簡單瞭解一下國產GPU
2023-06-21 12:03:05

英偉達都一萬億市值了,國產GPU現在發展的怎麼樣了?萬字長文,有興趣的進來簡單瞭解一下。
最近,與GPU有關的幾個科技新聞:一是英偉達NVIDIA市值超過一萬億美元,成為全球第一家市值過萬億的晶片公司;二是位元組跳動今年向NVIDIA訂購了超過10億美元的GPU。
同時還有一個新聞,美國將浪潮列入所謂「實體清單」。浪潮是人工智慧伺服器的重要供應商,其市佔率多年位列全球前三、中國第一。列入實體清單,意味著無法獲得美國的先進晶片,影響國內大量下游公司,對我國人工智慧行業造成較大影響。而早在2022年8月31日,美國就已經禁止NVIDIA的A100、H100系列和AMD的MI 250系列及未來的高階GPU產品銷往中國。美國對中國人工智慧行業的打壓是不遺餘力的,我國雖然頂著一個「全球算力第二」的頭銜,但算力的基礎設施是很薄弱的。
上回聊過國產CPU,這次我們來簡單瞭解一下國產GPU。內容太多,或有紕漏之處,希望小夥伴多多包涵。
術語表、縮寫表
HPC: High Performance Computing,高效能運算。
PCIe: PCI-Express介面,可以簡單理解為GPU和CPU之間的介面。
Ray Tracing: 光追。該技術是NVIDIA在2018年推出的,它利用實時光線追蹤技術,可以更加真實地模擬光線在場景中的傳播和反射,從而提高了遊戲的視覺效果和真實感。
GPU: Graphics Processing Unit,圖形處理單元,俗稱顯示卡。
GPGPU: General-Purpose Graphics Processing Unit,通用圖形處理單元。GPGPU主要對海量資料的平行計算做了優化,使其更適合AI模型訓練等領域。
FPGA: Field Programmable Gate Array,現場可程式化門陣列,對於這種晶片,使用者可以用程式碼對物理電路進行修改(比如通過對部分線路載入超過負荷的電流使其熔斷,當然現在有多種更先進的方法來達成對同一塊硬體電路的多次程式設計)
ASIC: Application-Specific Integrated Circuit,專用積體電路,例如你可以設計一款ASIC晶片專門用於矩陣乘法。它和GPU的區別在於,GPU比它通用,例如可以進行圖片渲染等等。它和FPGA的區別在於,其硬體電路在出廠後無法修改。
OpenGL: Open Graphics Library,是一個跨平臺的圖形API,允許開發者在不同作業系統和硬體上建立高效能的圖形應用程式。
DirectX: 是微軟開發的多媒體API,允許開發者在Windows平臺上建立高效能的多媒體應用程式。
OpenCL: Open Computing Language,一種跨平臺的平行計算框架,允許開發者基於OpenCL所提供的介面開發平行計算程式並執行與指定的裝置(如GPU)上。
CUDA: Compute Unified Device Architecture,是NVIDIA的一種平行計算框架,與OpenCL類似,但OpenCL是跨平臺,而CUDA只能用於NVIDIA GPU。
影象渲染、計算加速
GPGPU、通用GPU、全功能GPU、圖形GPU、渲染GPU、GPU+、……,這幾年,冒出很多雲山霧罩的名詞。這裡我們簡單點,把GPU按用途劃分成兩類:
- 影象渲染:這部分就是傳統的顯示卡,主要服務於圖形影象、遊戲、視訊等方面。全球主要玩家是NVIDIA、AMD、Intel。Intel憑藉CPU優勢佔據整合顯示卡60%以上市場份額。而獨立顯示卡部分,最新的資料,NVIDIA佔據84%市場份額,AMD為12%。
- 計算加速:這部分相當於大算力晶片,主要服務於AI模型訓練和推理等新興的算力需求。全球主要玩家是NVIDIA、AMD。其中NVIDIA處於統治地位,市場份額超過97%。
影象渲染部分,經過了20年的演化,存在大量複雜演演算法和各種專利壁壘,同時它包含多種專用的硬體單元,如光柵處理單元、紋理單元、光線追蹤核心等,硬體結構複雜。這使得影象渲染GPU自研難度是比較高的,因此,國內專注於影象渲染GPU,尤其是消費級桌面GPU的晶片公司比較少。
計算加速部分,簡單解釋一下,GPU最早被用於影象渲染,主要的工作說白了就是不停的計算每一個畫素點的顏色和亮度等數值,這種型別的計算很適合並行處理,於是GPU就針對性地使用大量計算核心(現代CPU的核心數是4-16個,而GPU的核心數是數千個),使得它可以一次同時處理成百上千的畫素點,提高影象渲染的效率。後來,隨著AI模型訓練和推理的興起,人們發現這個過程中存在很多矩陣加法、乘法等可以並行處理的計算,也很適合使用GPU來計算,於是GPU開始被用於AI行業,並不斷的對它的計算能力進行加強,事實上形成了廣義GPU裡的一個新分支,也就是我們說的「計算加速GPU」。較之影象渲染GPU,在計算加速GPU方面,國內的公司相對多一些,畢竟AI正當紅。
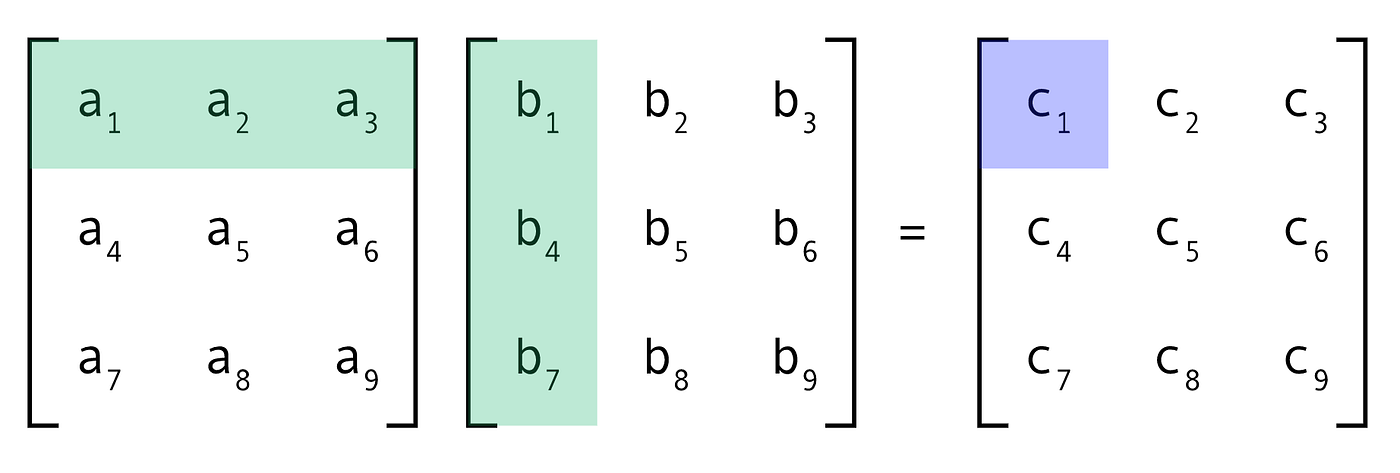
順便幫大家簡單複習一下矩陣運算,可以看到最終得到的結果中,每一個數值都是可以單獨計算的(c1=a1*b1+a2*b4+a3*b7,c2=a1*b2+a2*b5+a3*b8,……),互相沒有依賴,因此可以並行化處理。
圖形介面、顯示卡驅動
常見的圖形介面包括OpenGL、DirectX、Vulkan,其他的還有蘋果的Metal、AMD的Mantle、英特爾的One等。圖形介面,舉個例子,市面上有大量不同型號的顯示卡,每個顯得操作指令有可能都不一樣,這個時候,如果有一款遊戲需要建立一個2D或者3D的圖形,如何適配不同的顯示卡將成為一個大問題。因此遊戲和顯示卡之間的互動需要一個規範,而OpenGL、DirectX、Vulkan就是一種規範,有了這個規範,遊戲開發者只需要呼叫這些規範庫裡定義好的介面就行,不需要關注底層是哪種顯示卡。
我們說OpenGL、DirectX、Vulkan是一種規範,意味著它們並沒有提供真正的實現,真正功能的實現,則是在顯示卡廠商提供給你的驅動程式中。用程式設計師的話來比喻則是:OpenGL、DirectX、Vulkan相當於一個定義了一些介面,而顯示卡廠商提供驅動程式是對這些介面的實現,因此不同的顯示卡,才需要不同的驅動程式。
由於GPU除了傳統的影象渲染之外,還被用於計算加速,因此,除了圖形介面,我們還有計算加速相關的程式設計介面(或者說「框架」),比較有名的有OpenCL(Open Computing Language),一種跨平臺的平行計算框架,允許開發者基於OpenCL所提供的介面開發平行計算程式並執行與指定的裝置(如GPU)上。
另外一個是CUDA(Compute Unified Device Architecture),NVIDIA 2006年提出的一種平行計算框架,與OpenCL類似,但OpenCL是跨平臺,而CUDA只能用於NVIDIA GPU。CUDA是目前最廣泛使用的平行計算框架,畢竟NVIDIA在計算加速GPU上佔據絕對的霸主地位。下面的虛擬碼演示如何使用CUDA庫將某些特定的任務指定給GPU來完成。
t = troch.tensor([1,2,3]) // 該tensor是在CPU上建立的,對它的操作都將在CPU上進行 t = t.cuda() // 該tensor被轉移到GPU上,後續的操作都將在GPU上進行
同樣的,OpenCL、CUDA只是一個平行計算框架,真正與顯示卡的互動仍然需要藉助顯示卡驅動,所以,現代的顯示卡驅動,不僅要對OpenGL、DirectX、Vulkan這些影象相關的介面進行支援,還需要對OpenCL、CUDA這些與計算加速相關的介面的支援。可以看到,工作量轉移到了顯示卡驅動的開發了,所以顯示卡驅動的開發就越來越複雜困難,不信你問問隔壁英特爾。
不論CPU還是GPU,生態都很重要,二者的生態建設都是頂級難度,如果硬要比較的話,因為有現成的介面或者說框架,我個人覺得GPU的生態建設難度還是稍微的低一丟丟。影象渲染方面,基本上把主流的幾個影象相關的程式設計介面支援好就不錯了。計算加速方面,可以用OpenCL,但是目前AI領域基本上是NVIDIA CUDA所壟斷,也就是說各大廠在AI模型訓練上基本都是使用的CUDA庫,如果國產GPU想要這些大廠用你的顯示卡,通常有兩種方案,一種就是相容CUDA介面,這個是不容易的,尤其CUDA還在不斷更新中;還有一種是提供工具以便客戶可以直接將程式碼遷移到你的計算加速介面上,摩爾執行緒走的就是這個路子。
英偉達顯示卡
NVIDIA的顯示卡主要分為3類:
- GeForce:面向3D遊戲以及其他普通消費領域。主要品牌號有GTX、RTX。
- Quadro:面向專業圖形設計,如CAD等
- Tesla:面向計算加速,主要是AI領域
通常我們說NVIDIA的消費級顯示卡,是指的GeForce系列。先簡單介紹一下英偉達GeForce顯示卡的命名,這裡只說10系及之後的,更早的顯示卡型號挺混亂的,而且現在也很少有人提及了,這裡就不說了(主要是我也搞不清楚)。
首先,10系和16系品牌號都是GTX,而20系及以後都是RTX,因為從20系開始,NVIDIA給顯示卡增加了「光追 Ray Tracing」的特性,於是便以「R」打頭。
其次,在GTX/RTX之後,是4位元數位,比如 GTX 1060,這4位元數中前兩位是系列號,10就表示「10系」;後兩位表示效能等級,數位越大,表示效能越強。
- 10-40:低效能顯示卡,滿足基本的日常需求,俗稱「亮機卡」。
- 50 :中效能顯示卡,可以基本滿足當年主流遊戲以及主流應用。
- 60-90:高效能顯示卡,其中60俗稱「甜品卡」,也就是效能不錯,價格也不是太高,通常60賣的都比較好。

有些型號還在4位元數之後帶「Ti」或者「Super」標誌,可以看做是原來型號的加強版。
由於英偉達的消費級顯示卡常常被用來作為橫向比較的標杆,我整理了一個簡單的表格,列了一些GTX/RTX 10系及以後的顯示卡(主要是中效能卡和甜品卡),這樣大家對這些耳熟能詳的顯示卡的重要效能指標有一個整體的印象。主要資料來源是維基,一些型號有不同的版本,比如GTX 1050就有兩三個版本,沒辦法不一一列出,挑選了最早釋出的版本。
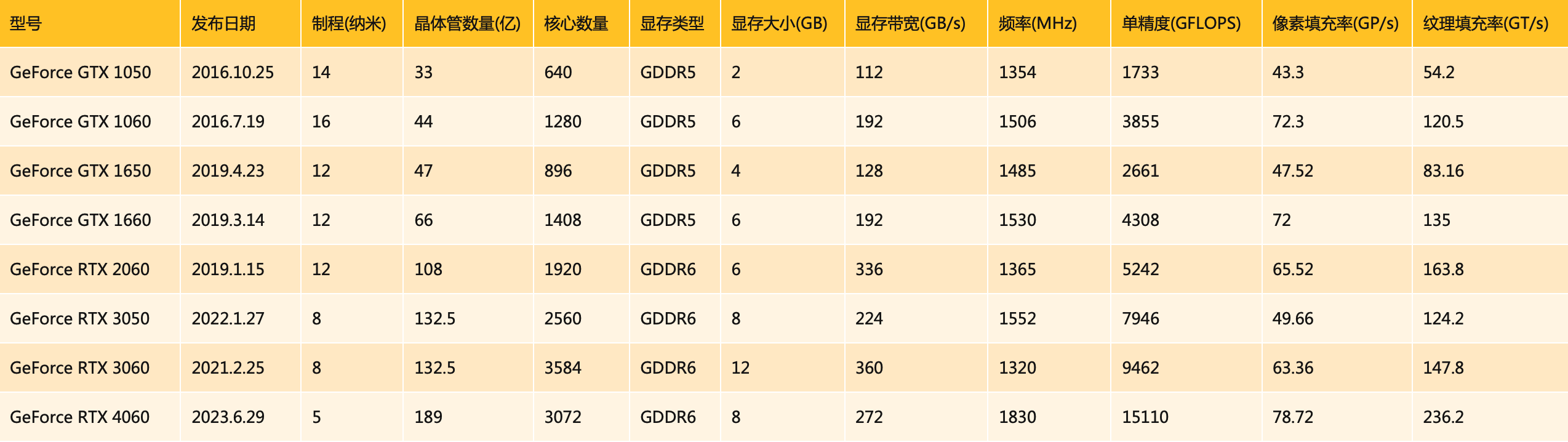
這裡的核心數量是指GPU晶片內整合的處理器數量,核心數量越多,處理效能越強。另外,單精度是指單精度浮點運算的效能,這是顯示卡計算效能的重要指標。其他像畫素填充率、紋理填充率則是與影象渲染效能相關的指標。
另外需要知道,像GTX 1650這樣的顯示卡,就已經能夠流暢地執行眼下幾乎所有的主流網路遊戲了。如果有哪一款國產GPU能在實測中達到與GTX 1650相當的水平,那絕對是了不起的成績。
國產GPU
相對於國產CPU,國內對GPU的重視程度相對較低,國產GPU起步更晚,與國際大廠差距很大。不過,最近幾年由AI以及高效能運算HPC帶來的算力需求增長,加上資本的投入,使得國內出現GPU的創業熱潮,不少GPU初創公司融資高達數10億元,同時也吸引了英偉達和AMD等國際廠商技術人才的加盟,進入了相對較快的發展期。當然,另外一個大家都知道的原因就是美國的科技打壓,導致許多硬體的供應鏈被切斷,其中當然也包括GPU,使得國內企業不得不走上了自主化道路。
景嘉微
景嘉微的技術核心團隊來自於國防科技大學,依靠軍工業務圖形顯控模組晶片起家,後來轉型民用市場,2016年上市,是國內涉足GPU行業的老牌廠商,也是國內首家成功研製國產GPU晶片並實現大規模工程應用的企業。最早推出的JM5系列幫助我們國家的軍隊替換下了大量古老的ATI顯示卡,後續又推出了JM7系列、JM9系列。
其中JM9系的畫素填充率為32GP/s,單精度浮點效能為1.5TFLOPS,對照前面給出的NVIDIA顯示卡,硬體指標勉強可對標GTX 1050。關於景嘉微GPU的指標官網上都沒有給出,前面的是網上的資料,可能有不準確的地方,另外,我看京東上賣的JM9230,單精度效能只有1.2TFLOPS?
JM9系,這個顯示卡玩主流遊戲估計暫時是別想了,AI訓練相關的計算加速也不行(畢竟主要還是側重影象渲染),不過看網上實測視屏播放看著還可以,普遍反映是比JM7繫好很多,處於亮機卡水平,對於一款純自主研發的GPU來說,還是需要鼓勵一下的。對了,景嘉微目前也已被美國商務部列入「實體清單」,可以看做是一種肯定吧。
芯動科技
芯動科技是採用Imagination GPU授權,Imagination之前還給蘋果提供過GPU授權,該公司目前是中國資金控股。
芯動目前主要釋出了兩款顯示卡:
- 風華一號:「國內第一款4K高效能資料中心顯示卡GPU」(釋出會標題),分A型卡(單芯)、B型卡(雙芯)兩款,旗艦款B型卡單精度浮點效能為10TFLOPS、畫素填充率320GP/s。這個字面效能達到了RTX 2080的水平了。
- 風華二號:「國內第一款4K高效能資料中心顯示卡GPU」(釋出會標題),單精度浮點效能1.5TFLOPS、畫素填充率為48GP/s,單精度效能接近GTX 1050。
不過,風華二號的功耗是4~15瓦,再對比NVIDIA GTX動輒一兩百瓦的功耗,估計實測效能與GTX 1050的差距會比較大。據說風華三號也已經設計完成,屆時會增加光追Ray Tracing特性。
沐曦
沐曦於2020年9月成立於上海,其GPU團隊很多是前AMD的工程師,該公司的GPU主要面向的是計算加速。2023年,旗下曦思N100實現量產,這是一款面向雲端資料中心應用的人工智慧推理GPU,單卡算力達80TFLOPS(FP16)、160TOPS(INT8),對比一下,NVIDIA A100(目前全球主流的計算加速GPU)是312TFLOPS(FP16)和624TOPS(INT8)。
海光
海光在之前介紹CPU的時候也介紹過,除了CPU,海光也有GPU業務,主要是面向計算加速。旗下的深算一號DCU(Deep Computing Unit 深度計算器)據說可以達到NVIDIA A100 70%的效能水平。
前面說到了在計算加速方面,下游使用者主要就是圍繞這NVIDIA的CUDA來開發的,這也形成了生態壁壘。由於海光的很多授權(包括CPU指令集架構授權)都來自AMD,因此海光GPU採取了相容ROCm(ADM GPU的計算介面)的方式,不過ROCm與CUDA相似,CUDA使用者可以以較低代價進行遷移,在一定程度上克服CUDA的生態壁壘。
摩爾執行緒
摩爾執行緒無疑是目前國產顯示卡里最火的一家,沒有之一。它成立於2020年10月,創始人是原NVIDIA全球副總裁、中國區總經理張建中,核心建立團隊基本都來自NVIDIA。摩爾執行緒在影象渲染和計算加速兩個方向都有佈局。
到目前為止,摩爾執行緒釋出了面向數位辦公的桌面顯示卡MTT S10/S30/S50、第一款國產遊戲顯示卡MTT S80、針對資料中心的全功能MTT S2000/S3000。就在最近(2023.5.31),摩爾執行緒還發布了S70遊戲顯示卡,相當於是S80的弱化版。
S80顯示卡核心數量4096個,單精度浮點效能14.4TFLOPS,紙面指標可以說是相當不錯了,實測的話,在《CS:GO》《英雄聯盟》等主流網遊可以流暢執行(這兩天看新驅動上實測米哈遊的《星穹鐵道》也能流暢執行。話說這有一個摩爾執行緒MTT S80測試合集,有興趣的小夥伴可以看看)。目前其主要問題是在驅動的優化上,導致硬體的潛力沒有發揮出來,部分主流遊戲和一下基準測試還跑不了。摩爾執行緒的驅動也保持著較快的更新速度,不過驅動的優化工作不可能一蹴而就,需要時間。
計算加速部分,針對NVIDIA圍繞自家顯示卡的CUDA生態壁壘,摩爾執行緒開發了一套遷移工具,可以將使用CUDA語言開發的程式碼經過重新編譯之後執行在自己的MUSA的GPU上,也可以在一定程度上克服CUDA的生態壁壘。
壁仞科技
壁仞科技成立於2019年9月,主要面向計算加速,截至目前該公司總融資額超50億元。
2022年8月,壁仞科技正式釋出首款通用GPU晶片BR100,創下全球算力紀錄,16位元浮點算力達到1000T以上、8位元定點算力達到2000T以上,單晶片峰值算力達到PFLOPS級別。甚至與英偉達最新發布的 4nm 旗艦 H100 相比,BR100 的紙面效能資料也毫不遜色。2022年9月9日,全球權威AI基準評測MLPerf™ V2.1推理最新評測成績公佈,浪潮AI伺服器成功搭載國產GPU晶片廠商壁仞科技自研的高階通用GPU,在BERT和ResNet50兩項重要任務中取得了8卡和4卡整機的全球最佳效能。
不過在今年(2023)二月份,網傳壁仞裁員,普遍認為是壁仞使用的7納米高階製程受到臺積電斷供的重創。這個後續會如何發展還得再觀察,目前只能給壁仞說一句加油。
格蘭菲
格蘭菲早期是兆芯(兆芯,這個上一回介紹CPU的時候說過了)的子公司,後來獨立出來,專注GPU業務。格蘭菲目前最新的GPU型號是Arise-GT10C0,單精度效能1.5TFlops,畫素填充率48GP/s,主頻500Mhz,工藝28nm。單看單精度計算效能和畫素填充率接近GTX 1050的水準,紋理填充還高一些。不過實測據說只有GT 630的水平,那時NVIDIA 2012年的產品了。
Arise-GT10C0在網上也是被許多「懂王」斥為電子垃圾,不過我個人是覺得,有多少能力辦多少事,只要是踏實在做事就好,況且,3個饅頭能吃飽,前兩個就可以不吃?
天數智芯
天數智芯成立於2015年12月,面向計算加速,是國內首家GPGPU高階晶片及超級算力提供商。2021年3月,公司釋出了國內首款通用GPU——天垓100,單精度浮點計算效能37TFLOPS、半精度浮點計算效能147TFLOPS、整型計算效能295TOPS(NVIDIA A100分別為19.5TFLOPS、312TFLOPS、624TOPS)。
結語
對於影象渲染GPU,雖然國內有個別廠家的硬體引數看起來已經相當不錯了,但是需要指出的就是,硬體引數很重要,但不是唯一重要的,軟體生態尤其是顯示卡驅動,還需要一段時間好好打磨。目前從各類實測視屏看來,摩爾執行緒是進展比較快的,部分主流遊戲可以流暢執行了,驅動程式也在不斷更新中。
對於計算加速GPU,個人覺得其研發和生態建設難度要比消費級顯示卡要相對小一些(只是相對)。這個方向的GPU面臨的比較大的問題是美國對晶片製程的制裁,例如壁仞的計算加速晶片就受到了臺積電7納米斷供的影響,這屬於真正的卡脖子了。關於製程,目前官方的訊息是,2023年第一季,中芯國際14納米的良率達到80%以上,雖然距離臺積電的90%+還有差距,但是能達到80%以上的良率就意味著可以進行商業量產了,所以14納米的國產替代會比較展開。下一步是10納米,難度是比較高的,14納米的良率從60%提高到80%,中芯國際花了5-6年,10納米不知道要花多長時間,更不用說7納米及以下了。
有人肯定要說光刻機了,這個要分開看,首先是荷蘭ASML的EUV肯定是拿不到了,不過DUV目前還是賣的,我們可以先用著,且走且看。至於國產替代,目前訊息是90納米的光刻機已經過驗收了(?),這個還有比較長的路需要走。
眼下,作為一名科技愛好者,我抱持的是在比較充分了解一件事情的前提下,做到既不妄自尊大,避免每天被各種「震驚」、「突破」、「厲害了」所汙染;也不妄自菲薄,就好比貿易戰剛開始的時候,網上好多人就說美國別的不用,只要切斷我們和網際網路的幾個根伺服器我們就完蛋了,其實瞭解過DNS原理的小夥伴就知道這種說法很可笑。對於晶片,花點時間瞭解它,就會知道我們面臨的是工程問題,而不是底層物理原理的問題,就好比對方是一個30年經驗的老師傅,我們是個新人,他打磨的工件就是比我們打磨的好,這個沒有辦法,我們需要時間,加班加點練唄。

(歡迎掃描上圖二維條碼關注公眾號,可自動獲得ChatGPT存取地址(本人自己搭建的跳板,可免費使用))