一致性hash演演算法原理及實踐
大家好,我是藍胖子,想起之前學演演算法的時候,常常只知表面,不得精髓,這個演演算法到底有哪些應用場景,如何應用在工作中,後來隨著工作的深入,一些不懂的問題才慢慢被抽絲剝繭分解出來。
今天我們就來看看工作和麵試中經常被點名的演演算法,一致性hash演演算法,並且我會介紹它在實際的應用場景並用程式碼實現出來。
本節的原始碼已經上傳到github
https://github.com/HobbyBear/codelearning/tree/master/consistenthash
原理介紹
首先我們來看看一致性hash的定義和演演算法思想,一致性hash演演算法有別於傳統hash演演算法,例如我們有3個節點,現在要考慮某個key值落到哪個節點上,傳統hash演演算法是將key通過hash函數後通過節點數量進行取模運算得到需要落到的節點序號。
nodeIdx := hashFunc(key)%len(nodes)
傳統hash演演算法在節點數量變化時基本上會導致大量舊資料經過hash得到的節點序號失效, 而一致性hash演演算法則能夠保證只有少部分舊資料需要重新改變需要落到的節點,其餘資料依然能夠保證節點擴容後,hash計算得到的節點序號和之前一致。
一致性hash演演算法假設了一個很大的數位空間,比如2的32次方, 節點資訊會被對映到這個數位空間的某個數位上,當我們需要看某個key落到哪個節點上時,也需要將key進行hash計算得到某個數位,接著就是找到在這個超大數位空間內,第一個大於該數位的節點。如果沒有大於該數位的節點,則將第一個節點作為key需要落到的節點。
這樣就等效於整個數位空間構成了一個環形結構,尋找key需要落到的節點上時,則是從key開始順時針尋找第一個節點。
用下面的示意圖來表示這個過程會更好理解

我們假設有3個節點A1,B1,C1, 這三個節點的資訊(比如主機名,ip等資訊)經過hash運算後得到了3個數位,A1對應10000,B1對應12000,C1 對應30000,現在需要看某個key需要落到哪個節點上,就應該這樣來看。
注意這裡的節點我是拿伺服器來舉例,實際上,節點也可以是表,某個key可以看出是表中的某一行,而一致性性hash演演算法的目的則是看某一行資料應該落到哪個表中,總之你可以發揮你的想象將演演算法中的事物進行代替抽象,演演算法的思想終究是不變的。
當某個key經過hash計算後,得到數位9000,那麼在順時針尋找到第一個大於它的節點則是節點A1,如果key經過hash計算後,得到數位11000,那麼尋找到的第一個大於它的節點則是節點B1。 注意一種特殊情況,如果key經過hash計算得到的數位是40000,那麼此時沒有任何一個節點是大於這個數位的,這種情況,正如上圖所示,一致性hash演演算法的陣列空間是環形結構,這樣key會落到第一個節點A1上。
這個只是最初版本的一致性hash,它會在節點數量較少時,出現分配資料不均勻的情況,比如可能會出現下面的場景

所有的節點都偏向了一側,這樣將會有大量資料落到A1 節點,造成資料分配不均勻。
所以一致性hash演演算法的改進版本提出虛擬節點的概念,通過引入節點的副本來讓整個hash環上的節點數量多起來。
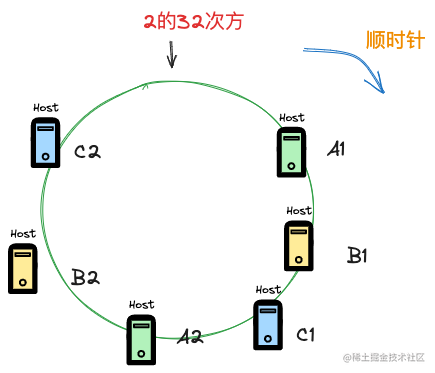
這裡假設引入的副本是一個,那麼參與分配的key的節點在hash環上則是6個,6個節點會讓對hash環的分配更加均勻,注意虛擬節點在實際環境中並不存在,比如這裡虛擬節點A2和實際的節點A1指向的其實都是同一個實際環境中的節點。
應用場景
在瞭解了一致性hash演演算法的原理後,我們再來看看它的一些適用場景,這樣能夠明白演演算法的目的,不至於紙上談兵。
負載均衡
首先來看下第一種應用場景,在負載均衡中的應用,拿memcache舉例,memcache的分散式架構其實是依賴使用者端來實現的,使用者端將快取key通過一致性hash演演算法計算需要快取到哪臺後端伺服器上。
而採用一致性hash的好處則是在擴縮容時,不會導致大面積的快取失效。

如上圖所示,現在要將D1節點下掉,由於一致性hash演演算法路由節點是順時針的,那麼只會影響到D1和A1之間的資料,這部分資料後續需要在B1節點上進行讀取,而其他節點上的資料則不會影響。
其實,從這裡應該能夠看出,一致性hash演演算法在負載均衡中一個極大的好處就是,對於有狀態的服務,能夠做到擴縮容節點時,影響面最小。
分庫分表
再來看看在分庫分表中的應用,如果分表時採用傳統hash演演算法,當還想擴容表時,不得不面對對所有分表資料進行重新hash,重新寫入,這無論是對於磁碟io還是cpu都有極大的壓力,我們應該在新增分表時儘量遷移少量的資料,減少影響面,這不正是一致性hash演演算法的功能嗎。

如上圖所示,現在新增了分表D1,那麼會影響到之前D1到A1的之前的資料,這部分資料之前是存到E1這張表上的,現在要遷移到D1表,所以你可以看到新增一個分表只會設計兩張表部分資料的遷移,相比傳統hash的全量遷移,優勢不言而喻。
程式碼實現
現在我們來看下如何實現下這個演演算法。
我們需要將節點資訊以及使用者key資訊對映成一個數位,這裡要用到hash函數,hash函數有很多,我們直接用一個,crc32的hash方式,這樣返回的數位剛好在2的32次方以內。
func ChecksumIEEE(data []byte) uint32
同時我們需要一個對映結構儲存節點在環上的hash key與節點資訊,還需要一個有序列表儲存hash key,以便於查詢使用者key對應的節點hash key是哪一個。
這裡的程式碼比較簡單,短短20多行即可。
package main
import (
"fmt"
"hash/crc32"
"sort")
func main() {
ch := NewConsistentHash(3)
ch.AddNodes("node1")
ch.AddNodes("node2")
ch.AddNodes("node3")
fmt.Println(ch.GetNode("lanpangzi"))
}
type ConsistentHash struct {
nodes map[uint32]string
keys []uint32
replicates int
}
func NewConsistentHash(replicate int) *ConsistentHash {
return &ConsistentHash{
nodes: make(map[uint32]string),
keys: make([]uint32, 0),
replicates: replicate,
}
}
func (c *ConsistentHash) AddNodes(node string) {
for i := 0; i <= c.replicates; i++ {
nodename := fmt.Sprintf("%s#%d", node, i)
hashKey := crc32.ChecksumIEEE([]byte(node))
c.nodes[hashKey] = nodename
c.keys = append(c.keys, hashKey)
}
sort.Slice(c.keys, func(i, j int) bool {
return c.keys[i] < c.keys[j]
})
}
func (c *ConsistentHash) GetNode(key string) string {
hashKey := crc32.ChecksumIEEE([]byte(key))
nodekeyIndex := sort.Search(len(c.keys), func(i int) bool {
return c.keys[i] >= hashKey
})
if nodekeyIndex == len(c.keys) {
nodekeyIndex = 0
}
return c.nodes[c.keys[nodekeyIndex]]
}
我們搞定了一致性hash演演算法,程式碼實現並不難,關鍵是要搞懂演演算法的原理以及作用,這樣才能靈活運用。