詳解4種模型壓縮技術、模型蒸餾演演算法
摘要:本文主要為大家講解關於深度學習中幾種模型壓縮技術、模型蒸餾演演算法:Patient-KD、DistilBERT、DynaBERT、TinyBERT。
本文分享自華為雲社群《深度學習實踐篇[17]:模型壓縮技術、模型蒸餾演演算法:Patient-KD、DistilBERT、DynaBERT、TinyBER》,作者: 汀丶。
1.模型壓縮概述
1.1模型壓縮原有
理論上來說,深度神經網路模型越深,非線性程度也就越大,相應的對現實問題的表達能力越強,但相應的代價是,訓練成本和模型大小的增加。同時,在部署時,大模型預測速度較低且需要更好的硬體支援。但隨著深度學習越來越多的參與到產業中,很多情況下,需要將模型在手機端、IoT端部署,這種部署環境受到能耗和裝置體積的限制,端側硬體的計算能力和儲存能力相對較弱,突出的訴求主要體現在以下三點:
- 首先是速度,比如像人臉閘機、人臉解鎖手機等應用,對響應速度比較敏感,需要做到實時響應。
- 其次是儲存,比如電網周邊環境監測這個應用場景中,要影象目標檢測模型部署在可用記憶體只有200M的監控裝置上,且當監控程式執行後,剩餘記憶體會小於30M。
- 最後是耗能,離線翻譯這種移動裝置內建AI模型的能耗直接決定了它的續航能力。

以上三點訴求都需要我們根據終端環境對現有模型進行小型化處理,在不損失精度的情況下,讓模型的體積更小、速度更快,能耗更低。
但如何能產出小模型呢?常見的方式包括設計更高效的網路結構、將模型的引數量變少、將模型的計算量減少,同時提高模型的精度。 可能有人會提出疑問,為什麼不直接設計一個小模型? 要知道,實際業務子垂類眾多,任務複雜度不同,在這種情況下,人工設計有效小模型難度非常大,需要非常強的領域知識。而模型壓縮可以在經典小模型的基礎上,稍作處理就可以快速拔高模型的各項效能,達到「多快好省」的目的。

上圖是分類模型使用了蒸餾和量化的效果圖,橫軸是推理耗時,縱軸是模型準確率。 圖中最上邊紅色的星星對應的是在MobileNetV3_large model基礎上,使用蒸餾後的效果,相比它正下方的藍色星星,精度有明顯的提升。 圖中所標淺藍色的星星,對應的是在MobileNetV3_large model基礎上,使用了蒸餾和量化的結果,相比原始模型,精度和推理速度都有明顯的提升。 可以看出,在人工設計的經典小模型基礎上,經過蒸餾和量化可以進一步提升模型的精度和推理速度。
1.2模型壓縮的基本方法
模型壓縮可以通過以下幾種方法實現:

- 剪裁:類似「化學結構式的減肥」,將模型結構中對預測結果不重要的網路結構剪裁掉,使網路結構變得更加 」瘦身「。比如,在每層網路,有些神經元節點的權重非常小,對模型載入資訊的影響微乎其微。如果將這些權重較小的神經元刪除,則既能保證模型精度不受大影響,又能減小模型大小。
- 量化:類似「量子級別的減肥」,神經網路模型的引數一般都用float32的資料表示,但如果我們將float32的資料計算精度變成int8的計算精度,則可以犧牲一點模型精度來換取更快的計算速度。
- 蒸餾:類似「老師教學生」,使用一個效果好的大模型指導一個小模型訓練,因為大模型可以提供更多的軟分類資訊量,所以會訓練出一個效果接近大模型的小模型。
- 神經網路架構搜尋(NAS):類似「化學結構式的重構」,以模型大小和推理速度為約束進行模型結構搜尋,從而獲得更高效的網路結構。
除此以外,還有權重共用、低秩分解等技術也可實現模型壓縮。
2.Patient-KD 模型蒸餾
2.1. Patient-KD 簡介
論文地址:Patient Knowledge Distillation for BERT Model Compression
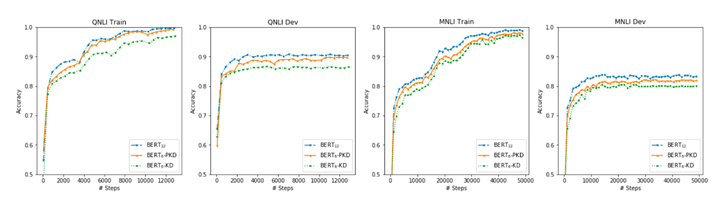
圖1: Vanilla KD和PKD比較
BERT預訓練模型對資源的高需求導致其很難被應用在實際問題中,為緩解這個問題,論文中提出了Patient Knowledge Distillation(Patient KD)方法,將原始大模型壓縮為同等有效的輕量級淺層網路。同時,作者對以往的知識蒸餾方法進行了調研,如圖1所示,vanilla KD在QNLI和MNLI的訓練集上可以很快的達到和teacher model相媲美的效能,但在測試集上則很快達到飽和。對此,作者提出一種假設,在知識蒸餾的過程中過擬合會導致泛化能力不良。為緩解這個問題,論文中提出一種「耐心」師生機制,即讓Patient-KD中的學生模型從教師網路的多箇中間層進行知識提取,而不是隻從教師網路的最後一層輸出中學習。
2.2. 模型實現
Patient-KD中提出如下兩個知識蒸餾策略:
- PKD-Skip: 從每k層學習,這種策略是假設網路的底層包含重要資訊,需要被學習到(如圖2a所示)
- PKD-last: 從最後k層學習,假設教師網路越靠後的層包含越豐富的知識資訊(如圖2b所示)
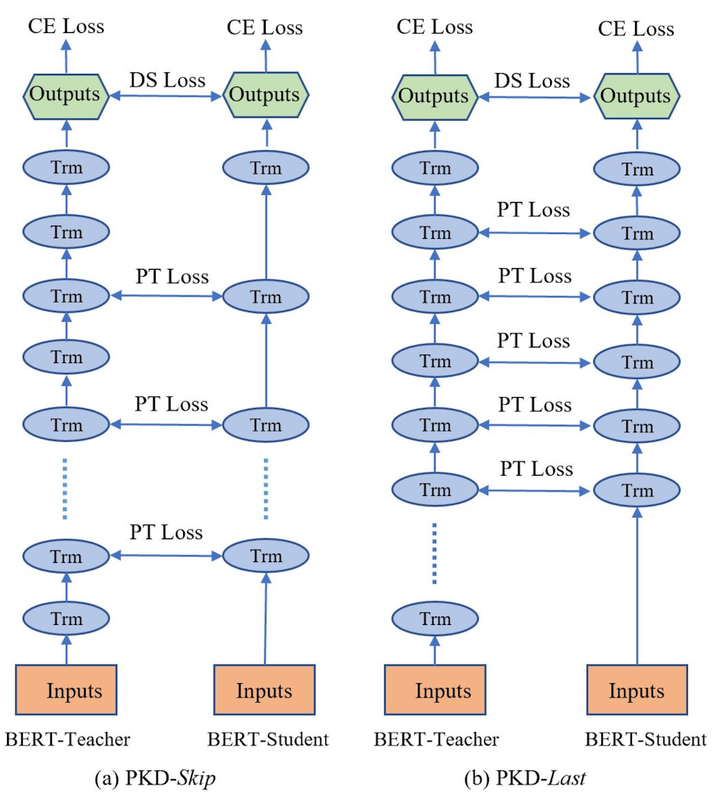
圖2a: PKD-Skip 學生網路學習教師網路每兩層的輸出 圖2b: PKD-Last 學生網路從教師網路的最後六層學習
因為在BERT中僅使用最後一層的[CLS] token的輸出來進行預測,且在其他BERT的變體模型中,如SDNet,是通過對每一層的[CLS] embedding的加權平均值進行處理並預測。由此可以推斷,如果學生模型可以從任何教師網路中間層中的[CLS]表示中學習,那麼它就有可能獲得類似教師網路的泛化能力。
因此,Patient-KD中提出特殊的一種損失函數的計算方式:

2.3. 實驗結果
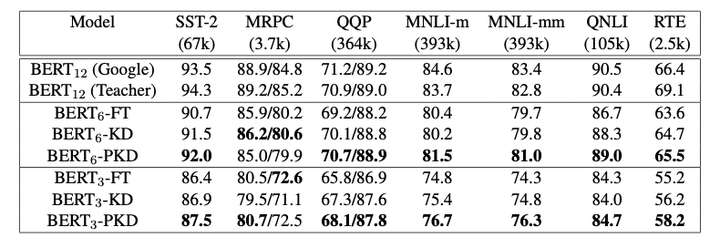
圖3: results from the GLUE test server
作者將模型預測提交到GLUE並獲得了在測試集上的結果,如圖3所示。與fine-tuning和vanilla KD這兩種方法相比,使用PKD訓練的BERT3BERT3和BERT6BERT6在除MRPC外的幾乎所有任務上都表現良好。其中,PKD代表Patient-KD-Skip方法。對於MNLI-m和MNLI-mm,六層模型比微調(FT)基線提高了1.1%和1.3%,
我們將模型預測提交給官方 GLUE 評估伺服器以獲得測試資料的結果。 結果總結在表 1 中。 與直接微調和普通 KD 相比,我們使用 BERT3 和 BERT6 學生的 Patient-KD 模型在除 MRPC 之外的幾乎所有任務上都表現最好。 此外,6層的BERT6−PKDBERT6−PKD在7個任務中有5個都達到了和BERT-Base相似的效能,其中,SST-2(與 BERT-Base 教師相比為-2.3%)、QQP(-0.1%)、MNLI-m(-2.2%)、MNLI-mm(-1.8%)和 QNLI (-1.4%)),這五個任務都有超過6萬個訓練樣本,這表明了PKD在巨量資料集上的表現往往更好。

圖4: PKD-Last 和 PKD-Skip 在GLUE基準上的對比
儘管這兩種策略都比vanilla KD有所改進,但PKD-Skip的表現略好於PKD-Last。作者推測,這可能是由於每k層的資訊提煉捕獲了從低階到高階的語意,具備更豐富的內容和更多不同的表示,而只關注最後k層往往會捕獲相對同質的語意資訊。

圖5: 引數量和推理時間對比
圖5展示了BERT3BERT3、BERT6BERT6、BERT12BERT12的推理時間即引數量, 實驗表明Patient-KD方法實現了幾乎線性的加速,BERT6BERT6和BERT3BERT3分別提速1.94倍和3.73倍。
3.DistilBERT蒸餾
3.1. DistilBERT 簡介
論文地址:DistilBERT, a distilled version of BERT: smaller, faster, cheaper and lighter

圖1: 幾個預訓練模型的引數量統計
近年來,大規模預訓練語言模型成為NLP任務的基本工具,雖然這些模型帶來了顯著的改進,但它們通常擁有數億個引數(如圖1所示),而這會引起兩個問題。首先,大型預訓練模型需要的計算成本很高。其次,預訓練模型不斷增長的計算和記憶體需求可能會阻礙語言處理應用的廣泛落地。因此,作者提出DistilBERT,它表明小模型可以通過知識蒸餾從大模型中學習,並可以在許多下游任務中達到與大模型相似的效能,從而使其在推理時更輕、更快。
3.2. 模型實現
學生網路結構
學生網路DistilBERT具有與BERT相同的通用結構,但token-type embedding和pooler層被移除,層數減半。學生網路通過從教師網路中每兩層抽取一層來進行初始化。
Training loss
LceLce 訓練學生模仿教師模型的輸出分佈:
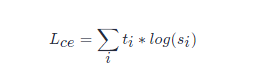
其中,titi和sisi分別是教師網路和學生網路的預測概率。
同時使用了Hinton在2015年提出的softmax-temperature:

其中,TT控制輸出分佈的平滑度,當T變大時,類別之間的差距變小;當T變小時,類別間的差距變大。zizi代表分類ii的模型分數。在訓練時對學生網路和教師網路使用同樣的temperature TT,在推理時,設定T=1T=1,恢復為標準的softmax。
最終的loss函數為LceLce、Mask language model loss LmlmLmlm(參考BERT)和 cosine embedding loss LcosLcos(student和teacher隱藏狀態向量的cos計算)的線性組合。
3.3. 實驗結果
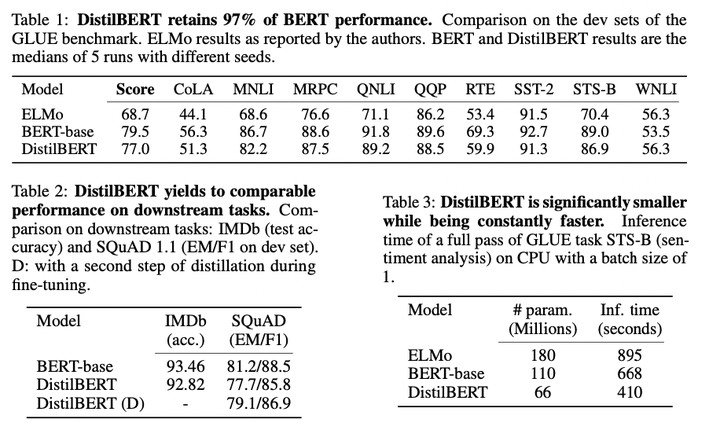
圖2:在GLUE資料集上的測試結果、下游任務測試和引數量對比
根據上圖我們可以看到,DistilBERT與BERT相比減少了40%的引數,同時保留了BERT 97%的效能,但提高了60%的速度。
4.DynaBERT蒸餾
4.1. DynaBERT 簡介
論文地址:DynaBERT: Dynamic BERT with Adaptive Width and Depth
預訓練模型,如BERT,在自然語言處理任務中的強大之處是毫無疑問,但是由於模型引數量較多、模型過大等問題,在部署方面對裝置的運算速度和記憶體大小都有著極高的要求。因此,面對實際產業應用時,比如將模型部署到手機上時,就需要對模型進行瘦身壓縮。近年的模型壓縮方式基本上都是將大型的BERT網路壓縮到一個固定的小尺寸網路。而實際工作中,不同的任務對推理速度和精度的要求不同,有的任務可能需要四層的壓縮網路而有的任務會需要六層的壓縮網路。DynaBERT(dynamic BERT)提出一種不同的思路,它可以通過選擇自適應寬度和深度來靈活地調整網路大小,從而得到一個尺寸可變的網路。
4.2. 模型實現
DynaBERT的訓練階段包括兩部分,首先通過知識蒸餾的方法將teacher BERT的知識遷移到有自適應寬度的子網路student DynaBERTWDynaBERTW中,然後再對 DynaBERTWDynaBERTW 進行知識蒸餾得到同時支援深度自適應和寬度自適應的子網路 DynaBERT。訓練過程流程圖如圖1所示。
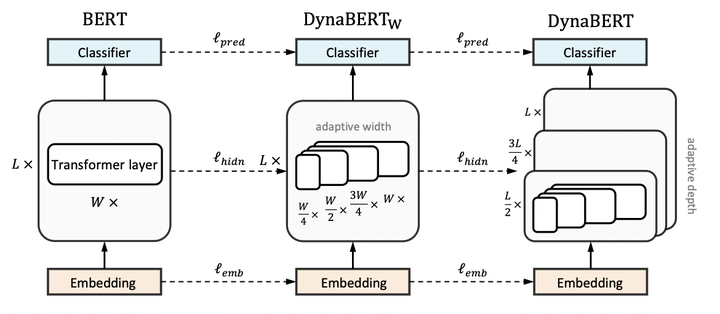
圖1: DynaBERT的訓練過程
寬度自適應 Adaptive Width
一個標準的transfomer中包含一個多頭注意力(MHA)模組和一個前饋網路(FFN)。在論文中,作者通過變換注意力頭的個數 NhNh 和前饋網路中中間層的神經元個數 dffdff 來更改transformer的寬度。同時定義一個縮放係數 mwmw 來進行剪枝,保留MHA中最左邊的 [mwNH][mwNH] 個注意力頭和 FFN中 [mwdff][mwdff] 個神經元。
為了充分利用網路的容量,更重要的頭部或神經元應該在更多的子網路中共用。因此,在訓練寬度自適應網路前,作者在 fine-tuned BERT網路中根據注意力頭和神經元的重要性對它們進行了排序,然後在寬度方向上以降序進行排列。這種選取機制被稱為 Network Rewiring。
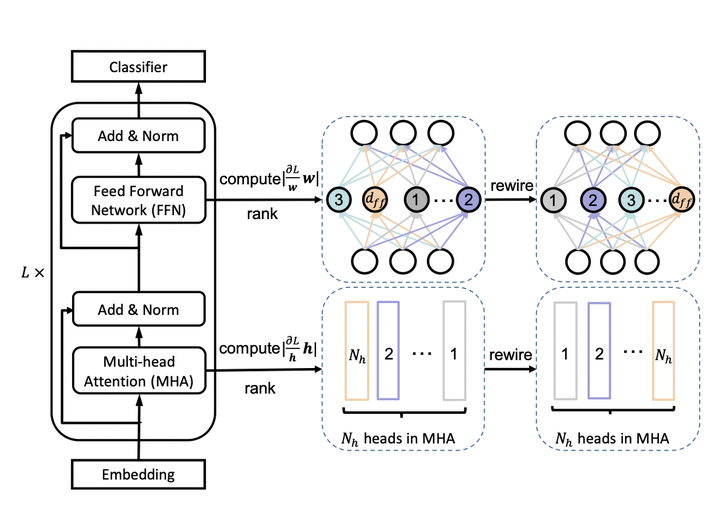
圖2: Network Rewiring
那麼,要如何界定注意力頭和神經元的重要性呢?作者參考 P. Molchanov et al., 2017 和 E. Voita et al., 2019 兩篇論文提出,去掉某個注意力頭或神經元前後的loss變化,就是該注意力頭或神經元的重要程度,變化越大則越重要。
訓練寬度自適應網路
首先,將BERT網路作為固定的教師網路,並初始化 DynaBERTWDynaBERTW。然後通過知識蒸餾將知識從教師網路遷移到 DynaBERTWDynaBERTW 中不同寬度的學生子網路。其中,mw=[1.0,0.75,0.5,0.25]mw=[1.0,0.75,0.5,0.25]。
模型蒸餾的loss定義為:

訓練深度自適應網路

4.3. 實驗結果
根據不同的寬度和深度剪裁係數,作者最終得到12個大小不同的DyneBERT模型,其在GLUE上的效果如下:
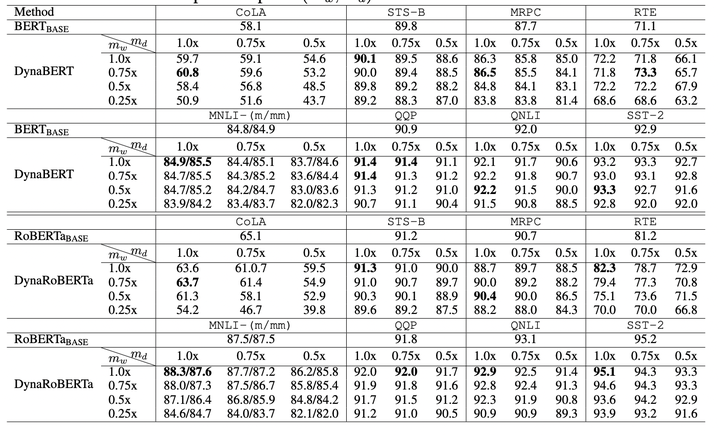
圖3: results on GLUE benchmark
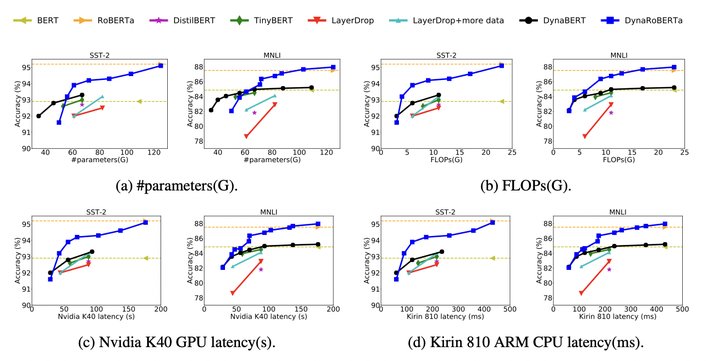
圖4:Comparison of #parameters, FLOPs, latency on GPU and CPU between DynaBERT and DynaRoBERTa and other methods.
可以看到論文中提出的DynaBERT和DynaRoBERTa可以達到和 BERTBASEBERTBASE 及 DynaRoBERTaDynaRoBERTa 相當的精度,但是通常包含更少的引數,FLOPs或更低的延遲。在相同效率的約束下,從DynaBERT中提取的子網效能優於DistilBERT和TinyBERT。
5.TinyBERT 蒸餾
5.1. TinyBERT 簡介
論文地址:TinyBERT: Distilling BERT for Natural Language Understanding
預訓練模型的提出,比如BERT,顯著的提升了很多自然語言處理任務的表現,它的強大是毫無疑問的。但是他們普遍存在引數過多、模型龐大、推理時間過長、計算昂貴等問題,因此很難落地到實際的產業應用中。TinyBERT是由華中科技大學和華為諾亞方舟實驗室聯合提出的一種針對transformer-based模型的知識蒸餾方法,以BERT為例對大型預訓練模型進行研究。四層結構的 TinyBERT4TinyBERT4 在 GLUE benchmark 上可以達到 BERTbaseBERTbase 96.8%及以上的效能表現,同時模型縮小7.5倍,推理速度提升9.4倍。六層結構的 TinyBERT6TinyBERT6 可以達到和 BERTbaseBERTbase 同樣的效能表現。
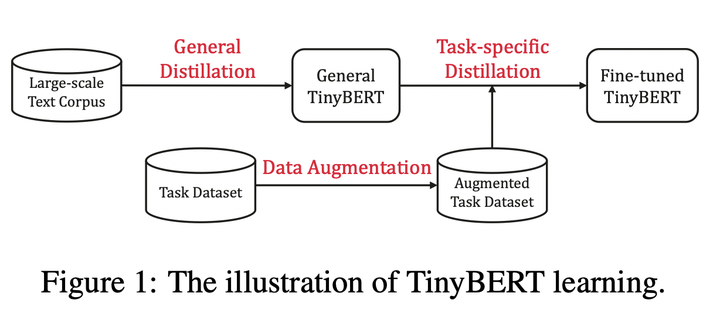
圖1: TinyBERT learning
TinyBERT主要做了以下兩點創新:
- 提供一種新的針對 transformer-based 模型進行蒸餾的方法,使得BERT中具有的語言知識可以遷移到TinyBERT中去。
- 提出一個兩階段學習框架,在預訓練階段和fine-tuning階段都進行蒸餾,確保TinyBERT可以充分的從BERT中學習到一般領域和特定任務兩部分的知識。
5.2. 模型實現
5.2.1知識蒸餾
知識蒸餾的目的在於將一個大型的教師網路 TT 學習到的知識遷移到小型的學生網路 SS 中。學生網路通過訓練來模仿教師網路的行為。fSfS 和 fTfT 代表教師網路和學生網路的behavior functions。這個行為函數的目的是將網路的輸入轉化為資訊性表示,並且它可被定義為網路中任何層的輸出。在基於transformer的模型的蒸餾中,MHA(multi-head attention)層或FFN(fully connected feed-forward network)層的輸出或一些中間表示,比如注意力矩陣 AA 都可被作為行為函數使用。
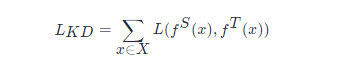
其中 L(⋅)L(⋅) 是一個用於評估教師網路和學生網路之間差異的損失函數,xx 是輸入文字,XX 代表訓練資料集。因此,蒸餾的關鍵問題在於如何定義行為函數和損失函數。
5.2.2 Transformer Distillation
假設TinyBert有M層transformer layer,teacher BERT有N層transformer layer,則需要從teacher BERT的N層中抽取M層用於transformer層的蒸餾。n=g(m)n=g(m) 定義了一個從學生網路到教師網路的對映關係,表示學生網路中第m層網路資訊是從教師網路的第g(m)層學習到的,也就是教師網路的第n層。TinyBERT嵌入層和預測層也是從BERT的相應層學習知識的,其中嵌入層對應的指數為0,預測層對應的指數為M + 1,對應的層對映定義為 0=g(0)0=g(0) 和 N+1=g(M+1)N+1=g(M+1)。在形式上,學生模型可以通過最小化以下的目標函數來獲取教師模型的知識:
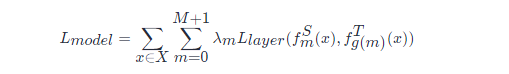
其中 LlayerLlayer 是給定的模型層的損失函數(比如transformer層或嵌入層),fmfm 代表第m層引起的行為函數,λmλm 表示第m層蒸餾的重要程度。
TinyBERT的蒸餾分為以下三個部分:transformer-layer distillation、embedding-layer distillation、prediction-layer distillation。
Transformer-layer Distillation
Transformer-layer的蒸餾由attention based蒸餾和hidden states based蒸餾兩部分組成。
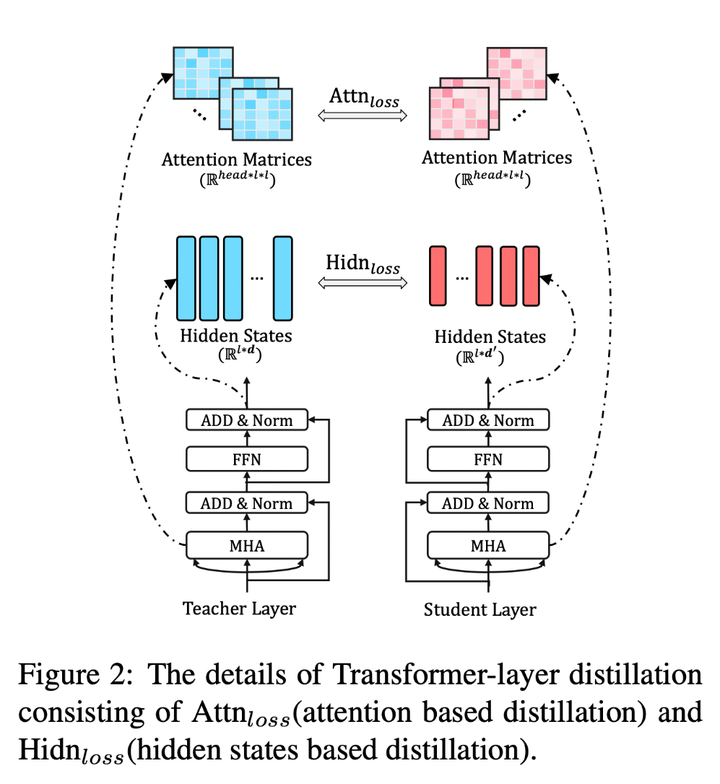
圖2: Transformer-layer distillation
其中,attention based蒸餾是受到論文Clack et al., 2019的啟發,這篇論文中提到,BERT學習的注意力權重可以捕獲豐富的語言知識,這些語言知識包括對自然語言理解非常重要的語法和共指資訊。因此,TinyBERT提出attention based蒸餾,其目的是使學生網路很好地從教師網路處學習到這些語言知識。具體到模型中,就是讓TinyBERT網路學習擬合BERT網路中的多頭注意力矩陣,目標函數定義如下:

對上述三個部分的loss函數進行整合,則可以得到教師網路和學生網路之間對應層的蒸餾損失如下:
5.3. 實驗結果

圖3: Results evaluated on GLUE benchmark
作者在GLUE基準上評估了TinyBERT的效能,模型大小、推理時間速度和準確率如圖3所示。實驗結果表明,TinyBERT在所有GLUE任務上都優於 BERTTINYBERTTINY,並在平均效能上獲得6.8%的提升。這表明論文中提出的知識整理學習框架可以有效的提升小模型在下游任務中的效能。同時,TinyBERT4TinyBERT4 以~4%的幅度顯著的提升了KD SOTA基準線(比如,BERT-PKD和DistilBERT),引數縮小至~28%,推理速度提升3.1倍。與teacher BERTbaseBERTbase 相比,TinyBERT在保持良好效能的同時,模型縮小7.5倍,速度提升9.4倍。