返回 0,既表示無負載。
那麼這個 pickTime 是什麼時候設定的呢?
就是在 doSelect 方法裡面經過 selectByP2C 方法選擇出一個伺服器端之後,在前面提到的 ConcurrentHashMap 中維護了 pickTime:
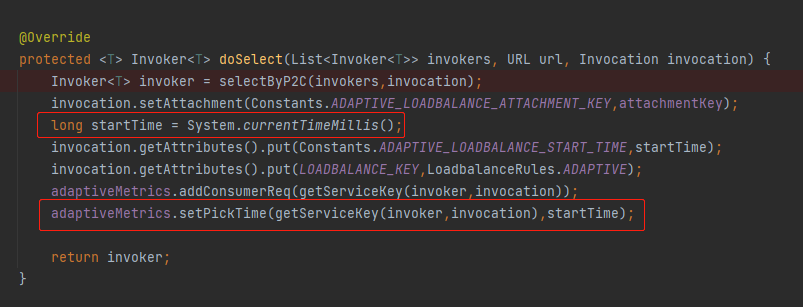
同時,在這裡還在上下文中維護了一個 startTime,表示這個請求開始執行的時間:
它是在什麼時候用的呢?
這個時候就要把目光放到 AdaptiveLoadBalanceFilter 這個類上了:
org.apache.dubbo.rpc.filter.AdaptiveLoadBalanceFilter#onResponse
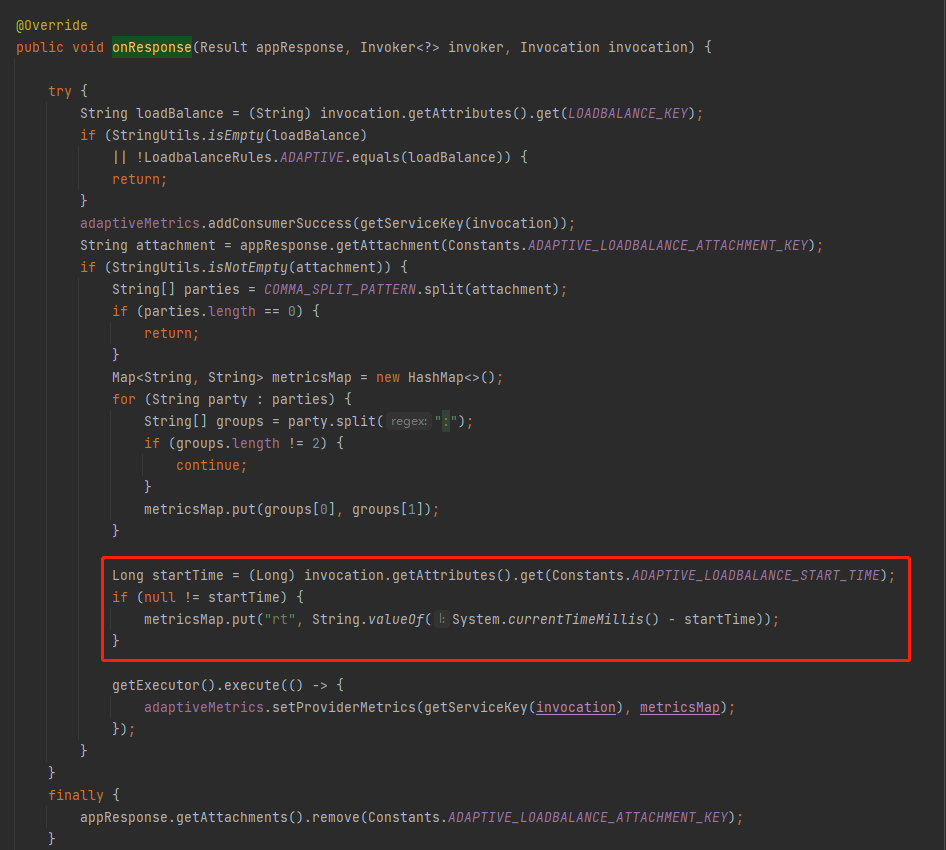
在 AdaptiveLoadBalanceFilter 裡面的 onResponse 方法裡面,當收到伺服器端的響應之後,在這裡取出了 startTime 用來計算 rt 值。
同時在這裡還維護了 AdaptiveMetrics 的 consumerSuccess(請求成功)、errorReq(請求失敗)這兩個屬性:
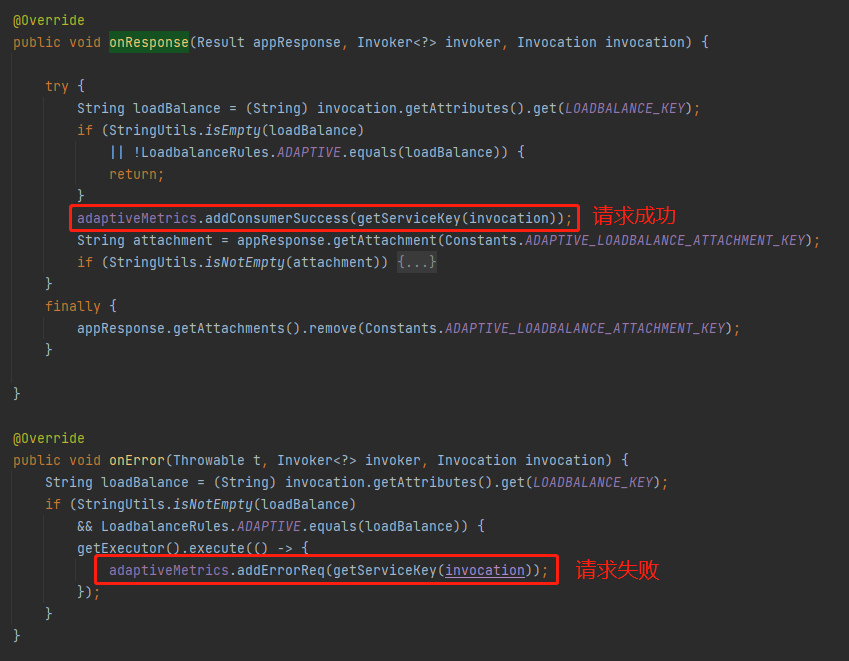
然後,我們還可以看到有這樣的一部分程式碼:
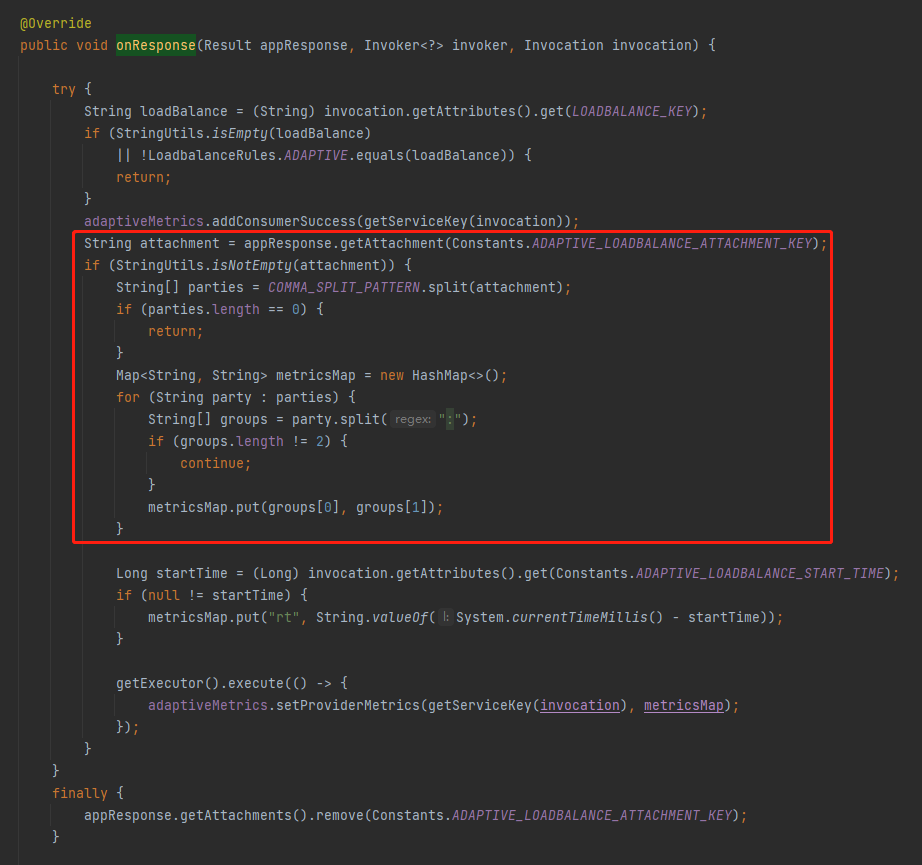
這部分程式碼是在對 ADAPTIVE_LOADBALANCE_ATTACHMENT_KEY 這個欄位進行處理。
那麼這是個啥玩意呢?
我也不知道,但是我知道它也是在 AdaptiveLoadBalance 的 doSelect 方法裡面進行了一次維護:
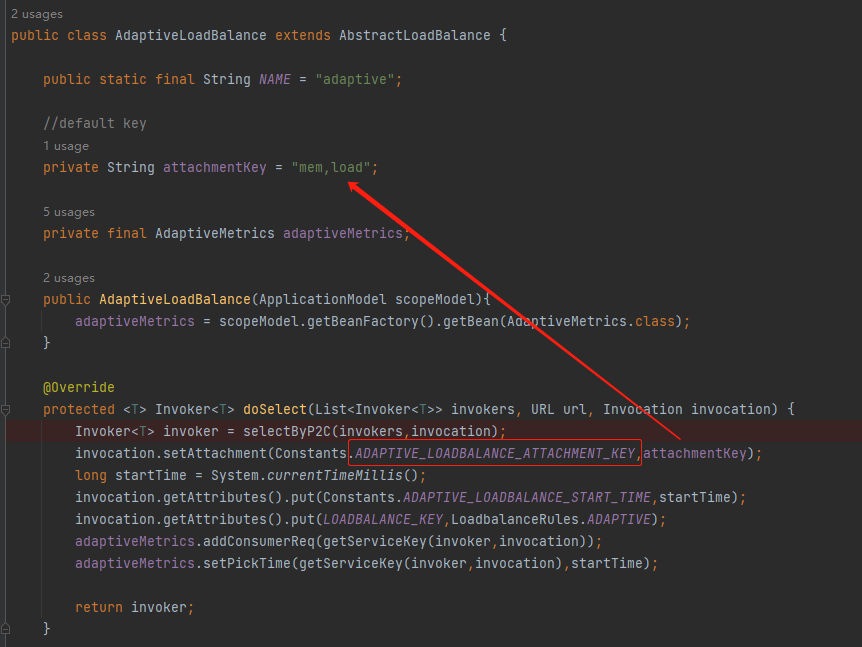
塞進去的值是:
private String attachmentKey = "mem,load";
看樣子是要對記憶體和負載這兩個維度進行統計。
首先,我問你,統計是站在誰的維度統計?
是不是要統計伺服器端的 mem 和 load?
所以,這裡的含義是使用者端告訴伺服器端:我這邊需要 mem,load 這兩個維度,你一會給我送回來。
那麼伺服器端是怎麼感知到的呢?
那我們就要把目光切換到 ProfilerServerFilter 這個 Filter 了:
org.apache.dubbo.rpc.filter.ProfilerServerFilter#onResponse
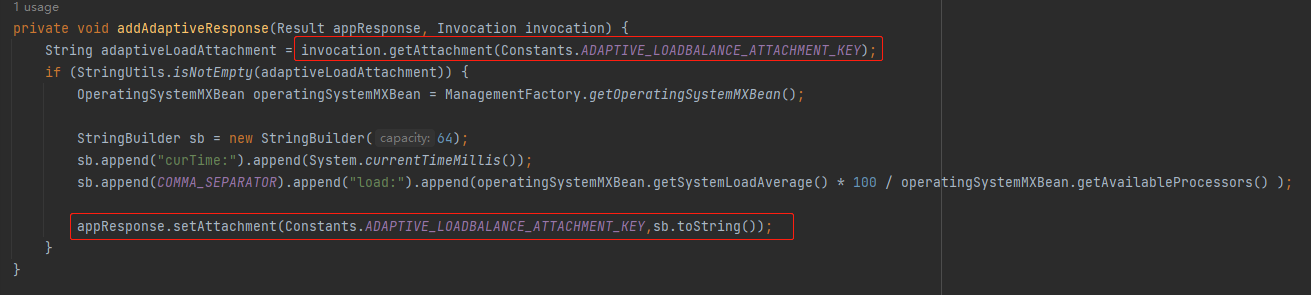
在這裡我們可以看到,它從上下文中取出了 ADAPTIVE_LOADBALANCE_ATTACHMENT_KEY 變數,判斷是否為空。
如果不為空則搞點事情,然後再重新給這個變數賦值。
那麼問題就來了:這個地方並沒有對所謂的 mem,load 進行任何處理,只是進行了非空判斷,然後就自己 new 了一個 StringBuilder,拼接了 curTime 和 load 屬性。
和 mem 沒有任何關係?
是的,沒有任何關係。
甚至和 load 都沒有任何關係,只要 ADAPTIVE_LOADBALANCE_ATTACHMENT_KEY 不是空就行。
但是你不能說這是 BUG,這算是個 features 吧。
好,經過前面的分析,我們回到這個地方:
org.apache.dubbo.rpc.filter.AdaptiveLoadBalanceFilter#onResponse
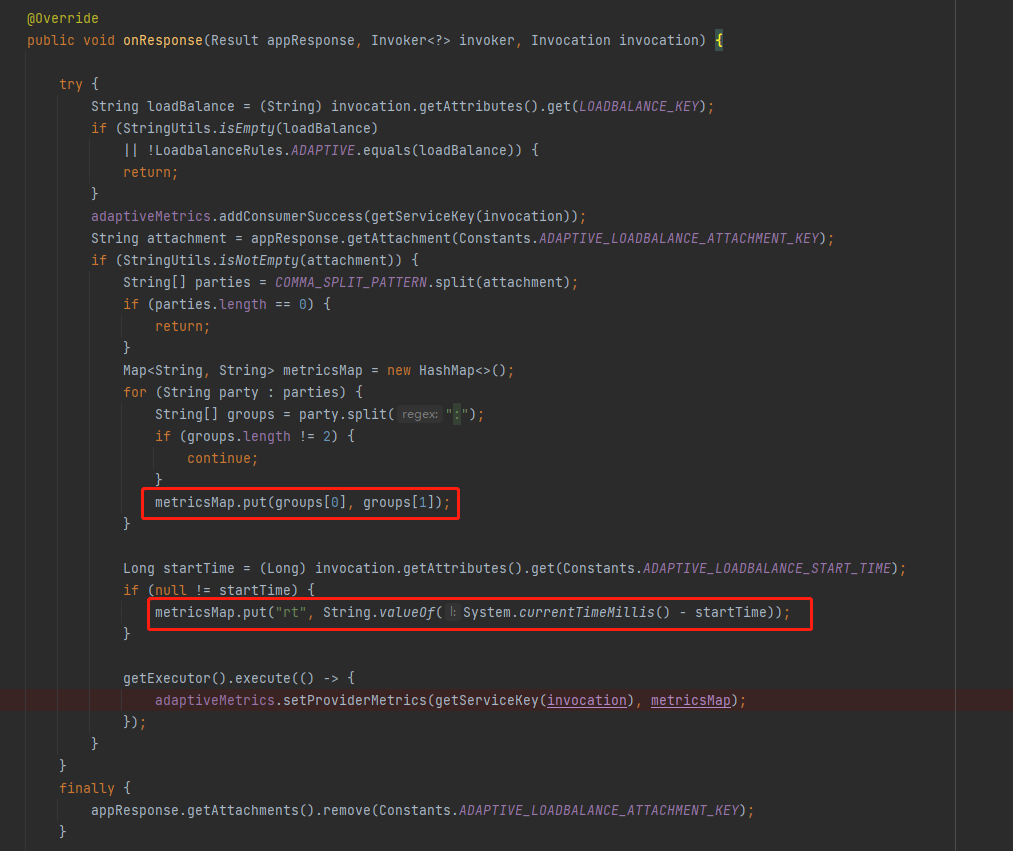
來,你告訴我,這個 metricsMap 裡面裝得是什麼?
是不是隻有 curTime、load、rt 這三個屬性。
巧了,在 AdaptiveMetrics 的 setProviderMetrics 方法中,也只是用(寫)到(死)了這三個值,用於給其他欄位賦值:
org.apache.dubbo.rpc.AdaptiveMetrics#setProviderMetrics
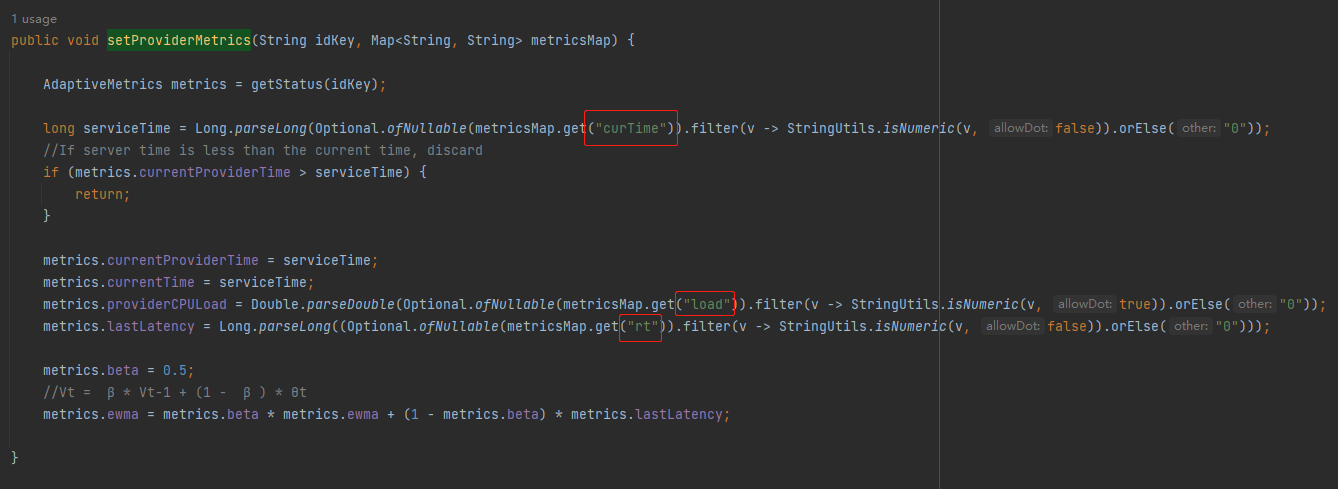
然後你注意看最後兩行:
Vt = β * Vt-1 + (1 - β ) * θt
這是什麼東西?
公式?我當然知道這是一個公式了。
我是問你這是一個什麼公式?
第一次看到的時候我也是懵的,我也不知道,所以我查了一下,這是指數加權平均(exponentially weighted moving average),簡稱 EWMA,可以用來估計變數的區域性均值,使得變數的更新與一段時間內的歷史取值有關。

我試圖去理解它,我也大概知道它是什麼東西,但是你讓我給你說出來,抱歉,超綱了。

好,最後回到計算 load 值的這個地方:
org.apache.dubbo.rpc.AdaptiveMetrics#getLoad
最後一行程式碼是這樣的:
return metrics.providerCPULoad * (Math.sqrt(metrics.ewma) + 1) * (inflight + 1) / ((((double) metrics.consumerSuccess.get() / (double) (metrics.consumerReq.get() + 1)) * weight) + 1);
雖然一眼望去眼睛疼,但是我還是給你解釋一下每個變數的含義:
- providerCPULoad:是在 ProfilerServerFilter 的 onResponse 方法中經過計算得到的 cpu load。
- ewma:是在 setProviderMetrics 方法裡面維護的,其中 lastLatency 是在 ProfilerServerFilter 的 onResponse 方法中經過計算得到的 rt 值。
- inflight:是當前服務提供方正在處理中的請求個數。
- consumerSuccess:是在每次呼叫成功後在 AdaptiveLoadBalanceFilter 的 onResponse 方法中維護的值。
- consumerReq:是總的呼叫次數。
- weight:是服務提供方設定的權重。
以上這些變數帶入到上面的公式中,就能獲取到一個 load 值。
每個服務提供方經過上面的計算都會得到一個 load 值,其值越低代表越其負載越低。請求就應該發到負載低的機器上去。
因為這個 load 值,是實時計算出來的,反應的是當前伺服器的處理能力。
而負載均衡策略在選擇的時候,通過 load 值來決策是否應該選中這個服務提供方。
所以,這就是自適應負載均衡。
有的同學就會問了:既然可以實時計算 load 值,那麼為什麼不把所有的服務提供者的 load 都計算出來,然後選擇最小的呢?
很簡單,因為隨機選擇兩個出來比較對應的時間是可控的,在常數時間內。但是如果你要把所有的服務提供者都計算一遍,那麼耗時就和服務提供者的數量成正比了。
P2C,穩當的,放心。
自適應限流
前面聊了自適應負載均衡,但是還在站在服務呼叫方的角度來說的。
服務呼叫方來決定本次由哪個服務提供方來執行這次請求。
那麼問題就來了:你服務呼叫方憑什麼說啥就是啥?我服務提供方不服氣。
假設現在所有的服務提供方的 load 值都很高了。我 P2C 出來兩個,一個負載是 100,一個負載是 99。
按理來說,這個時候不應該把請求再給到服務方了。但是呼叫方可不管這些事情,一個勁的給就行了,邊給邊說:成長,一定是伴隨著痛苦的...

所以,出於保護自己的原則,伺服器端應該有權在自己快 hold 不住的時候,拒絕呼叫端發來的請求。
但是到底應該在什麼時候去拒絕請求呢?
這個不好說,應該是一個隨著服務能力變化而變化的一個東西。
基於此,Dubbo 也提出了自適應限流的措施:
https://cn.dubbo.apache.org/zh-cn/overview/reference/proposals/heuristic-flow-control/#自適應限流
從理論上講,伺服器端機器的處理能力是存在上限的,對於一臺伺服器端機器,當短時間內出現大量的請求呼叫時,會導致處理不及時的請求積壓,使機器過載。在這種情況下可能導致兩個問題:
- 由於請求積壓,最終所有的請求都必須等待較長時間才能被處理,從而使整個服務癱瘓。
- 伺服器端機器長時間的過載可能有宕機的風險。


這玩意就更復雜了,我看了一下對應的 pr,目前還處於 open 狀態:
看得我腦殼疼,在這裡指個路,有興趣的可以自己去研究一下。
另外,可以結合著這個賽題看。
https://tianchi.aliyun.com/competition/entrance/531923/introduction

能看明白更好,看不明白的話,學到一個看起來很牛逼的詞也不錯的:柔性叢集排程。