AB實驗:科學歸因與增長的利器
第一章 AB實驗的基本原理和應用
AB實驗的相關概念:
3個基本引數:實驗參與單元、實驗控制引數、實驗指標
2個核心價值:驗證因果關係、量化策略效果
2個關鍵特性:先驗性、並行性
基本流程:分流 -> 實驗 -> 資料分析 -> 決策
基本要素
- 實驗參與單元,關鍵條件:
- 實驗參與單元互不干擾
- 實驗參與單元合理隨機化
- 足夠的實驗參與單元;實驗實際提升效果越不明顯,就需要更多的參與單元來確認實驗效果。例如:點選率、曝光率等變化幅度較大的指標,變化1%,需要十萬級單位;留存率變化幅度較小,需要更多;對於初創、垂類(使用者只有幾千或幾萬),只能測出3%、5%甚至10%以上的實驗效果
- 實驗控制引數,滿足以下條件:
- 實驗控制引數可分配(最關鍵)
- 實驗控制引數容易改變
- 實驗指標,滿足兩個基本要求:
- 實驗指標能反映實驗者的意圖
- 實驗指標可測、易測
核心價值
- 定性因果:驗證因果關係,確保方向正確
相關性:當一件事情出現時,另一件事情也出現
因果關係:一件事情出現的原因是另一件事情出現,或者一件事情出現的結果是另外一件事出現 - 定量增長:實踐資料驅動,精細成本收益
因果推斷常用的模型:- 潛在因果框架,Rubin因果模型(RCM)
- 因果圖模型
\(T_i\)表示個體i是否進行了某個實驗,實驗取1,對照取0,\(\{Y_i(1),Y_i(0)\}\)表示個體i進行實驗和作為對照的潛在結果,例如:\(Y_i(0)\)表示使用者沒有被投放紅點時的活躍度,\(Y_i(1)-Y_i(0)\)表示個體接受實驗後的個體因果作用。
\(E\{Y_i|T_i = 1\}\)是實驗對參與實驗的人的平均因果效應,\(E\{Y_i(0)|T_i = 1\}-E\{Y_i(0)|T_i = 0\}\)是隨機本組帶來的選擇偏差
關鍵特性
先驗性:小流量預先獲得效果評估
並行性:同一個實驗物件可以有多個實驗並行展開
應用場景
典型的應用場景:推薦類場景(演演算法優化黑盒屬性)、運營類場景(長短期綜合收益ROI)、UI設計和互動類場景(感性決策眾口難調)
第二章 AB實驗的關鍵問題
實驗參與物件的3個問題
- 實驗參與物件是否被合理隨機化(效能最好:雜湊函數)
- 實驗參與物件是否相互獨立;AB實驗結果有效需要滿足一個基本假設:個體處理穩定性假設(Stable Unit Treatment Value Assumption,SUTVA:任何實驗單元的潛在結果不會隨分配給其他單元的處理而變化)
- 實驗參與物件的數量是否足夠進行實驗評估
實驗隨機分流的3個問題
- 最小分流單元採用什麼顆粒度是最佳的選擇(元素級別、頁面級別、對談級別、使用者級別)
- 在分流時,如何在不增加實驗評估複雜度的情況下實驗流量複用
- 對於同一個實驗組中的各組物件,是否同質?存在SRM問題(樣本比例不匹配)嗎?
實驗指標的2個問題
- 如何建立一個完善的產品指標體系,包括指標的設計、評估、進化和計算等
- 如何選擇合適的實驗評估指標,包括從產品視角、工程視角綜合考慮,以及多個目標指標如何合併成綜合評價指標(OEC)
實驗分析和評估的3個問題
- 對於統計結果理解是否正確
- 如何解讀實驗結果中p值、置信度、置信區間的關係
- 實驗得出的相對提升,究竟是一個自然波動還是真實的實驗提升
- 實驗參與單元的數量是否足以檢驗想要的實驗效果
- 實驗統計的power值(統計功效)是否充分
- 實驗統計精度是否可以檢測出業務的提升
- 實驗分析的過程是否正確
- 有沒有進行AA實驗
- 在實驗過程中有沒有SRM測試
- 在實驗過程中有沒有偷窺實驗
- 是否存在倖存者偏差、辛普森悖論
- 區域性實驗的結果如何推導為全域性提升量、轉化過程是否正確
- 實驗分析的外推結果是否正確
在一些特定的情況下,實驗結果被推廣到實驗的設定之外不再有效:- 群體外推:結果推廣到實驗群體之外
- 時間外推:實驗時間範圍之外推廣,因此不能確保長期影響和短期影響是相同的
第三章 AB實驗的統計學知識
隨機抽樣與抽樣分佈
樣本均值與總體均值總有差異,\(\mu = \bar{x} + \epsilon \),如何衡量\(\epsilon\),當無法得到全部使用者資料時,可以採用反覆抽取100個使用者的方法,得到不同的隨機樣本,通過\(E(\bar{x})= \mu,\sigma_{\bar{x}}=\frac{\sigma}{\sqrt{n}}\)來計算總體均值
- 樣本容量:每個隨機樣本中個體數
- 樣本量:隨機抽樣的次數
樣本容量與邊際誤差
- 均值類指標\(\epsilon = Z_{\alpha/2}\frac{\sigma}{\sqrt{n}}\),樣本容量\(n = \frac{(Z_{\alpha/2})^2\sigma^2}{\epsilon^2}\),邊際誤差是業務需要檢驗的最低幅度變化,所以又稱為最小檢出水平
- 比率類指標\(n = \frac{(Z_{\alpha/2})^2\bar{p}(1-\bar{p})}{\epsilon^2}\)
假設檢驗
為控制第二類錯誤,引入一個概念——功效(power)。功效是指H0不成立時,做出拒絕H0的結論正確的概率,功效 \(= 1- \beta\),第二類錯誤發生的概率越小,功效越大。
例如:當\(P<\alpha\),則拒絕原假設H0,認為策略有效;
當\(P \geq \alpha\),則不能拒絕原假設H0,也不能接受H1,此時不能說明策略有效,也不能說明策略無效,需要進一步觀察功效,如果功效>80%,說明犯第二類錯誤的概率很低,即策略有效被判斷為無效的概率很低,此時策略是無效的。
弄假成真第一類:原假設為真拒絕原假設(拒真錯誤)——活動指標相等(假:活動無效),但判斷為活動有效(真)
弄真成假第二類:原假設為假接受原假設(取偽錯誤)——活動指標不相等(真:活動有效),但判斷為活動無效(假)
非引數檢驗
引數檢驗要求符合獨立同分布,非引數的方法對總體概率沒有分佈的要求,不對模型做任何引數假設,完全是基於資料模擬的方法。目前使用最多的是bootstrap(有放回)和jackknife(無放回)。
多重測試問題
每次判斷正確的概率為95%,對同樣的事情多次判斷,開設N個相同的實驗組,全部判斷正確的概率變為(95%)^N,問題的主要來源:
- 多次重複相同的實驗;
- 多次進行相同對比;
- 實驗進行過程中多次檢視實驗結果,即常說的實驗偷窺
- 同一個實驗有多個指標的情況
採用以下方式進行避免:
- 在構建實驗指標體系的時候,核心實驗指標的設定和選擇要儘量少
- 在實驗過程中不要多次檢視實驗結果
第四章 AB實驗參與單元
實驗參與單元的選擇
在網際網路產品的AB實驗中,有以下幾種比較常見的實驗參與單元:
- 元素級別:指對實驗元素,比如一篇文章、一首歌曲等進行隨機分流並標識實驗id的隨機過程。(例:演演算法推薦資訊)
- 頁面級別:產品頁面被視為實驗參與單元,進行實驗的頁面每開啟一次,就會被隨機函數分配到不同的實驗組中。
- 對談級別:使用者在網站的一次存取時檢視的一組頁面或者是啟動一次APP後在APP內的行為(啟動 -> 退出)
- 使用者級別:以使用者為實驗參與單元
選擇合適的實驗參與單元的關鍵因素:
- 實驗所需要的流量以及實驗檢測精度
- 使用者體驗的連續性
注:為保證體驗的穩定性和連續性,最好採用使用者級別;在不影響使用者體驗的前提下采用更細粒度的隨機單元。
使用者級別的實驗參與單元的常用使用者標識有:
- 登入賬號
- 裝置ID
實驗參與單元的SUTVA問題
常見問題如下:
- 什麼是SUTVA?
個體處理穩定性假設(Stable Unit Treatment Value Assumption),指在AB實驗分析中,假設實驗中每個實驗參與單元的行為是相互獨立的。 - 為什麼需要讓SUTVA成立
AB實驗因果分析主要基於魯賓因果模型進行,分析框架的三個基本要素:- 潛在結果:給定一個實驗單元和一系列動作,把一個「實驗單元-動作」確定為一個潛在結果。「潛在」表達的意思是並不總能在現實中觀察到這個結果,但理論上發生。
- SUTVA:任何單元的潛在結果不會因分配給其他單元的處理而發生變化,並且對於每一個單元,不同的處理對應唯一不同的結果
- 分配機制
- 哪些情況會導致SUTVA不成立
- 直接干擾:同時存取相同的物理空間
- 間接干擾:通過某些潛在變數或共用資源,兩個實驗單元可以有間接連線;例:滴滴讓實驗組的乘客更有可能選擇搭車導致司機少了
- 如何解決SUTVA不成立的問題
解決AB實驗的干擾問題:- 建立監控和報警
- 隔離法:通過識別連線媒介隔離使用者來消除潛在干擾,常用的隔離方法:
- 共用資源隔離
- 地理位置隔離
- 網路族群隔離:在社群網路上,可以根據節點干擾的可能性構建彼此接近的節點的簇,然後將簇作為單元獨立、隨機分為實驗組或對照組
- 邊緣度分析
- 生態經驗法
- 雙邊隨機化
最小實驗參與單元數量
如何確定一個「最小」的樣本量,在保證實驗「可靠性」的同時,不會浪費過多流量。控制樣本量的主要因素:
- 顯著性水平
- 統計功效(\(1-\beta\)):實驗本身有效果同時也被判斷為有效果的概率。對於一個AB實驗
- 第一類錯誤不超過5%
- 第二類錯誤不超過20%,功效大於80%
背後理念:寧可砍掉四個好的產品,也不讓一個壞的產品上線
- 基線水平:在實驗開始之前,對照組中所關心的實驗指標的表現情況,即產品不做改變時的指標水平。
- 最小檢出水平:用於衡量實驗判斷精度的最低要求
總結:計算最小實驗單元就是為了將第一類和第二類錯誤控制在一定範圍內,達到一定的實驗置信度和業務評估精度,主要有四個因子:顯著性、統計功效、指標(方差)、最小檢出水平
第五章 AB實驗的隨機流量
進行使用者隨機分流,需要重點關注的幾個問題:
- 使用者如何被隨機分為實驗組和對照組
- 實驗量增加後,流量不夠用的問題和解決
- 不同層之間的正交性是如何實現並保證的
- 隨機分流時如何選擇雜湊演演算法
單層分流模式
適合階段:實驗初級階段,實驗數量通常很少
定義:單層指不重複利用使用者,在同一個時間內,使用者最多隻會參與一個實驗。
缺點:對並行實驗數量有限制
正交分層模式
實現方法:擁有多個實驗層,其中每一層的行為類似於單層方法。為了確保層間實驗的正交性,在把使用者分配到桶時,會新增層id,也稱為鹽值。層與層之間的正交性就是靠雜湊函數加層id的方式來保證。
正交分層模式的關鍵點:
- 正交性如何保證?
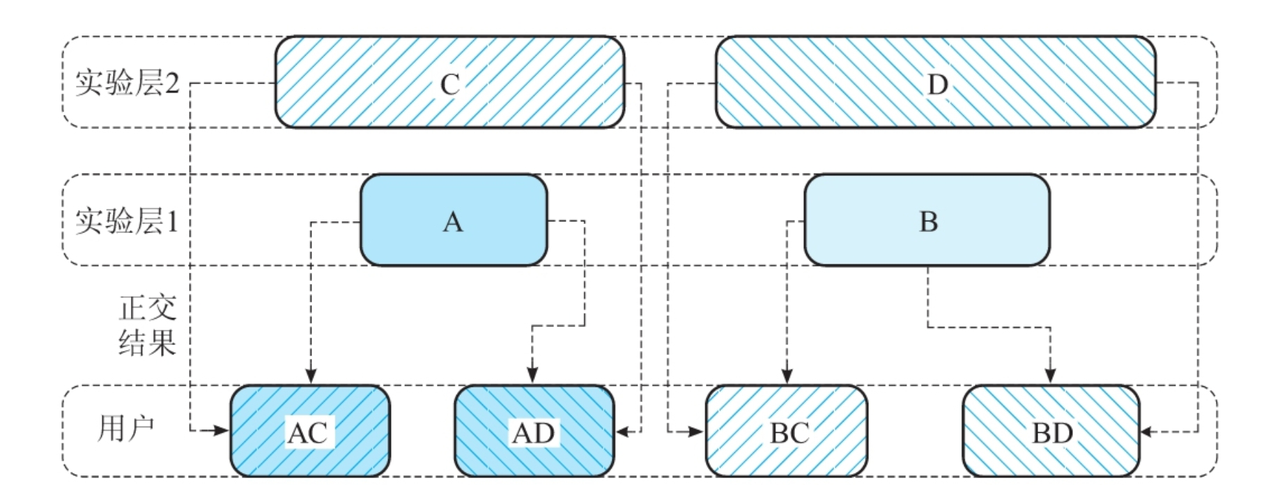
- 如何確定分多少層且如何使用?
全析因實驗設計:將每個實驗都單獨作為一層
為避免同類實驗碰撞,可以使用有限層的劃分方式:將系統引數劃分為多個層,不同層執行不同類的實驗,組合在一起可能會產生較差的使用者體驗的實驗必須放在同一層,防止向同一使用者執行。關鍵點:- 同類業務互斥進入同一層
- 不同類業務可以拆分到不同層,並行進行、保證實驗流量足夠,通過正交實現層間效果互相影響的隔離
雜湊演演算法
雜湊演演算法的考慮方面:計算效能、均勻性、相關性
計算效能:指開始分流時雜湊演演算法的速度
均勻性:指同層之中分為不同實驗組的時候,每個組分到參與使用者的數量儘量一致(組間差異)
相關性:指不同層的組之間的混合儘量均勻(層間差異)
常用的雜湊演演算法:MD、SHA、JDB、Murmur
注:在滿足一定使用者量的情況下出現了顯著差異,大概率是出現了分流不均的情況,原因:系統出錯、使用者不同質,一般考慮在實驗前進行檢驗(SRM檢驗[樣本比例不匹配]、AA實驗)
第六章 AB實驗的SRM問題
樣本比例不匹配問題(SRM)是常見的一種導致實驗失敗的原因。
保護指標:
- 組織性保護指標:保護指標用於保護業務不受傷害
- 實驗可信度保護指標:針對實驗本身的可信度(SRM指標)
什麼是SRM
SRM問題是實驗組和對照組之間的實驗參與單元數量(比如使用者數、頁面數、對談數等)的比率不匹配。
導致SRM問題的原因
原因:實驗的部署、執行、資料處理、分析
- 部署階段
- 殘留效應:前一個實驗汙染了相同使用者分組的後續實驗
- 觸發前狀態偏差
- 動態定向目標:定向目標是指實驗執行在特定的使用者集上,基於使用者的屬性和活動特徵為他們提供個性化的產品體驗
-
執行階段
採用圖6-2來避免出現使用者過濾條件
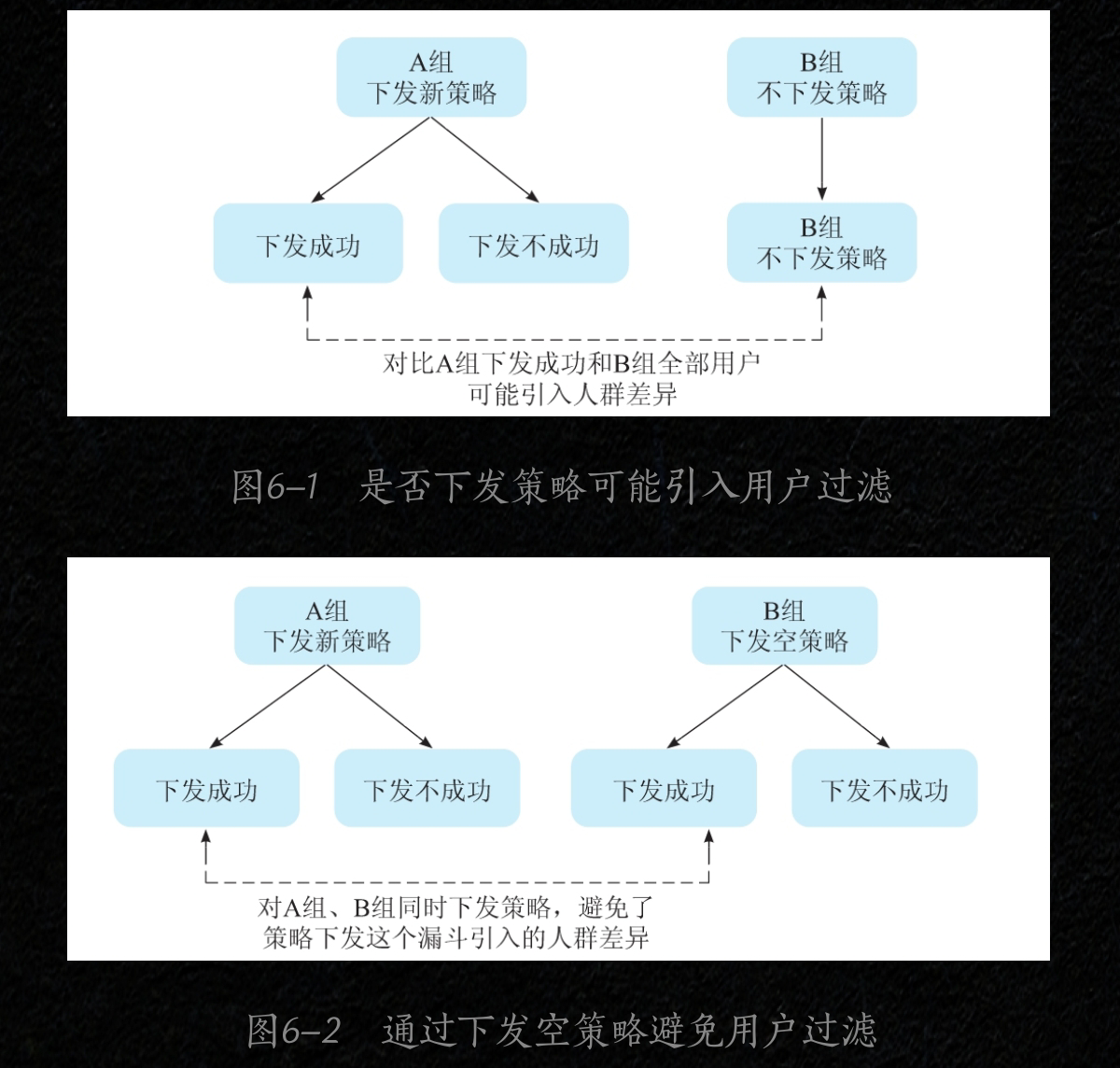
-
資料處理和分析階段
在資料分析階段,SRM問題主要是分析過程中一些樣本偏差被忽視,以理論的樣本比例進行分析造成的錯誤。例如:機器人過濾;資料處理中常刪除機器人流量,而機器人過濾會存在資料失真的情況,從而導致SRM問題
SRM指標計算和定位
- SRM指標計算
通過實驗組和對照組實驗參與單元的可比性來實現,當取樣比例指標的P值很低時,應該假定大概率是系統中的某個地方存在錯誤。
舉例:
預定比例 實驗:對照 = 447500:447500 = 0.5:0.5
實際比例 實驗:對照 = 445000:450000 = 0.4972:0.5
計算過程:
計算方差:\(\sigma = \sqrt{\frac{p(1-p)}{n}}=\sqrt{\frac{0.5(1-0.5)}{895000}}=0.0005285\)
計算Z統計量:\(z_{\alpha/2}=\frac{x-\mu}{\sigma}=\frac{0.4972-0.5}{0.000528}=-5.2980\)
查P值:根據Z值反查P值,\(P = 1.17 \times10^{-7}\),P值很低(遠低於0.001)
做出判斷:傾向認為這個實驗出現了SRM問題
- 定位SRM問題
常見的定位SRM問題方法:
- 驗證隨機化點或觸發點上游沒有差異
- 驗證變數分配是否正確
- 是否有相同的初始區間(一起開始實驗)
- 檢視細分市場的樣本比率
- 每天是否有異常資料
- 某個細分市場資料是否突出
- 新老使用者等
第七章 AA實驗
隨機選取兩組使用者,對這兩組使用者使用一樣的策略,除了參與實驗的物件之外沒有其他不同的實驗成為AA實驗,也稱為AA測試、空轉實驗,就是實驗組和對照組完全相同的AB實驗。
AA實驗的意義
- 控制第一類錯誤
控制實驗有效卻被判斷為無效的情況 - 確保使用者同質
- 資料指標對齊,評估指標的可信度和可變性
將實驗指標資料和大盤指標資料對齊,有兩個重點檢查環節:- 生效的使用者量是不是和預估的實驗流量匹配
- 各項比率、人均指標是不是和大盤紀錄檔監控系統的資料對齊
如果存在指標和大盤資料存在明顯差異,應該檢查如下環節:
- 估計統計方差
如何執行AA實驗
- 什麼時候執行AA實驗
一般在AB實驗系統剛開始執行,或是AB實驗系統採用了新的隨機分流機制(新隨機函數、新增加實驗層、實驗域等)、採用新的資料計算流等任何可能影響實驗結果的重大變化的時候,建議隨機執行儘可能多的AA實驗。
可以模擬1000個AA實驗,並根據實驗結果繪製P值分佈圖,如果AA實驗的P值分佈不均勻,則AB實驗系統的可信度存疑。
注意事項:- AA實驗進行3~7天,如果多項指標有顯著差異,則AA實驗不通過,需要重新開啟AA實驗
常規的實驗級別AA實驗保證了實驗的可信度,但增加了實驗的週期,加速實驗程序的常用方法——紀錄檔回溯法、流量尋優法。
AA實驗失敗的常見原因
常見原因如下:
- 分流不隨機
- 指標方差估計錯誤
- 最小樣本量不符合要求
- 髒資料
第八章 AB實驗的靈敏度
什麼是實驗靈敏度
靈敏度是某種測量方法對單位濃度或單位待測量物質變化的響應變數的響應量變化程度。檢測能力的大小就稱為實驗靈敏度。
如何理解實驗靈敏度?單個實驗優化所能帶來的提升是非常有限的,這個時候如果實驗檢測的靈敏度不高,就容易給出錯誤甚至相反的結論。
如何提升實驗靈敏度
實驗靈敏程度 = 對樣本指標所在區間估計的準確程度,減少邊際誤差,提高靈敏度的方法主要有兩種:1. 降低方差;2. 增加樣本量
增加樣本量的可控性較低,一般通過減少方差的方法,主要從三個方面入手:
- 選擇指標,選擇方差更小的指標
- 選擇實驗參與單元,選擇粒度更小的參與單元以減少方差
- 在實驗分組過程中,通過分層法、CUPED等方法減少因不同特徵使用者組間分配不均帶來方差
選擇指標
- 選擇方差較小的指標評估
- 標準化評估指標,常見標準化方法:二值轉化、對數轉化、截斷法、
選擇實驗參與物件
- 選擇更細粒度的單元隨機化物件
- 使用觸發分析
選擇實驗分組
- 使用分層、控制變數或CUPED方法
- 設計配對實驗:
配對設計實驗的思想:在配對實驗設計中向同一個使用者展示實驗組和對照組方案,同一個使用者可以同時對這兩組方案做出反饋,消除使用者差異性,例如:交錯設計
定向觸發技術和評估
- 觸發的方式:特徵觸發、行為觸發
- 觸發範圍的變化:擴大觸發範圍、觸發範圍改變、機器學習模型觸發範圍
- 觸發實驗的分析需要注意的點:
- 一旦使用者觸發,後續實驗必須將這些使用者包含在其中
- 分析時間粒度的選擇
- 合理計算觸發實驗計算提升量
- 觸發檢驗,確保觸發,應執行兩項檢查:
- SRM問題
- 補充分析,為從未觸發的使用者進行AA實驗,如果統計上有顯著差異,那麼觸發條件很有可能不正確
- 觸發技術的侷限性
如何驗證實驗靈敏度的提升
可以通過模擬實驗的方法驗證靈敏度的提升,模擬實驗就是採用和線上完全相同的實驗抽樣演演算法,復現線上抽樣效果