CMU15445 (Fall 2020) 資料庫系統 Project#3
前言
經過前兩個實驗的鋪墊,終於到了執行 SQL 語句的時候了。這篇部落格將會介紹 SQL 執行計劃實驗的實現過程,下面進入正題。
總體架構
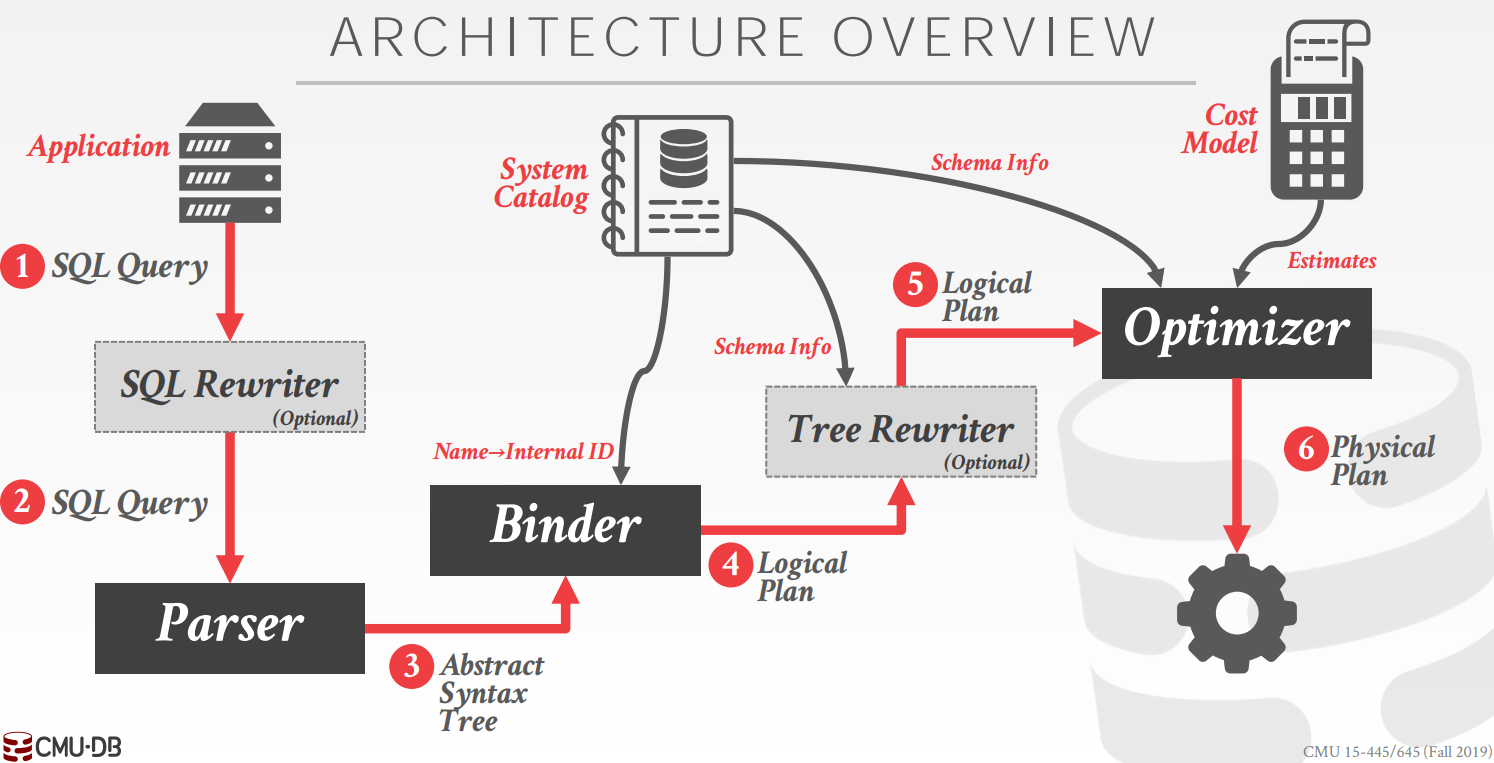
一條 SQL 查詢的處理流程如下為:
- SQL 被 Parser 解析為抽象語法樹 AST
- Binber 將 AST轉換為 Bustub 可以理解的更高階的 AST
- Tree rewriter 將語法樹轉換為邏輯執行計劃
- Optimizer 對邏輯計劃進行優化,生成最終要執行的物理執行計劃
- 執行引擎執行物理執行計劃,返回查詢結果
物理執行計劃定義了具體的執行方式,比如邏輯計劃中的 Join 可以被替換為 Nest loop join、 Hash join 或者 Index join。由於 Fall 2020 版本的程式碼沒有 Parser 和 Optimizer,所以測試用例中都是手動構造的物理執行計劃。
系統目錄
目錄結構
資料庫會維護一個內部目錄,以跟蹤有關資料庫的後設資料。目錄中可以存放資料表的資訊、索引資訊和統計資料。Bustub 中使用 Catalog 類表示系統目錄,內部存放 table_oid_t 到 TableMetadata 的對映表以及 index_oid_t 到 IndexInfo 的對映表。
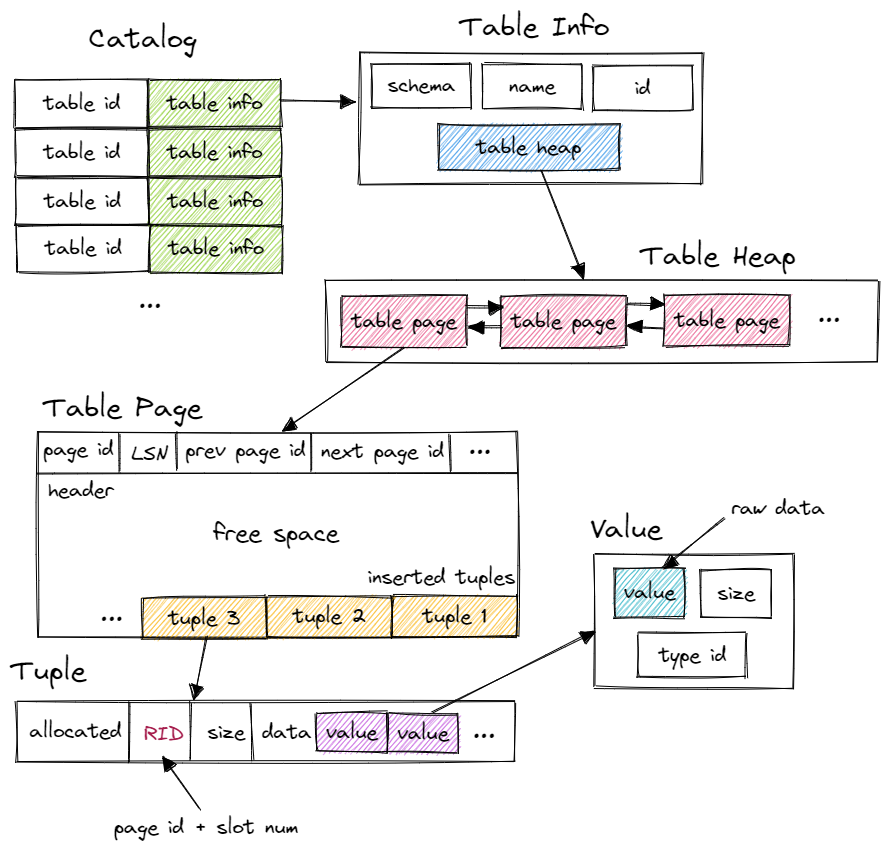
TableMetadata 描述了一張表的資訊,包括表名、Schema、表 id 和表的指標。程式碼如下所示:
struct TableMetadata {
TableMetadata(Schema schema, std::string name, std::unique_ptr<TableHeap> &&table, table_oid_t oid)
: schema_(std::move(schema)), name_(std::move(name)), table_(std::move(table)), oid_(oid) {}
Schema schema_;
std::string name_;
std::unique_ptr<TableHeap> table_;
table_oid_t oid_;
};
TableHeap 代表了一張表,實現了 tuple 的增刪改查操作。它的內部存放了第一個表頁 TablePage 的 id,由於每個 TablePage 都會存放前一個和下一個表頁的 id,這樣就將表組織為雙向連結串列,可以通過 TableIterator 進行迭代。
TablePage 使用分槽頁結構(slotted page),tuple 從後往前插入,每個 tuple 由一個 RID 標識。
class RID {
public:
RID() = default;
/**
* Creates a new Record Identifier for the given page identifier and slot number.
*/
RID(page_id_t page_id, uint32_t slot_num) : page_id_(page_id), slot_num_(slot_num) {}
explicit RID(int64_t rid) : page_id_(static_cast<page_id_t>(rid >> 32)), slot_num_(static_cast<uint32_t>(rid)) {}
inline int64_t Get() const { return (static_cast<int64_t>(page_id_)) << 32 | slot_num_; }
inline page_id_t GetPageId() const { return page_id_; }
inline uint32_t GetSlotNum() const { return slot_num_; }
bool operator==(const RID &other) const { return page_id_ == other.page_id_ && slot_num_ == other.slot_num_; }
private:
page_id_t page_id_{INVALID_PAGE_ID};
uint32_t slot_num_{0}; // logical offset from 0, 1...
};
表管理
Catalog 中有三個與表相關的方法:CreateTable、GetTable(const std::string &table_name) 和 GetTable(table_oid_t table_oid),第一個方法用於建立一個新的表,後面兩個方法用於獲取表後設資料:
/**
* Create a new table and return its metadata.
* @param txn the transaction in which the table is being created
* @param table_name the name of the new table
* @param schema the schema of the new table
* @return a pointer to the metadata of the new table
*/
TableMetadata *CreateTable(Transaction *txn, const std::string &table_name, const Schema &schema) {
BUSTUB_ASSERT(names_.count(table_name) == 0, "Table names should be unique!");
auto tid = next_table_oid_++;
auto table_heap = std::make_unique<TableHeap>(bpm_, lock_manager_, log_manager_, txn);
tables_[tid] = std::make_unique<TableMetadata>(schema, table_name, std::move(table_heap), tid);
names_[table_name] = tid;
return tables_[tid].get();
}
/** @return table metadata by name */
TableMetadata *GetTable(const std::string &table_name) {
auto it = names_.find(table_name);
if (it == names_.end()) {
throw std::out_of_range("Table is not found");
}
return tables_[it->second].get();
}
/** @return table metadata by oid */
TableMetadata *GetTable(table_oid_t table_oid) {
auto it = tables_.find(table_oid);
if (it == tables_.end()) {
throw std::out_of_range("Table is not found");
}
return it->second.get();
}
索引管理
建立索引
Catalog 使用 CreateIndex() 方法建立索引,建立的時候需要將表中的資料轉換為鍵值對插入索引中:
/**
* Create a new index, populate existing data of the table and return its metadata.
* @param txn the transaction in which the table is being created
* @param index_name the name of the new index
* @param table_name the name of the table
* @param schema the schema of the table
* @param key_schema the schema of the key
* @param key_attrs key attributes
* @param keysize size of the key
* @return a pointer to the metadata of the new table
*/
template <class KeyType, class ValueType, class KeyComparator>
IndexInfo *CreateIndex(Transaction *txn, const std::string &index_name, const std::string &table_name,
const Schema &schema, const Schema &key_schema, const std::vector<uint32_t> &key_attrs,
size_t keysize) {
BUSTUB_ASSERT(index_names_.count(index_name) == 0, "Index names should be unique!");
auto id = next_index_oid_++;
auto meta = new IndexMetadata(index_name, table_name, &schema, key_attrs);
auto index = std::make_unique<BPLUSTREE_INDEX_TYPE>(meta, bpm_);
// 初始化索引
auto table = GetTable(table_name)->table_.get();
for (auto it = table->Begin(txn); it != table->End(); ++it) {
index->InsertEntry(it->KeyFromTuple(schema, key_schema, key_attrs), it->GetRid(), txn);
}
indexes_[id] = std::make_unique<IndexInfo>(key_schema, index_name, std::move(index), id, table_name, keysize);
index_names_[table_name][index_name] = id;
return indexes_[id].get();
}
查詢索引
資料庫中有多個表,一個表可以擁有多個索引,但是每個索引對應一個全域性唯一的 index_oid_t:
IndexInfo *GetIndex(const std::string &index_name, const std::string &table_name) {
auto it = index_names_.find(table_name);
if (it == index_names_.end()) {
throw std::out_of_range("Table is not found");
}
auto iit = it->second.find(index_name);
if (iit == it->second.end()) {
throw std::out_of_range("Index is not found");
}
return indexes_[iit->second].get();
}
IndexInfo *GetIndex(index_oid_t index_oid) {
auto it = indexes_.find(index_oid);
if (it == indexes_.end()) {
throw std::out_of_range("Index is not found");
}
return it->second.get();
}
std::vector<IndexInfo *> GetTableIndexes(const std::string &table_name) {
auto it = index_names_.find(table_name);
if (it == index_names_.end()) {
return {};
};
std::vector<IndexInfo *> indexes;
for (auto &[name, id] : it->second) {
indexes.push_back(GetIndex(id));
}
return indexes;
}
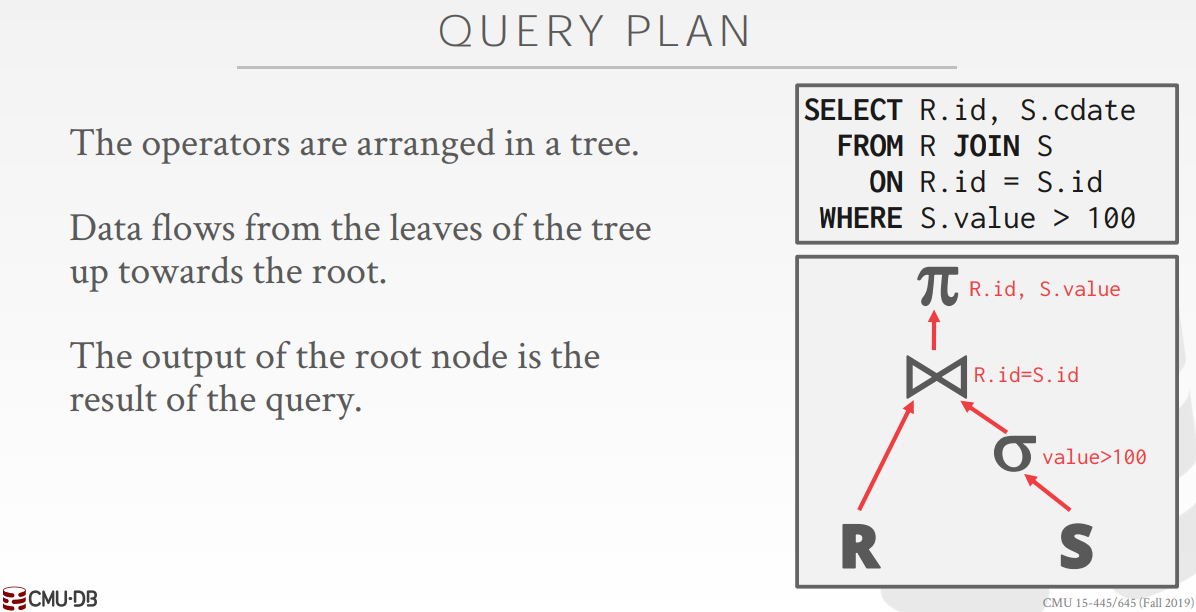
執行器
如下圖的右下角所示,執行計劃由一系列運算元組合而成,每個運算元可以擁有自己的子運算元,資料從子運算元流向父運算元,最終從根節點輸出執行結果。執行計劃有三種執行模型:
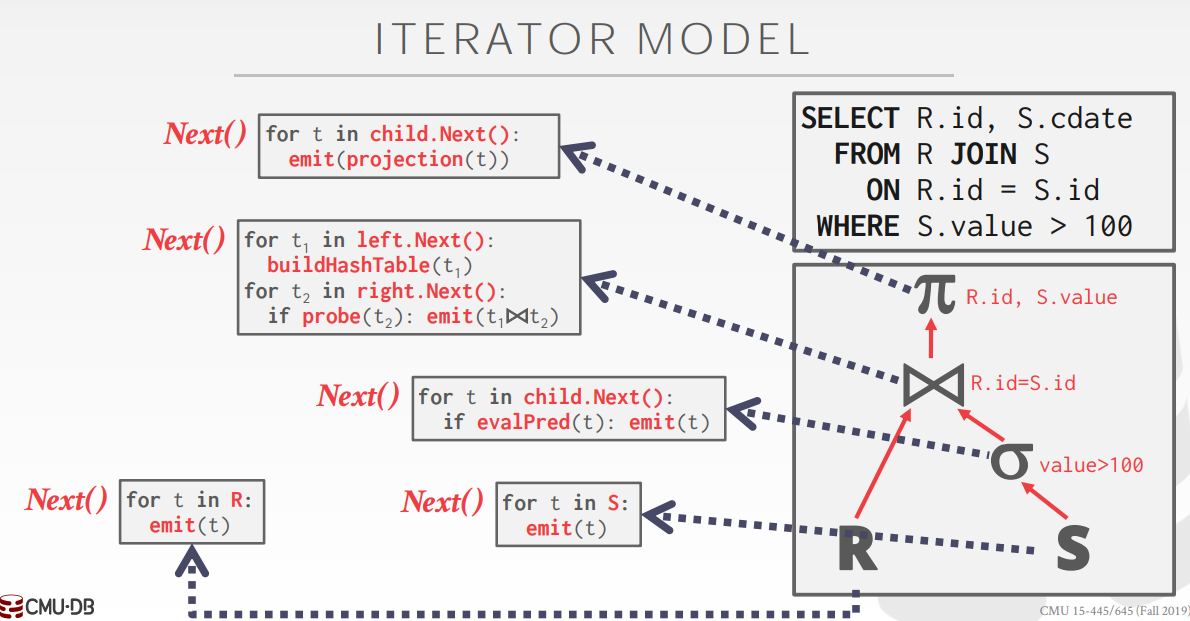
-
迭代模型:每個運算元都會實現
Next()方法,父運算元呼叫子運算元的Next()方法獲取一條記錄,外部通過不斷呼叫根節點的Next()方法直至沒有更多資料輸出。這種方法的優點就是一次只產生一條 Tuple,記憶體佔用小 -
物化模型:每個運算元一次性返回所有記錄
-
向量模型:迭代模型和物化模型的折中版本,一次返回一批資料
本次實驗使用迭代模型,虛擬碼如下圖所示:
Bustub 使用執行引擎 ExecutionEngine 執行物理計劃,這個類的程式碼很簡潔,只有一個 Execute() 方法。可以看到這個方法會先將執行計劃轉換為對應的執行器 executor,使用 Init() 初始化後迴圈呼叫 executor 的 Next() 方法獲取查詢結果:
class ExecutionEngine {
public:
ExecutionEngine(BufferPoolManager *bpm, TransactionManager *txn_mgr, Catalog *catalog)
: bpm_(bpm), txn_mgr_(txn_mgr), catalog_(catalog) {}
DISALLOW_COPY_AND_MOVE(ExecutionEngine);
bool Execute(const AbstractPlanNode *plan, std::vector<Tuple> *result_set, Transaction *txn,
ExecutorContext *exec_ctx) {
// construct executor
auto executor = ExecutorFactory::CreateExecutor(exec_ctx, plan);
// prepare
executor->Init();
// execute
try {
Tuple tuple;
RID rid;
while (executor->Next(&tuple, &rid)) {
if (result_set != nullptr) {
result_set->push_back(tuple);
}
}
} catch (Exception &e) {
// TODO(student): handle exceptions
}
return true;
}
private:
[[maybe_unused]] BufferPoolManager *bpm_;
[[maybe_unused]] TransactionManager *txn_mgr_;
[[maybe_unused]] Catalog *catalog_;
};
全表掃描
SeqScanExecutor 用於進行全表掃描操作,內部帶有 SeqScanPlan 執行計劃:
/**
* SeqScanExecutor executes a sequential scan over a table.
*/
class SeqScanExecutor : public AbstractExecutor {
public:
/**
* Creates a new sequential scan executor.
* @param exec_ctx the executor context
* @param plan the sequential scan plan to be executed
*/
SeqScanExecutor(ExecutorContext *exec_ctx, const SeqScanPlanNode *plan);
void Init() override;
bool Next(Tuple *tuple, RID *rid) override;
const Schema *GetOutputSchema() override { return plan_->OutputSchema(); }
private:
/** The sequential scan plan node to be executed. */
const SeqScanPlanNode *plan_;
TableMetadata *table_metadata_;
TableIterator it_;
};
SeqScanPlan 宣告如下,Schema *output 指明瞭輸出列,table_oid 代表被掃描的表,而 AbstractExpression *predicate 代表謂詞運算元:
/**
* SeqScanPlanNode identifies a table that should be scanned with an optional predicate.
*/
class SeqScanPlanNode : public AbstractPlanNode {
public:
/**
* Creates a new sequential scan plan node.
* @param output the output format of this scan plan node
* @param predicate the predicate to scan with, tuples are returned if predicate(tuple) = true or predicate = nullptr
* @param table_oid the identifier of table to be scanned
*/
SeqScanPlanNode(const Schema *output, const AbstractExpression *predicate, table_oid_t table_oid)
: AbstractPlanNode(output, {}), predicate_{predicate}, table_oid_(table_oid) {}
PlanType GetType() const override { return PlanType::SeqScan; }
/** @return the predicate to test tuples against; tuples should only be returned if they evaluate to true */
const AbstractExpression *GetPredicate() const { return predicate_; }
/** @return the identifier of the table that should be scanned */
table_oid_t GetTableOid() const { return table_oid_; }
private:
/** The predicate that all returned tuples must satisfy. */
const AbstractExpression *predicate_;
/** The table whose tuples should be scanned. */
table_oid_t table_oid_;
};
舉個栗子,SELECT name, age FROM t_student WHERE age > 16 的 age > 16 部分就是 predicate ,實際資料型別為 ComparisonExpression ,而 predicate 又由 ColumnValueExpression(代表 age 列的值) 和 ConstantValueExpression(代表 16)組成。
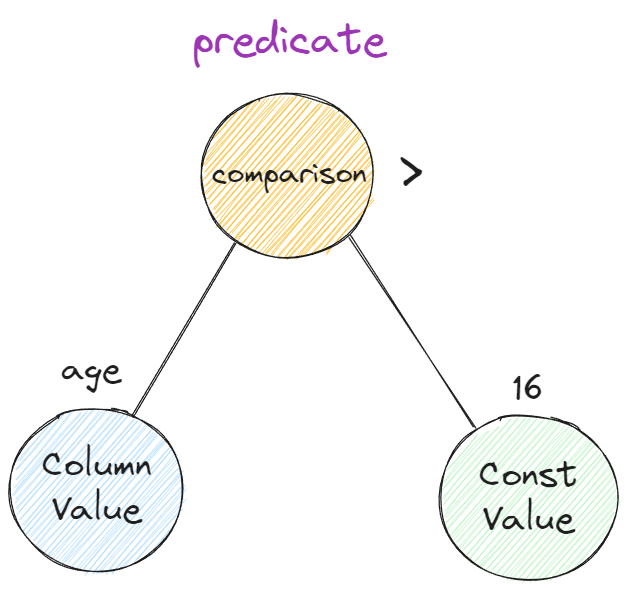
要實現全表掃描只需在 Next 函數中判斷迭代器所指的 tuple 是否滿足查詢條件並遞增迭代器,如果滿足條件就返回該 tuple,不滿足就接著迭代。
SeqScanExecutor::SeqScanExecutor(ExecutorContext *exec_ctx, const SeqScanPlanNode *plan)
: AbstractExecutor(exec_ctx),
plan_(plan), table_metadata_(exec_ctx->GetCatalog()->GetTable(plan->GetTableOid())) {}
void SeqScanExecutor::Init() { it_ = table_metadata_->table_->Begin(exec_ctx_->GetTransaction()); }
bool SeqScanExecutor::Next(Tuple *tuple, RID *rid) {
auto predicate = plan_->GetPredicate();
while (it_ != table_metadata_->table_->End()) {
*tuple = *it_++;
*rid = tuple->GetRid();
if (!predicate || predicate->Evaluate(tuple, &table_metadata_->schema_).GetAs<bool>()) {
// 只保留輸出列
std::vector<Value> values;
for (auto &col : GetOutputSchema()->GetColumns()) {
values.push_back(col.GetExpr()->Evaluate(tuple, &table_metadata_->schema_));
}
*tuple = {values, GetOutputSchema()};
return true;
}
}
return false;
}
測試用例中通過下述程式碼手動構造出 SELECT colA, colB FROM test_1 WHERE colA < 500 的全表掃描執行計劃並執行:
// Construct query plan
TableMetadata *table_info = GetExecutorContext()->GetCatalog()->GetTable("test_1");
Schema &schema = table_info->schema_;
auto *colA = MakeColumnValueExpression(schema, 0, "colA");
auto *colB = MakeColumnValueExpression(schema, 0, "colB");
auto *const500 = MakeConstantValueExpression(ValueFactory::GetIntegerValue(500));
auto *predicate = MakeComparisonExpression(colA, const500, ComparisonType::LessThan);
auto *out_schema = MakeOutputSchema({{"colA", colA}, {"colB", colB}});
SeqScanPlanNode plan{out_schema, predicate, table_info->oid_};
// Execute
std::vector<Tuple> result_set;
GetExecutionEngine()->Execute(&plan, &result_set, GetTxn(), GetExecutorContext());
索引掃描
上一節中實現了 B+ 樹索引,使用索引可以減小查詢範圍,大大加快查詢速度。由於 IndexScanExecutor 不是模板類,所以這裡使用的 KeyType 為 GenericKey<8>,KeyComparator 為 GenericComparator<8>:
#define B_PLUS_TREE_INDEX_ITERATOR_TYPE IndexIterator<GenericKey<8>, RID, GenericComparator<8>>
#define B_PLUS_TREE_INDEX_TYPE BPlusTreeIndex<GenericKey<8>, RID, GenericComparator<8>>
class IndexScanExecutor : public AbstractExecutor {
public:
/**
* Creates a new index scan executor.
* @param exec_ctx the executor context
* @param plan the index scan plan to be executed
*/
IndexScanExecutor(ExecutorContext *exec_ctx, const IndexScanPlanNode *plan);
const Schema *GetOutputSchema() override { return plan_->OutputSchema(); };
void Init() override;
bool Next(Tuple *tuple, RID *rid) override;
private:
/** The index scan plan node to be executed. */
const IndexScanPlanNode *plan_;
IndexInfo *index_info_;
B_PLUS_TREE_INDEX_TYPE *index_;
TableMetadata *table_metadata_;
B_PLUS_TREE_INDEX_ITERATOR_TYPE it_;
};
索引掃描的程式碼和全表掃描幾乎一樣,只是迭代器換成了 B+ 樹的迭代器:
IndexScanExecutor::IndexScanExecutor(ExecutorContext *exec_ctx, const IndexScanPlanNode *plan)
: AbstractExecutor(exec_ctx),
plan_(plan),
index_info_(exec_ctx->GetCatalog()->GetIndex(plan->GetIndexOid())),
index_(dynamic_cast<B_PLUS_TREE_INDEX_TYPE *>(index_info_->index_.get())),
table_metadata_(exec_ctx->GetCatalog()->GetTable(index_info_->table_name_)) {}
void IndexScanExecutor::Init() { it_ = index_->GetBeginIterator(); }
bool IndexScanExecutor::Next(Tuple *tuple, RID *rid) {
auto predicate = plan_->GetPredicate();
while (it_ != index_->GetEndIterator()) {
*rid = (*it_).second;
table_metadata_->table_->GetTuple(*rid, tuple, exec_ctx_->GetTransaction());
++it_;
if (!predicate || predicate->Evaluate(tuple, &table_metadata_->schema_).GetAs<bool>()) {
// 只保留輸出列
std::vector<Value> values;
for (auto &col : GetOutputSchema()->GetColumns()) {
values.push_back(col.GetExpr()->Evaluate(tuple, &table_metadata_->schema_));
}
*tuple = {values, GetOutputSchema()};
return true;
}
}
return false;
}
插入
插入操作分為兩種:
- raw inserts:插入資料直接來自插入執行器本身,比如
INSERT INTO tbl_user VALUES (1, 15), (2, 16) - not-raw inserts:插入的資料來自子執行器,比如
INSERT INTO tbl_user1 SELECT * FROM tbl_user2
可以使用插入計劃的 IsRawInsert() 判斷插入操作的型別,這個函數根據子查詢器列表是否為空進行判斷:
/** @return true if we embed insert values directly into the plan, false if we have a child plan providing tuples */
bool IsRawInsert() const { return GetChildren().empty(); }
如果是 raw inserts,我們直接根據插入執行器中的資料構造 tuple 並插入表中,否則呼叫子執行器的 Next 函數獲取資料並插入表中。因為表中可能建了索引,所以插入資料之後需要更新索引:
class InsertExecutor : public AbstractExecutor {
public:
/**
* Creates a new insert executor.
* @param exec_ctx the executor context
* @param plan the insert plan to be executed
* @param child_executor the child executor to obtain insert values from, can be nullptr
*/
InsertExecutor(ExecutorContext *exec_ctx, const InsertPlanNode *plan,
std::unique_ptr<AbstractExecutor> &&child_executor);
const Schema *GetOutputSchema() override { return plan_->OutputSchema(); };
void Init() override;
// Note that Insert does not make use of the tuple pointer being passed in.
// We return false if the insert failed for any reason, and return true if all inserts succeeded.
bool Next([[maybe_unused]] Tuple *tuple, RID *rid) override;
void InsertTuple(Tuple *tuple, RID *rid);
private:
/** The insert plan node to be executed. */
const InsertPlanNode *plan_;
std::unique_ptr<AbstractExecutor> child_executor_;
TableMetadata *table_metadata_;
std::vector<IndexInfo *> index_infos_;
uint32_t index_{0};
};
InsertExecutor::InsertExecutor(ExecutorContext *exec_ctx, const InsertPlanNode *plan,
std::unique_ptr<AbstractExecutor> &&child_executor)
: AbstractExecutor(exec_ctx),
plan_(plan),
child_executor_(std::move(child_executor)),
table_metadata_(exec_ctx->GetCatalog()->GetTable(plan->TableOid())),
index_infos_(exec_ctx->GetCatalog()->GetTableIndexes(table_metadata_->name_)) {}
void InsertExecutor::Init() {
if (!plan_->IsRawInsert()) {
child_executor_->Init();
}
}
bool InsertExecutor::Next([[maybe_unused]] Tuple *tuple, RID *rid) {
if (plan_->IsRawInsert()) {
if (index_ >= plan_->RawValues().size()) {
return false;
}
*tuple = {plan_->RawValuesAt(index_++), &table_metadata_->schema_};
InsertTuple(tuple, rid);
return true;
} else {
auto has_data = child_executor_->Next(tuple, rid);
if (has_data) {
InsertTuple(tuple, rid);
}
return has_data;
}
}
void InsertExecutor::InsertTuple(Tuple *tuple, RID *rid) {
// 更新資料表
table_metadata_->table_->InsertTuple(*tuple, rid, exec_ctx_->GetTransaction());
// 更新索引
for (auto &index_info : index_infos_) {
index_info->index_->InsertEntry(
tuple->KeyFromTuple(table_metadata_->schema_, index_info->key_schema_, index_info->index_->GetKeyAttrs()), *rid,
exec_ctx_->GetTransaction());
}
}
更新
UpdateExecutor 從子執行器獲取需要更新的 tuple,並呼叫 GenerateUpdatedTuple 生成更新之後的 tuple,同樣也要更新索引。
class UpdateExecutor : public AbstractExecutor {
friend class UpdatePlanNode;
public:
UpdateExecutor(ExecutorContext *exec_ctx, const UpdatePlanNode *plan,
std::unique_ptr<AbstractExecutor> &&child_executor);
const Schema *GetOutputSchema() override { return plan_->OutputSchema(); };
void Init() override;
bool Next([[maybe_unused]] Tuple *tuple, RID *rid) override;
/* Given an old tuple, creates a new updated tuple based on the updateinfo given in the plan */
Tuple GenerateUpdatedTuple(const Tuple &old_tup);
private:
const UpdatePlanNode *plan_;
const TableMetadata *table_info_;
std::unique_ptr<AbstractExecutor> child_executor_;
std::vector<IndexInfo *> index_infos_;
};
bool UpdateExecutor::Next([[maybe_unused]] Tuple *tuple, RID *rid) {
if (!child_executor_->Next(tuple, rid)) {
return false;
}
// 更新資料表
auto new_tuple = GenerateUpdatedTuple(*tuple);
table_info_->table_->UpdateTuple(new_tuple, *rid, exec_ctx_->GetTransaction());
// 更新索引
for (auto &index_info : index_infos_) {
// 刪除舊的 tuple
index_info->index_->DeleteEntry(
tuple->KeyFromTuple(table_info_->schema_, index_info->key_schema_, index_info->index_->GetKeyAttrs()), *rid,
exec_ctx_->GetTransaction());
// 插入新的 tuple
index_info->index_->InsertEntry(
new_tuple.KeyFromTuple(table_info_->schema_, index_info->key_schema_, index_info->index_->GetKeyAttrs()), *rid,
exec_ctx_->GetTransaction());
}
return true;
}
刪除
DeleteExecutor 的資料來自於子執行器,刪除之後需要更新索引。
DeleteExecutor::DeleteExecutor(ExecutorContext *exec_ctx, const DeletePlanNode *plan,
std::unique_ptr<AbstractExecutor> &&child_executor)
: AbstractExecutor(exec_ctx),
plan_(plan),
child_executor_(std::move(child_executor)),
table_metadata_(exec_ctx->GetCatalog()->GetTable(plan->TableOid())),
index_infos_(exec_ctx->GetCatalog()->GetTableIndexes(table_metadata_->name_)) {}
void DeleteExecutor::Init() { child_executor_->Init(); }
bool DeleteExecutor::Next([[maybe_unused]] Tuple *tuple, RID *rid) {
if (!child_executor_->Next(tuple, rid)) {
return false;
}
table_metadata_->table_->MarkDelete(*rid, exec_ctx_->GetTransaction());
// 更新索引
for (auto &index_info : index_infos_) {
index_info->index_->DeleteEntry(
tuple->KeyFromTuple(table_metadata_->schema_, index_info->key_schema_, index_info->index_->GetKeyAttrs()), *rid,
exec_ctx_->GetTransaction());
}
return true;
}
巢狀迴圈連線
要實現連線操作,最簡單粗暴的方法就是開個二重回圈,外層迴圈是小表(指的是資料頁較少),內層迴圈是大表,小表驅動大表。但是這種連線方法效率非常低,因為完全無法利用到快取池(分塊變成四重回圈之後效果會好一些):

假設一次磁碟 IO 的時間是 0.1ms,那麼大表驅動小表耗時 1.3 小時,小表驅動大表耗時 1.1 小時,可見速度慢的感人。

迴圈巢狀連線執行器 NestLoopJoinExecutor 的宣告如下,可以看到資料成員包括 left_executor_ 和 right_executor,前者代表外表執行器,後者代表內表的執行器:
class NestedLoopJoinExecutor : public AbstractExecutor {
public:
/**
* Creates a new NestedLoop join executor.
* @param exec_ctx the executor context
* @param plan the NestedLoop join plan to be executed
* @param left_executor the child executor that produces tuple for the left side of join
* @param right_executor the child executor that produces tuple for the right side of join
*
*/
NestedLoopJoinExecutor(ExecutorContext *exec_ctx, const NestedLoopJoinPlanNode *plan,
std::unique_ptr<AbstractExecutor> &&left_executor,
std::unique_ptr<AbstractExecutor> &&right_executor);
const Schema *GetOutputSchema() override { return plan_->OutputSchema(); };
void Init() override;
bool Next(Tuple *tuple, RID *rid) override;
private:
/** The NestedLoop plan node to be executed. */
const NestedLoopJoinPlanNode *plan_;
std::unique_ptr<AbstractExecutor> left_executor_;
std::unique_ptr<AbstractExecutor> right_executor_;
Tuple left_tuple_;
bool is_done_;
};
由於一次只能返回一個 tuple,所以需要先儲存外表的一個 tuple,然後迴圈呼叫內表執行器的 Next() 方法直至匹配,當內表遍歷完一遍之後需要更新外表的 tuple。這個部分的程式碼寫的比較奇怪,如果有 python 的 yield 關鍵字可能會好寫很多:
void NestedLoopJoinExecutor::Init() {
left_executor_->Init();
right_executor_->Init();
RID left_rid;
is_done_ = !left_executor_->Next(&left_tuple_, &left_rid);
}
bool NestedLoopJoinExecutor::Next(Tuple *tuple, RID *rid) {
Tuple right_tuple;
RID right_rid, left_rid;
auto predicate = plan_->Predicate();
auto left_schema = left_executor_->GetOutputSchema();
auto right_schema = right_executor_->GetOutputSchema();
while (!is_done_) {
while (right_executor_->Next(&right_tuple, &right_rid)) {
if (!predicate || predicate->EvaluateJoin(&left_tuple_, left_schema, &right_tuple, right_schema).GetAs<bool>()) {
// 拼接 tuple
std::vector<Value> values;
for (auto &col : GetOutputSchema()->GetColumns()) {
values.push_back(col.GetExpr()->EvaluateJoin(&left_tuple_, left_schema, &right_tuple, right_schema));
}
*tuple = {values, GetOutputSchema()};
return true;
}
}
is_done_ = !left_executor_->Next(&left_tuple_, &left_rid);
right_executor_->Init();
}
return false;
}
索引迴圈連線
索引迴圈連線可以減少內表的掃描範圍和磁碟 IO 次數,大大提升連線效率。假設走一次索引的 IO 次數為常數 \(C \ll n\),那麼總共只需 \(M+m \cdot C\) 次 IO:

巢狀迴圈執行器 NestIndexJoinExecutor 的宣告如下,child_executor_ 是外表的執行器,內表的資料由索引提供,所以不需要內表的執行器:
class NestIndexJoinExecutor : public AbstractExecutor {
public:
NestIndexJoinExecutor(ExecutorContext *exec_ctx, const NestedIndexJoinPlanNode *plan,
std::unique_ptr<AbstractExecutor> &&child_executor);
const Schema *GetOutputSchema() override { return plan_->OutputSchema(); }
void Init() override;
bool Next(Tuple *tuple, RID *rid) override;
private:
/** The nested index join plan node. */
const NestedIndexJoinPlanNode *plan_;
std::unique_ptr<AbstractExecutor> child_executor_;
TableMetadata *inner_table_info_;
IndexInfo *index_info_;
Tuple left_tuple_;
std::vector<RID> inner_result_;
};
在索引上尋找匹配值時需要將 left_tuple_ 轉換為內表索引的 key:
bool NestIndexJoinExecutor::Next(Tuple *tuple, RID *rid) {
Tuple right_tuple;
RID left_rid, right_rid;
auto left_schema = plan_->OuterTableSchema();
auto right_schema = plan_->InnerTableSchema();
while (true) {
if (!inner_result_.empty()) {
right_rid = inner_result_.back();
inner_result_.pop_back();
inner_table_info_->table_->GetTuple(right_rid, &right_tuple, exec_ctx_->GetTransaction());
// 拼接 tuple
std::vector<Value> values;
for (auto &col : GetOutputSchema()->GetColumns()) {
values.push_back(col.GetExpr()->EvaluateJoin(&left_tuple_, left_schema, &right_tuple, right_schema));
}
*tuple = {values, GetOutputSchema()};
return true;
}
if (!child_executor_->Next(&left_tuple_, &left_rid)) {
return false;
}
// 在內表的索引上尋找匹配值列表
auto value = plan_->Predicate()->GetChildAt(0)->EvaluateJoin(&left_tuple_, left_schema, &right_tuple, right_schema);
auto inner_key = Tuple({value}, index_info_->index_->GetKeySchema());
index_info_->index_->ScanKey(inner_key, &inner_result_, exec_ctx_->GetTransaction());
}
return false;
}
聚合
由於 Fall2020 沒有要求實現雜湊索引,所以聚合執行器 AggregationExecutor 內部維護的是直接放在記憶體中的雜湊表 SimpleAggregationHashTable 以及雜湊表迭代器 aht_iterator_。將鍵值對插入雜湊表的時候會立刻更新雜湊表中儲存的聚合結果,最終的查詢結果也從該雜湊表獲取:
void AggregationExecutor::Init() {
child_->Init();
// 構造雜湊表
Tuple tuple;
RID rid;
while (child_->Next(&tuple, &rid)) {
aht_.InsertCombine(MakeKey(&tuple), MakeVal(&tuple));
}
aht_iterator_ = aht_.Begin();
}
bool AggregationExecutor::Next(Tuple *tuple, RID *rid) {
auto having = plan_->GetHaving();
while (aht_iterator_ != aht_.End()) {
auto group_bys = aht_iterator_.Key().group_bys_;
auto aggregates = aht_iterator_.Val().aggregates_;
++aht_iterator_;
if (!having || having->EvaluateAggregate(group_bys, aggregates).GetAs<bool>()) {
std::vector<Value> values;
for (auto &col : GetOutputSchema()->GetColumns()) {
values.push_back(col.GetExpr()->EvaluateAggregate(group_bys, aggregates));
}
*tuple = {values, GetOutputSchema()};
return true;
}
}
return false;
}
測試
在終端輸入:
cd build
cmake ..
make
make executor_test
make grading_executor_test # 從 grade scope 扒下來的測試程式碼
./test/executor_test
./test/grading_executor_test
測試結果如下,成功通過了所有測試用例:
後記
通過這次實驗,可以加深對目錄、查詢計劃、迭代模型和 tuple 頁佈局的理解,算是收穫滿滿的一次實驗了,以上~~