現代C++學習指南-型別系統
在前一篇,我們提供了一個方向性的指南,但是學什麼,怎麼學卻沒有詳細展開。本篇將在前文的基礎上,著重介紹下怎樣學習C++的類別型系統。
寫在前面
在進入型別系統之前,我們應該先達成一項共識——儘可能使用C++的現代語法。眾所周知,出於相容性的考慮,C++中很多語法都是合法的。但是隨著新版本的推出,有些語法可能是不推薦或者是需要避免使用的。所以本篇也儘可能採用推薦的語法形式(基於C++11或以上版本),這也是現代C++標題的含義。
採用現代語法有兩點好處。其一,現代語法可以編譯出更快更健壯的程式碼。編譯器也是隨著語言的發展而發展的,現代語法可以在一定程度上幫助編譯器做更好的優化。其二,現代語法通常更簡潔,更直觀,也更統一,有助於增強可讀性和可維護性。
明確了這點後,讓我們一起踏入現代C++的大門吧。
型別系統
程式是一種計算工具,根據輸入,和預定義的計算方法,產生計算結果。當程式執行起來後,這三者都需要在記憶體中表示成合適的值才能讓程式正常工作,負責解釋的這套工具就是型別系統。數位,字串,鍵盤滑鼠事件等都是資料,而且在記憶體中實際存在的形式也是一樣的,但是按我們人類的眼光來看的話,對它們的處理是不一樣的。數位能進行加減乘除等算術運算,但是對字串進行算術運算就沒有意義,而鍵盤滑鼠的值通常只是讀取,不進行計算的。正是由於這些差異,程式語言的第一個任務就是需要定義一套型別系統,告訴計算機怎樣處理記憶體中的資料。
為了讓程式語言儘可能簡單,程式語言一般把型別系統分為兩步實現,一部分是編譯器,另一部分是型別。編譯器那部分負責將開發者的程式碼解釋成合適的形式,以便可以高效,準確在記憶體中表示。型別部分則定義一些編譯器能處理的型別,以便開發者可以找到合適的資料來完成輸入輸出的表示和計算方法的描述。這兩者相輔相成,相互成就。
型別作為型別系統的重要表現形式,在程式語言中的重要性也就不言而喻了。如果把寫程式看成是搭積木的話,那麼程式的積木就是型別系統。型別系統是開發者能操作的最小單位,它限制了開發者的操作規則,但是提供了無限的可能。C++有著比積木更靈活的型別系統。
型別
型別是程式語言的最小單位,任何一句程式碼都是一種記憶體使用形式。
而談到C++的類別型也就不得不談到它的三種型別表現形式——普通型別,指標,參照。它們是三種不同的記憶體使用和解釋形式,也是C++的最基礎的形式。和大部分程式語言不同,C++對內建型別沒有做特權處理,只要開發者願意,所有的型別都可以有一致的語法形式(通過運運算元過載),所以下面關於型別的舉例適合所有的型別。
普通型別就是沒有修飾的型別,如int,long,double等。它們是按值傳遞的,也就是賦值和函數傳參是拷貝一份值,對拷貝後的值進行操作,不會再影響到老值。
int a=1; //老值,存在地址1
int b=a; //新值,存在地址2
b=2; //改變新值,改變地址2
//此時a還是1,b變成了2
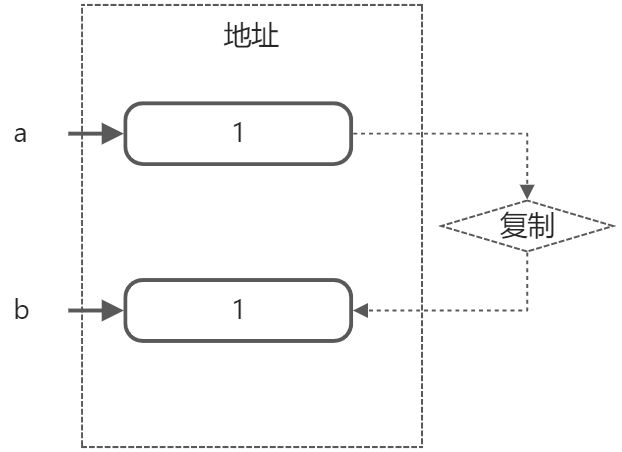
那假如我們需要修改老值呢,有兩種途徑,一種是指標,另一種則是參照。
指標是C/C++裡面的魔法,一切皆可指標。指標包含兩個方面,一方面它是指一塊記憶體,另一方面它可以指允許對這塊記憶體進行的操作。指標的值是一塊記憶體地址,操作指標,操作的是它指向的那塊地址。
int a=1; //老值,存在地址1
int* b=&a; //&代表取地址,從右往左讀,取a的地址——地址1,存在地址2
*b=2; //*是解除參照,意思是把存在地址2(b)的值取出來,並把那個地址(地址1)的值改成2
//此時a,*b變成了2
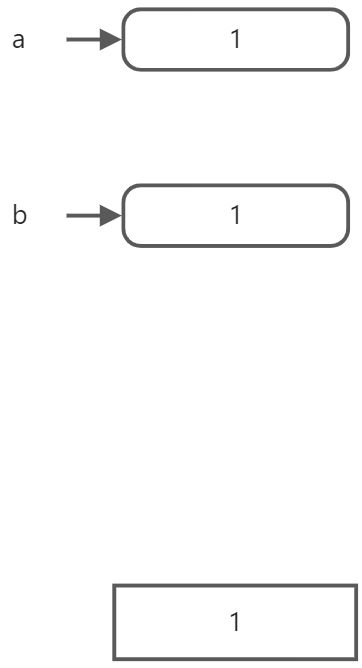
參照則是指標的改進版,參照能避免無效參照,不過參照不能重設,比指標缺少一定的靈活性。
int a=1; //老值,存在地址1
int& b=a; //&出現在變數宣告的位置,代表該變數是參照變數,參照變數必須在宣告時初始化
b=2; //可以像普通變數一樣操作參照變數,同時,對它的操作也會反應到原始物件上
//此時a,b變成了2
變數定義
型別僅僅是一種語法定義,而要真正使用這種定義,我們需要用型別來定義變數,即變數定義。
C++變數定義是以下形式:
type name[{initial_value}]
這裡的關鍵在於type。type是型別和限定符的組合。看下面的例子:
int a; //普通整型
int* b; //型別是int和*的組合,組成了整型指標
const int* c; //從右往左讀,*是指標,const int是常數整型,組成了指向常數整型的指標型別
int *const d; //也是從右往左讀,const是常數,後面是指標,說明這個指標是常數指標,指向最左邊的int,組成常數指標指向整型
int& e=a; //型別是int和&的組合,組成了整型參照
constexpr int f=a+e; //constexpr代表這個變數需要在編譯期求值,並且不再可變。
以上,基本就是變數定義的所有形式了,型別確定了變數的基本屬性,而限定符限定了變數的使用範圍。
定義變數也是按照這個步驟進行,首先確定我們需要什麼型別的變數,其次再進一步確定是否需要對這個變數新增限定,很多時候是需要的。可以按以下步驟來確定新增什麼樣的限定符:
- 是個大物件,可以考慮把變數宣告成參照型別。通常參照型別是比指標型別更優的選擇。
- 大物件可能需要被重置,可以考慮宣告為指標。
- 只想要個常數,新增
constexpr。 - 只想讀這個變數,新增
const。
變數初始化
變數定義往往伴隨著初始化,這對於區域性變數來說很重要,因為區域性變數的初值是不確定的,在沒有對變數進行有效初始化前就使用變數,會導致不可控的問題。所以嚴格來說,前面的變數定義是不完全正確的。
C++11推出了全新的,統一的初始化方式,即在變數名後面跟著大括號,大括號裡包著初始化的值。這種方式可以用在任何變數上,稱之為統一初始化,如:
int a{9527}; //普通型別
string b={"abc"}; //另一種寫法,等價但是不推薦
Student c{"張三","20220226",18}; //大括號中是建構函式引數
當然,除了用型別名來定義變數外,還可以將定義和初始化合二為一,變成下面這種最簡潔的形式:
auto a={1}; //推導為整型
auto b=string{"abc"};
auto c=Student{"張三","20220226",18}
這裡auto是讓編譯器自己確定型別的意思。上面這種寫法是完全利用了C++的類別型推導,這也是好多現代語言推薦的形式。不過需要注意的是,使用型別推導後,=就不能省略了。
有了初始化的變數後,我們就可以用它們完成各種計算任務了。C++為開發者實現了很多內建的計算支援。如數位的加減乘除運算,陣列的索引,指標的操作等。還提供了分支if,switch,迴圈while,for等語句,為我們提供了更靈活的操作。
函數
變數是程式語言中的最小單位,隨著業務的複雜度增加,有些時候中間計算會分散業務的邏輯,增加複雜度。為了更好地組織程式碼,型別系統增加了 函數來解決這個問題。
函數也是型別,是一種複合型別。它的型別由參數列,返回值組合而成,也就是說兩個函數,假如參數列和返回值一樣,那麼它們從編譯器的角度來看是等價的。當然光有它們還不夠,不然怎麼能出現兩個參數列和返回值一樣的函數呢。一個完整的函數還需要有個函數體和函數名。所以函數一般是下面這種形式:
//常規函數形式
[constexpr] 返回值 函數名(參數列)[noexcept]{
函數體
}
//返回值後置形式
auto 函數名(參數列)->返回值
當一個函數沒有函數體的時候,我們通常稱之為函數宣告。加上函數體就是一個函數定義。
void f(int); //函數宣告
void fun(int value){ //函數定義,因為有大括號代表的函數體
}
以上就是函數的基本框架,接下來我們分別來看一看組成它的各部分。
先說最簡單的函數名,它其實是函數這種型別的一個變數,這個變數的值表示從記憶體地址的某個位置開始的一段程式碼塊。前面也說過之所以能出現兩個參數列和返回值都相同的函數,但是編譯器能識別,其主要功勞就在函數名上,所以函數名也和變數名一樣,是一種識別符號。那假如反過來,函數名相同,但是參數列或者返回值不同呢,這種情況有個專有名詞——函數過載。基於函數是複合型別的認識,它們中只要其中一種不同就算過載。另外,在C++11,還有一種沒有名字的函數,稱為lambda表示式。lambda表示式是一種類似於直接量的函數值,就像13,'c'這種,是一種不提前定義函數,直接在呼叫處定義並使用的函數形式。
參數列是前面型別定義的升級款。所有前面說的關於變數定義的都適用於它,三種形式的變數定義,多個變數,變數初始化等。不過,它們都有了新名詞。參數列的變數稱為形式引數,初始化稱為預設引數。同樣形參在實際使用的時候需要初始化,不過初始化來自呼叫方。形式引數沒有預設值就需要在呼叫的時候提供引數,有預設值的可以省略。
int plus(int a,int b=1){ //b是一個預設引數
return a+b;
}
int main(void){
int c=plus(1); //沒有提供b的值,所以b初始化為1,結果是2
int d=plus(2,2); //a,b都初始化為2,結果是4
//int f=plus(1,2,3); //plus只有兩個形參,也就是兩個變數,沒法儲存三個值,所以編譯錯誤
return 0;
}
和參數列一樣,返回值也是一個變數,這個變數會通過return語句返回給呼叫者,所以從記憶體操作來看,它是一個賦值操作。
std::string msg(){
std::string input;
std::cin>>input;
return input;
}
int main(void){
auto a=msg();
std::string b=msg();//msg返回的input複製到了b中
return 0;
}
遺憾的是C++只支援單返回值,也就是一個函數呼叫最多隻能返回一個值,假如有多個值就只能以形參形式返回了,這種方式對於函數呼叫就不是很友好,所以C++提出了新的解決思路。
類
隨著業務的複雜度再次增加,函數形參個數可能會增加,或者可能需要返回多個值,然後在多個不同的函數間傳遞。這樣會導致資料容易錯亂,並且增加使用者的學習成本。
為了解決這些問題,工程師們提出了物件導向——多個資料打包的技術。表現在語言層面上,就是用類把一組操作和完成這組操作需要的資料打包在一起。資料作為類的屬性,操作作為類的方法,使用者通過方法操作內部資料,資料不再需要使用者自己傳遞,管理。這對於開發者無疑是大大簡化了操作。我們稱之為物件導向程式設計,而在函數間傳遞資料的方式稱為程式導向程式設計。這兩種方式底層邏輯其實是一致的,該傳遞的引數和函數呼叫一樣都不少,但是物件導向的區別是這些繁瑣、容易出錯的工作交給編譯器來做,開發者只需要按照物件導向的規則做好設計工作就好了,剩下的交給編譯器。至此,我們的型別系統又向上提升了一級。類不僅是多個型別的聚合體,還是多個函數的聚合體,是比函數更高階的抽象。
可以看下面程式導向程式設計和物件導向程式設計的程式碼對比
struct Computer{
bool booted;
friend std::ostream& operator<<(std::ostream& os,const Computer & c){
os<<"Computing";
return os;
}
};
void boot(Computer& c){
c.booted=true;
std::cout<<"Booting...";
}
void compute(const Computer& c){
if(c.booted){
std::cout<<"Compute with "<<c;
}
}
void shutdown(Computer& c){
c.booted=false;
std::cout<<"Shutdown...";
}
int main(void){
auto c=Computer();
boot(c);
compute(c);
shutdown(c);
return 0;
}
程式導向最主要的表現就是,開發者需要在函數間傳遞資料,並維護資料狀態,上面例子中的資料是c。
struct Computer{
bool booted;
friend std::ostream& operator<<(std::ostream& os,const Computer & c){
os<<"Computing";
return os;
}
void boot(){
booted=true;
std::cout<<"Booting...";
}
void compute(){
if(booted){
std::cout<<"Compute with "<<this;
}
}
void shutdown(){
booted=false;
std::cout<<"Shutdown...";
}
};
int main(void){
auto c=Computer();
c.boot();
c.compute();
c.shutdown();
return 0;
}
可以看出物件導向的程式碼最主要的變化是,方法的引數變少了,但是可以在方法裡面直接存取到類定義的資料。另一個變化發生在呼叫端。呼叫端是用資料呼叫方法,而不是往方法裡面傳遞資料。這也是物件導向的本質——以資料為中心。
當然,類的封裝功能只是類功能的一小部分,後面我們會涉及到更多的類知識。作為初學者,我們瞭解到這一步就能讀懂大部分程式碼了。
總結
型別系統是一門語言的基本構成部分,它支撐著整個系統的高階功能,很多高階特性都是在型別系統的基礎上演化而來的。所以學習語言的型別系統有個從低到高,又從高到低的過程,從最基礎的型別開始,學習如何從低階型別構築出高階型別,然後站在高階型別的高度上,審視高階型別是怎樣由低階型別構築的。這一上一下,一高一低基本上就能把語言的大部分特性瞭解清楚了。
低階型別更偏向於讓編譯器更好地工作,高階型別偏向於讓開發者更好地工作,C++從普通型別,函數,類提供了各個層級的支援,讓開發者有更多自由的選擇,當然也就增加了開發者的學習難度。但是開發者並不是都需要所有選擇的,所以我覺得正確的學習應該是以專案規模為指導的。一些專案,完全用不到物件導向,就可以把精力放在打造好用的函數集上。而有的專案,物件導向是很好的選擇,就需要在類上花費時間。回到開頭的積木例子,選用什麼積木完全看我們想搭什麼模型,要是沒有合適的積木,我們可以自己創造。這就是C++的迷人之處。