解放計算力:使用並行處理提升python for迴圈速度
Python 是一門功能強大的程式語言,但在處理大規模資料或複雜計算任務時,效能可能成為一個瓶頸。幸運的是,Python 提供了多種方法來提升效能,其中之一是利用並行處理來加速回圈操作。本文將介紹如何使用並行處理技術來優化 for 迴圈,從而提高 Python 程式的執行速度。我們將討論並行處理的概念、常用的並行處理庫以及範例程式碼來演示如何應用並行處理來加速 for 迴圈。
一、什麼是並行處理
在電腦科學中,"並行處理" 是指同時執行多個任務或操作的技術。它利用多個處理單元或執行緒來並行執行任務,從而提高程式的執行速度。在 Python 中,我們可以利用多執行緒、多程序或非同步程式設計等技術來實現並行處理。
二、常用的並行處理庫
Python 提供了多個並行處理庫,其中一些常用的庫包括:
- multiprocessing:這個內建庫提供了跨平臺的多程序支援,可以使用多個程序並行執行任務。
- threading:這個內建庫提供了多執行緒支援,可以在同一程序內使用多個執行緒並行執行任務。
- concurrent.futures:這個標準庫提供了高階的並行處理介面,可以使用執行緒池或程序池來管理並行任務的執行。
- joblib:這是一個流行的第三方庫,提供了簡單的介面來並行執行 for 迴圈,尤其適用於科學計算和機器學習任務。
- dask:這是一個靈活的第三方庫,提供了並行處理和分散式計算的功能,適用於處理大規模資料集。
在本文中,我們將重點關注 multiprocessing 和 joblib 這兩個庫來進行示範。
三、並行處理 for 迴圈的範例程式碼
為了演示如何使用並行處理技術來加速 for 迴圈,我們將採用一個簡單的範例場景:計算一個列表中每個元素的平方值,並將結果儲存在新的列表中。
使用 multiprocessing 進行並行處理
import time
import multiprocessing
def square(num):
time.sleep(1) # 模擬耗時的計算操作
return num ** 2
if __name__ == '__main__':
numbers = [1, 2, 3, 4, 5, 6, 7, 8, 9, 10]
# 普通的 for 迴圈
start_time = time.time()
results = []
for num in numbers:
results.append(square(num))
end_time = time.time()
print("普通的 for 迴圈時間:", end_time - start_time)
# 並行處理
start_time = time.time()
pool = multiprocessing.Pool()
results = pool.map(square, numbers)
pool.close()
pool.join()
end_time = time.time()
print("並行處理時間:", end_time - start_time)
在上述程式碼中,我們定義了一個 square 函數,用於計算給定數位的平方。然後,我們建立了一個 multiprocessing.Pool 物件,它管理了一個程序池。通過呼叫 pool.map 方法,我們將 square 函數應用到 numbers 列表的每個元素上,並使用多個程序並行執行。最後,我們獲得了計算結果並列印輸出。
輸出效果:

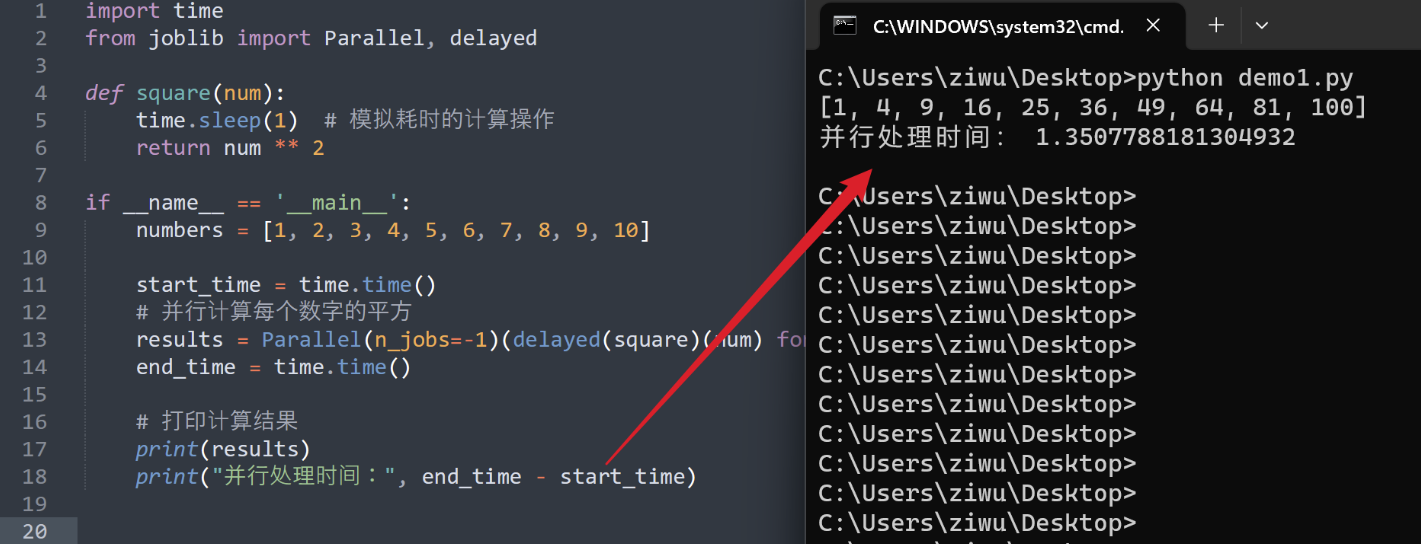
使用 joblib 進行並行處理
import time
from joblib import Parallel, delayed
def square(num):
time.sleep(1) # 模擬耗時的計算操作
return num ** 2
if __name__ == '__main__':
numbers = [1, 2, 3, 4, 5, 6, 7, 8, 9, 10]
start_time = time.time()
# 平行計算每個數位的平方
results = Parallel(n_jobs=-1)(delayed(square)(num) for num in numbers)
end_time = time.time()
# 列印計算結果
print(results)
print("並行處理時間:", end_time - start_time)
在上述程式碼中,我們使用了 joblib 庫的 Parallel 函數和 delayed 裝飾器。通過將 square 函數應用到 numbers 列表的每個元素上,我們可以使用多個執行緒或程序來並行執行計算。n_jobs=-1 表示使用所有可用的處理器核心。
輸出效果:
四、總結
本文介紹瞭如何利用並行處理技術來優化 Python 中的 for 迴圈,從而提高程式的執行速度。我們討論了並行處理的概念,介紹了常用的並行處理庫,以及展示了使用 multiprocessing 和 joblib 庫進行並行處理的範例程式碼。通過並行處理,我們可以充分利用多核處理器和多執行緒/程序的優勢,加速程式的執行並提升效率。然而,在使用並行處理時,需要注意避免共用資源的競爭和處理器負載的平衡,以免引入額外的複雜性。因此,在實際應用中,需要根據具體情況選擇合適的並行處理方案。希望本文能夠幫助你理解並行處理的概念和應用,並在需要優化 Python 程式效能時提供有益的指導。