微服務架構學習與思考(14):監控和可觀測性詳細介紹
一、APP故障小故事
在一個休息日的週六,你和朋友在公司附近逛街,突然,老闆來了一通電話:
-
老闆:小王,我們 APP 購物詳情頁面,怎麼突然存取不了,一直在那裡載入,出了什麼 bug,趕緊看看?
-
小王:好的,老闆,你等等,我馬上回來看看是咋回事。
丟下朋友,一路小跑,火花帶閃電,奔回辦公室,開機找 bug。
修好 bug 後,就應該思考一下,老闆是咋發現這種情況?為什麼他能先於我發現呢?有什麼好的手段處理這種情況,我能最先發現網站存取異常?然後抓緊處理。
這時,你可能想到了對網站進行監控,化被動為主動,主動去獲取 APP 異常資訊。不錯,這是一個很好的方法。
二、為什麼需要監控
從上面的小故事可以得到一些啟發,比如 APP 發生不能存取的異常情況時,相關人員能夠快速感知到異常情況的發生,先於使用者得到異常情況的資訊,能讓相關人員及時進行應急處理,減少損失。而不是等到多數使用者來報告異常情況才去處理,這時損失就變大了。
監控系統不僅可以監控上面提到的應用程式頁面存取異常,還可以監控其他頁面存取流量,API 呼叫情況,響應時間,請求頻率,錯誤率等等,這些都關乎業務整體執行情況。
對應用程式本身也可以進行監控,比如 APM(應用程式效能監控)監控,這樣遇到應用程式故障時,可以快速定位問題、處理問題。
還有當執行應用程式伺服器的 CPU、記憶體持續走高,磁碟儲存空間所剩不多等等各種異常情況,都需要監控來及時發現,並報給運維人員進行處理。
上面不管是業務存取異常,還是伺服器資源執行異常,還是 API 呼叫異常,程式出 bug 等各種異常情況,都需要及時發現並處理,目的是減少業務損失。
可以通過監控系統來及時發現異常情況,並通過系統記錄與異常相關聯的資訊,還原異常出現的現場環境,從而協助運維或研發人員快速定位問題,並及時處理異常情況。
三、監控作用總結
為什麼需要監控,除了上面說的作用外,下面對監控的作用做一些總結。(我理解的最大作用是:化被動為主動)
- 近實時瞭解業務執行的健康狀況
- 提前獲知業務異常情況資訊並告警通知
- 幫助定位各種異常、bug等故障
- 為排障提供詳細資訊
- 業務運營資訊的統計和監控
- 監控系統資源使用情況,保障系統穩定執行
- 對異常情況發出告警通知,及時進行處理
四、監控系統流程
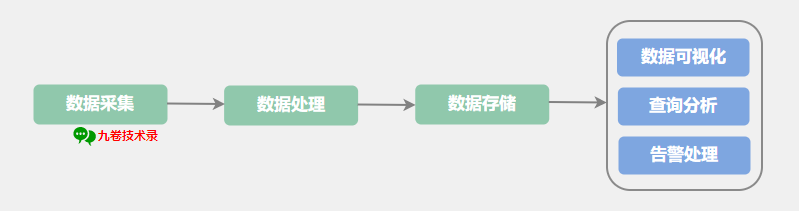
監控系統一般流程如下圖:
-
資料採集:
通過採集工具收集相關監控指標的資料,比如採集作業系統指標, CPU 使用率、記憶體使用率、TCP 連線數等等。常用的採集資料的方式有代理和埋點 2 種方式。
- 資料採集的軟體工具,有 Filebeat,Fluentd,Fluent Bit,LogStash,Promtai,Vector,Mtail,Flume 等等。
-
資料處理:
又可以叫資料計算處理,對採集到的原始資料進行各種緯度的計算處理,得到我們想要的一些監控指標資料。比如對於一些業務指標的計算,今天新增使用者的數、7 天新增使用者數、7 天某頁面的 UV 等等資料指標。
- 處理資料的工具有哪些?一般需要自己開發程式來進行資料處理,簡單的指標計算可以通過 SQL 來進行統計。資料量比較大統計實時性高,可以使用 storm,flink 等巨量資料計算框架來進行計算統計。
-
資料儲存:
這裡儲存有 3 層含義,第一個是對採集的原始資料進行儲存,第二個是對計算後的資料進行儲存。第三個是有時我們會對原始資料進行暫存處理,比如暫存在 kafka 中。
- 資料儲存軟體,資料暫存型的 kafka,關係型資料庫 MySQL、PostgrSQL,時序資料庫 InfluxDB、OpenTSDB、TimescaleDB,還有 Elasticsearch、MongoDB、ClickHouse、HBase、Hadoop 等等。
-
查詢分析、資料視覺化:
查詢分析對監控的指標進行檢視然後分析。資料視覺化,用圖形方式展示監控的指標。
- 一般都是需要開發人員進行程式開發。log 型的紀錄檔有 kibana 工具。
-
告警處理:
把系統發生的錯誤、異常資訊及時通知給研發、運維等相關人員,讓他們及時進行處理。告警通知方式多種多樣,有簡訊、IM、郵件、Slack等等方式。
- 有簡單的告警設定,比如 prometheus 裡的。複雜的告警處理就需要研發來進行相關開發。
五、監控類別分層和指標
按照架構分層分類
根據業務系統架構設計,把監控系統類別進行分層,一般可分為 4 層,如下簡圖:
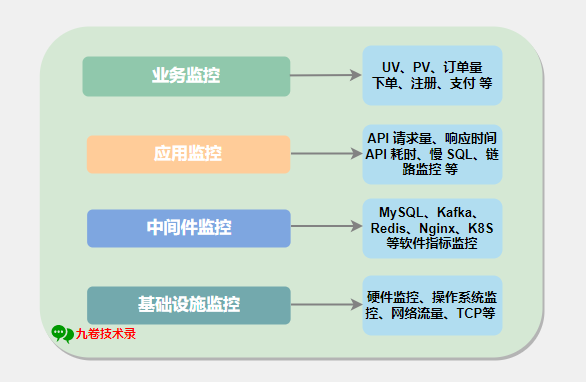
上面是一個比較大的監控分類,大的監控類別還可以在細分為一些小類和這些類別的一些監控指標,
業務監控:
這一層主要是對業務運營的指標和業務流程進行監控,隨時監控業務異常和 bug 狀況。
- 業務運營:日新增註冊使用者(7日,30日,當天等等),流失使用者數,活躍使用者數,每個頁面的 PV、UV,下單數量,支付數量、結算率 等等資料
- 業務異常資料:比如某個頁面存取異常統計,頁面 404,500 等統計
- 業務鏈路:業務鏈路中的關鍵節點,這些節點的健康情況、資料流向是否異常的監控
- 使用者體驗資料:頁面載入時間,互動響應時間等等,這些是前端監控資料的一部分
應用監控:
這一層主要是對應用程式執行情況進行監控,
-
API 監控:請求量、響應時間、耗時總長、超時比率,響應錯誤數、比率,比如 404,500 等統計
-
鏈路監控:API 請求之間的鏈路資訊,比如鏈路的響應時間,耗時等
-
應用程式監控:對應用程式的持續監控,continue profiling。比如應用程式本身使用的記憶體,CPU 數,哪部分程式使用比較高
中介軟體監控:
一些使用的軟體,比如 資料庫、Nginx、Redis、Kafka、K8S 等等軟體,這些軟體本身會給出一個介面,這個介面用來統計軟體自身的一些資訊,可以收集這些資訊,然後進行統計。還可以用產生的紀錄檔進行統計。
比如說 Redis 的命令 redis info 就會顯示 Redis 的很多資訊,可以摘出需要的資訊進行記錄統計。
這裡每一個軟體都可以進行獨立的記錄和統計。比如資料庫,
- 資料庫:資料庫連線數,QPS,主從延遲,慢查詢,鎖的一些資訊
基礎設施監控:
這裡的基礎設定包括一些硬體,比如交換機,物理磁碟,網路卡狀態。還包括作業系統,網路,虛擬機器器的監控
- 作業系統:CPU 使用率,記憶體使用情況,硬碟使用情況
- 網路:TCP 連線數、連線狀態,網路流入流出流量等網路指標
按照監控內容分類
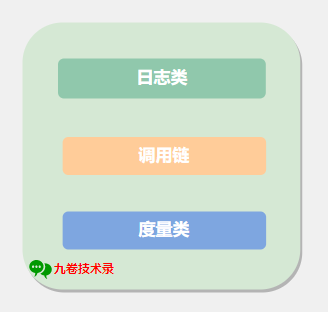
- 紀錄檔類
紀錄檔類就是指系統產生的紀錄檔資訊,程式碼裡記錄的一些程式執行資訊,還有一些業務級別上記錄的紀錄檔資訊,在帶上時間。
比如 Nginx 裡記錄的存取紀錄檔,應用記錄下使用者登入紀錄檔,使用者搜尋記錄紀錄檔,下單紀錄檔資料,這些都是與使用者做某件事情相關聯的紀錄檔資訊。
有助於我們進行一些指標統計,異常資訊查詢和分析,告警通知。
- 呼叫鏈
呼叫鏈一般是指程式 API 之間相互呼叫的一些資訊,端到端的存取路徑相關資訊,也叫鏈路追蹤。這些都是 APM 應用程式效能監控。
我前面有寫一篇關於 google 的 Dapper 鏈路追蹤文章,在這裡 https://www.cnblogs.com/jiujuan/p/16097314.html 。
- 度量類
度量類指的是記錄一串以時間為緯度的資料,然後通過聚合統計,來計算一些監控指標。用來描述一些指標資料和指標變化趨勢,可以用圖表來表示。
在可觀測性裡這個叫 metrics 。
上面 3 個分類其實跟可觀測性的 3 個指標有點類似,下面就講一講可觀測性的內容。
六、可觀測性Observability
什麼是可觀測性
維基上:
控制理論中的可觀察性(observability)是指系統可以由其外部輸出推斷其其內部狀態的程度。系統的可觀察性和可控制性是數學上對偶的概念。它與可控制性(Controllability)一起,是由匈牙利數學家 Rudolf E. Kálmán 提出。
IBM:
一般來說,可觀察性是指您僅根據所瞭解的外部輸出對複雜系統內部狀態或條件的理解程度。 系統的可觀察性越高,您就能越迅速、越準確地從發現的效能問題找到根本原因,而不必進行額外的測試或編碼。
- From:https://www.ibm.com/cn-zh/topics/observability IBM的可觀測性
CNCF:
可觀察性是系統的一種屬性,描述了系統可以從其外部輸出中被理解的程度。
比如通過 CPU 使用時間、記憶體使用、磁碟空間、延遲、系統執行的錯誤資訊等來衡量,計算機系統或多或少是可以被觀察到的狀況。聚合分析這些資料,您可以檢視這些可觀察的資料來了解系統的執行狀況。
IBM 的定義和維基的差不多。
可觀測性是對軟體的一種度量能力。軟體是一個複雜系統,怎麼知道它的執行狀況是否健康呢?怎麼從外部窺見軟體的執行狀況和異常情況呢?怎麼分析出現的異常呢?通過軟體內部產生的資料資訊(紀錄檔資訊、鏈路資訊、profilling 等等各種資訊)並輸出到外部,外部把這些資訊通過聚合、計算,用一定的形式組織起來,然後用列表、圖表形式展現出來,這樣我們就可以肉眼去檢視軟體系統各種緯度的情況、系統當前所處的狀態。
可觀測性就像一個顯微鏡,它仔細觀察軟體系統的各種指標和狀態,系統是否出現異常情況。
可觀測的三大支柱
可觀測性具體怎麼做?有哪些指標。
可觀測性一般有 3 個方向,分別是:事件紀錄檔、鏈路追蹤 和 聚合度量,這 3 個方向各有自己的重點,又不是完全獨立的,它們有重合的地方。
可以看看 Peter Bourgon 的一篇總結文章《Metrics, Tracing, and Logging》,裡面有一張很經典圖片描述了 3 者之間的關係,受到了業界普遍的關注:
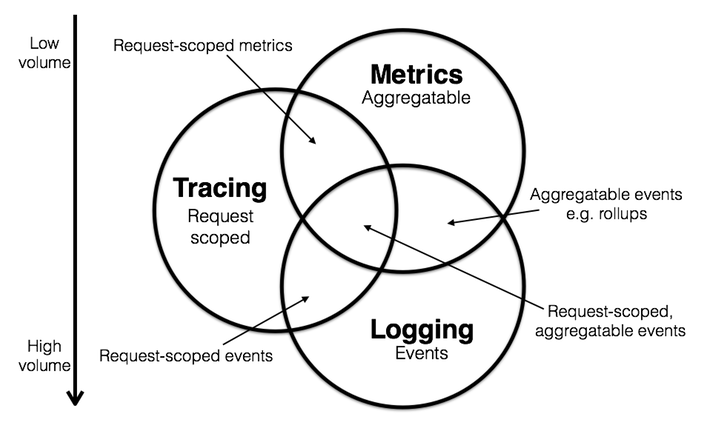
(圖片來源:《Metrics, Tracing, and Logging》)
指標(Metrics)、追蹤(Tracing)、紀錄檔(Logging),這是可觀測性的3個基本指標。
-
紀錄檔 logging
上面表示 Logging 是 events,它是特定時間發生離散事件的記錄。比如 Nginx 的存取紀錄檔記錄,每條紀錄檔記錄一般有存取時間戳、響應碼、頁面 URL、使用者端 IP 等資訊。還有程式也會記錄一些使用者存取資訊,比如下單記錄。
-
鏈路追蹤 Tracing
端到端請求範圍內的呼叫鏈路相關資訊。比如記錄每個請求階段的開始時間、時長等資訊。關於 google 的 Dapper 鏈路追蹤文章,我前面寫的 https://www.cnblogs.com/jiujuan/p/16097314.html 。
鏈路追蹤主要是為了排除故障,比如分析呼叫鏈中哪一部分用時比較長、哪個方法出錯了等等。
-
度量 Metrics
度量是對系統中某一類資訊的聚合計算。比如伺服器中 CPU 利用率、記憶體剩餘數,系統容量等等
七、監控和可觀測性的區別
監控是收集一組預定義的指標和紀錄檔,來幫助研發和運維觀察和了解系統執行狀態的工具,並提供解決方案。
可觀測性是事先未定義的屬性和模式來探索系統出現的問題,有效幫助研發或運維偵錯系統的工具。
上面是來自 google cloud 。
監控告訴你出了點問題,而可觀測性是告訴你哪裡出了點問題以及為什麼會發生。
監控是一種收集和分析從各個系統中提取的預定義資料,來解決系統中出現的問題。可觀測性是一種聚合所有 IT 系統產生的資料的來觀察、推演系統內部的狀態,並分析系統出現的問題以及為什麼出現這個問題。
可觀測性的定義範圍更廣,監控是可觀測性的一個子集。
監控和可觀測性之間的關係圖:
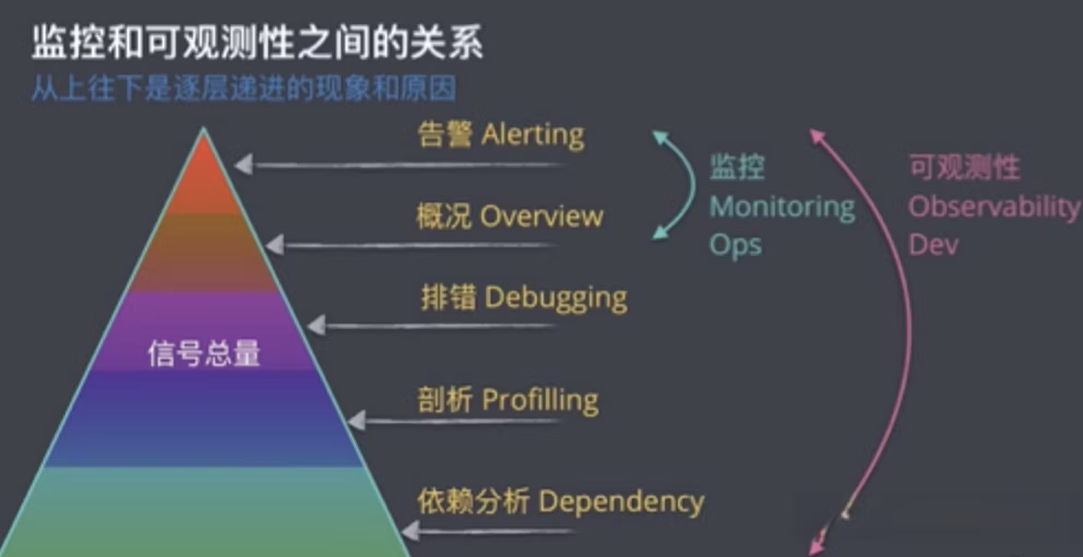
(來自:萬字破解雲原生可觀測性)
八、CNCF 中監控和可觀測性軟體工具
Monitoring監控工具
(來自:https://landscape.cncf.io/guide--monitoring)
上面最常用的應該是 prometheus + grafana 組合。
除了上面列出的外,還有一款監控系統 - 夜鶯監控(Nightingale),它是一款 ALL IN ONE 設計的監控系統。
Nightingale 夜鶯監控,一款先進的開源雲原生監控分析系統,採用 All-In-One 的設計,集資料採集、視覺化、監控告警、資料分析於一體,與雲原生生態緊密整合,提供開箱即用的企業級監控分析和告警能力。
github 地址:https://github.com/ccfos/nightingale 。
Logging紀錄檔工具

(來自:https://landscape.cncf.io/guide--logging)
上面最常用的應該是 ELK(elasticsearch、logstash、kinbana)
Tracing鏈路追蹤工具

(來自:https://landscape.cncf.io/guide--tracing)
上面常用的鏈路追蹤, jaeger,pinpoint,skywalking,zipkin,OpenTelemetry 等。
九、參考
- https://db-engines.com/en/system
- https://peter.bourgon.org/blog/2017/02/21/metrics-tracing-and-logging.html Peter Bourgon 的 Metrics, Tracing, and Logging
- https://cloud.google.com/architecture/devops/devops-measurement-monitoring-and-observability?hl=zh-cn 監控和可觀測性
- https://zhuanlan.zhihu.com/p/137672436 萬字破解雲原生可觀測性
- https://landscape.cncf.io/guide
- https://n9e.github.io/ 夜鶯監控