C++面試八股文:override和finial關鍵字有什麼作用?
某日二師兄參加XXX科技公司的C++工程師開發崗位第22面: (二師兄好苦逼,節假日還在面試。。。)
面試官:C++的繼承瞭解嗎?
二師兄:(不好意思,你面到我的強項了。。)瞭解一些。
面試官:什麼是虛擬函式,為什麼需要虛擬函式?
二師兄:虛擬函式允許在基礎類別中定義一個函數,然後在派生類中進行重寫(
override)。二師兄:主要是為了實現物件導向中的三大特性之一多型。多型允許在子類中重寫父類別的虛擬函式,同樣的函數在子類和父類別實現不同的形態,簡稱為多型。
面試官:你知道
override和finial關鍵字的作用嗎?二師兄:
override關鍵字告訴編譯器,這個函數一定會重寫父類別的虛擬函式,如果父類別沒有這個虛擬函式,則無法通過編譯。此關鍵字可省略,但不建議省略。二師兄:
finial關鍵字告訴編譯器,這個函數到此為止,如果後續有類繼承當前類,也不能再重寫此函數。二師兄:這兩個關鍵字都是C++11引入的,為了提升C++物件導向編碼的安全性。
面試官:你知道多型是怎麼實現的嗎?
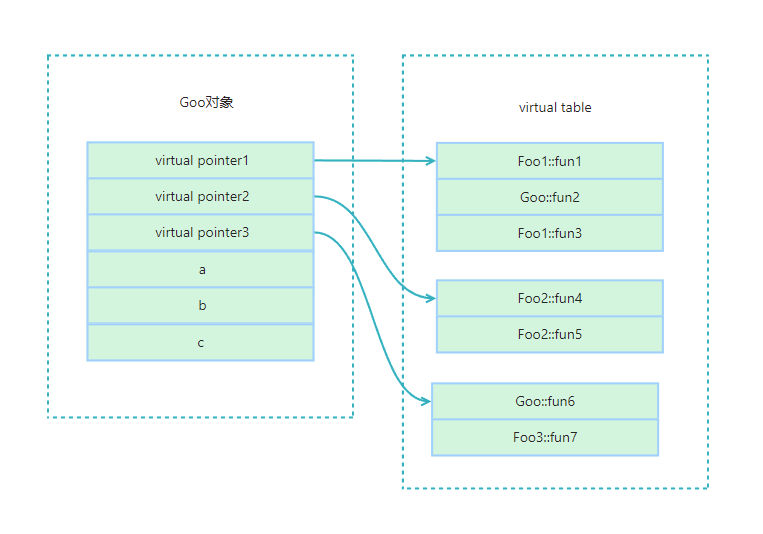
二師兄:(起開,我要開始裝逼了!)C++主要使用了虛指標和虛表來實現多型。在擁有虛擬函式的物件中,包含一個虛指標(
virtual pointer)(一般位於物件所在記憶體的起始位置),這個虛指標指向一個虛表(virtual table),虛表中記錄了虛擬函式的真實地址。
#include <iostream>
struct Foo
{
size_t a = 42;
virtual void fun1() {std::cout <<"Foo::fun1" << std::endl;}
virtual void fun2() {std::cout <<"Foo::fun2" << std::endl;}
virtual void fun3() {std::cout <<"Foo::fun3" << std::endl;}
};
struct Goo: Foo{
size_t b = 1024;
virtual void fun1() override {std::cout <<"Goo::fun1" << std::endl;}
virtual void fun3() override {std::cout <<"Goo::fun3" << std::endl;}
};
using PF = void(*)();
void test(Foo* pf)
{
size_t* virtual_point = (size_t*)pf;
PF* pf1 = (PF*)*virtual_point;
PF* pf2 = pf1 + 1; //偏移8位元組 到下一個指標 fun2
PF* pf3 = pf1 + 2; //偏移16位元組 到下下一個指標 fun3
(*pf1)(); //Foo::fun1 or Goo::fun1 取決於pf的真實型別
(*pf2)(); //Foo::fun2
(*pf3)(); //Foo::fun3 or Goo::fun3 取決於pf的真實型別
}
int main(int argc, char const *argv[])
{
Foo* fp = new Foo;
test(fp);
fp = new Goo;
test(fp);
size_t* virtual_point = (size_t*)fp;
size_t* ap = virtual_point + 1;
size_t* bp = virtual_point + 2;
std::cout << *ap << std::endl; //42
std::cout << *bp << std::endl; //1024
}

二師兄:當初始化虛表時,會把當前類override的函數地址寫到虛表中(
Goo::fun1、Goo::fun3),對於基礎類別中的虛擬函式但是派生類中沒有override,則會把基礎類別的函數地址寫到虛表中(Foo::fun2),在呼叫函數的時候,會通過虛指標轉到虛表,並根據虛擬函式的偏移得到真實函數地址,從而實現多型。面試官:不錯。上圖你畫出了單一繼承的記憶體佈局,那多繼承呢?
二師兄:多繼承記憶體佈局類似,只不過會多幾個
virtual pointer。
#include <iostream>
struct Foo1
{
size_t a = 42;
virtual void fun1() {std::cout <<"Foo1::fun1" << std::endl;}
virtual void fun2() {std::cout <<"Foo1::fun2" << std::endl;}
virtual void fun3() {std::cout <<"Foo1::fun3" << std::endl;}
};
struct Foo2{
size_t b = 1024;
virtual void fun4() {std::cout <<"Foo2::fun4" << std::endl;}
virtual void fun5() {std::cout <<"Foo2::fun5" << std::endl;}
};
struct Foo3{
size_t c = 0;
virtual void fun6() {std::cout <<"Foo3::fun1" << std::endl;}
virtual void fun7() {std::cout <<"Foo3::fun3" << std::endl;}
};
struct Goo: public Foo1, public Foo2, public Foo3
{
virtual void fun2() override {std::cout <<"Goo::fun2" << std::endl;}
virtual void fun6() override {std::cout <<"Goo::fun6" << std::endl;}
};
int main(int argc, char const *argv[])
{
Goo g;
g.fun1(); //Foo1::fun1
g.fun2(); //Goo::fun2
g.fun3(); //Foo1::fun3
g.fun4(); //Foo2::fun4
g.fun5(); //Foo2::fun5
g.fun6(); //Goo::fun6
g.fun7(); //Foo3::fun7
}
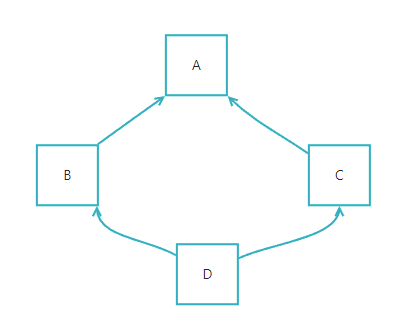
面試官:你知道什麼是菱形繼承嗎?菱形繼承會引發什麼問題?如何解決?
二師兄:菱形繼承(
Diamond Inheritance)是指在繼承層次結構中,如果兩個不同的子類B和C繼承自同一個父類別A,而又有一個類D同時繼承B和C,這種繼承關係被稱為菱形繼承。
二師兄:因為B和C各繼承了一份A,當D繼承B和C的時候就會有2份A;
#include <iostream>
struct A
{
int val = 42;
virtual void fun(){std::cout <<"A::fun" << std::endl;}
};
struct B: public A{ void fun() override{std::cout <<"B::fun" << std::endl;}};
struct C: public A{ void fun() override{std::cout <<"C::fun" << std::endl;}};
struct D: public B, public C{void fun() override{std::cout <<"D::fun" << std::endl;}};
int main(int argc, char const *argv[])
{
D d;
std::cout << d.val << std::endl; //編譯失敗,不知道呼叫從哪個類中繼承的val變數
d.fun(); //編譯失敗,不知道呼叫從哪個類中繼承的fun函數
}
二師兄:解決的辦法有兩種,一種是在呼叫符之前加上父類別限定符:
std::cout << d.B::val << std::endl; //42
d.C::fun(); //C::fun
二師兄:但這裡並沒有解決資料冗餘的問題,因為D中有B和C,而B和C各有一個虛表和一個int型別的成員變數,所以
sizeof(D)的大小是32(x86_64架構,考慮到記憶體對齊)。二師兄:所幸在C++11引入了虛繼承(
Virtual Inheritance)機制,從源頭上解決了這個問題:
#include <iostream>
struct A
{
int val = 42;
virtual void fun(){std::cout <<"A::fun" << std::endl;}
};
struct B: virtual public A{ void fun() override{std::cout <<"B::fun" << std::endl;}};
struct C: virtual public A{ void fun() override{std::cout <<"C::fun" << std::endl;}};
struct D: public B, public C{void fun() override{std::cout <<"D::fun" << std::endl;}};
int main(int argc, char const *argv[])
{
D d;
std::cout << d.val << std::endl; //42
d.fun(); //D::fun
}
二師兄:此時在物件
d中,只包含了一個val和兩個虛指標,成員變數的冗餘問題得到解決。面試官:一般我們認為多型會影響效能,你舉得為什麼影響效能?
二師兄:大多數人認為,虛擬函式的呼叫會先通過虛指標跳到虛擬函式表,然後通過偏移確定函數真實地址,再跳轉到地址執行,是間接呼叫導致了效能損失。
二師兄:但實際上無法內聯才是虛擬函式效能低於正常函數的主要原因。由於多型是執行時特徵,在編譯時編譯器並不知道指標指向的函數地址,所以無法被內聯。同時跳轉到特定地址執行函數可能引發的
L1 cache miss(空間區域性性不好),這也會影響效能。面試官:虛擬函式的呼叫一定是非內聯的嗎?
二師兄:不是。現代編譯器很聰明,如果編譯器能夠在編譯時推斷出真實的函數,可能會直接內聯這個虛擬函式。虛擬函式的呼叫是否內聯取決於編譯器的實現和上下文。
面試官:你覺得多型在安全性上有沒有什麼問題?
二師兄:的確是有的。當我們把類中的虛擬函式定義為
private的時候,雖然我們不能通過類的物件去存取這個函數,但我們知道這個函數就在虛擬函式表中,可以通過特殊的方法(上文中已經給出範例)存取它:
#include <iostream>
struct Foo
{
private:
virtual void fun() {std::cout << "Foo::fun" << std::endl;}
};
int main(int argc, char const *argv[])
{
Foo f;
//f.fun(); //編譯錯誤
using Fun = void(*)();
size_t* virtual_point = (size_t*)&f;
Fun* fun = (Fun*)*virtual_point;
(*fun)();
}
面試官:好的,今天的面試到這裡就結束了,請回去等通知吧。
今天二師兄表現很不錯,加個肉粽。感謝小夥伴的耐心閱讀,祝各位小夥伴端午節牛逼(端午快樂->沒文化,端午安康->跟風狗,好吧我祝各位端午牛逼)。二師兄的C++面試之旅,明天不見不散
關注我,帶你21天「精通」C++!(狗頭)