深入淺出MySQL

Photo by Merilin Kirsika Tedder from Pexels
一、MySQL的邏輯架構
MySQL作為一個流行的開源關係型資料庫管理系統,它可以執行在多種平臺上,支援多種儲存引擎,提供了靈活的資料操作和管理功能。MySQL的邏輯架構可以分為三層:連線層、服務層和引擎層,下方是網上流傳度很廣的一張架構圖。
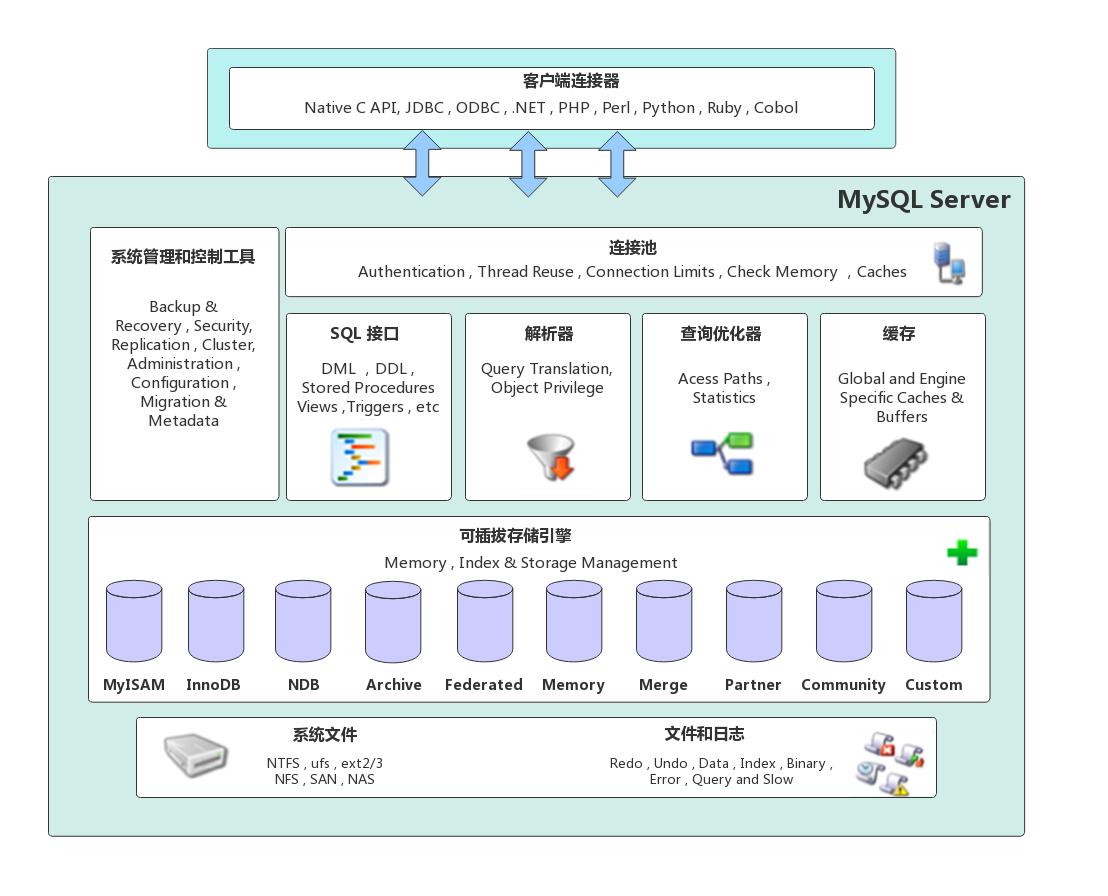
需要注意的是, 上圖描述的是MySQL5.7及以前的邏輯架構,MySQL8.0中正式移除了查詢快取元件, 因為從收集的資料來看查詢快取的命中率很低,即使是在MySQL5.7中查詢快取這個選項也是預設關閉的,所以本篇文章就不對快取這款內容做解析了。具體可以檢視官方的一篇部落格:
事實上,如果不去關注其內部的細節,《高效能MySQL》一書中的這張簡圖也足夠讓我們對其邏輯架構有一個直觀的認知:
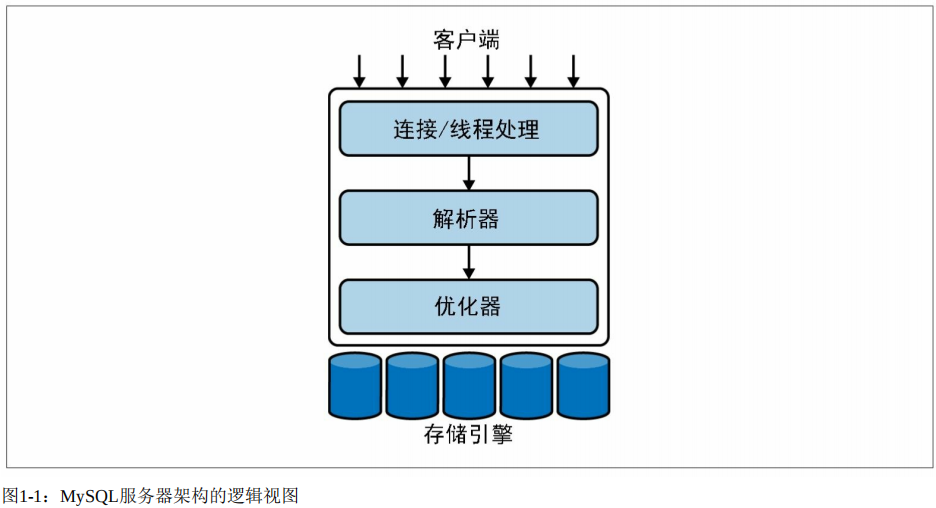
1、連線層詳解
當用戶端傳送連線請求時,MySQL伺服器會在連線層接收請求,分配一個執行緒來處理該連線,隨後進行身份驗證。具體的功能如下:
-
使用者端連線的建立與處理:當用戶端發起連線請求時,MySQL會建立一個專用的執行緒(以作業系統級別的執行緒實現)來為該使用者端服務。這些服務執行緒使用執行緒池裡的長連線服務多個使用者請求,減少了執行緒切換的開銷。
-
安全認證:安全認證是連線層的另一項重要任務。當用戶端連線到MySQL伺服器時,伺服器首先需要驗證使用者端的身份。MySQL使用基於使用者名稱、主機和密碼的認證方式。在連線時,使用者端需要提供有效的使用者名稱、主機名和密碼,伺服器會根據在"mysql.user"表中的資料進行驗證,若通過,則建立連線。
-
連線資源管理:MySQL支援可設定的最大連線數。當到達最大連線數時,新的連線請求會被拒絕。符合條件的使用者端可以設定連線超時時間、使用者端閒置關閉時間等引數。同時,可以通過"mysql.user"表設定特定使用者對於資料庫的操作許可權。
-
執行緒管理:MySQL會自動建立和管理連線執行緒,其中包括以執行緒數作為上限的執行緒池。執行緒池的目的是複用連線執行緒,避免了執行緒切換和建立的開銷。此外,MySQL使用非同步I/O機制和協程,儘可能提高了並行和吞吐量。
2、服務層詳解
服務層是MySQL中的核心元件,負責提供各種資料庫操作所需的基本功能,如SQL語法處理、事務管理、鎖管理等。
SQL語法處理
服務層負責從使用者端接收來自連線層的SQL查詢請求,並進行初始分析、解析和預處理。
- 查詢快取(MySQL8.0 中不存在):MySQL會將查詢語句和其結果快取在記憶體中。當收到一個相同的查詢請求時,先檢查快取中是否有匹配的結果。如果有匹配結果,則直接返回,並跳過剩餘的處理步驟。如果沒有匹配,將繼續執行下一個步驟。
- SQL解析器:服務層的SQL解析器主要進行語法解析。解析器會根據MySQL詞法分析器和語法分析器的解析規則,將查詢語句解析成一個字串表示的樹狀結構,用於儲存語法單位(詞素)及它們之間的關係。
- SQL預處理:在構建完成解析樹後,預處理模組對解析樹進行優化和處理。這包括檢查許可權、完整性約束、函數呼叫和資料型別等。在預處理階段,還可能對查詢進行改寫,例如將"UNION"操作轉換為"JOIN"操作,或者將子查詢轉換為連線操作。
事務管理
MySQL的服務層負責事務管理,確保在執行一系列操作時,滿足原子性、一致性、隔離性和永續性這四個特性。事務管理涉及的主要功能包括:
- 事務隔離級別:MySQL支援四個事務隔離級別:讀未提交、讀已提交、可重複讀和序列化。這些隔離級別分別定義了事務間資料存取的隔離程度,用於防止髒讀、不可重複讀和幻讀。
- 鎖管理:在事務過程中,可能需要對資料加鎖,以確保資料的一致性。MySQL支援的鎖型別包括共用鎖、排它鎖、意向鎖、行鎖、表鎖等。
- Undo紀錄檔:服務層通過Undo紀錄檔實現了事務回滾操作,當事務執行中途出現異常或使用者發出回滾請求時,可以通過Undo紀錄檔回滾資料到事務開始前的狀態。
- Redo紀錄檔:為了保證事務的永續性,在事務執行過程中,修改的資料首先寫入到Redo紀錄檔中,再更新到磁碟檔案上。在系統恢復過程中,可以通過Redo紀錄檔進行資料恢復。
快取管理
MySQL優化器使用快取來提高查詢速度,包括:
- 查詢快取:當相同的SQL查詢被多次執行時,可以從查詢快取中直接獲取結果,提高效能。由於MySQL 8.0中已移除了查詢快取功能,使用者需要自行實現相關功能,如使用Redis、Memcached等中間快取系統。
- 錶快取:用於儲存表的後設資料,如表的結構定義。當查詢需要表資訊時,優先從錶快取中獲取,避免磁碟操作。
- 執行緒快取:用於複用伺服器的連線執行緒。當一個連線關閉後,它的執行緒會被放回執行緒快取池中,供新的連線使用。執行緒池意味著減少了建立和銷燬執行緒的開銷。
- 緩衝池:主要用於InnoDB儲存引擎,緩衝池管理快取的資料頁,包括資料和索引。當需要存取這些頁時,可以直接從緩衝池讀取,提高存取速度。
3、引擎層詳解
引擎層負責儲存資料和執行SQL語句。MySQL支援多種儲存引擎,每種引擎各有特點,根據實際需求進行選用。當然,只要沒有非常明確的特殊需求就不需要更改儲存引擎,因為InnoDB在大部分場景下都比其他引擎更加適用。引擎層通過標準API與服務層互動,實現資料的儲存和查詢。
- InnoDB:InnoDB是MySQL的預設儲存引擎,提供了事務支援、行級鎖定、外來鍵約束等功能,主要用於高並行、高可靠性的OLTP場景。
- MyISAM:MyISAM通常用於唯讀資料表,適用於簡單查詢和全文索引。其不支援事務、行級鎖等功能,適用於OLAP場景。
- Memory:Memory儲存引擎支援雜湊和B樹索引,它將資料儲存在記憶體中,易受到系統斷電或宕機等影響,具有較高的寫效能但不適用於大規模資料分佈。
- 其他儲存引擎:MySQL還支援如Archive、NDB Cluster等其他儲存引擎,它們分別適用於存檔表、分散式資料庫等不同場景。
我們可以在SQL命令列中執行 show engines; 來檢視當前支援的儲存引擎:
mysql> show engines;
+--------------------+---------+----------------------------------------------------------------+--------------+------+------------+
| Engine | Support | Comment | Transactions | XA | Savepoints |
+--------------------+---------+----------------------------------------------------------------+--------------+------+------------+
| FEDERATED | NO | Federated MySQL storage engine | NULL | NULL | NULL |
| MEMORY | YES | Hash based, stored in memory, useful for temporary tables | NO | NO | NO |
| InnoDB | DEFAULT | Supports transactions, row-level locking, and foreign keys | YES | YES | YES |
| PERFORMANCE_SCHEMA | YES | Performance Schema | NO | NO | NO |
| MyISAM | YES | MyISAM storage engine | NO | NO | NO |
| MRG_MYISAM | YES | Collection of identical MyISAM tables | NO | NO | NO |
| BLACKHOLE | YES | /dev/null storage engine (anything you write to it disappears) | NO | NO | NO |
| CSV | YES | CSV storage engine | NO | NO | NO |
| ARCHIVE | YES | Archive storage engine | NO | NO | NO |
+--------------------+---------+----------------------------------------------------------------+--------------+------+------------+
9 rows in set (0.00 sec)
二、MySQL語句執行流程
SQL語句的執行流程可以簡單分為以下幾個步驟:
- 聯結器:使用者端連線到MySQL伺服器,聯結器負責驗證使用者端的身份和許可權,如果通過驗證,就建立一個連線,並從許可權表中讀取該使用者的所有許可權資訊。
- 語法分析:在執行SQL語句之前,MySQL需要對SQL語句進行語法分析。語法分析器會檢查SQL語句是否符合語法規則,並將其轉換為一棵語法樹。如果SQL語句不符合語法規則,MySQL將會返回一個錯誤訊息。語意分析是在語法分析之後進行的。它會檢查SQL語句是否符合語意規則,並將其轉換為一棵語意樹。語意分析器會檢查表名、列名、資料型別等資訊是否正確。如果SQL語句不符合語意規則,MySQL將會返回一個錯誤訊息。
- 查詢優化:在語意分析之後,MySQL會對SQL語句進行查詢優化。查詢優化器會分析查詢語句,並生成一個最優的執行計劃。執行計劃是指MySQL執行SQL語句的具體步驟,包括使用哪些索引、如何連線表等。
- 執行SQL語句:在查詢優化之後,MySQL會執行SQL語句。執行器會按照執行計劃的步驟,逐步執行SQL語句。執行器會根據查詢語句,從磁碟讀取資料,並將其儲存在記憶體中。然後,執行器會對資料進行排序、分組、聚合等操作,最終生成查詢結果。
另外請注意,本篇文章依舊是在為後續寫MySQL優化流程做知識上的鋪墊,所以一些細節會簡單介紹,但實際的SQL優化思想會等到後面的文章再詳細介紹。
下面我們來詳細解釋一下SQL語句的執行流程和細節。
1. 語法分析
語法分析是MySQL執行SQL語句的第一步。語法分析器會對SQL語句進行分析,檢查其是否符合語法規則。如果SQL語句不符合語法規則,MySQL將會返回一個錯誤訊息。詳細的來說又可分為以下幾步:
- 詞法分析:主要負責從SQL語句中提取關鍵字,比如:查詢的表,欄位名,查詢條件等等。詞法分析器會將SQL語句分割成一個個的詞法單元(token),併為每個token賦予一個型別(type)和值(value)。
- 語法規則:主要判斷SQL語句是否合乎MySQL的語法。語法規則模組會使用yacc工具生成的語法分析器,根據MySQL的語法規則(grammar rule)來檢查詞法單元是否符合語法要求。
- 語意分析:主要負責檢查SQL語句的語意是否正確,比如:表名和欄位名是否存在,資料型別是否匹配,函數是否合法等。語意分析器會根據資料字典(data dictionary)和目錄(catalog)來驗證SQL語句的有效性。
MySQL使用的語法分析器是Bison。它是一種自動生成解析器的工具,可以根據語法規則自動生成語法分析器。下面是一個範例SQL語句:
SELECT name, age FROM student WHERE id = 1;
在語法分析階段,MySQL會進行以下操作:
- 詞法分析:將SQL語句分割成以下詞法單元:
| token | type | value |
|---|---|---|
| SELECT | keyword | select |
| name | identifier | name |
| , | symbol | , |
| age | identifier | age |
| FROM | keyword | from |
| student | identifier | student |
| WHERE | keyword | where |
| id | identifier | id |
| = | operator | = |
| 1 | number | 1 |
- 語法規則:根據MySQL的語法規則,檢查詞法單元是否符合以下格式:
select_statement: SELECT select_expression_list FROM table_reference_list [WHERE where_condition]
- 語意分析:根據資料字典和目錄,檢查以下內容:
- 表student是否存在
- 欄位name, age, id是否屬於表student
- 欄位id的資料型別是否與數位1匹配
- 等等
如果以上步驟都沒有出現錯誤,那麼MySQL就會認為這條SQL語句在語法分析階段是正確的,並繼續進行後續的處理。否則,MySQL就會報錯,並停止執行這條SQL語句。
2. 查詢優化
查詢優化是MySQL執行SQL語句的第三步。SQL語句在查詢優化階段會經歷以下步驟:
- 查詢重寫:MySQL會對SQL語句進行一些語法和邏輯上的變換,以便於後續的優化和執行。例如,將子查詢轉換為連線,將or條件轉換為union,將in條件轉換為exists等。
- 查詢分解:MySQL會將一條複雜的SQL語句分解為多個簡單的子查詢,每個子查詢可以單獨優化和執行。例如,將union查詢分解為多個select查詢,將關聯子查詢分解為獨立的select查詢等。
- 預處理:MySQL會對SQL語句進行一些基本的檢查和處理,例如檢查語法錯誤,解析引數,分配內部資源等。
- 優化器:MySQL會根據統計資訊和成本模型,為SQL語句選擇一個最佳的執行計劃。執行計劃包括了連線順序,存取方法,索引選擇,排序策略等。
舉例說明,下面是一個範例SQL語句:
SELECT name, age FROM student WHERE id IN (SELECT student_id FROM score WHERE score > 80);
則首先在查詢重寫時,MySQL會將這條SQL語句重寫為:
SELECT name, age FROM student s JOIN score c ON s.id = c.student_id WHERE c.score > 80;
這樣做的好處是:
- 連線查詢通常比子查詢更快,因為MySQL優化器可以生成更佳的執行計劃,可以預先裝載資料,更高效地處理查詢。
- 子查詢往往需要執行重複的查詢,子查詢生成的臨時表上也沒有索引,因此效率會更低。
- 連線查詢可以利用索引加速,比如在student表的id列和score表的student_id列上建立索引。
接下來在查詢分解階段,MySQL會將這條SQL語句分解為兩個子查詢:
SELECT name, age, id FROM student;
SELECT student_id FROM score WHERE score > 80;
預處理時MySQL會對SQL語句進行一些基本的檢查和處理,例如檢查表名和欄位名是否存在,解析引數等。
最後優化器會根據統計資訊和成本模型,為SQL語句選擇一個最佳的執行計劃。
MySQL優化器是負責為SQL語句選擇一個最佳的執行計劃的模組。執行計劃包括了連線順序,存取方法,索引選擇,排序策略等。MySQL優化器是基於成本的優化器(cost-based optimizer),也就是說它會根據統計資訊和成本模型來估算不同執行計劃的代價,並選擇代價最小的那個。
MySQL優化器在選擇執行計劃時會考慮以下幾個方面:
- 表依賴關係:MySQL優化器會分析SQL語句中涉及到的表之間是否有依賴關係,比如外來鍵約束,主鍵約束等。這些依賴關係會影響連線順序和存取方法的選擇。
- 可用索引:MySQL優化器會分析SQL語句中參與條件過濾或排序的列是否有可用索引,並根據索引型別和覆蓋度來選擇合適的索引。
- 預估行數:MySQL優化器會根據資料字典和目錄中儲存的統計資訊來預估每個表或每個索引範圍內的行數。這些行數會影響成本模型中的I/O代價和CPU代價。
- 預估成本:MySQL優化器會根據預估行數和成本常數(cost constant)來預估每個執行計劃的成本。成本常數是一些固定引數,比如隨機讀一頁資料的代價,排序一行資料的代價等。MySQL優化器會選擇成本最低的執行計劃。
例如,上面能夠重寫後的SQL語句應該是:
SELECT name, age FROM student s JOIN score c ON s.id = c.student_id WHERE c.score > 80;
MySQL優化器在選擇執行計劃時會進行以下操作:
- 分析表依賴關係:發現student表和score表之間沒有依賴關係,因此可以任意調整連線順序。
- 分析可用索引:發現student表有一個主鍵索引idx_student_id(id),
這麼一通分析之後到底有點紙上談兵,接下來我們在MySQL 8.0 裡執行命令,畢竟實踐出真知。進入MySQL命令列,利用explain來檢視執行計劃:
mysql> SELECT name, age FROM student WHERE id IN (SELECT student_id FROM score WHERE score > 80);
+----------+------+
| name | age |
+----------+------+
| zhangsan | 18 |
| wangwu | 20 |
+----------+------+
2 rows in set (0.00 sec)
mysql> explain SELECT name, age FROM student WHERE id IN (SELECT student_id FROM score WHERE score > 80);
+----+-------------+---------+------------+------+---------------+------+---------+------+------+----------+-----------------------------------------------------------------+
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
+----+-------------+---------+------------+------+---------------+------+---------+------+------+----------+-----------------------------------------------------------------+
| 1 | SIMPLE | student | NULL | ALL | PRIMARY | NULL | NULL | NULL | 4 | 100.00 | NULL |
| 1 | SIMPLE | score | NULL | ALL | student_id | NULL | NULL | NULL | 8 | 12.50 | Using where; FirstMatch(student); Using join buffer (hash join) |
+----+-------------+---------+------------+------+---------------+------+---------+------+------+----------+-----------------------------------------------------------------+
2 rows in set, 1 warning (0.01 sec)
我們可以在explain的結果中看到,兩行的ID值都為1,而我們自己寫的SQL語句裡有兩個Select,說明實際並沒有按照我們的原SQL來執行
再使用show warnings來檢視實際執行的sql內容:
mysql> show warnings;
+-------+------+----------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------+
| Level | Code | Message |
+-------+------+----------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------+
| Note | 1003 | /* select#1 */ select `datasets`.`student`.`name` AS `name`,`datasets`.`student`.`age` AS `age` from `datasets`.`student` semi join (`datasets`.`score`) where ((`datasets`.`score`.`student_id` = `datasets`.`student`.`id`) and (`datasets`.`score`.`score` > 80)) |
+-------+------+----------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------+
1 row in set (0.00 sec)
可以發現,實際執行的時候用的是semi join,這是因為Semi Join返回的結果只包含主表(左表)中滿足連線條件的行,而不包含從表(右表)的任何資料。它的主要目的是通過減少要比較的資料量來提高查詢效能。通過使用Semi Join,可以避免將兩個表的所有資料進行連線,並僅僅關注滿足連線條件的部分資料。
但是對於開發人員來說,我們並不需要關注優化器內部的所有決策,因為涉及的因素太多了,所以我們從整體上來看知道大致的優化方向即可。
這裡也給出上面範例的建表語句,方便有心的讀者自行嘗試:
CREATE TABLE student
(
id INT PRIMARY KEY auto_increment,
name VARCHAR(20),
age INT
) charset = utf8mb4;
CREATE TABLE score
(
student_id INT,
course VARCHAR(20),
score INT,
FOREIGN KEY (student_id) REFERENCES student (id)
) charset = utf8mb4;
INSERT INTO student (id, name, age) VALUES (1, 'zhangsan', 18),(2, 'lisi', 19),(3, 'wangwu', 20),(4, 'zhaoliu', 21);
INSERT INTO score (student_id, course, score) VALUES (1, '數學', 85),(1, '語文', 90),(2, '數學', 75),(2, '語文', 80),(3, '數學', 95),(3, '語文', 100),(4, '數學', 65),(4, '語文', 70);
SELECT name, age FROM student WHERE id IN (SELECT student_id FROM score WHERE score > 80);
3. 執行SQL語句
執行SQL語句是MySQL執行SQL語句的最後一步。簡單來說,執行器會按照執行計劃的步驟,逐步執行SQL語句。執行器會根據查詢語句,從磁碟讀取資料,並將其儲存在記憶體中。然後,執行器會對資料進行排序、分組、聚合等操作,最終生成查詢結果。
說的詳細一點,一些重要的步驟如下:
- 開啟表:MySQL會根據執行計劃中涉及到的表,開啟相應的表檔案,併為每個表分配一個表控制程式碼(table handle)。
- 鎖定表:MySQL會根據SQL語句的型別(讀或寫)和事務的隔離級別,為涉及到的表加上相應的鎖(共用鎖或排他鎖)。鎖的作用是保證資料的一致性和並行性。
- 讀取資料:MySQL會根據執行計劃中選擇的存取方法(全表掃描或索引掃描),從儲存引擎中讀取資料。儲存引擎是負責管理資料檔案的模組,不同的儲存引擎有不同的特性和優化。
- 過濾資料:MySQL會根據執行計劃中的過濾條件(where,group by,having,order by,limit等),對讀取到的資料進行過濾和處理。過濾條件可以減少返回給使用者端的資料量,提高查詢效率。
- 返回結果:MySQL會將過濾後的資料返回給使用者端,並釋放相關的資源(表控制程式碼,鎖等)。使用者端可以接收到結果集,並進行後續的操作。
實際上,依舊可以通過MySQL命令列來了解其執行過程:
mysql> set profiling = 'ON';
Query OK, 0 rows affected, 1 warning (0.00 sec)
mysql> SELECT name, age FROM student WHERE id IN (SELECT student_id FROM score WHERE score > 80);
+----------+------+
| name | age |
+----------+------+
| zhangsan | 18 |
| wangwu | 20 |
+----------+------+
2 rows in set (0.00 sec)
mysql> show profile for query 1;
+--------------------------------+----------+
| Status | Duration |
+--------------------------------+----------+
| starting | 0.000094 |
| Executing hook on transaction | 0.000005 |
| starting | 0.000008 |
| checking permissions | 0.000005 |
| checking permissions | 0.000004 |
| Opening tables | 0.000088 |
| init | 0.000009 |
| System lock | 0.000009 |
| optimizing | 0.000012 |
| statistics | 0.000035 |
| preparing | 0.000076 |
| executing | 0.000065 |
| end | 0.000004 |
| query end | 0.000005 |
| waiting for handler commit | 0.000009 |
| closing tables | 0.000008 |
| freeing items | 0.000021 |
| cleaning up | 0.000010 |
+--------------------------------+----------+
18 rows in set, 1 warning (0.00 sec)
可以看到,命令執行結果非常詳細的列出了所有步驟,本文只是挑選了一部分來展開說。
具體結合到例子來說明,假設有一條SQL語句如下:
SELECT name, age FROM student s JOIN score c ON s.id = c.student_id WHERE c.score > 80 ORDER BY s.age LIMIT 10;
在執行階段,MySQL會進行以下操作:
- 開啟表:MySQL會開啟student表和score表,併為它們分配兩個表控制程式碼s和c。
- 鎖定表:MySQL會根據SQL語句是讀操作,並且假設事務的隔離級別是可重複讀(repeatable read),為student表和score表加上共用鎖(shared lock)。
- 讀取資料:MySQL會根據執行計劃中選擇的存取方法,從儲存引擎中讀取資料。假設執行計劃是先掃描score表的索引idx_score(score),然後回表獲取student_id列,再通過student_id列關聯到student表,並獲取name和age列。
- 過濾資料:MySQL會根據執行計劃中的過濾條件,對讀取到的資料進行過濾和處理。具體步驟如下:
- 根據where條件c.score > 80,篩選出符合條件的記錄。
- 根據order by條件s.age,對記錄按照學生年齡進行排序。
- 根據limit條件10,只取前10條記錄作為結果集。
- 返回結果:MySQL會將結果集返回給使用者端,並釋放相關的資源。
三、InnoDB儲存結構
InnoDB是MySQL的預設儲存引擎,它支援事務、行級鎖、外來鍵、MVCC等特性,提供了高效能和高可靠性的資料儲存方案。InnoDB的底層結構主要由兩部分組成:記憶體結構和磁碟結構。
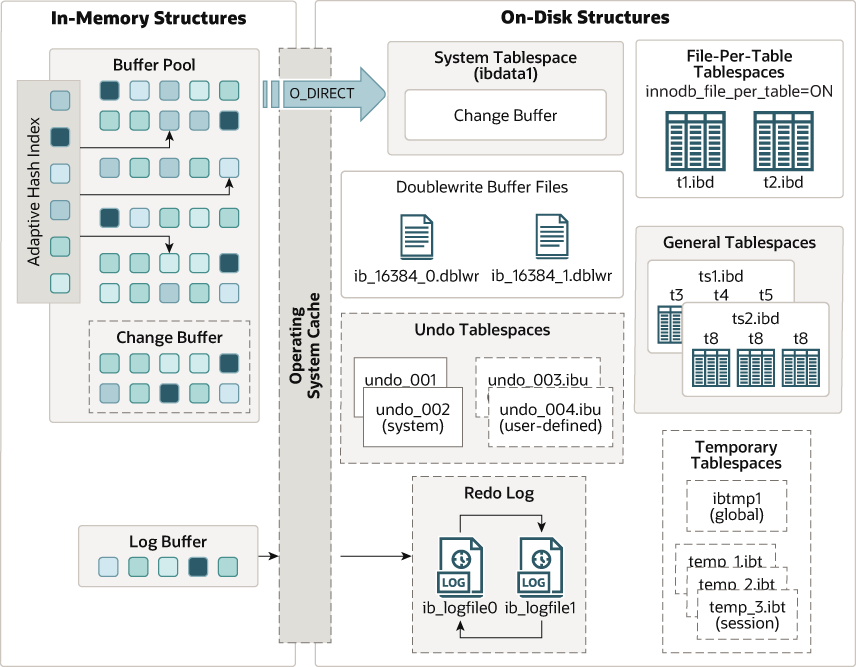
圖片來源:https://dev.mysql.com/doc/refman/8.0/en/innodb-architecture.html
記憶體結構
InnoDB的記憶體結構主要包括以下幾個部分:
- 緩衝池(Buffer Pool)
- 更改緩衝區(Change Buffer)
- 自適應雜湊索引(Adaptive Hash Index)
- 紀錄檔緩衝區( Log Buffer)
如果對這部分內容感興趣可以看官方檔案,這裡只做一個簡單的介紹。
緩衝池(Buffer Pool)
主要用於快取表資料和索引資料,加快存取速度。緩衝池是InnoDB記憶體結構中最重要的部分,通常佔用宿主機80%的記憶體。緩衝池被分成多個頁,每頁預設大小為16KB,每頁可以存放多條記錄。緩衝池中的頁按照LRU(最近最少使用)演演算法進行淘汰,同時也被分成兩個子連結串列:New Sublist和Old Sublist,分別存放存取頻繁和不頻繁的頁。
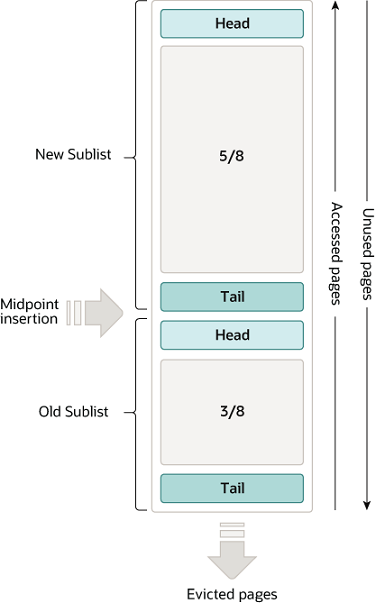
- New Sublist:佔用緩衝池5/8的空間,存放最近被存取過的頁。當一個新的頁被讀入緩衝池時,會被放在New Sublist的最前端。當一個已經存在於緩衝池的頁被存取時,如果它在New Sublist中,則不會改變位置;如果它在Old Sublist中,則會被移動到New Sublist的最前端。
- Old Sublist:佔用緩衝池3/8的空間,存放較久未被存取過的頁。當一個已經存在於緩衝池的頁被存取時,如果它在Old Sublist中,則會被移動到New Sublist的最前端;如果它在New Sublist中,則不會改變位置。
- 淘汰策略:當緩衝池已滿時,需要淘汰一些頁來騰出空間。淘汰策略是從Old Sublist的尾部開始掃描,找到第一個沒有被修改過(clean)且沒有被鎖定(unlocked)的頁,並將其淘汰出緩衝池。
寫緩衝(Change Buffer)
主要用於快取對非聚集索引的修改操作,減少磁碟I/O。寫緩衝是緩衝池的一部分,當對非聚集索引進行插入、刪除或更新時,不會立即修改磁碟上的索引頁,而是先記錄在寫緩衝中。當緩衝池中的資料頁被重新整理到磁碟時,會將寫緩衝中的修改操作合併到相應的索引頁中。
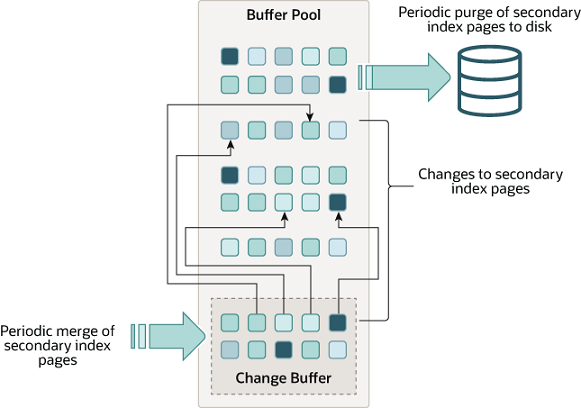
- 寫緩衝型別:寫緩衝有三種型別,分別用於記錄不同型別的非聚集索引修改操作:
- Insert Buffer:用於記錄對非聚集索引進行插入操作時產生的新條目(entry)。
- Delete Buffer:用於記錄對非聚集索引進行刪除操作時需要刪除的條目(entry)。
- Purge Buffer:用於記錄對非聚集索引進行更新操作時需要刪除和插入的條目(entry)。
- 寫緩衝結構:寫緩衝是由多個段(segment)組成的,每個段有一個點陣圖(bitmap),用於標記哪些頁有寫緩衝條目(entry)。每個段都有一個根頁(root page),用於儲存寫緩衝條目(entry)。每個根頁都有一個B+樹結構,用於按照空間ID(space ID)和頁號(page number)排序寫緩衝條目(entry)。
- 寫緩衝合併:當緩衝池中的資料頁被重新整理到磁碟時,會觸發寫緩衝的合併操作。合併操作的步驟如下:
- 根據資料頁的空間ID(space ID)和頁號(page number),在寫緩衝中查詢是否有對應的條目(entry)。
- 如果有,就將寫緩衝中的條目(entry)應用到磁碟上的索引頁中,完成修改操作。
- 如果沒有,就直接重新整理資料頁到磁碟,不做任何修改操作。
- 將寫緩衝中已經合併的條目(entry)刪除,釋放空間。
紀錄檔緩衝(Log Buffer)
主要用於快取重做紀錄檔(Redo Log),保證事務的永續性。紀錄檔緩衝是一個迴圈使用的記憶體區域,預設大小為16MB,可以通過引數innodb_log_buffer_size來調整。當事務提交時,會將紀錄檔緩衝中的重做紀錄檔重新整理到磁碟上的重做紀錄檔檔案中。紀錄檔緩衝中的重做紀錄檔也會在以下情況下被重新整理:紀錄檔緩衝已滿、每秒鐘一次、每個事務檢查點一次。
- 重做紀錄檔:重做紀錄檔是一種物理紀錄檔,記錄了對資料頁進行的物理修改操作。重做紀錄檔可以用於恢復事務在崩潰或異常情況下未完成的修改操作,保證資料的完整性和一致性。
- 重做紀錄檔格式:重做紀錄檔由多個固定大小的紀錄檔塊(log block)組成,每個紀錄檔塊預設大小為512位元組。每個紀錄檔塊包含以下資訊:
- 紀錄檔塊頭(log block header):佔用12位元組,包含了紀錄檔塊編號(log block number),校驗和(checksum),資料長度(data length)等資訊。
- 紀錄檔記錄(log record):佔用不定長度,包含了對資料頁進行的物理修改操作的詳細資訊。例如,修改了哪個資料頁,修改了哪個偏移量,修改前後的值是什麼等。
- 紀錄檔塊尾(log block tail):佔用4位元組,包含了紀錄檔塊編號(log block number)的副本。
- 重做紀錄檔檔案:重做紀錄檔檔案是磁碟上儲存重做紀錄檔的檔案,通常有兩個或多個,以實現迴圈寫入和備份。重做紀錄檔檔案可以通過引數innodb_log_files_in_group來指定數量,通過引數innodb_log_file_size來指定大小。重做紀錄檔檔案中有一個特殊的位置叫做檢查點(checkpoint),表示到這個位置之前的所有重做紀錄檔都已經被應用到資料檔案中,可以被覆蓋或刪除。
自適應雜湊索引(Adaptive Hash Index)
主要用於加速等值查詢,提高查詢效率。自適應雜湊索引是InnoDB根據查詢頻率和模式自動建立的一種雜湊索引,可以將某些B+樹索引轉換為雜湊索引,從而減少樹的搜尋次數。自適應雜湊索引是可選的,可以通過引數innodb_adaptive來開啟或關閉。
- 自適應雜湊索引原理:當InnoDB發現某個B+樹索引被頻繁用於等值查詢時,就會為該索引建立一個對應的雜湊索引。雜湊索引是一種基於鍵值對的索引,可以通過雜湊函數快速定位到資料頁的位置。雜湊索引比B+樹索引更簡單,更高效,但只能用於等值查詢,不能用於範圍查詢或排序查詢。
- 自適應雜湊索引結構:自適應雜湊索引是由多個分割區(partition)組成的,每個分割區有一個雜湊表(hash table),用於儲存鍵值對。每個鍵值對包含以下資訊:
- 鍵(key):由B+樹索引的鍵值和空間ID(space ID)組成。
- 值(value):由資料頁的頁號(page number)和記錄的偏移量(offset)組成。
- 自適應雜湊索引使用:當InnoDB執行一個等值查詢時,會先在自適應雜湊索引中查詢是否有匹配的鍵值對。如果有,就直接定位到資料頁的位置,並獲取記錄。如果沒有,就回退到B+樹索引中進行搜尋。
磁碟結構
表空間(Tablespace)
表空間是InnoDB儲存引擎邏輯結構的最高層,所有的資料都存放在表空間中。表空間可以分為以下五種型別¹²³⁴⁵:
- 系統表空間(system tablespace):系統表空間是InnoDB的預設表空間,通常儲存在ibdata1檔案中,也可以分成多個檔案。系統表空間包含了InnoDB的資料字典,雙寫緩衝區,Change Buffer和undo log等重要資訊。系統表空間是共用的,可以儲存多個表的資料和索引。系統表空間的大小是不可縮小的,只能通過重建整個資料庫來減小。
- 臨時表空間(temporary tablespace):臨時表空間用於儲存臨時表的資料和索引,例如在執行復雜查詢時產生的中間結果。臨時表空間通常儲存在ibtmp1檔案中,可以設定為自動擴充套件或固定大小。臨時表空間不會持久化到磁碟,每次資料庫重啟後都會被清空。
- 常規表空間(general tablespace):常規表空間是一種共用表空間,可以儲存多個表的資料和索引。常規表空間可以在任意位置建立多個檔案,檔案的擴充套件方式可以是自動擴充套件或預分配。常規表空間可以用於跨資料庫儲存資料,或者將不同型別或大小的表分開儲存。
- undo表空間(undo tablespace):undo表空間包含undo log復原記錄的集合,用於事務回滾和一致性讀。undo log記錄了資料頁修改前的值,用於恢復未提交或已回滾的事務所做的修改,或者提供給其他事務一個資料修改前的快照。undo表空間可以有多個檔案組成,檔案儲存在innodb_undo_directory指定的目錄下,以undofile開頭命名。
- 檔案獨佔表空間(file-per-table tablespace):檔案每表表空間是一種獨佔表空間,含單個InnoDB表的資料和索引,並儲存在檔案系統中自己的資料檔案中。檔案每表表空間的檔名與表名相同,以.ibd為擴充套件名,位於資料庫目錄下。檔案每表表空間可以實現單個表的壓縮,加密,傳輸和優化等操作。
資料字典(Data Dictionary)
資料字典包含用於跟蹤物件,如表,索引,和列等後設資料的內部系統表²⁴。後設資料實際上位於InnoDB系統表空間中。InnoDB使用資料字典來管理和存取資料庫物件,並檢查使用者對物件的許可權。資料字典在資料庫啟動時載入到記憶體中,並在資料庫關閉時重新整理到磁碟上。
雙寫緩衝區(Doublewrite Buffer)
雙寫緩衝區位於系統表空間中的儲存區域,用於保證資料頁在寫入磁碟時不會損壞²⁴⁵。InnoDB在Buffer Pool中重新整理頁面時,會將資料頁寫入doublewrite緩衝區後才會寫入磁碟。如果在寫入OS Cache或者磁碟mysql程序奔潰後, InnoDB啟動崩潰恢復能從doublewrite找到完整的副本用來恢復。
重做紀錄檔(Redo Log)
重做紀錄檔是基於磁碟的資料結構,在崩潰恢復期間用於糾正不完整事務寫入的資料 。MySQL以迴圈方式寫入重做紀錄檔檔案,預設會產生ib_logfile0 和 ib_logfile1兩個檔案。InnoDB在提交事務之前重新整理事務的redo log,InnoDB使用組提交(group commit)技術來提高效能。重做紀錄檔記錄了資料頁的物理修改,而不是邏輯修改,這樣可以減少紀錄檔的大小和恢復的時間。重做紀錄檔可以通過innodb_log_file_size和innodb_log_files_in_group引數來調整大小和數量。
更改緩衝區(Change Buffer)
更改緩衝區是Buffer Pool中的一部分,用於快取對輔助索引頁的修改 。當InnoDB需要修改一個輔助索引頁時,如果該頁在Buffer Pool中,則直接修改;如果該頁不在Buffer Pool中,則將修改記錄在Change Buffer中,而不是從磁碟讀取該頁。這樣可以減少磁碟I/O操作,提高效能。Change Buffer中的修改會在後臺或者檢查點時合併到輔助索引頁中。Change Buffer的大小可以通過innodb_change_buffer_max_size引數來調整。
四、InnoDB磁碟空間管理結構
這部分簡單介紹即可,參考官方檔案:MySQL :: MySQL 8.0 參考手冊 :: 15.11.2 檔案空間管理
InnoDB的磁碟結構主要包括以下幾個部分:
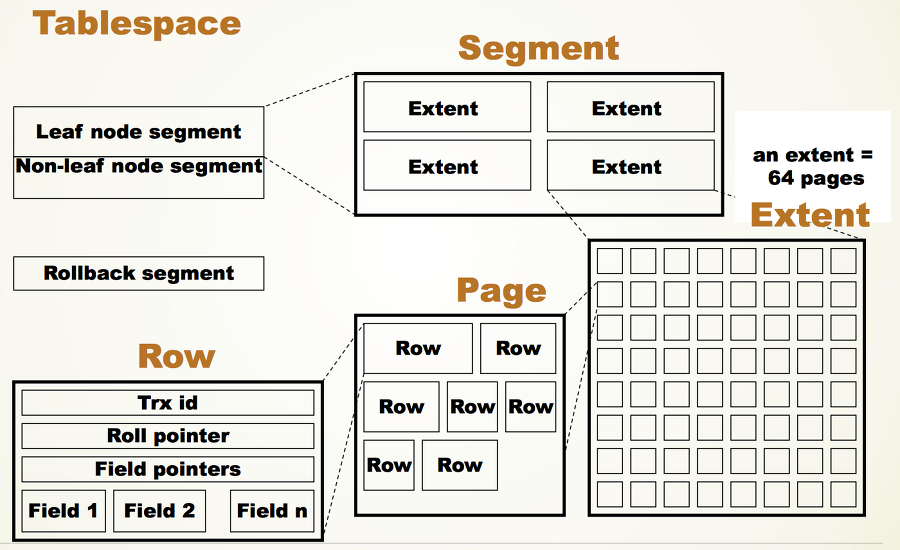
- 表空間(Tablespace):表空間是InnoDB儲存資料和索引的邏輯單位,它由一個或多個檔案組成。表空間可以分為系統表空間(System Tablespace),通用表空間(General Tablespace),檔案表空間(File-Per-Table Tablespace)和臨時表空間(Temporary Tablespace)。
- 段(Segment):段是表空間中分配和管理空間的單位,它由一個或多個連續或不連續的區(Extent)組成。段可以分為資料段(Data Segment),索引段(Index Segment),回滾段(Rollback Segment),復原紀錄檔段(Undo Log Segment)和系統段(System Segment)。
- 區(Extent):區是段中分配空間的單位,它由一組連續的頁(Page)組成。每個區的大小固定為1MB,包含64個頁。
- 頁(Page):頁是InnoDB在磁碟和記憶體之間傳輸資料的基本單位,它由一個固定大小的塊(Block)組成。每個頁的大小預設為16KB,可以通過引數innodb_page_size來調整。頁可以分為不同的型別,根據儲存的內容而定,比如資料頁(Data Page),索引頁(Index Page),系統頁(System Page),事務系統頁(Transaction System Page),復原紀錄檔頁(Undo Log Page)等。
- 行(Row):行是InnoDB儲存資料記錄的最小單位,它由一個或多個列(Column)組成。每個行的大小不能超過半個頁。行可以分為兩種格式,根據儲存方式而定,比如緊湊格式(Compact Format)和動態格式(Dynamic Format)。
參考資料:
- MySQL :: MySQL 8.0 Reference Manual
- 高效能MySQL 第四版