使用 InstructPix2Pix 對 Stable Diffusion 進行指令微調
本文主要探討如何使用指令微調的方法教會 Stable Diffusion 按照指令 PS 影象。這樣,我們 Stable Diffusion 就能聽得懂人話,並根據要求對輸入影象進行相應操作,如: 將輸入的自然影象卡通化 。
 |
|---|
| 圖 1:我們探索了 Stable Diffusion 的指令微調能力。這裡,我們使用不同的影象和提示對一個指令微調後的 Stable Diffusion 模型進行了測試。微調後的模型似乎能夠理解輸入中的影象操作指令。(建議放大並以彩色顯示,以獲得最佳視覺效果) |
InstructPix2Pix: Learning to Follow Image Editing Instructions 一文首次提出了這種教 Stable Diffusion 按照使用者指令 編輯 輸入影象的想法。本文我們將討論如何拓展 InstructPix2Pix 的訓練策略以使其能夠理解並執行更特定的指令任務,如影象翻譯 (如卡通化) 、底層影象處理 (如影象除雨) 等。本文接下來的部分安排如下:
你可在 此處 找到我們的程式碼、預訓練模型及資料集。
引言與動機
指令微調是一種有監督訓練方法,用於教授語言模型按照指令完成任務的能力。該方法最早由谷歌在 Fine-tuned Language Models Are Zero-Shot Learners (FLAN) 一文中提出。最近大家耳熟能詳的 Alpaca、FLAN V2 等工作都充分證明了指令微調對很多工都有助益。
下圖展示了指令微調的一種形式。在 FLAN V2 論文 中,作者在一個樣本集上對預訓練語言模型 (如 T5) 進行了微調,如下圖所示。
 |
|---|
| 圖 2: FLAN V2 示意圖 (摘自 FLAN V2 論文)。 |
使用這種方法,我們可以建立一個涵蓋多種不同任務的訓練集,並在此資料集上進行微調,因此指令微調可用於多工場景:
| 輸入 | 標籤 | 任務 |
|---|---|---|
| Predict the sentiment of the following sentence: 「The movie was pretty amazing. I could not turn around my eyes even for a second.」 |
Positive | Sentiment analysis / Sequence classification |
| Please answer the following question. What is the boiling point of Nitrogen? |
320.4F | Question answering |
| Translate the following English sentence into German: 「I have a cat.」 |
Ich habe eine Katze. | Machine translation |
| … | … | … |
在該理念的指導下,FLAN V2 的作者對含有數千個任務的混合資料集進行了指令微調,以達成對未見任務的零樣本泛化:
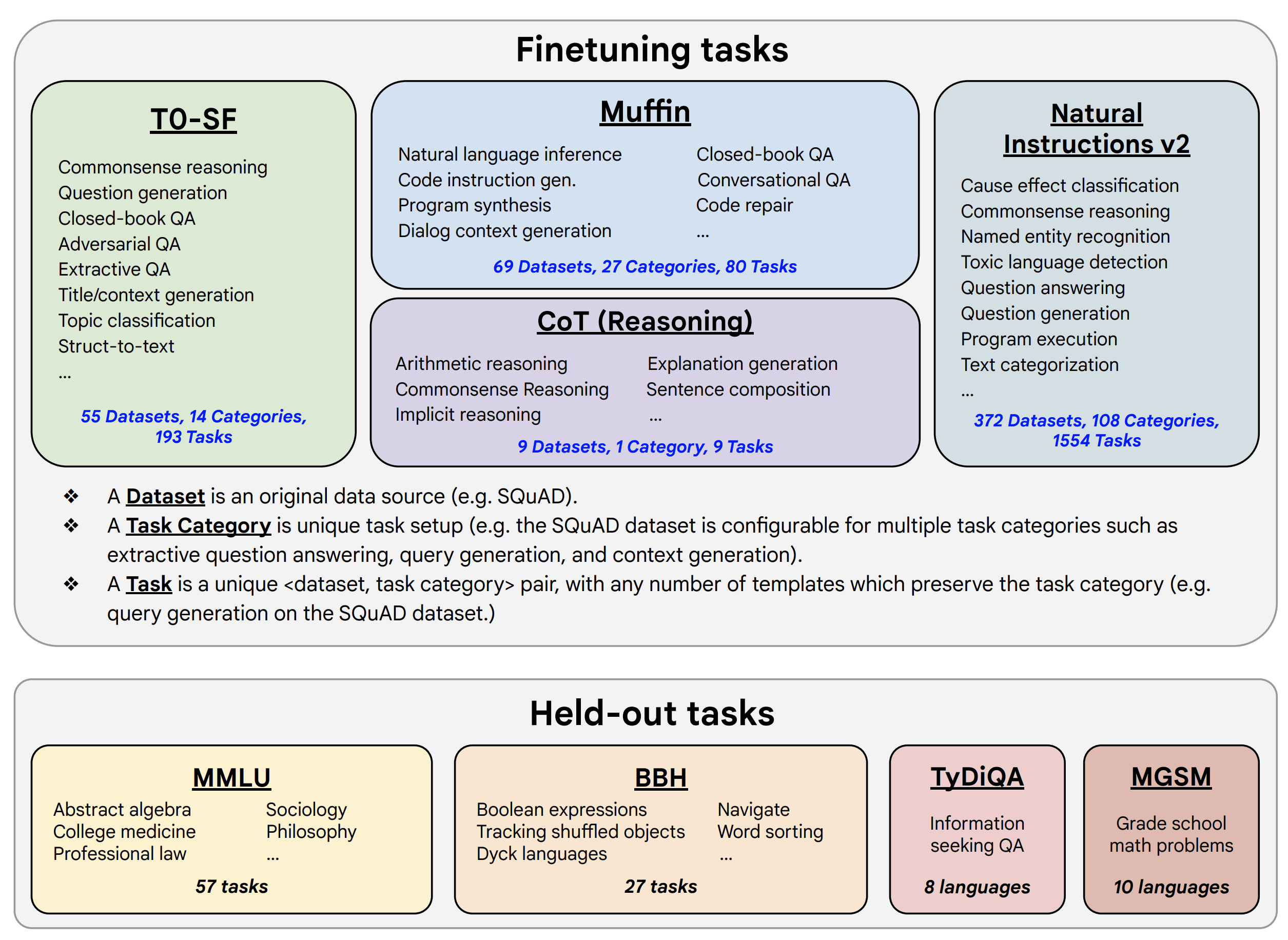 |
|---|
| 圖 3: FLAN V2 用於訓練與測試的混合任務集 (圖來自 FLAN V2 論文)。 |
我們這項工作背後的靈感,部分來自於 FLAN,部分來自 InstructPix2Pix。我們想探索能否通過特定指令來提示 Stable Diffusion,使其根據我們的要求處理輸入影象。
預訓練的 InstructPix2Pix 模型 擅長領會並執行一般性指令,對影象操作之類的特定指令可能並不擅長:
 |
|---|
| 圖 4: 我們可以看到,對同一幅輸入影象(左列),與預訓練的 InstructPix2Pix 模型(中間列)相比,我們的模型(右列)能更忠實地執行「卡通化」指令。第一行結果很有意思,這裡,預訓練的 InstructPix2Pix 模型很顯然失敗了。建議放大並以彩色顯示,以獲得最佳視覺效果。原圖見此處。 |
但我們仍然可以利用在 InstructPix2Pix 上的一些經驗和觀察來幫助我們做得更好。
另外,卡通化、影象去噪 以及 影象除雨 等任務的公開資料集比較容易獲取,所以我們能比較輕鬆地基於它們構建指令提示資料集 (該做法的靈感來自於 FLAN V2)。這樣,我們就能夠將 FLAN V2 中提出的指令模板思想遷移到本工作中。
資料集準備
卡通化
剛開始,我們對 InstructPix2Pix 進行了實驗,提示其對輸入影象進行卡通化,效果不及預期。我們嘗試了各種推理超引數組合 (如影象引導比 (image guidance scale) 以及推理步數),但結果始終不理想。這促使我們開始尋求不同的處理這個問題的方式。
正如上一節所述,我們希望結合以下兩個工作的優勢:
(1) InstructPix2Pix 的訓練方法,以及
(2) FLAN 的超靈活的建立指令提示資料集模板的方法。
首先我們需要為卡通化任務建立一個指令提示資料集。圖 5 展示了我們建立資料集的流水線:
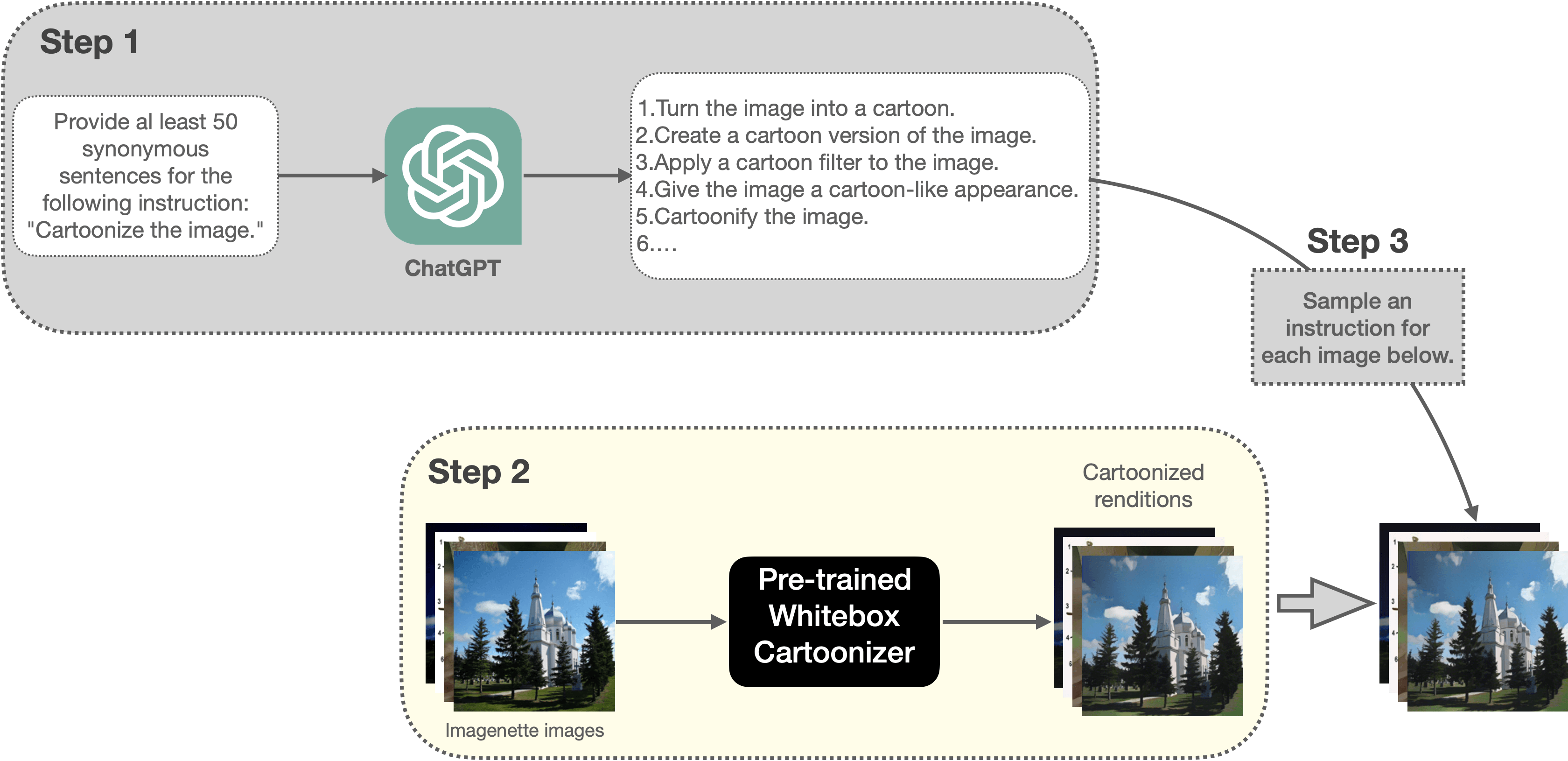 |
|---|
| 圖 5: 本文用於建立卡通化訓練資料集的流水線(建議放大並以彩色顯示,以獲得最佳視覺效果)。 |
其主要步驟如下:
- 請 ChatGPT 為 「Cartoonize the image.」 這一指令生成 50 個同義表述。
- 然後利用預訓練的 Whitebox CartoonGAN 模型對 Imagenette 資料集 的一個隨機子集 (5000 個樣本) 中的每幅影象生成對應的卡通化影象。在訓練時,這些卡通化的影象將作為標籤使用。因此,在某種程度上,這其實相當於將 Whitebox CartoonGAN 模型學到的技能遷移到我們的模型中。
- 然後我們按照如下格式組織訓練樣本:
 |
|---|
| 圖 6: 卡通化資料集的樣本格式(建議放大並以彩色顯示,以獲得最佳視覺效果)。 |
你可以在 此處 找到我們生成的卡通化資料集。有關如何準備資料集的更多詳細資訊,請參閱 此處。我們將該資料集用於微調 InstructPix2Pix 模型,並獲得了相當不錯的結果 (更多細節參見「訓練實驗及結果」部分)。
下面,我們繼續看看這種方法是否可以推廣至底層影象處理任務,例如影象除雨、影象去噪以及影象去模糊。
底層影象處理 (Low-level image processing)
我們主要專注 MAXIM 論文中的那些常見的底層影象處理任務。特別地,我們針對以下任務進行了實驗: 除雨、去噪、低照度影象增強以及去模糊。
我們為每個任務從以下資料集中抽取了數量不等的樣本,構建了一個單獨的資料集,併為其新增了提示,如下所示: 任務 提示 資料集 抽取樣本數
| 任務 | 提示 | 資料集 | 抽取樣本數 |
|---|---|---|---|
| 去模糊 | 「deblur the blurry image」 | REDS (train_blur及 train_sharp) |
1200 |
| 除雨 | 「derain the image」 | Rain13k | 686 |
| 去噪 | 「denoise the noisy image」 | SIDD | 8 |
| 低照度影象增強 | "enhance the low-light image」 | LOL | 23 |
上表中的資料集通常以 輸入輸出對的形式出現,因此我們不必擔心沒有真值 (ground-truth)。你可以從 此處 找到我們的最終資料集。最終資料集如下所示:
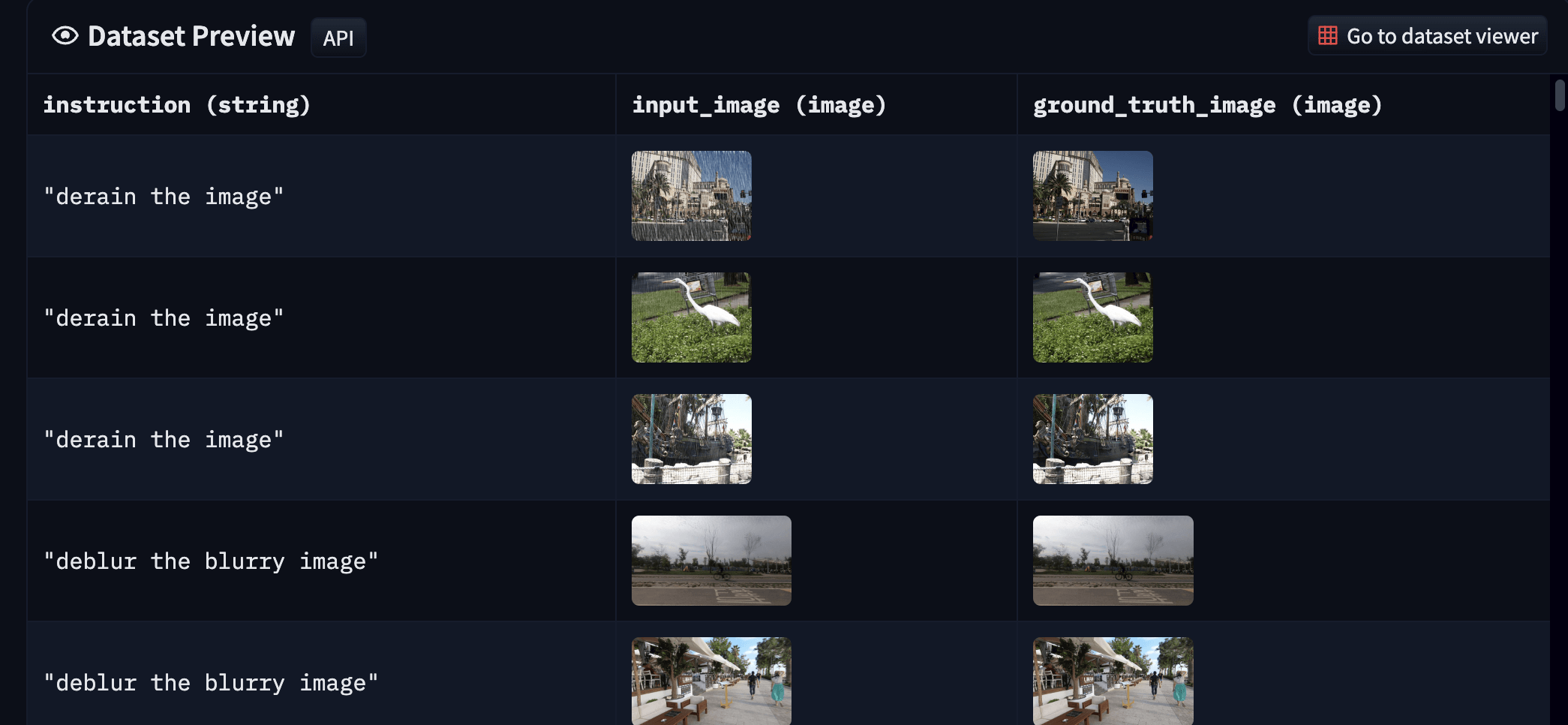 |
|---|
| 圖 7: 我們生成的底層影象處理資料集的樣本(建議放大並以彩色顯示,以獲得最佳視覺效果)。 |
總的來說,這種資料集的組織方式來源於 FLAN。在 FLAN 中我們建立了一個混合了各種不同任務的資料集,這一做法有助於我們一次性在多工上訓練單個模型,使其在能夠較好地適用於含有不同任務的場景。這與底層影象處理領域的典型做法有很大不同。像 MAXIM 這樣的工作雖然使用了一個單一的模型架構,其能對不同的底層影象處理任務進行建模,但這些模型的訓練是在各個資料集上分別獨立進行的,即它是「單架構,多模型」,但我們的做法是「單架構,單模型」。
訓練實驗及結果
這 是我們的訓練實驗的指令碼。你也可以在 Weight and Biases 上找到我們的訓練紀錄檔 (包括驗證集和訓練超參):
在訓練時,我們探索了兩種方法:
- 對 InstructPix2Pix 的 checkpoint 進行微調
- 使用 InstructPix2Pix 訓練方法對 Stable Diffusion 的 checkpoint 進行微調
通過實驗,我們發現第一個方法從資料集中學得更快,最終訓得的模型生成質量也更好。
有關訓練和超參的更多詳細資訊,可檢視 我們的程式碼 及相應的 Weights and Biases 頁面。
卡通化結果
為了測試 指令微調的卡通化模型 的效能,我們進行了如下比較:
 |
|---|
| 圖 8: 我們將指令微調的卡通化模型(最後一列)的結果與 CartoonGAN 模型(第二列)以及預訓練的 InstructPix2Pix 模型(第三列)的結果進行比較。顯然,指令微調的模型的結果與 CartoonGAN 模型的輸出更一致(建議放大並以彩色顯示,以獲得最佳視覺效果)。原圖參見此處。 |
測試影象是從 ImageNette 的驗證集中取樣而得。在使用我們的模型和預訓練 InstructPix2Pix 模型時,我們使用了以下提示: 「Generate a cartoonized version of the image」,並將 image_guidance_scale、 guidance_scale、推理步數分別設為 1.5、7.0 以及 20。這只是初步效果,後續還需要對超參進行更多實驗,並研究各引數對各模型效果的影響,尤其是對預訓練 InstructPix2Pix 模型效果的影響。
此處 提供了更多的對比結果。你也可以在 此處 找到我們用於比較模型效果的程式碼。
然而,我們的模型對 ImageNette 中的目標物件 (如降落傘等) 的處理效果 不及預期,這是因為模型在訓練期間沒有見到足夠多的這類樣本。這在某種程度上是意料之中的,我們相信可以通過增加訓練資料來緩解。
底層影象處理結果
對於底層影象處理 (模型),我們使用了與上文相同的推理超參:
- 推理步數: 20
image_guidance_scale: 1.5guidance_scale: 7.0
在除雨任務中,經過與真值 (ground-truth) 和預訓練 InstructPix2Pix 模型的輸出相比較,我們發現我們模型的結果相當不錯:
 |
|---|
| 圖 9: 除雨結果(建議放大並以彩色顯示,以獲得最佳視覺效果)。提示為 「derain the image」(與訓練集相同)。原圖見此處 。 |
但低照度影象增強的效果不盡如意:
 |
|---|
| 圖 10: 低照度影象增強結果(建議放大並以彩色顯示,以獲得最佳視覺效果)。提示為 「enhance the low-light image」(與訓練集相同)。原圖見[此處]。 |
這種情況或許可以歸因於訓練樣本不足,此外訓練方法也尚有改進餘地。我們在去模糊任務上也有類似發現:
 |
|---|
| 圖 11: 去模糊結果(建議放大並以彩色顯示,以獲得最佳視覺效果)。提示為 「deblur the image」(與訓練集相同)。原圖見此處 。 |
我們相信對社群而言,底層影象處理的任務不同組合如何影響最終結果 這一問題非常值得探索。 在訓練樣本集中增加更多的任務種類並增加更多具代表性的樣本是否有助於改善最終結果? 這個問題,我們希望留給社群進一步探索。
你可以試試下面的互動式演示,看看 Stable Diffusion 能不能領會並執行你的特定指令:
體驗地址:
潛在的應用及其限制
在影象編輯領域,領域專家的想法 (想要執行的任務) 與編輯工具 (例如 Lightroom) 最終需要執行的操作之間存在著脫節。如果我們有一種將自然語言的需求轉換為底層影象編輯原語的簡單方法的話,那麼使用者體驗將十分絲滑。隨著 InstructPix2Pix 之類的機制的引入,可以肯定,我們正在接近那個理想的使用者體驗。
但同時,我們仍需要解決不少挑戰:
- 這些系統需要能夠處理高解析度的原始高清影象。
- 擴散模型經常會曲解指令,並依照這種曲解修改影象。對於實際的影象編輯應用程式,這是不可接受的。
開放性問題
目前的實驗仍然相當初步,我們尚未對實驗中的很多重要因素作深入的消融實驗。在此,我們列出實驗過程中出現的開放性問題:
- 如果擴巨量資料集會怎樣? 擴巨量資料集對生成樣本的質量有何影響?目前我們實驗中,訓練樣本只有不到 2000 個,而 InstructPix2Pix 用了 30000 多個訓練樣本。
- 延長訓練時間有什麼影響,尤其是當訓練集中任務種類更多時會怎樣? 在目前的實驗中,我們沒有進行超參調優,更不用說對訓練步數進行消融實驗了。
- 如何將這種方法推廣至更廣泛的任務集?歷史資料表明,「指令微調」似乎比較擅長多工微調。 目前,我們只涉及了四個底層影象處理任務: 除雨、去模糊、去噪和低照度影象增強。將更多工以及更多有代表性的樣本新增到訓練集中是否有助於模型對未見任務的泛化能力,或者有助於對複合型任務 (例如: 「Deblur the image and denoise it」) 的泛化能力?
- 使用同一指令的不同變體即時組裝訓練樣本是否有助於提高效能? 在卡通化任務中,我們的方法是在 資料集建立期間 從 ChatGPT 生成的同義指令集中隨機抽取一條指令組裝訓練樣本。如果我們在訓練期間隨機抽樣,即時組裝訓練樣本會如何?對於底層影象處理任務,目前我們使用了固定的指令。如果我們按照類似於卡通化任務的方法對每個任務和輸入影象從同義指令集中取樣一條指令會如何?
- 如果我們用 ControlNet 的訓練方法會如何? ControlNet 允許對預訓練文生圖擴散模型進行微調,使其能以影象 (如語意分割圖、Canny 邊緣圖等) 為條件生成新的影象。如果你有興趣,你可以使用本文中提供的資料集並參考 這篇文章 進行 ControlNet 訓練。
總結
通過本文,我們介紹了我們對「指令微調」 Stable Diffusion 的一些探索。雖然預訓練的 InstructPix2Pix 擅長領會執行一般的影象編輯指令,但當出現更專門的指令時,它可能就沒法用了。為了緩解這種情況,我們討論瞭如何準備資料集以進一步微調 InstructPix2Pix,同時我們展示了我們的結果。如上所述,我們的結果仍然很初步。但我們希望為研究類似問題的研究人員提供一個基礎,並激勵他們進一步對本領域的開放性問題進行探索。
連結
感謝 Alara Dirik 和 Zhengzhong Tu 的討論,這些討論對本文很有幫助。感謝 Pedro Cuenca 和 Kashif Rasul 對文章的審閱。
參照
如需參照本文,請使用如下格式:
@article{
Paul2023instruction-tuning-sd,
author = {Paul, Sayak},
title = {Instruction-tuning Stable Diffusion with InstructPix2Pix},
journal = {Hugging Face Blog},
year = {2023},
note = {https://huggingface.co/blog/instruction-tuning-sd},
}
英文原文:
https://hf.co/blog/instruction-tuning-sd 原文作者: Sayak Paul
譯者: Matrix Yao (姚偉峰),英特爾深度學習工程師,工作方向為 transformer-family 模型在各模態資料上的應用及大規模模型的訓練推理。
審校/排版: zhongdongy (阿東)